
一种移动边缘计算环境中服务QoS的预测方法
2020-06-05 12:17任丽芳王文剑
小型微型计算机系统 2020年6期
任丽芳,王文剑
1(山西财经大学信息学院,太原030006)
2(山西大学计算机与信息技术学院,太原030006)
1 引 言
移动边缘计算(Mobile Edge Computing,MEC)通过在终端设备和云之间引入边缘设备,将云服务扩展到网络边缘,实现了在移动用户附近提供服务,降低云服务器的计算负载,减缓网络带宽的压力[1,2].随着智能移动终端的日益普及,可以在移动设备上运行的移动服务已经被大量开发,并通过访问移动边缘服务器被调用[2].因此,为用户推荐服务或者为服务组合选择组件服务就需要在这种移动边缘计算环境中进行考虑,而服务选择与推荐又以服务QoS (quality of service,服务质量)为依据.服务的QoS 属性主要包括:可用性、响应时间、吞吐率等一组性能指标,其中每个QoS 属性都用于表征服务在某一方面的质量信息.因此,服务QoS 值的预测成为服务推荐与服务选择中重要的基础工作.在移动边缘计算环境中,由于移动用户在各个边缘节点之间的移动,导致所访问的边缘服务器随时可能发生切换,使得边缘计算环境中的服务QoS 预测成为了一个挑战[3].
已有不少工作致力于服务QoS 预测,现有的方法主要是基于协同过滤(collaborative filtering,CF)的,这些方法又可分为基于内存的(memory-based)方法[4-7]和基于模型的(modelbased)方法[8-12].在协同过滤方法的基础上,又发展起了情境感知的服务QoS 预测方法[12-20].
基于内存的方法根据历史QoS 数据挖掘用户之间和服务之间的相似性,基于与当前用户相似的用户对目标服务的QoS 和当前用户对与目标服务相似的服务的QoS 对当前用户使用目标服务的 Q oS 做出预测.如 S hao 等人[4]基于用户在相同的服务上的相似经历提出了基于相似用户的个性化服务预测方法.Zheng 等人[5]集成了用户和服务的相似性对当前用户调用目标服务的QoS 进行预测.Jiang 等人[6]在度量用户或服务的相似性时考虑了共同用户或者共同服务的标准差.李昆仑等人[7]通过将用户评分的均值差引入对用户相似度的计算,将相似的两个向量的均值引入对向量缺失值的填充并实现降维,基于改进的用户相似性度量和评分预测的提出了一种协同过滤推荐算法.这类基于内存的服务QoS 预测方法有较强的可解释性,然而在实践中,由于历史QoS 数据极其稀疏,相似用户或相似服务很难找到.
基于模型的方法从历史QoS 或者评分数据中学习隐藏在数据背后的QoS 或者评分模式,并建立模型对未知QoS 进行预测.Yu 等人[8]基于QoS 矩阵是低秩的或者近似低秩的假设提出了基范数正则化的矩阵分解方法对未知QoS 进行预测.Zhang 等人[9]提出了非负张量分解的方法来对基于时间的QoS 进行预测.Zheng 等人[10]集成了基于相似用户的方法与矩阵分解的方法对未知服务QoS 进行个性化预测.Ren和Wang[11]提出了基于SVM 的协同过滤方法SVM4SR 对未知服务的评分排序进行预测,进而实现服务推荐.文献[12]通过粒化思想对SVM4SR 进行优化,进一步提升模型的精度与效率.基于模型的方法总会在模型复杂度和预测准确度之间权衡,为了提升预测准确度而使用越来越复杂的模型.
情境感知的方法将用户-服务QoS 或评分数据之外的信息包含到协同过滤的方法中以进一步提高预测的准确度.如Chen 等人[13]利用位置信息对用户和服务聚类,基于聚类结果对QoS 进行个性化预测.唐明董等人[14]基于QoS 属性受用户位置影响的事实,提出了位置感知的Web 服务QoS 预测方法.Qiu 等人[15]基于历史数据感知用户的信任,识别并排除掉不可信用户,提高了 Q oS 值预测的准确度.Wang 等人[16]通过采用累积和控制图检测恶意反馈的等级,然后提出Bloom 过滤恶意反馈,减少信誉度量中的偏差.朱文强等人[17]、Deng 等人[18]通过评估用户在社区网络的信任关系,增强服务推荐的可信度.张鹏程等人[19]、申利民等人[20]感知环境要素随时间变化导致服务QoS 波动,分别提出一种基于时间序列分析的QoS 预测方法.情境感知的方法就各自所关心所感知的方面预测精度都有所提高.
综上所述,这些研究都是非常有意义的工作,为提升未知服务的个性化QoS 预测的准确性做出了很大贡献.然而,这些研究主要针对传统的Internet 环境,认为同一个用户使用相同的服务其QoS 值就是确定的.然而,在移动环境中,由于用户的位置移动可能引起边缘服务器的切换,使得接收信号发生变化,导致同一用户多次使用相同的服务其QoS 也不尽相同,因此传统方法的 Q oS 预测值就会出现较大的偏差[21,22].
边缘计算模型将原有云计算模型执行的部分或者全部计算任务迁移到边缘设备上,为移动计算等相关技术提供了一个更好的计算平台[1].因此,本文考虑边到缘计算环境中移动用户位置的改变会导致所访问的边缘服务器的切换,提出了移动边缘计算环境中服务QoS 预测方法(EQoSP,Edgecomputing QoS Prediction),在对服务的QoS 值进行预测时考虑当前用户所访问的边缘服务器.希望能得到更准确的QoS预测值,为移动边缘环境中服务推荐和服务选择提供依据.
2 相关工作
传统的服务QoS 预测方法,没有考虑移动边缘计算环境中用户通过访问不同的边缘服务器使用同一服务,预测QoS值的偏差可能较大.为解决这一问题,已有不少研究致力于移动网络环境的服务QoS 预测.
Chen 等人[13]提出了区域相似性的概念,并通过 I P 地址来检索相似用户的位置,利用位置信息和QoS 值对用户和服务进行聚类,并根据聚类结果对用户进行个性化服务推荐,IP地址的引入体现了该方法对网络位置的感知,从而为用户推荐其所在位置QoS 最优的服务.Deng 等人[21]感知用户移动导致接收的网络信号的变化,在对移动服务QoS 的计算模型中考虑了输入输出所需的时间,提出了移动环境下服务组合中的组件选择的方法,该方法感知用户移动中接收到的网络信号强弱不同,导致输入输出的时间不同,从而选择最适合当前位置的组件服务.Wang 等[22]为实现边缘服务器计算环境下的移动服务推荐,基于用户的移动性,通过相似用户和相似边缘服务器的历史QoS 数据对用户位置发生移动后的服务QoS 进行预测.文中的相似用户和相似服务器都采用Top-k个,然而实践中固定的k 值如果太小容易损失部分相似信息,反之如果k 值太大就会将一些并不相似信息考虑在内,影响QoS 预测的准确性.
不同于上述研究,本文不使用传统的固定的Top-k 相似用户和相似服务的个数,而是基于历史QoS 通过聚类自然地个性化地为每个用户和边缘服务器确定相似用户和相似边缘服务器的个数,以求更准确的服务QoS 预测.
3 本文方法
本文首先通过聚类分析为当前用户/边缘服务器寻找相似用户/边缘服务器,然后计算相似用户与当前用户及相似边缘服务器与当前边缘服务器之间的相似度,最后基于相似用户/边缘服务器的历史QoS 数据对当前用户在当前边缘服务器附近使用目标服务的QoS 进行预测.
本节首先通过一个情景案例说明边缘计算环境的QoS 预测的两种不同情形,然后给出模型定义,通过聚类确定相似用户/边缘服务器的方法,以及用户之间/边缘服务器之间相似性的度量方法,最后给出两种不同情况下未知QoS 的预测方法.
3.1 情景案例
设想用户u 经常用手机通过访问边缘服务器e1来调用服务s,现在用户u 来到另一个边缘服务器e2的附近,但他仍然想用服务s.我们需要通过对用户在边缘服务器e2附近使用服务s 的QoS 预测,决定访问边缘服务器e2还是周围其他边缘服务服务器.此时,有如下两种情况[22].
情况1.边缘服务器e2上有服务s 的调用历史QoS 数据;此时,我们需要通过e2上s 的历史QoS 值预测用户使用服务s 的 Q oS 值.
情况2.边缘服务器e2上不存在服务s 的调用历史QoS记录.此时,我们需要通过周边其他边缘服务器预测用户访问服务s的QoS值.
3.2 模型定义
定义1.用户(User)在这里是一个广义的概念,指移动边缘计算环境中的所有终端设备,包含移动设备,可移动的物联网设备等.一个用户可以被形式化为一个二元组(ui,UQo-Si),其中:
ui是用户i 的标识,通过用户标识可以唯一地确定一个用户;
UQoSi是用户i 在移动边缘计算环境中使用服务的历史QoS 记录.
定义2.服务(Service)在这里特指可以通过移动终端设备访问的资源.一个服务可以形式化为一个三元组(si,fun,SQoSi),其中:
si是服务i 的标识,通过服务标识可以唯一地确定一个服务;
fun 是服务的功能分类号,通过fun 可以确定调用该服务可以实现的功能;
SQoSi是服务i 在移动边缘计算环境中被用户调用的历史QoS 记录.
定义3.边缘服务器(Edge Server)是分布在终端设备和云之间靠近移动终端的边缘节点.一个边缘服务器可以被形式化为一个三元组(ei,Loc,EQoSi),其中:
ei是边缘服务器i 的标识,通过边缘服务器标识可以唯一地确定一个边缘服务器;
Loc 是边缘服务器的部署位置,位置决定边缘服务器的服务覆盖范围;
EQoSi是通过访问边缘服务器i 调用服务的QoS 历史记录.
3.3 相似用户/边缘服务器的确定
本文采用k-means++聚类的方式分别对用户空间和边缘服务器空间进的历史数据进行分析.
K-means 算法因实现简单且运算速度快,成为一种最常用的无监督聚类算法,其基本思想是:按照样本之间的距离大小,将给定的样本集划分为k 个簇(cluster),力求簇内样本点尽量紧密,而簇间距离尽量大.设样本集被划分为k 个簇Ci(i=1,2,…,k),则 k-means 算法的目标是最小化平方误差,其中是簇 Ci的质心.质心的选择对最后的聚类效果和运行时间有很大的影响,如果仅仅是完全随机地去选择,有可能导致算法收敛很慢.因此,本文采用k-means++算法,随机地选取第一个质心,在选取第n+1 个聚类中心时,距离当前n 个聚类中心越远的点会有更高的概率被选为第n+1 个聚类中心,优化对质心的选择.此外,类簇个数k 值的确定也是这类算法的关键.由于在聚类之前用户和边缘服务器可能的类簇个数并不确定,因此,本文采用如式(1)定义的 DB 指数(Davies-Bouldin Index,DBI)作为聚类的优化目标.
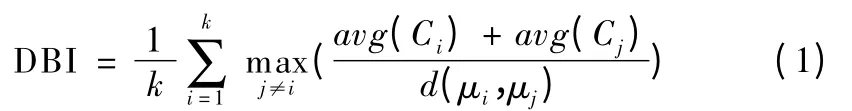
其中,avg(Ci)代表类簇Ci内样本间的平均距离,d(μi,μj)是类簇Ci与Cj的质心μi与μj之间的距离.可以看出,类内距离越小而类间距离越大时DBI 越小,因此,本文选择使DBI 取最小值的k 作为类簇个数.


在进行聚类前,本文首先构造用户数据集U.历史QoS 数据集HQoS 是一个m×n×l 的3 阶张量,其中第1 维代表 m个用户,第2 维代表n 个服务,第3 维表示l 个边缘服务器.其每个元素 HQoSi,j,f表示在第 f 个边缘服务器上用户 i 调用服务j 的QoS 值,没有调用记录的记为0.可以将张量HQoS转换成矩阵U,其中U 的每一行ui由HQoS 中用户i 在不同边缘服务器上对每一个服务调用的QoS 记录构成,故ui是一个包含n×l 个元素的行向量.所以,算法1 的输入U 是一个m行n×l列的矩阵.
对于边缘服务器空间的聚类,我们首先通过 qes=求该边缘服务器每个服务的平均QoS 值,其中qus是用户u 通过边缘服务器e 访问过服务s 的QoS 值.由各服务的平均QoS 值构成该边缘服务器的样本数据,故边缘服务器聚类的输入数据为l 行n 列的QoS 矩阵.聚类方法与用户空间聚类的方法类似,不再赘述.
3.4 相似性计算
对于情况1 所描述的情景,边缘服务器e2上有服务s 的历史QoS 记录.此时,用户u 在边缘服务器e1上使用服务s的历史QoS 数据已经失效,我们需要在边缘服务器e2的历史记录中为用户u 找相似用户,根据相似用户使用服务s 的QoS 预测用户u 使用服务s 的QoS 值.
在边缘服务器e2的历史记录中查找使用过服务s 的用户,在这些用户中过滤出当前用户u 的同一类簇的相似用户,用如式(2)所示的改进的PCC(Pearson correlation coefficient,皮尔逊相关系数)来计算用户a 与用户u 之间的相似度.

对于情况2 所描述的情景,边缘服务器e2上没有服务s的调用记录.此时,我们需要在边缘服务器e2附近搜索与边缘服务器e1相似且存有服务s 的历史QoS 数据的边缘服务器,根据相似边缘服务器上相似用户使用服务s 的QoS 记录预测用户u 使用服务s 的QoS 值.
搜索边缘服务器e2周边的其他边缘服务器,这里可以根据实际情况设置一个半径阈值r 确定搜索范围.在这些边缘服务器中过滤出与边缘服务器e1同一类簇且存有服务s 的QoS 记录的边缘服务器.用如式(3)所示改进的PCC 来计算边缘服务器b 与边缘服务器e 之间的相似度.
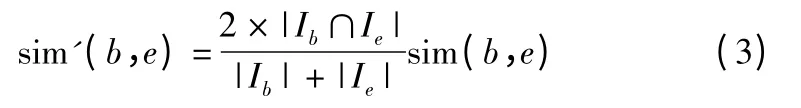
3.5 QoS 预测
对于情况1 所描述的情景,能为预测用户u 调用服务s提供数据的用户a,需要既是用户u 的同类簇用户C(u)中的用户,又是通过边缘服务器e2访问过服务s 的用户U(e2,s)中的用户.因此,用户u 通过边缘服务器e2访问服务s 的QoS值可以通过式(4)进行预测.
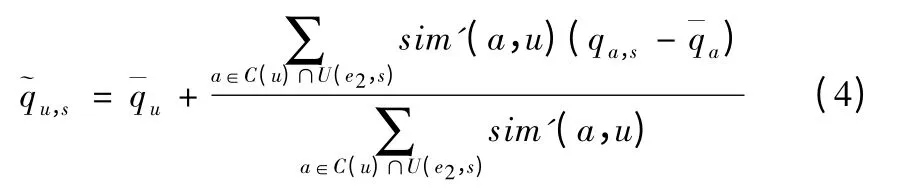
对于情况2 所描述的情景,能提供数据的边缘服务器b,需要满足既是边缘服务器e1的同类簇边缘服务器,又是在边缘服务器e2附近且存有服务s 的访问记录的边缘服务器.因此,此时根据相似边缘服务器对用户u 使用服务s 的QoS 值可以通过式(5)进行预测.
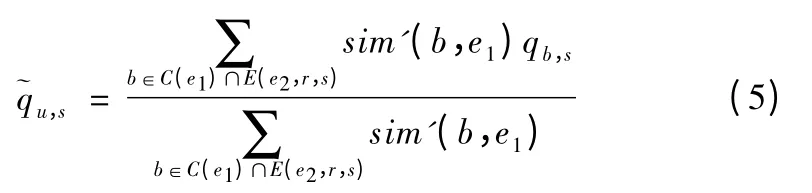
因此,对于情况1,用户当前所在边缘服务器e2上存在服务s 的调用记录,则从用户u 所在的类簇中挑选所有通过边缘服务器调用过服务s 的用户,基于他们使用服务s 的QoS 值 ,预测用户u 使用服务s 的QoS 值.对于情况2,用户当前所在边缘服务器e2上存在服务s 的调用记录,则从边缘服务器e1所在的类簇中挑选所有与边缘服务器e2的距离小于r,且有服务s 的调用QoS 数据的边缘服务器,基于这些边缘服务器上服务 s 的的 QoS 值,预测用户使用服务 s 的 QoS 值.


据算法2,在用户位置发生移动,边缘服务器发生切换后,可对用户在新位置能够得到的QoS 进行预测.
3.6 一个例子
本节用一个简单的例子,进一步阐释本文的方法.
假如有 5 个用户{u1,u2,u3,u4,u5},3 个服务{s1,s2,s3},以及4 个边缘服务器{e1,e2,e3,e4},每个边缘服务器上的QoS 历史数据分别为:

用户u4之前使用过服务s1和s2,现在用户到了边缘服务器e4附近,需要调用服务s2,可以看到用户u4没有通过e4调用过服务s2,但是服务s2有通过边缘服务器e4使用的记录,符合情况1 的场景.
经用户空间聚类得用户u4的相似用户为u3和u5.根据式(2)求得用户u4与相似用户u3、u5的相似度分别为:sim'(u3,u4)=0.5227,sim'(u5,u4)=0.7379,带入式(4)可以计算出用户 u4通过访问 e4调用服务 s2的预测 QoS 值为:.
现在用户u4又到了边缘服务器e2附近,想调用服务s1,可以看出在边缘服务器e2上没有服务s1的使用记录,符合情况2 的场景.
经边缘服务器空间聚类,边缘服务器e2与边缘服务器e1与e3均相似,假设边缘服务器e1与e2相距较远,因此只能根据距离较近的边缘服务器e3上服务s1的历史QoS 记录进行预测,依次将数据代入式(3)与式(5),求得用户u4在边缘服务器 e2附近调用服务 s1的预测 QoS 值为.
4 实验结果及分析
为了验证EQoSP 的有效性,实验部分首先通过聚类分析确定相似用户和相似边缘服务器,然后与几种典型的QoS 预测方法比较预测的准确度.
仿真实验在MATLAB R2018a 环境运行,操作系统Windows 10 64 位,处理器是 Intel Core i7,3.6GHz,内存 16GB.
4.1 数据集描述
因为响应时间是QoS 属性中受移动环境最大的属性,所以本文采用香港中文大学博士郑子彬等人的研究成果WSDREAM 数据集中的Dataset 3[8]中响应时间数据 rtRate 作为QoS 数据.该数据集包括142 个用户在64 个不同的时间对1500 个Web 服务访问的响应时间记录,每一个的访问时间,都形成一个142×1500 的响应时间矩阵.本文将该数据集稀疏化为不同的数据密度5%、10%、15%和20%,以模拟真实环境中的QoS 数据,同时,本文将每个不同的时刻的数据当作不同边缘服务器的数据,并且将访问时间的邻近关系当成边缘服务器的邻近关系.
4.2 度量标准
平均绝对误差MAE(Mean absolute error)和均方根误差RMSE(root mean squared error)是最常用来度量预测值与真实值之间的差异的两个指标.本文采用MAE 和RMSE 来评估所提出的QoS 预测方法的准确性.MAE 和RMSE 的定义分别如式(6)和式(7)所示:
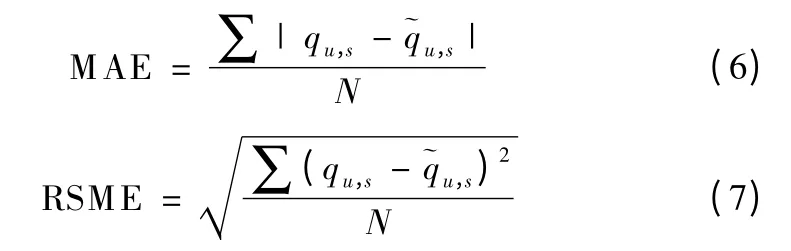
其中,qu,s是用户 u 使用服务 s 的真实 QoS 值,表示用户u 使用服务s 的QoS 的预测值,N 是所预测的QoS 值的个数.MAE 和RMSE 的值越小表示预测值越准确.
4.3 聚类个数的确定
为了根据数据本身的特性自然地确定相似用户和相似边缘服务器的个数,本文首先对用户空间和边缘服务器空间进行聚类.为确定合适的类簇个数,本文采用如式(1)所示的DBI 作为聚类的度量指标,DBI 越小说明类内聚类越小而类间距离越大,说明聚类效果越好.
由于实际情况中QoS 数据非常稀疏[10],类簇个数太多可能导致某些用户很难找到相似用户或者相似边缘服务器,所以本文让类簇个数k 从2 变到20.图1 是用户空间的聚类结果.从图1 可以看出 k=15 时,DBI 最小,其值为 0.0716,聚类效果最好,因此本文后续实验中,相似用户的确定以k=15时的聚类结果为依据.
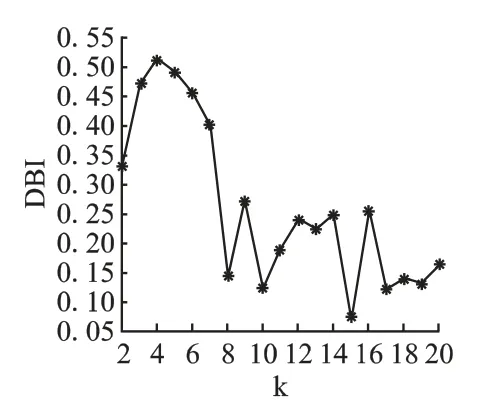
图1 不同用户类簇个数时的DBI 值Fig.1 DBI of different numbers of user clusters
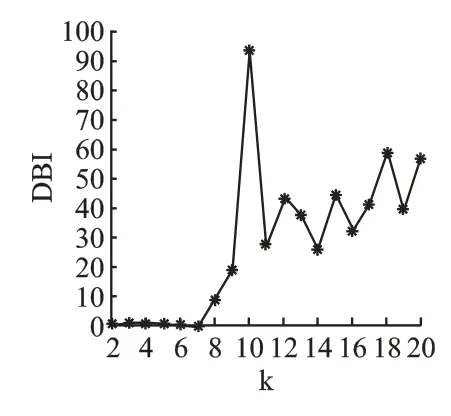
图2 不同边缘服务器类簇个数的DBI 值Fig.2 DBI of different numbers of edge sever clusters
图2 是边缘服务器空间的聚类结果.由于边缘服务器个数较少,所以本文让类簇个数k 从2 变到20.从图2 可以看出k=7 时,DBI 最小,其值为 0.0026,聚类效果最好,因此本文后续实验中,边缘服务器的聚类个数k 值取7.
4.4 预测准确性比较
本文以MAE 与RSME 作为预测QoS 值准确性的度量.与本文方法进行比较的方法如下:
UPCC[4]是基于相似用户的协同过虑预测方法,用户之间的相似度以PCC 来度量.利用当前用户的相似用户使用目标服务的QoS 值来对当前用户使用目标服务的QoS 进行预测.
UIPCC[5]以PCC 来度量用户之间和服务之间的相似度,并利用当前用户对与目标服务相似的服务的调用QoS 值和与当前用户相似的用户对目标服务调用的QoS 值对当前用户使用目标服务的QoS 进行预测.
UEPCC[22]是针对边缘计算环境下的 QoS 预测方法,该方法同时考虑用户之间和边缘服务器之间的相似性.取Topk 相似用户和相似边缘服务器提供的数据预测移动用户位置发生移动后使用目标服务可能获得的QoS 值.
实验中,本文从数据集中随机地选择两个边缘服务器作为边缘服务器e1和e2,对e1上已知而e2上未知的用户-服务QoS 数据进行预测.表1 是本文方法EQoSP 与上述方法的MAE 与 MRSE 值的比较.
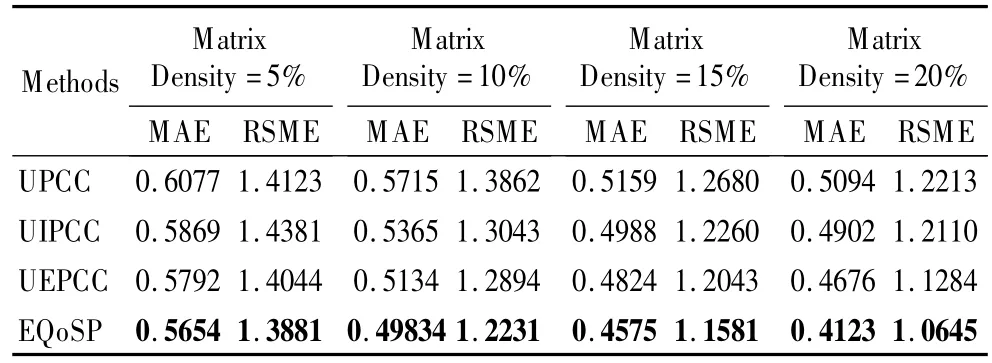
表1 预测QoS 值准确度比较Table 1 Accuracy comparison of predicted QoS values
从表1 可以看出,随着矩阵密度从5%增加到20%,所有的方法的MAE 值与MRSE 值都在逐渐减小,说明已知数据越多,预测值越来越准确.固定矩阵密度为5%,10%,15%和20%可以看出,相比较而言,本文的方法的MAE 和MRSE 值都是最小的.这是因为本文方法既考虑了用户的移动性,又能依据数据本身的特性以一种较为自然的方式个性化地确定相似用户和相似边缘服务器.
4.5 仿真实验
为了验证所提出方法在真实环境下的有效性,进行了如下仿真实验.17 个用户在山西大学校园分布的8 个基站(模拟边缘服务器)附近分别访问计算中心的服务器,记录响应时间.所采集的有效数据构成的响应时间矩阵密度为d=35.29%.
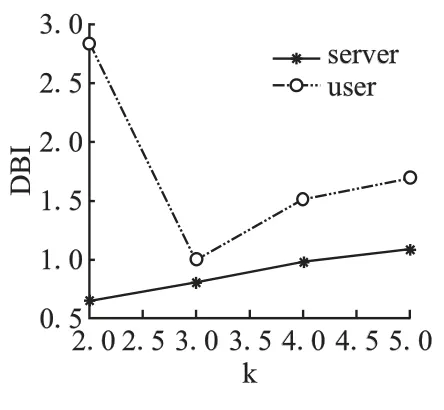
图3 用户/边缘服务器聚类情况Fig.3 DBI of differentnumber of clusters
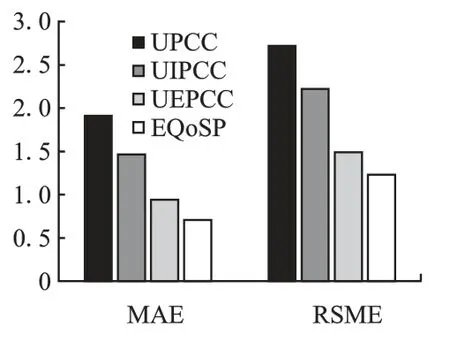
图4 不同方法的预测准确度比较Fig.4 Accuracy comparison of different methods
图3 是仿真数据集上分别对边缘服务器和用户的聚类情况.用户和边缘服务器聚类个数分别采用k=2,3,4,5.
从图3 可以看出,当k=2 时,边缘服务器的聚类效果最优,k=3 时用户的聚类效果最优.因此,后续实验中服务器分成2 类,用户分成3 类.
图4 所示是上述几种方法在仿真数据集上预测QoS 的MAE 和 RSME.
从图4 可以看出,UEPCC 和EQoSP 的预测值误差都有较小,这两种方法都是针对边缘计算环境的QoS 的预测.而本文提出的EQoSP 的MAE 和RSME 比UEPCC 方法的MAE和RSME 又小一些,这是因为EQoSP 没有采用固定个数的对相似用户和相似边缘服务器,而是通过对历史数据的聚类分析,根据数据本身的特性自然地确定相似用户和相似边缘服务器,从而使得QoS 预测值更加准确.
5 结 论
本文提出了一种边缘计算环境中的移动服务QoS 预测方法.考虑到移动用户的位置改变会导致所访问的边缘服务器切换.当用户位置发生移动时,本文根据切换后的边缘服务器上是否有目标服务的访问记录,分两种不同的情况对用户使用服务的QoS 进行预测.此外,不同于以往的固定的Top-k个相似用户和相似服务器的方法,本文通过用户空间和边缘服务器空间的聚类,提出一种按照数据本身特性自然地确定相似用户和相似边缘服务器的方法.在真实数据集上的实验结果表明,本文的方法有更高的QoS 预测精度.
尽管本文的方法在仿真环境下提高了边缘服务器环境下服务QoS 值预测的准确度,然而实际的边缘计算环境更为复杂,比如服务QoS 不可能是固定值,可能会随着时间发生演化.在未来的研究中,我们将把时间因素考虑在模型之中,提高模型在真实环境中的适应性.
猜你喜欢
消费电子(2022年7期)2022-10-31
数字技术与应用(2017年9期)2017-12-07
智能计算机与应用(2016年6期)2017-05-08
通信产业报(2016年44期)2017-03-13
中国信息化·学术版(2013年1期)2013-05-28
智能计算机与应用(2007年4期)2007-08-25
电子设计应用(2004年6期)2004-07-27
雕塑(1999年2期)1999-06-28
雕塑(1996年2期)1996-07-13
雕塑(1996年4期)1996-07-12
