
一种基于自适应非极大值抑制的文本检测算法
2020-06-04 12:55陈泽瀛
数字技术与应用 2020年3期
陈泽瀛


摘要:场景文本检测是场景文本识别系统的重要步骤,也是一个具有挑战性的问题。与一般对象检测不同,场景文本检测的主要挑战在于自然图像中文本的任意方向,较小的尺寸以及显著不同的宽高比。本文提出了一种名为SANTD( Self-adaptive NMS Text Detection)可端到端训练的文本检测模型,该检测模型可以在单个网络中精确、高效地检测任意方向的场景文本。同时,本文还对非极大值抑制做了修改,使其可自适应地检测文本框附近的密度值。在评估实验中,SANTD在准确率和召回率上都表现出了一定的优势。在数据集ICDAR 2015上,SANTD以11.6fps得到84.3%的值。
关键词:文本检测;自适应;非极大值抑制;卷积神经网络
中图分类号:TP391 文献标识码:A 文章编号:1007-9416(2020)03-0117-04
0 引言
场景文本是自然场景中最常见的视觉对象之一,经常出现在道路标志、车牌、广告牌、产品包装上。尽管自然场景下的文本检测与传统的OCR相似,但由于文本的多样性、背景的复杂性以及无法控制的光照条件等因素,使得场景文本阅读更具挑战性,如文献[1]所述。近年来,场景文本检测已经得到了广泛的研究[1-3],并且随着目标检测、语义分割的迅速发展,近来取得了明显的进步。这些场景文本检测器主要可以分为两类。一类是基于目标检测(如SSD[4]、YOLO[5]、DenseBox[6])直接预测候选边界框的文本检测算法如TextBoxes[7],FCRN[8]和EAST[9]。第二类是基于语义分割,例如文献[10]和文献[11],它们生成分割图并通过后期处理生成最终的文本边界框。
本文基于目标检测算法SSD通过端到端可训练的单个神经网络直接预测具有四边形的单词边界框来检测文本,并在网络中构建自适应非极大值抑制算法,称之为SANTD。
本文用四边形代替传统目标检测中的矩形框来表示文本区域,同时为了识别较长的文本区域,加入“长条形”卷积核来预测文本区域边界框。SANTD通过联合预测文本是否存在和锚点框坐标偏移,直接在多层输出文本边界框,然后输出所有锚点框经过可学习非极大值抑制后的锚点框。在网络中,单个前向网络可以检测图像上的多尺度文本框。该检测器在速度上具有很大优势。
1 相关工作
1.1 文本检测
场景文本阅读系统通常由文本检测和文本识别两部分组成。前一个组件主要以单词边框的形式在图像中定位文本。后者将文字图像裁剪成机器可解释的字符序列。在本文中,我们涵盖了这两个方面,但更多的是关注检测。一般来说,大多数文本检测器可以根据原始检测目标和目标包围盒的形状,按照两种分类策略大致分为几类。
1.1.1 基于回归的文本检测
在过去两年中,基于回归的文本检测已成为场景文本检测的主流。基于普通目标检测器,提出了几种文本检测方法,并取得了实质性进展。源自SSD[4]的TextBoxes[7]使用“长”默认框和“长”卷积核来应对极端的宽高比。同样,在文献[12]中,Ma等人利用Faster-RCNN[13]的体系结构,并在RPN中添加旋转锚点以检测面向任意方向的场景文本。SegLink[14]基于SSD网络预测文本分割区域和区域间链接,并将这些分割区域链接到文本框,以便在自然场景中处理长方向的文本。基于DenseBox[6],EAST[9]直接使文本框回归。
本文基于目标检测算法DSSD[15],与上述直接回归文本框或直接分割的方法不同,我们定位文本框角点的位置,然后通过对检测到的角进行采样、分组和引入可学习非极大值抑制来生成文本框。
1.1.2 基于分割的文本检测
基于分割的文本检测是文本检测的另一个方向。受FCN[16]的启发,提出了一些使用分割图来检测场景文本的方法。在文献[10]中,Zhang等人第一次尝试由FCN从分割图提取文本块。然后,他们使用MSER[17]检测这些文本块中的字符,并通过一些先验规则将字符分组为单词或文本行。在文献[11]中,Yao等人使用FCN来预测输入图像的三种类型的地图(文本区域,字符和链接方向)。然后进行一些后处理以获得带有分割图的文本边界框。
1.1.3 基于角点的目标检测
基于角点的目标检测是目标检测算法的一种新方式。在DeNet[18]中,Tychsen-Smith等人在Faster-RCNN风格的两阶段模型中,提出了一个角检测层和一个稀疏样本层来代替RPN。在文献[19]中,Wang等提出PLN(点连接网络),它使用完全卷积网络对边界框的角点、中心点及其连接线进行回归,然后使用角点、中心点及其连接线形成对象的边界框。
1.1.4 端到端文本检测器
端到端方法同时训练检测和识别模块,以便通过利用识别结果来提高检测精度。 FOTS[20]和EAA[21]将流行的检测和识别方法进行叠加,并以端到端的方式对其进行训练。Mask TextSpotter[22]利用他们的统一模型将识别任务视为语义分割问题。显然,使用识别模块进行训练可以帮助文本检测器对类似文本的背景识别更加鲁棒。
1.2 非极大值抑制
非极大值抑制(NMS,Non-Maximum Suppression)是计算机视觉中广泛使用的后处理算法。它是许多检测方法的重要组成部分,例如边缘检测[23],特征点检测和目标检测[13,24,25]。NMS廣泛应用于目标检测算法中,对于重叠度较高的一部分同类候选框来说,去掉那些置信度较低的框,只保留置信度最大的那一个进行后面的流程,其中重叠度通过NMS阈值衡量。
Soft-NMS[26]和Learning-NMS[27]被提出用来改善NMS的结果。Soft-NMS不会丢弃得分低于阈值的所有周围提议,而是通过增加邻居与得分较高的边界框的重叠程度来降低邻居的检测得分。文献[27]试图学习仅使用盒子及其分数作为输入的深层神经网络来执行NMS功能,但是该网络经过专门设计并且非常复杂。文献[28]提出了一个对象关系模块来学习NMS作为端到端通用对象检测器的功能。文献[29]用学习到的本地化置信度代替了在NMS过程中使用的提议分类分数,以指导NMS保存更准确的本地化边界框。与它们不同的是,本文建议将每个真实目标周围的密度作为自己的抑制阈值来学习,这与文字计数任务中的文字密度估计有一些相似之处。
2 SANTD
2.1 网络结构
本文使用基于VGG16的全卷积网络结构作为主干网络,使用类似于U-Net的构建方式聚合低卷积层特征,网络结构如图1所示。
SANTD继承了当前较为流行的VGG-16网络结构[30],保留了从Conv1_1到Conv5_3的卷积层,并将VGG-16的最后两个全连接层转换为两个卷积层(C6和C7)进行下采样[4]。在C7之后通过最大池化分成不同分辨率的另外四个卷积层,分为四个阶段(C8至C11)。然后,在C11之后加入多个上采样卷积层用来聚合不同感受野下的检测结果。最后,通过自适应非极大值抑制提取出文本框。综上所述,SANTD是完全卷积的结构,仅由卷积和池化层组成,所以SANTD可以在训练和测试阶段适应任意大小的图像。
2.2 自适应非极大值抑制
Greedy-NMS和Soft-NMS的设计都遵循着一个假设:当一个检测框与当前最大得分检测框重叠程度较高时,这个检测框是假阳性的可能性更大。这个假设用于目标识别时没有问题,因为在正常情况下目标很少会发生遮挡。但是,这种假设在拥挤的场景中则会有一定的偏差;在密集文字场景中,人类实例彼此高度重叠的检测框。为了适应密集文字场景检测,NMS应考虑:(1)远离的检测框,其误报的可能性较小,因此应予以保留;(2)对于高度重叠的相邻检测框,抑制策略不仅取决于与的重叠,而且还要判定此时是否位于拥挤区域。如果位于拥挤的区域,则其高度重叠的相邻检测框很可能是真实的,因此应给予较轻的惩罚或予以保留。但是对于稀疏区域的实例,惩罚应更高些。
本文将检测框的拥挤度定义为其他检测框与检测框重叠部分的最大值,如公式所示:
(1)
另外,本文将非极大值抑制的阈值进行调整,用与的较大值作为当前循环下的阈值如公式所示:
(2)
(3)
其中,表示检测框的自适应非极大值抑制阈值,表示检测框的拥挤度,表示检测框得分或经过前序非极大值抑制后的当前得分。当邻近检测框与检测框重叠区域小于时,阈值与传统NMS一致为超参数;当大于等于时,自适应NMS阈值将转变成,即当前。
自适应非极大值抑制算法如图2所示,从算法复杂度而言几乎与greedy NMS和soft NMS保持一致。自适应非极大值抑制的唯一额外消耗是一个包含个元素的列表,其中存储了每个检测框的拥挤度,对于今天的硬件配置而言,可以忽略不计。因此,自适应非极大值抑制算法对检测器的运行效率影响不大。
3 评估实验
为了验证该方法的有效性,我们在ICDAR2013和ICDAR2015公共数据集上进行了实验,并与其他方法进行了比较。
3.1 实验细节
SANTD在SynthText[8]上进行了预训练,然后在其他數据集(COCO-Text除外)上进行了微调。我们使用Adam优化模型,将学习率固定为。在训练前阶段,我们在SynthText上训练模型一个时间。在微调阶段,迭代次数由数据集的大小决定。
数据扩充我们使用与SSD相同的数据扩充方式。我们以SSD方式从输入图像中随机采样补丁,然后将采样补丁的大小调整为512×512。
我们的方法在PyTorch[31]中实现。所有实验都是在常规工作站上进行的(CPU:IntelXeonCPU E5-2650 v3 @ 2.30GHz; GPU:NVIDIA Tesla V100; RAM:64GB)。我们在4个GPU上并行训练具有32个批处理大小的模型,并在1个批处理大小的GPU上评估模型。
3.2 评估协议
用于文本检测和文本识别的经典评估协议都依赖于三个参数,它们分别是准确率(),召回率()和值()。
(4)
其中,和分别是命中框,错误框和错过的框的数量。对于文字检测时,如果预测框与真实框之间的大于给定阈值(通常设置为0.5),则将检测到的框视为命中框。文本端到端识别中的命中框不仅需要相同的限制,还需要正确的识别结果。由于需要在精度和召回率之间进行权衡,因此是性能评估中最常用评估值。
3.3 实验结果
3.3.1 检测水平方向文字
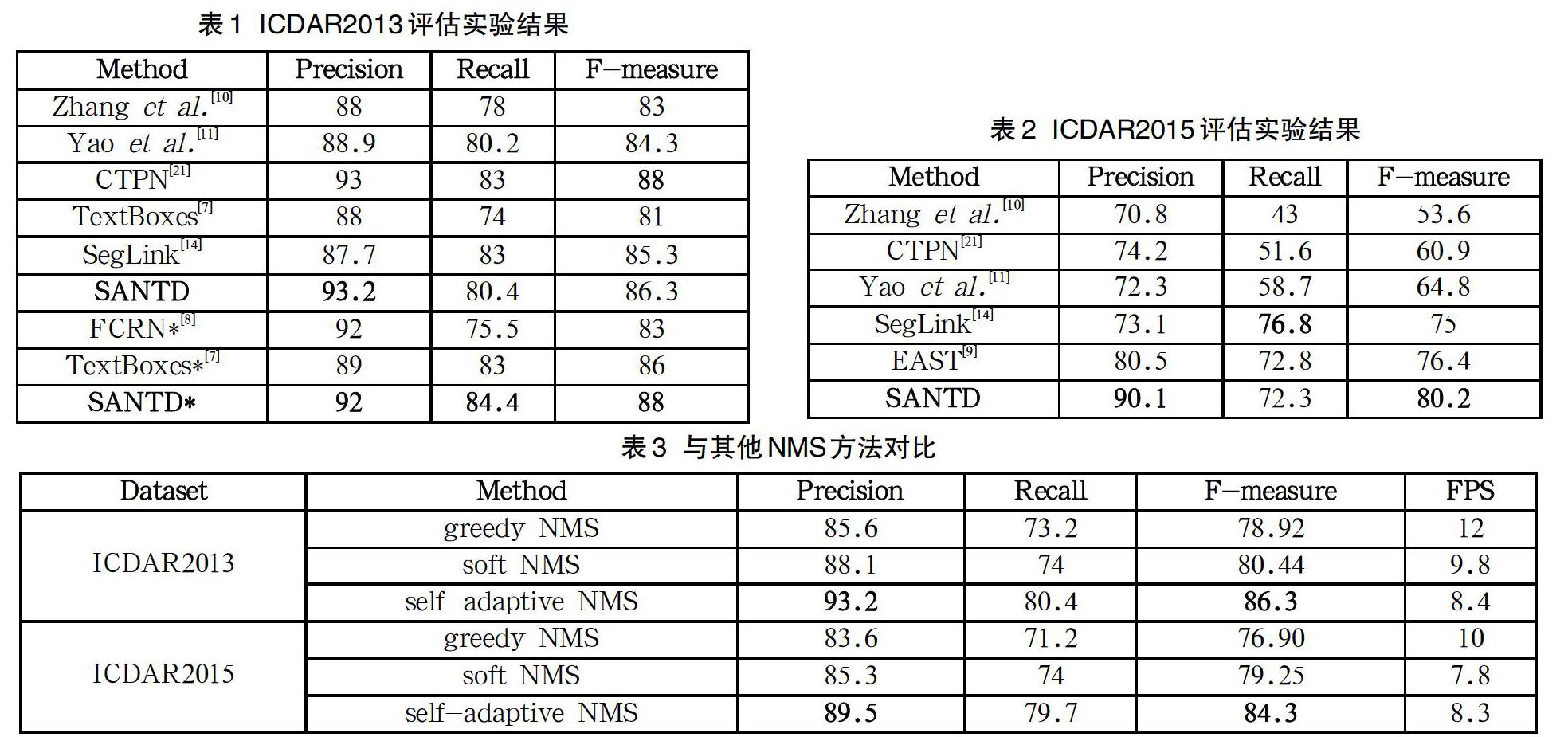
我们评估了模型在ICDAR2013数据集上水平文本的检测能力。在测试中,输入图像的大小调整为512×512。我们还使用多尺度输入来评估模型,表1中带*的部分是在多尺度下的评估结果,多尺度包括(512×512;768×768;768×1280;1280×1280)。
结果如表1所示,与大多数评估方式保持一致,使用“Deteval”方式进行评估。本文提出的算法在评估中取得了不错的结果。单次测试时,我们的方法达到了86.3%的值,略低于最高结果。在多尺度评估中,我们的方法达到了88%的值,与其他方法相比具备一定的竞争力。
3.3.2 检测任意方向文字
我们在ICDAR2015数据集上评估我们的模型,以测试其在任意方向文本检测方面的能力。我们在ICDAR2015和ICDAR2013的数据集上再微调。为了更好地检测垂直文本,在最近的15个epoch中,以0.2的概率将图像随机正向或逆向旋转90度。
本文将SANTD与其他方法进行了比较,并在表2中列出了评估实验结果。从表2中可以看出SANTD优于其他方法。在单次测试中,SANTD达到了80.2%的值,超过了所有其他文献[9-11,14,21]中的算法。
3.3.3 与其他NMS对比
为了验证自适应非极大值抑制的有效性,本文使用同样的网络结果,只在最后一步非极大值抑制做相应变化,分别在ICDAR2013和ICDAR2015两个数据集上进行评估实验,实验结果如表3所示。
由表3可見,自适应非极大值抑制不管是在数据集ICDAR 2013上还是ICDAR2015都表现出了不错的成绩,同时在FPS上也并没有太多差别。
4 结语
本文提出一种自适应非极大值抑制的,并且可以检测任意方向文本的检测算法SANTD。该算法快速、高效且可端到端训练。在未来的工作中,我们希望以端到端的方式加入文字识别模型,同时训练文本检测和文本识别模型,由此或许可以让检测和识别都能表现得更加准确、高鲁棒性和更强的可推广性,使其转化为一个更好的场景文本发现系统,从而可以更广泛地应用到生产生活中去。
参考文献
[1] Bissacco A,Cummins M,Netzer Y,et al.PhotoOCR:Reading Text in Uncontrolled Conditions[C]//2013 IEEE International Conference on Computer Vision(ICCV).IEEE,2013:785-792.
[2] Epshtein B,Ofek E,Wexler Y.Detecting Text in Natural Scenes with Stroke Width Transform[C]//Computer Vision and Pattern Recognition (CVPR),2010 IEEE Conference on.IEEE,2010:2963-2970.
[3] Yao C,Bai X,Liu W,et al.Detecting Texts of Arbitrary Orientations in Natural Images[C]//IEEE Conference on Computer Vision & Pattern Recognition.IEEE,2012:1083-1090.
[4] Liu W,Anguelov D,Erhan D,et al.SSD:Single Shot MultiBox Detector[C]//European Conference on Computer Vision.Springer International Publishing,2016:21-37.
[5] Redmon J,Divvala S,Girshick R,et al.You Only Look Once:Unified,Real-Time Object Detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2016.
[6] Huang L,Yang Y,Deng Y,et al.DenseBox:Unifying Landmark Localization with End to End Object Detection[J].Computer Science,2015,37(9):682-689.
[7] Liao M,Shi B,Bai X,et al.TextBoxes:A Fast Text Detector with a Single Deep Neural Network[J].AAAI,2017:4161-4167.
[8] Gupta A,Vedaldi A,Zisserman A.Synthetic Data for Text Localisation in Natural Images[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2016:2315-2324.
[9] Zhou X,Yao C,Wen H,et al.EAST:An Efficient and Accurate Scene Text Detector[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2017:2642-2651.
[10] Zhang Z,Zhang C,Shen W,et al.Multi-Oriented Text Detection with Fully Convolutional Networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2016:4159-4167.
[11] Yao C,Bai X,Nong S.Scene Text Detection via Holistic,Multi-Channel Prediction[J].arXiv e-prints,2016:1606.09002.
[12] Ma J,Shao W,Ye H,et al.Arbitrary-Oriented Scene Text Detection via Rotation Proposals[J].ieee transactions on multimedia,2017(99):1.
[13] Ren S,He K,Girshick R,et al.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[14] Shi B,Bai X,Belongie S.Detecting Oriented Text in Natural Images by Linking Segments[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2017:3482-3490.
[15] Fu C Y,Liu W,Ranga A,et al.DSSD:Deconvolutional Single Shot Detector[J].arXiv e-prints,2017:1701.06659.
[16] Long J,Shelhamer E,Darrell T.Fully Convolutional Networks for Semantic Segmentation[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2014,39(4):640-651.
[17] Neumann L,Matas J.A Method for Text Localization and Recognition in Real-World Images[C]//Computer Vision-accv -asian Conference on Computer Vision.DBLP,2010:770-783.
[18] Tychsen-Smith L,Petersson L.DeNet:Scalable Real-time Object Detection with Directed Sparse Sampling[J].ICCV,2017:428-436.
[19] Wang X,Chen K,Huang Z,et al.Point Linking Network for Object Detection[J].arXiv e-prints,2017:1706.03646.
[20] Liu X,Liang D,Yan S,et al.FOTS:Fast Oriented Text Spotting with a Unified Network[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE/CVF,2018:5676-5685.
[21] Epshtein B,Ofek E,Wexler Y.Detecting Text in Natural Scenes with Stroke Width Transform[C]//Computer Vision and Pattern Recognition (CVPR),2010 IEEE Conference on.IEEE,2010:2963-2970.
[22] Lyu P,Liao M,Yao C,et al.Mask TextSpotter:An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2018(10):1.
[23] Rosenfeld A,Thurston M.Edge and Curve Detection for Visual Scene Analysis[J].IEEE Transactions on Computers,1971,C-20(5):562-569.
[24] Lin T Y,Goyal P,Girshick R,et al.Focal Loss for Dense Object Detection[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,42(2):318-327.
[25] Lin T Y,Dollár,Piotr,Girshick R,et al.Feature Pyramid Networks for Object Detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2016:936-944.
[26] Bodla N,Singh B,Chellappa R,et al.Soft-NMS--Improving Object Detection With One Line of Code[C]//2017 IEEE International Conference on Computer Vision (ICCV).2017:5562-5570.
[27] Hosang J,Benenson R,Schiele B.A Convnet for Non-maximum Suppression[C]//German Conference on Pattern Recognition. Springer International Publishing,2016:192-204.
[28] Hu H,Gu J,Zhang Z,et al.Relation Networks for Object Detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE/CVF,2018:3588-3597.
[29] Jiang B,Luo R,Mao J,et al.Acquisition of Localization Confidence for Accurate Object Detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE/CVF, 2018:3588-3597.
[30] Simonyan K,Zisserman A.Very Deep Convolutional Networks for Large-Scale Image Recognition[J].Computer Science,2014:730-734.
[31] Pytorch[K].http://pytorch.org/.
Abstract:Scene text detection is an important step in a scene text recognition system, and it is also a challenging problem. Unlike general object detection, the main challenge of scene text detection is the arbitrary orientation of text in natural images, smaller sizes, and significantly different aspect ratios. In this paper, we propose an end-to-end training text detection model called SANTD (Self-adaptive NMS Text Detection), which can accurately and efficiently detect scene text in any direction in a single network. At the same time, this paper also modified the non-maximum suppression so that it can adaptively detect the density value near the box. In the evaluation experiment, SANTD showed certain advantages in both precision and recall. On the dataset ICDAR 2015, SANTD gets a value of 84.3% f-measure at 11.6fps.
Key words:text detection; self-adaptive; NMS; Convolutional Neural Network
猜你喜欢
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
中国教育信息化·基础教育(2016年11期)2016-12-27
汽车科技(2016年5期)2016-11-14
中国新通信(2016年16期)2016-10-18
