
基于深度学习的多属性盐丘自动识别方法
2020-06-03 07:46张玉玺张浩然吕文杰
石油地球物理勘探 2020年3期
张玉玺 刘 洋*③ 张浩然 吕文杰 薛 浩
(①中国石油大学(北京)油气资源与探测国家重点实验室,北京昌平 102249; ②中国石油大学(北京)CNPC物探重点实验室,北京昌平 102249; ③中国石油大学(北京)克拉玛依校区,新疆克拉玛依 834000; ④中海油研究总院,北京 100028)
0 引言
盐丘是一种重要的底辟构造[1],同时往往会伴随一系列断裂构造。这种断裂构造会使某种可渗透地层单元变为不可渗透地层单元,使盐丘具有良好的密闭性,为油气聚集和储存提供空间。因此盐丘的准确解释对于盐下储层的勘探与开发具有重要意义。然而,基于三维地震数据的盐丘解释仍具有挑战性。一方面,探测盐丘时,首先要确定陡倾的盐层沉积界面,即盐丘侧翼。但是由于盐丘形态复杂、地层倾角大,甚至会出现盐丘顶部直径明显大于下部,形如“蘑菇状”的情况,而盐丘速度又高于围岩,造成地震波场复杂及时间域构造畸变。另一方面,随着对盐丘的勘探程度逐渐提高,地震数据量不断增大、接收到的地震反射信号更复杂,导致解释工作难度大,多解性强,传统的多属性分析等方法已很难满足盐丘解释的需求。为了解决这些问题,人们相继提出了多种计算机辅助解释技术。Shi等[2]利用归一化割图像分割算法求取全局最优化问题的方法检测盐丘,但是计算成本高,不适用于实时地震解释[3]。Jing等[4]利用边缘检测技术识别盐丘边界,简单、高效。Aqrawi等[5]通过优化边缘检测技术,对样本设置不同权重组合样本,可更好地检测盐丘。但是基于边缘检测的盐丘识别技术仅在地震振幅变化剧烈时才能取得良好效果,而且单独使用地震振幅信息也不能全面地体现盐丘特征。
地震属性能较为直观地反映特殊的地质构造特征,因此属性技术被广泛用于盐丘解释。Berthelot等[6]提出基于纹理属性的盐丘检测方法。Shafiq等[7]提出利用纹理梯度(GOT)分别测量两个相邻时窗之间的纹理差异检测盐丘边界。此外,梯度结构张量[8]、曲率[9]、相似性[10]等地震属性陆续用于盐构造解释并取得一定效果。但基于地震属性的解释方法通常需要提取多种属性并且采用特殊的处理方式拾取地震信息,再进行精细解释得到最终结果,依赖于人工并且需要花费大量的时间,难以满足盐丘勘探、开发需求。深度学习技术得到迅速发展,并逐渐用于地震资料解释,自2018年始,深度学习技术在石油勘探领域掀起了研究热潮。Pham等[11]利用深度卷积神经网络检测河道;Di等[12]应用反卷积神经网络分析地震相,初步实现了地震相自动分类;Wu等[13]利用端到端的卷积神经网络自动识别三维断层。
为了提高盐丘解释精度并缩短工作周期,本文以深度学习技术为基础,以少量的二维地震数据为样本训练和测试模型,基本能自动分割盐丘,但仍存在一定误差。为了充分考虑不同地震属性特征,进一步减少误差,利用集成学习方法将不同地震属性模型融合并测试整个三维地震数据体。结果表明,该方法能有效减少误差,提高盐丘分类准确率。
1 网络结构
深度学习通过构建具有多个隐藏层的网络模型和海量数据挖掘数据深层特征。学习过程为逐层特征变换,将样本在原空间的特征表示变换到新特征空间,新空间能够刻画更丰富的数据内在特征,从而使分类或预测更准确。
图像识别和图像分割是深度学习极为重要的两个部分。图像识别通过给定一个滑动窗在图像上滑动,每一个滑动窗所在的小图像块被当作一个样本输入神经网络进行训练,从而识别滑动窗中心像素点,当遍历所有像素点就实现了对整个图像每一个像素点的分类。这种方法的缺点在于每一个像素点都需要取一个以自身为中心的图像块,而相邻两个像素点图像块相似度非常高,并且需要重复计算相同部分,造成了大量信息冗余,使网络训练速度变慢。另一方面,滑动窗尺寸的选取也需要兼顾计算效率与分类精度。当尺寸较大时,计算量增大,尺寸较小时,图像块只包含少量局部信息,可能导致错误的分类。图像分割是将整个图像作为输入进行模型训练,利用得到的模型对图像的每个像素点同时进行分类和定位,实现目标的精确分割。
文中将盐丘识别视为目标分割问题,在识别目标的同时圈定目标位置。基于编码—解码器结构[14]在计算机领域的出色表现,本文扩展了该结构并输入地震属性数据训练模型。
图1为编码—解码器网络结构,图2为特征图随网络结构的尺寸变化。由图可见: ①该网络为由20个卷积层(conv)组成的对称结构网络,编码器部分(左侧)的每个卷积层包含不同数量的卷积核并使用批量标准化算子(BN)和线性整流函数(ReLU),每次卷积运算之后产生多通道特征图(蓝色),通常在池化层(Max pooling)后,通道数成倍增加,特征图尺寸减半(图2),才能在减少网络参数的同时确左侧为用于提取输入特征的编码器部分,右侧为恢复空间信息及准确定位的解码器部分,与左侧对称。蓝色和红色分别表示多通道特征图和最大池化特征图;绿色和黄色分别表示上采样特征图和Softmax激活函数。蓝色下方的数字表示每一层的输入通道数(由试验确定),箭头表示左、右结构对称保提取的特征更具有代表性;②在每个上采样(Up-sampling)过程中,通道数减半,特征图尺寸加倍直至恢复至输入尺寸(图2),尺寸变化必须为整数。
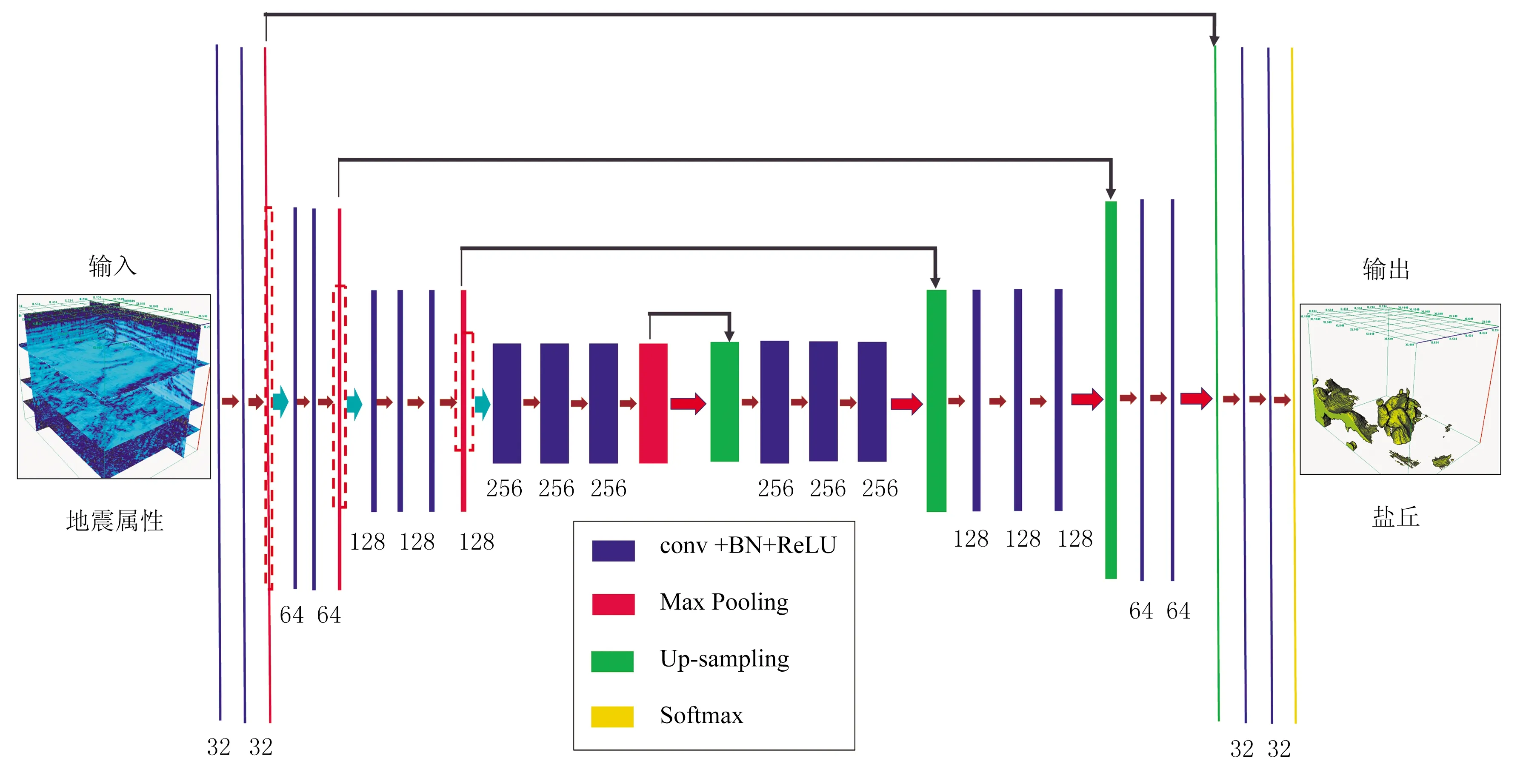
图1 编码—解码器网络结构
在网络结构中,卷积层数的设置应在保证模型准确率的前提下,降低训练成本,卷积层数过多可能导致模型训练过拟合现象。通道数决定了提取的特征,通道数越多,提取的特征越丰富,但通道数过多时,会增加网络参数,从而降低运算效率,并且可能发生过拟合现象。图3为卷积层数—模型训练时间—准确率关系、第一层卷积层通道数—准确率关系。由图可见:①当卷积层数为16和18时,模型训练的准确率较低;当卷积层数为20和22时,二者的准确率相近(分别为97.75%和98.04%),但后者准确率提高较小且需要更长的模型训练时间,因此将网络的卷积层数设置为20(图3a)。②完成4个Epoch后网络的准确率基本稳定;当通道数为32和64时,模型训练准确率较高且相近,因此选择第一层卷积层通道数为32。

图2 特征图随网络结构的尺寸变化
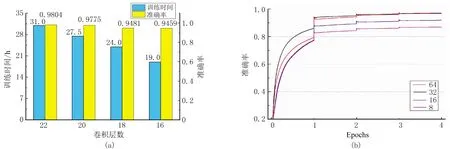
图3 卷积层数—模型训练时间—准确率关系(a)、第一层卷积层通道数—准确率关系(b)1个Epoch表示使用所有的训练数据完成一次训练,当完成一个Epoch后,模型得到一次更新
2 地震属性选取及预处理
盐丘通常呈圆柱形、锥形和穹隆形等,特殊的形态产生特殊的地震响应[15]。盐丘两侧地层反射中断,与围岩的界面表现为强振幅、低连续反射结构,盐丘内部呈杂乱或空白反射结构(图4a)。
2.1 属性选取
用于研究的数据为荷兰北海F3区块的三维地震数据,该区域沉积盆地构造演化经历了中生代的裂陷期和新生代裂后沉降期。古新世至上新世,盆地沉积了陆相、海陆过渡相以及海相地层,尽管该时期构造运动不活跃,但是依然发育盐丘底辟和区域不整合面[16]。基于盐丘的地震反射特征,选取杂乱(Chaos)、均方根振幅(RMS)以及方差(Variance)等3种敏感属性,每种属性包含两类样本,即主测线数据及时间切片(图4)。
2.2 数据预处理
数据包含563条主测线和768条联络测线数据,采样间隔为4ms,时间采样点数为384,时间记录范围为188~1720ms。由于人工标记标签耗时,为了提高工作效率,只选择少量典型数据进行标注。
具体步骤为: ①分别选取典型的15条主测线剖面和15个时间切片,选取的样本应兼顾整个数据体; ②借助属性分析等方法,人工解释样本并标注为标签,由于标签的准确性直接影响模型的预测性能,因此应尽可能准确地标注标签(图5)。
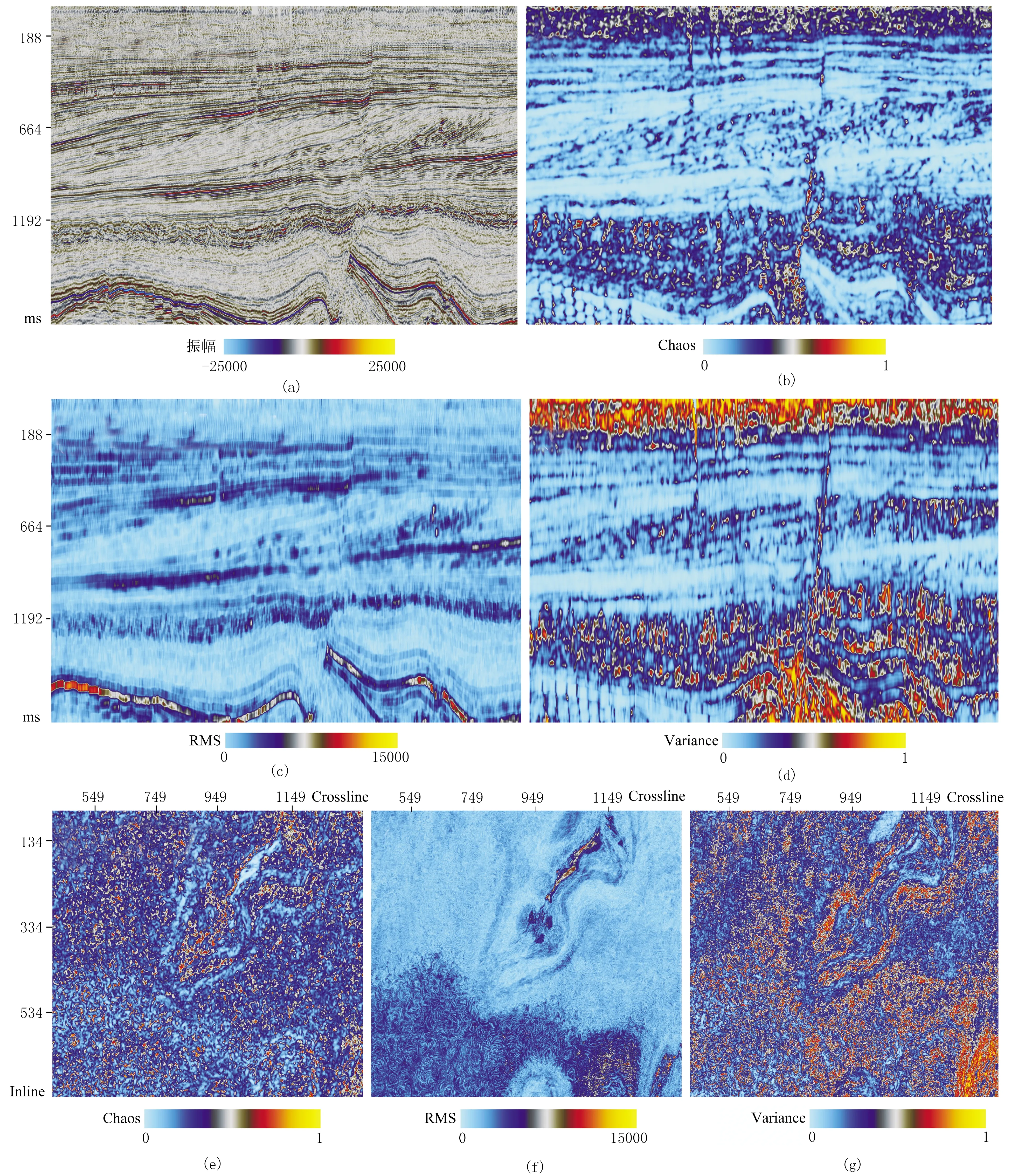
图4 原始地震剖面及选取的3种属性a)Inline285原始地震数据; (b)、(c)和(d)分别为Inline285的Chaos、RMS及Variance剖面; (e)、(f)和(g)分别为t=1364ms时刻的Chaos、RMS及Variance切片
2.2.1 镜像处理
由网络结构可知,在模型训练过程中样本尺寸变化必须为整数。然而,原始数据输入网络时往往不满足该条件,因此对训练数据使用镜像操作(图6)。首先计算满足要求的最小输入尺寸,以得到镜像参数。通过设置镜像参数拓展输入数据的尺寸,从而使网络能够接受任意尺寸的输入,意味着镜像操作可以提高网络的适用性。需注意的是,应保证对训练样本与标签进行相同的处理。
2.2.2 数据增强
深度神经网络需要大量训练数据以保证模型的性能。由于不同区域的地质环境和地下构造差异较大,因此目前没有通用的数据集。
人工解释并制作标签很耗时,且在小数据集上使用深度神经网络容易过拟合。为了解决该问题并获得高性能的预测模型,利用数据增强方法分别处理主测线剖面和时间切片的15个样本并自动生成70000个训练数据。
两组患者经治疗耳石症的眩晕和位置性眼震症状均有所改善,且治疗后四周时效果更明显,研究组患者根据患者病情选用不同复位手法,治疗疗效显著优于对照组,差异具有统计学意义(P<0.05),见表1。
数据增强是指对已有的训练样本进行一定的变换生成大量数据,其作用在于: ①增加训练的数据量,提高模型的泛化能力; ②利用多种变换以及添加噪声保证训练样本的多样性,有利于提升模型的稳定性并防止网络过拟合。本文主要应用角度旋转、沿y轴的镜像、模糊、光照等操作以及添加高斯和椒盐噪声,以不同的变换方式模拟不同地质条件的地震反射特征(图7)。

图5 Inline285原始地震剖面(a)及对应的标签(b)数字0表示非盐丘,1表示盐丘
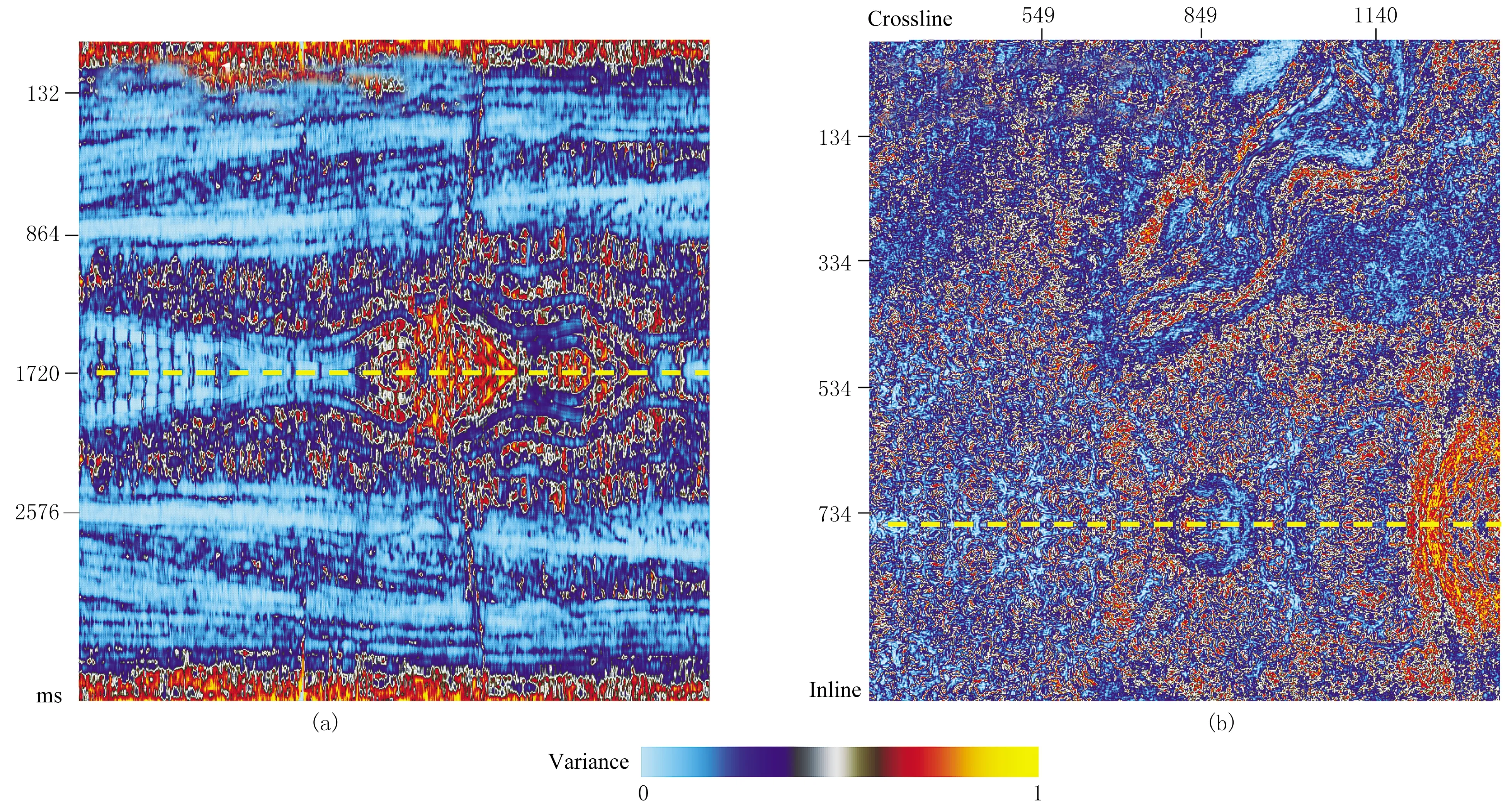
图6 镜像处理示例(a)Inline 285的Variance剖面; (b)t=1364ms时刻的Variance切片镜像处理结果黄色虚线为镜像边界

图7 数据增强示例(a)、(b)和(c)仅使用旋转操作; (d)、(e)和(f)使用旋转、模糊、光照操作及添加高斯和椒盐噪声
3 模型训练与测试
提取3种地震属性(每种属性包含两类样本)进行数据增强,将增强后的数据输入网络训练模型,得到6个模型和6个结果。在NVIDIA Tesla K40m GPU上模型的训练时间为27.5h。
表1为基于不同属性的模型预测准确率。由表可见,基于RMS属性的模型测试准确率最高,基于Chaos属性的模型测试准确率最低。图8为t=1692ms时刻不同切片的盐丘预测结果。由图可见,与标签(图8a)相比,3种切片均能预测盐丘的大致分布范围,但RMS切片的预测结果(图8b)误差点较Chaos切片(图8c)和Variance切片(图8d)少(图中红框位置)。图9为基于不同属性的三维盐丘预测结果。由图可见: ①利用单种属性进行模型训练能自动识别盐丘(图中黄色区域),但存在预测误差(图中红框位置); ②由主测线数据和切片得到的盐丘预测结果存在一定差异(图中蓝框位置); ③RMS属性三维盐丘预测结果误差点较少,Chaos属性三维盐丘预测结果有较多杂乱分布的预测误差。

表1 基于不同属性的模型预测准确率
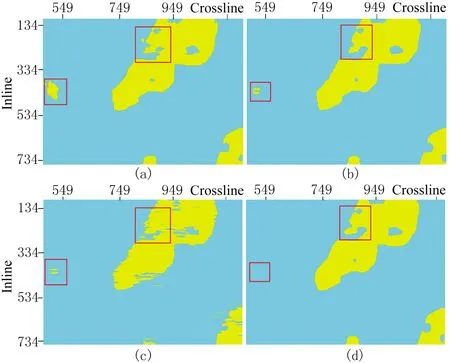
图8 t=1692ms时刻不同切片的盐丘预测结果(a)标签; (b)、(c)和(d)分别为RMS、Chaos和Variance切片预测结果黄色部分表示盐丘
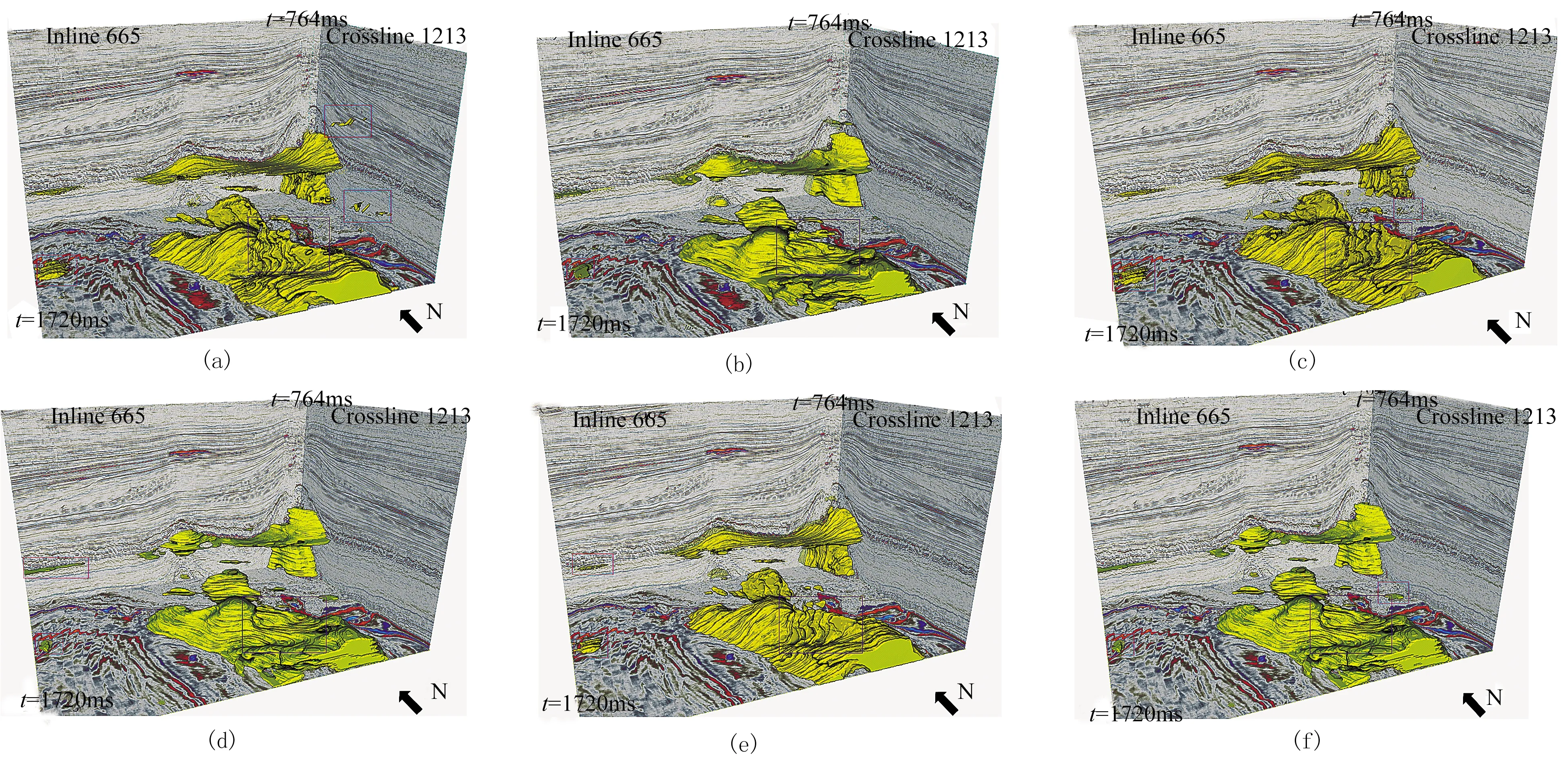
图9 基于不同属性的三维盐丘预测结果(a)RMS剖面; (b)RMS切片; (c)Chaos剖面; (d)Chaos切片; (e)Variance剖面; (f)Variance切片
4 集成学习
基于不同地震属性得到的盐丘分布范围大致相同,但是边界存在差异,并且均有预测误差点。为了综合考虑各属性特征,减少预测误差并得到更可靠、准确的识别结果,利用集成学习方法融合各属性模型。
集成学习思想[17]是利用一定的优化策略将多个基学习器模型集成为强学习器模型组,其中基学习器模型可以单独训练,并且它们的预测能以某种方式融合以得到更全面、准确的结果。该方法的优点在于: ①即使某个基学习器得到了错误的预测,集成的强学习器也可以将错误纠正; ②分类器间存在差异性并各自有一定的使用范围和优势,通过集成策略将多个学习器合并就可以融合各学习器的优势,减小错误率,提高学习泛化能力,实现更好的预测。集成学习算法的关键主要在于: ①基学习器的训练数据多样性; ②基学习器的训练方法多样性; ③组合策略多样性。提取的3种地震属性保证了输入样本扰动,每种属性又分为主测线数据及时间切片两类训练数据,保证了输入属性扰动,基于两种扰动训练基学习器能产生差异性大的个体。在模型训练过程中根据输入的不同调整训练参数,以保证算法参数的多样性,有助于得到差异较大的基学习器。基于6类输入数据,得到了6个独立模型,流程如图10所示。
盐丘的自动识别是一个二分类问题。针对分类问题,常用的组合策略包括绝对多数投票法、相对多数投票法以及加权投票法[18]。本文采用加权投票法。假设目标有m类{c1,c2,…,cm},x为任意一个预测样本,有T个学习器和T个预测结果hi(x)(i=1,…,T),第i个学习器的准确率为Ri,wi为第i个基学习器的权重,由各基学习器的准确率确定。再将各个类别的加权票数求和,则最大值对应的类别为最终的预测结果H(x),即
(1)
本文利用加权投票法融合6类结果,集成结果的准确率为97.43%(图11b),高于基于RMS的预测结果(图11c)。在3种属性中,由于RMS预测结果与标签最相近,准确率最高(图8)。因此集成学习方法的预测结果准确率高于基于3种基础属性的预测结果。综上所述,集成学习方法能减少预测误差,进一步优化分类。图12为模型融合后三维盐丘预测结果。由图可见:由于集成学习过程中综合考虑了多种属性的剖面和切片特征,最终识别结果更可靠、准确, 明显消除了许多分类错误点(图9红框),盐丘边界较清晰。
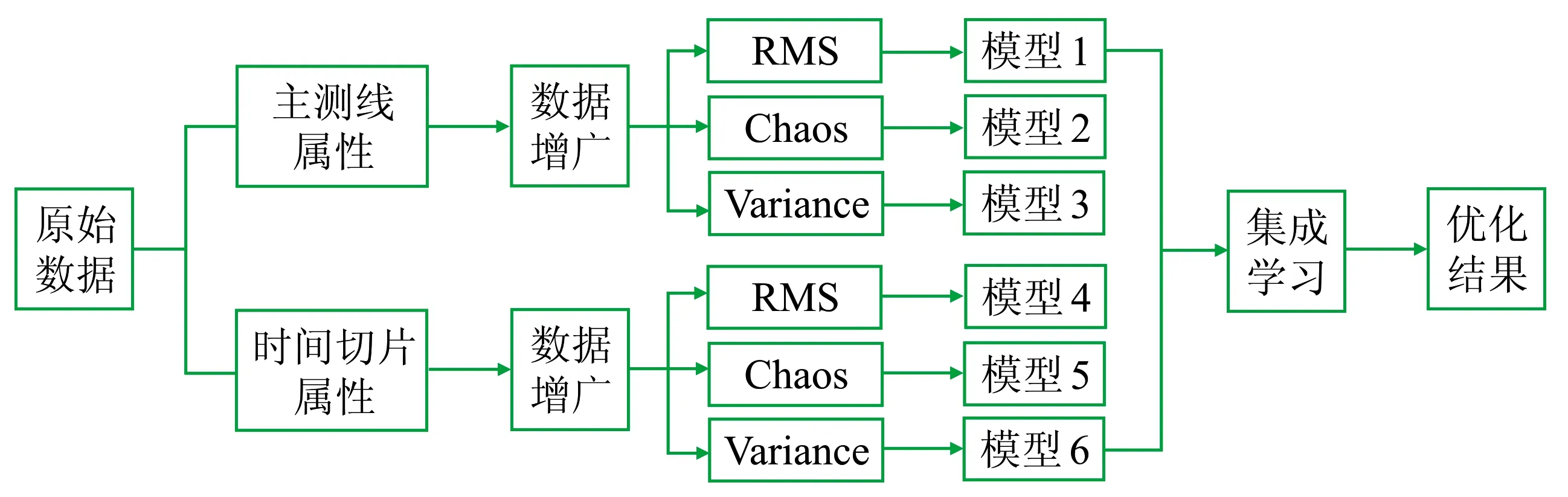
图10 集成学习流程
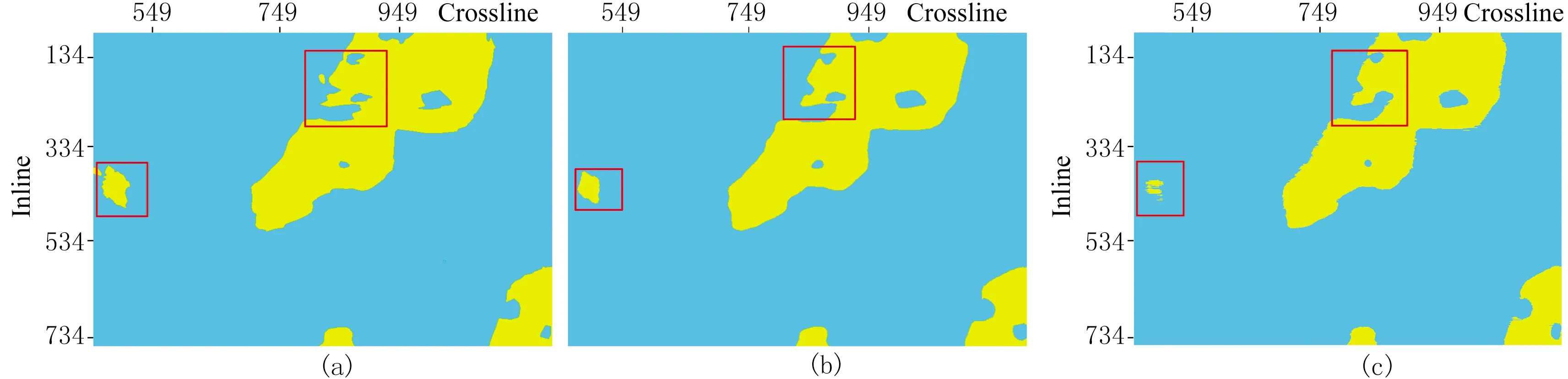
图11 t=1692ms时刻不同方法切片的盐丘预测结果(a)标签; (b)集成学习; (c)RMS属性
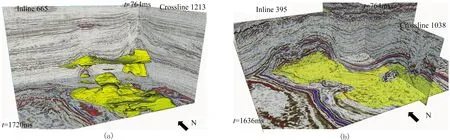
图12 模型融合后三维盐丘预测结果(a)三维盐丘显示; (b)局部盐丘与原始数据叠加显示
5 结论
本文提出了基于深度学习的多属性盐丘自动识别方法。该方法基于盐丘的地震反射特征提取了杂乱、均方根振幅以及方差等3种敏感属性,每一种属性分别选取少量主测线数据及时间切片作为训练样本;然后搭建基于编码—解码器结构的神经网络,分别输入不同的样本进行训练和测试,模型训练时间约为27.5h。测试结果表明,单种属性的预测模型能大致划定盐丘边界,其中RMS属性预测结果的准确率高于Chaos和Variance属性,但仍存在较多误差点,并且由各属性得到的盐丘边界存在差异。为了综合考虑各属性特征,利用集成学习技术对基础模型融合、优化,并用于整个三维数据体。结果显示,盐丘边界清晰,分类错误点明显减少,进一步提高了模型预测能力。
综上所述,与传统盐丘解释技术相比,深度学习技术能有效提高解释效率,并能较准确地实现三维盐丘的自动分割,在辅助三维地震解释的应用中具有巨大潜力。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
科学与财富(2020年15期)2020-07-04
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
移动通信(2019年4期)2019-06-25
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
