
基于Faster R-CNN的精密零部件的识别方法*
2020-06-02 03:42孙海铭时兆峰
飞控与探测 2020年2期
孙海铭,时兆峰,李 晗,王 芳
(北京自动化控制设备研究所·北京·100074)
0 引 言
随着社会的不断进步与科技的不断发展,工业生产的自动化、现代化、智能化已经成为不可阻挡的趋势[1],大量智能生产线如雨后春笋般涌现。在航空航天领域中,陀螺作为惯导的核心部件之一,是众多航空航天设备的重要组成单元。在实际制造装配过程中,由于陀螺的特殊作用,对于其安装精度具有极高的要求。传统的方法主要通过培训熟练技术工人,通过人的操作经验及感官判断安装是否符合要求,虽然最终也可以达到使用的精度要求,但存在装配效率低、依赖工人的工作状态等影响因素,且合格的安装工人需要大量的时间精力进行培训,并且在实际生产环境中,很难出现陀螺摆放位置固定且背景物体单一的理想状态,很容易出现惯性陀螺与其相配合组装的电路板互相重叠遮挡的情况,因此,在陀螺的制造装配过程中引入智能制造技术显得尤为重要,将陀螺从众多装配零部件中识别出来是首先需要解决的问题。介于上述情况,在工业生产条件下,有必要提高对陀螺等需要一定装配精度的物品的精确识别能力,要求不但能够在理想环境且单一物体中识别出所需要的陀螺,还能在多物体的复杂环境下对陀螺进行有效识别。
有关目标识别的算法,主要可以分为两大类。一类是传统的图像目标识别算法,主要是基于人工设计图像特征,典型的有尺度不变特征变换(Scale Invariant Feature Transform,SIFT)、方向梯度直方图(Histogram of Oriented Gradient,HOG)等,通过这些特征将图像由矩阵信息转化为对应的特征向量,然后使用训练好的特征分类器,例如支持向量机(Support Vector Machine,SVM)等实现对图像中目标的识别。在面对复杂背景,尤其是当被识别物体有遮挡情况时,传统的目标识别算法效果较差,且对工作人员的经验依赖性较强,算法的鲁棒性较差,很难适应复杂的应用环境。随着机器视觉以及深度学习的不断发展,基于深度学习的目标识别技术异军突起,被广泛地研究与应用,与传统的检测方法相比,具有目标特征自动提取功能,且无需人工干预设计,能有效地对多任务需求自动地学习目标的特征,在目标检测领域表现出强大的优势。其按照检测的步骤可以分为两大类:(1)one-stage检测算法,其直接产生物体的类别概率和位置坐标,算法的计算速度较快,但准确度较低,比较典型的算法如YOLO[2]和SSD[3];(2)two-stage检测算法,其将检测问题划分为两个阶段,首先产生候选区域,然后对候选区域进行分类(一般还需要对位置精修)。由于该种算法在识别精确度上有着极大的优势,近年来越来越多的科研人员投入到该方向的研究。Girshick 等提出了基于区域卷积神经网络(Regions with Convolutional Neural Network,R-CNN)的目标检测方法,该方法利用选择性搜索算法(Selective Search,SS)生成候选区域用于提取目标特征,虽然解决了少量有限标注数据训练生成较高质量模型问题,但是在提取特征效率和占用内存方面表现欠佳。随后,为了解决R-CNN 中出现大量冗余的特征提取问题,Girshick 等[4]又提出了Fast R-CNN 模型,通过采用自适应尺度池化操作极大地提高了目标检测与识别的性能。He 等[5]提出了基于深度卷积网络的空间金字塔池化层视觉识别方法,对输入的图片数据尺寸大小放宽了限制,从而显著提高了识别的准确率。介于He的思路,Ren 等[6]提出了Fast R-CNN的改进模型,Faster R-CNN 模型,该模型是由区域建议网络(Region Proposal Network,RPN)和Fast R-CNN 构成,用区域建议网络替代选择性搜索算法,解决了计算区域建议时间开销大的瓶颈问题,使实时目标检测与识别成为可能。由于算法性能的不断改进,Faster R-CNN 模型被广泛应用于车辆检测领域[7]、遥感影像地物目标识别领域[8-9]、外观缺陷检测领域、行人检测与识别领域[10-11]以及田间图像检测领域[12]等。
针对上述观点,为了实现对陀螺的精确目标识别,并且克服传统图像识别方法效率低、鲁棒性差、环境适应性差等特点,充分排除复杂环境因素对被识别物体的干扰,对目标物体进行高效识别,本文采用Faster R-CNN深度学习网络对陀螺进行识别,通过三种评价指标综合对Faster R-CNN网络在该应用环境下的识别性能进行考察,同时还对比SSD以及Fast R-CNN深度学习网络模型,验证了所用算法在识别时的准确性与实时性。
1 Faster R-CNN深度学习网络
Faster R-CNN对Fast R-CNN网络进行优化,形成了一种性能更加优异的目标识别网络。相较于基于回归的单步法的识别网络,例如YOLO系列,Faster R-CNN有着更高的精度,并且,相对于之前的Fast R-CNN,Faster R-CNN在实时性方面也有了很大的提升。其中,最重要的优化来自于用RPN代替了原有的选择性搜索方法,专门用来进行候选区域的推荐工作,可以生成高质量的候选区域框。并且,在Faster R-CNN中实现了区域建议网络与特征提取网络的卷积层共享,这大大提高了网络的效率,降低了区域建议功能的时间成本。
如图1的流程图所示,Faster R-CNN主要分为三部分:
(1)特征提取网络。作为一种经典的卷积神经网络的目标检测方法,Faster R-CNN首先采用一组特征提取模块,即卷积层、ReLU激活函数、池化层来提取图片的特征图(feature map)。得到的特征图用于后面的RPN网络与全连接层。本文采用经典的VGG16卷积神经网络提取输入图像的卷积特征,该网络由5部分卷积层、3层全连接层、softmax输出层构成,层与层之间采用最大池化(max-pooling)分开,所有隐层的激活单元均采用ReLU函数。同时,VGG16采取使用多个较小卷积核(3×3)的卷积层来代替一个卷积核较大的卷积层的方案,一方面可以减少参数,增加网络的实时性,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合以及表达能力。除此之外,VGG16每一部分卷积层网络的通道数都在翻倍,由第一层的64通道增加到最后的512通道,通道数的增加,可以使更多的图像信息被更好地提取出来。
(2)即区域建议网络RPN。经典的检测方法生成检测框都非常耗时,如opencv库中的adaboost算法使用滑动窗口结合图像金字塔生成检测框;R-CNN使用选择性搜索方法(selective search)生成检测框。而Faster R-CNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN网络生成检测框,既能提升检测框的生成速度,同时真正将整个算法用卷积神经网络结合起来,这是Faster R-CNN的巨大优势。RPN是一个全卷积神经网络(Fully Convolutional Network,FCN),采用滑动窗口机制实现区域建议框的生成,RPN结构如图2所示。区域建议网络包含一个卷积层和两个全连接层,卷积层添加于卷积特征图之后,与 VGG-16 特征提取网络最后一个卷积层相同,两个全连接层采用并行的方式与卷积层连接,其中一个全连接层采用1×1的卷积核和18个通道数,另一个全连接层采用的1×1卷积核和36个通道数。RPN通过将特征提取网络所提取的卷积特征图作为输入,然后在共享卷积特征图上添加一个小的滑动窗口进行滑动,该滑动窗口经过中间层(Intermediate layer)将卷积特征图中d个大小为n×n(n=3)的空间窗口映射到一个低维向量(512 维)上,最后这个低维向量被输入到两个并行的全连接层——边框分类层(Cls layer)和边框回归层(Reg layer),用于输出滑动窗口中的区域特征是目标还是图像背景,以及输出该区域位置的位置坐标。当滑动窗口在共享卷积特征图上滑动时,每个滑动的位置都会预测出k个区域建议框,因此边框分类层会输出2k个得分(k个目标的分数、k个背景的分数),用于预测每个区域建议框是目标或者不是目标的概率,边框回归层会输出4k个变换参数,用于编码k个区域建议框的位置坐标。另外,采用非极大值抑制法(Non-Maximum Suppression,NMS)使区域建议网络所提取的候选框更加精确,同时每个区域建议框的中心实质是当前滑动窗口的中心。
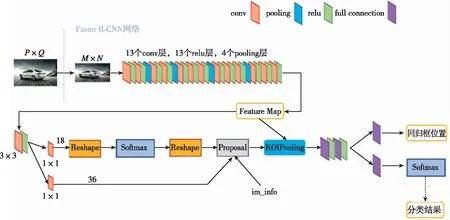
图1 Faster R-CNN流程图
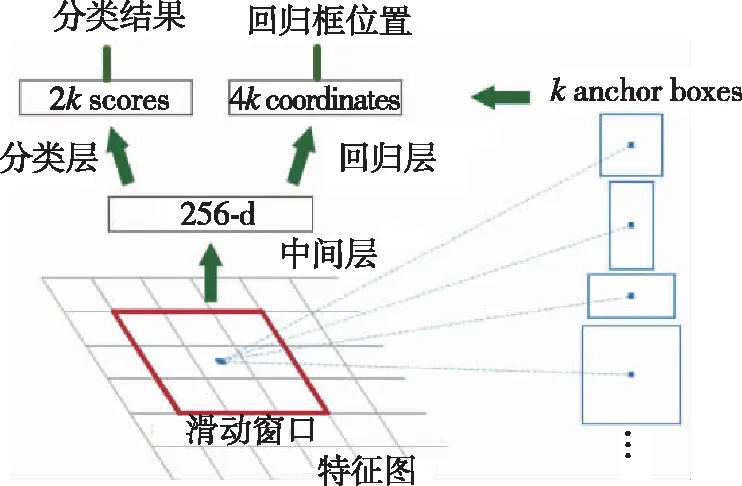
图2 RPN结构图
对于RPN总体的损失函数定义为
(1)
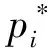
公式(1)中的Lcls表示分类损失,实质是两个类别(目标与非目标)的对数损失,定义为
(2)
公式(1)中的Lreg表示回归损失,定义为
(3)
公式(1)中的Ncls(由小批量锚点的大小决定,此处Ncls=256)和Nreg(由锚点的位置数量决定,此处Nreg=2400)表示规范化参数,分别对分类项和回归项两项进行归一化,并通过一个平衡参数λ(此处取λ=10)进行加权,因此使分类项部分与回归项部分的权重大致相同。公式(2)中log表示对数损失函数,公式(3)中的R表示鲁棒损失函数。
对于边框回归,采用以下4个坐标的参数化
(4)
式中,x、y、w、h表示预测边框的中心坐标及其高度和宽度,变量x、xa、x*分别表示预测边框、锚点、真实区域边框的x坐标(y、w、h同样适用)。
(3)感兴趣区域池化层(RoI pooling layer)。对于传统的CNN(如AlexNet、VGG),当网络训练好后,输入的图像尺寸必须是固定值,同时网络输出也是固定大小的向量或矩阵,如果输入图像大小不固定,主要有两种解决办法:
①从图像中裁剪(crop)一部分传入网络;
②将图像扭曲(warp)成需要的大小后传入网络。
效果如图3所示,剪裁法破坏了图像的完整性,扭曲法破坏了图像的原始图形信息。为了提升网络的训练速度,提高网络的检测正确率,Faster R-CNN采用了RoI pooling层,该层主要负责收集建议(proposal),并计算出建议特征图(proposal feature maps),然后送入后续网络,从流程图可以看出RoI pooling层有2个输入:
①特征提取网络提取的特征图;
②区域建议网络提取的建议(proposal)。

图3 剪裁与图像扭曲的效果图
RoI pooling层的具体工作流程为:
①根据输入图像,将感兴趣区域(RoI)映射到特征图的对应位置;
②将映射后的区域划分为大小相同的模块(模块的数量与输出维度相同);
③对每个模块进行最大池化操作。
通过上述操作,将不同大小的感兴趣区域(RoI)固化为相同大小的感兴趣区域特征池化图,然后再通过后续的两个连续的全连接层将感兴趣区域特征池化图转化为一个感兴趣区域特征向量(4096 维),该向量包含感兴趣区域的最终特征,最后将该向量分别输入两个全连接层,其中一个利用Softmax 计算分类得分,输出预测的类别概率;另一个利用边框回归(Bbox regressor)获得位置偏移量,输出更加准确的目标检测框。
2 实验数据集
2.1 目标样本分析
待识别的样本惯性陀螺如下图所示。从图中可以明显看出,惯性陀螺通体呈扁平圆柱状,下方为薄长方体底座,表面涂有迷彩色喷漆。该物体外形的最大特点是圆形特征,除此之外没有显著的外形特征,直接从外形特征出发对惯性陀螺进行精确识别具有一定难度。并且考虑到在实际的生产装配过程中,惯性陀螺往往与电路板同时进行装配,难免会有惯性陀螺与电路板互相遮挡的情况,因此在制作数据集的过程中,除了如下图的理想情况,应该重点采集惯性陀螺被部分遮挡时的情况,为后续的识别工作打下基础。

图4 惯性陀螺
2.2 图像数据采集
由于网上并没有完全适用于本文的开源数据集,因此本文构建了一个具有一定数量的惯性陀螺数据集。通过深度学习理论可知,数据集中图片越接近真实的应用场景,网络训练便越成功,最终网络的识别效率可能就会越高。鉴于上述理论,本文分析了惯性陀螺装配过程中的工作环境以及可能出现的干扰零部件,最终确定了白色、红色两种工作背景这两大类,以及每种工作背景颜色下,单独的惯性陀螺、惯性陀螺与电路板同时存在的复杂情况以及惯性陀螺被电路板遮挡的遮挡情况这三小类,共6种工作场景。为了充分考虑到经常出现的惯性陀螺被电路板遮挡这一情况,在采集图像时这种情况占数据集的比重较高,同时为了出现过拟合情况,没有一味地提高复杂情况照片的比重。最终确定单独物体、复杂物体、物体有遮挡三种情况1∶2∶2的比例,按照上述原则采集图片数据2000张。其中,两种颜色的背景红色与白色的图像各占约50%,即各1000张。在每种颜色背景的图片中,分别包含单独物体、复杂物体和有遮挡物体三种情况,具体数量如表1所示。
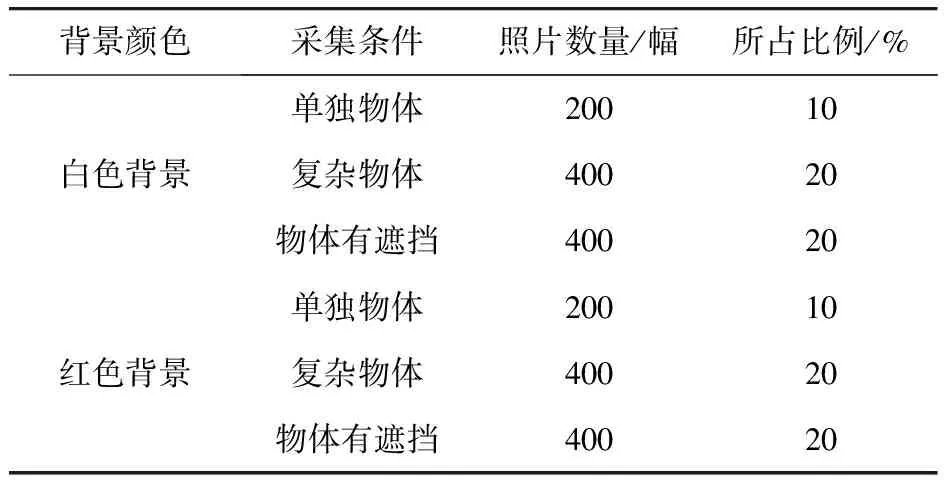
表1 采集图像各种类型的分布情况
作为成熟的神经网络,需要大量的数据进行训练,因为网络中有数以万计的参数等待训练,上述2000张照片显然不足以完成训练Faster R-CNN网络的任务。获取大量数据有两种方法,一种是获取新的数据,即拍摄更多符合要求的图片,这种方法很麻烦,需要大量的成本;第二种方法则是对数据进行增强,利用现有的数据,通过翻转、亮度改变、对比度改变等图像处理中的操作,人为创造出更多的符合要求的数据,在增加训练样本的同时也增加了样本的多样性,提升了网络的鲁棒性,使得训练的网络具有更好的泛化能力。
针对上述分析,本文主要运用了水平翻转、竖直翻转、水平竖直旋转、亮度增强、亮度减弱、对比度增强、对比度减弱几种方法对数据集进行增强,具体通过Python版本的open-cv库进行编程实现,结果如下图所示,分别对初始图像进行上述7种操作,其中亮度变为初始图像的1.4倍与0.5倍,饱和度变为原来的1.5倍与0.4倍。经过数据增强后,训练样本数据由之前的2000张扩张到20000张,有效地扩充了样本数据集的大小,能够降低过拟合现象出现的概率,同时,也有利于网络更好地提取图像的特征。

(a)原图

(b)对比度加

(c)亮度加

(d)翻转

(e)对比度减

(f)亮度减
2.3 数据集的制作
采集图片之后,手工制作数据集。Label-img是一个开源的Pascal Voc格式的数据集制作工具,利用Python编写,在各种系统都可以编译运行,具有页面简洁、操作简单等优点。本文利用Label-img制作了Pascal Voc格式数据集。数据集中所有图片都经过人工标定,标定原则为:对训练集每一幅样本中的前景目标以最小外接矩形对其进行画框标定,包括前景目标轮廓不全的也将其进行画框标定,以保证特征标签训练的可靠性,避免偶然因素对网络训练及后期测试造成的影响。尤其是在面对有遮挡情况的照片时,确保对整个惯性陀螺物体进行标注,保证后期运行时能够正确找出惯性陀螺的位置。
在确定训练集与测试集数量时,借鉴“留出法”[14],即直接将数据集划分为两个互斥的集合,为了保证两个集合数据分布大致一致,按照表1中的图像类别分别按比例抽取。按照训练数据应占总数据集三分之二的理论,随机抽取样本数据集中的65%样本数据(13000幅)作为训练集(Train sets),为了保证上文中提到的两个集合中数据分布大致一致,按照表2中图片类型的分布情况,每种类型各抽取65%作为训练集,即白色背景下,单独物体1300张,复杂物体2600张,物体有遮挡1300张,红色背景下,单独物体1300张,复杂物体2600张,物体有遮挡1300张,剩余35%样本数据(7000幅)作为测试(Test sets)。
3 仿真实验及结果分析
3.1 实验条件简介
本文算法的训练与验证均基于tensorflow框架[13-14],同时图片的预处理及数据增强时对于图片的处理工作均通过open-cv进行,运行系统环境为ubuntu16.04,训练阶段GPU选择为NVIDIA GeForce GTX 1080Ti,通过Pyhon语言实现编程操作。
3.2 评价指标
在计算机视觉领域中,根据不同的任务,有着截然不同的评价指标。本文结合现有的评价方法,采用识别准确率、识别召回率和识别速度进行评价,具体含义如下
(1)准确率与召回率
设DT为识别到的目标(Detection Result),GT为真实的目标(Ground Truth),根据DT与GT的IoU结果来判断其识别是否正确,如果IoU大于阈值(本实验取0.5),认为其识别正确,反之则认为其识别错误。将正确识别的个数除以正确识别个数与误识别个数的和得到识别准确率;将正确识别个数除以正确识别个数与漏识别个数的和得到识别召回率,公式如下
(5)
(6)
式中,P为准确率,R为召回率,TP为算法正确识别物体的数量,FP为将背景中的干扰误识别为物体的数量,FN为未识别到的物体的数量。
(2)识别速度
本文利用学术领域常用的FPS来表征识别速度。FPS指的是每秒中识别图像的数量,即帧/s。它是识别时间的倒数,它的数值越大表明单位时间内识别的图像数量越多,即算法的运行速度越快,反之则越慢。
3.3 模型训练结果分析
本文采用的深度学习网络,训练过程中基于梯度下降法来优化参数,这也是目前普遍的方法。通过不断迭代求得最小的损失函数以及最优的模型权重。进行梯度下降法前需要给参数赋初始值,如果训练数据集前先加载预训练模型作为初始化,可以加快梯度下降法的收敛速度,并且更有可能获得一个较低的模型误差,并且排除掉因为未正确初始化或者漏初始化而造成的梯度消失或发散的现象。初始化模型中的随机初始化,避免数据的对称性,从而保证网络学习的合理性。
鉴于上述理论,本文以端到端的训练方式共享卷积特征,利用微软开发的COCO[15]的预训练模型进行初始化参数设置,这是因为在面对一个庞大的深度网络时,通过加载预训练模型的方式可以大大加快网络的训练速度,并且COCO作为广泛运用的数据集,其性能的优越性已被证明。模型的优化器选择动量项为0.9随机梯度下降算法,权值的初始学习率设置为 0.001,衰减系数为0.0005,最大迭代次数设置为 100000 步。训练结束后保存训练好的模型,利用测试集对模型效果进一步验证。
为了对比Faster R-CNN与SSD算法在训练过程中的优异性差别,制作了训练过程中网络总体损失随训练次数变化图,从图中可以看出,SSD网络在20000次训练后开始收敛,Faster R-CNN网络在10000次训练后开始收敛,20000次训练后与SSD网络的趋势开始相近。虽然在最后SSD与Faster R-CNN模型在20000次训练后都收敛,但明显Faster R-CNN网络收敛速度更快,甚至在10000步时便已经趋于稳定,在训练收敛速度方面,Faster R-CNN具有一定优势。
3.4 实验结果分析
实验利用自建的数据集对网络进行训练,训练完成后,将得到的权值模型在对应的测试集上进行测试,检测框的概率阈值设置为0.5。选取部分Faster R-CNN算法的识别效果图,如图7所示。

图6 SSD与Faster R-CNN总体损失对比

(a)白色背景单独物体

(b)白色背景复杂物体

(c)白色背景物体有遮挡

(d)红色背景单独物体

(e)红色背景复杂物体

(f)红色背景物体有遮挡
结果表明,Faster R-CNN算法能够对陀螺进行有效识别,测试时间在1080Ti上可以达到15FPS,具体结果如图8所示。在对单一物体识别时,无论是简单的白色背景,还是具有干扰性的深红色背景,Faster R-CNN网络都取得了较好的效果。在面对复杂情况时,将电路板与需要被识别的惯性陀螺无规律地摆放在一起时,Faster R-CNN网络也可以在多物体中对惯性陀螺进行有效识别;在惯性陀螺部分被电路板遮挡这一情况下,Faster R-CNN网络仍然能对物体进行有效识别。

图8 速度对比图
根据模型评价指标,同时为了验证Faster R-CNN网络在此种应用环境下的优越性,将本实验在相同配置条件以及工作环境下做了Faster R-CNN与其他现行流行程度较高的深度学习目标检测网络性能对比,结果如下表2所示。SSD、Fast R-CNN深度学习模型分别对测试集图片进行识别。通过结果对比可知,相较于另外三种目标识别网络,Faster R-CNN网络表现出一定的优良性能,在准确率以及召回率方面都有着很大的差异。但是也可以看出,SSD这类单步法的深度学习算法在识别速度方面有着很大的优势,但是识别精度以及召回率劣势太大,如图9所示,SSD很容易出现遮挡情况下无法召回物体的情况。随着现在硬件设备的不断升级换代,识别速度可以被硬件设备进一步弥补。目前得到的Faster R-CNN的15FPS的识别速度,已经可以满足很多的应用场景。综合上述分析,虽然SSD网络在识别速度方面表现出了很大的优势,但是因为准确率以及召回率这两项指标的巨大优势,Faster R-CNN 网络在本文的应用场景之下具有更优良的性能。

(a)SSD识别效果

(b)SSD识别效果
同时将Faster R-CNN算法在相同工作环境下与传统的目标识别算法HOG+SVM进行对比。在理想的试验状态下,即物体摆放位置良好且互相无遮挡,HOG+SVM可以达到最高50%的识别准确率。由于传统算法需要基于人工的经验,随着环境的改变,很容易出现图10(b)中误检测的情况。并且面对复杂的识别环境,如图10(a)的情况,电路板与惯性陀螺共同摆放或者惯性陀螺部分被电路板遮挡时,传统的目标识别算法几乎失去作用,图中无法返回任何输出框,即算法认为图中没有被识别物体。Faster R-CNN相对于传统的目标识别算法具有巨大的提升。

(a)SVM识别效果

(b)SVM识别效果
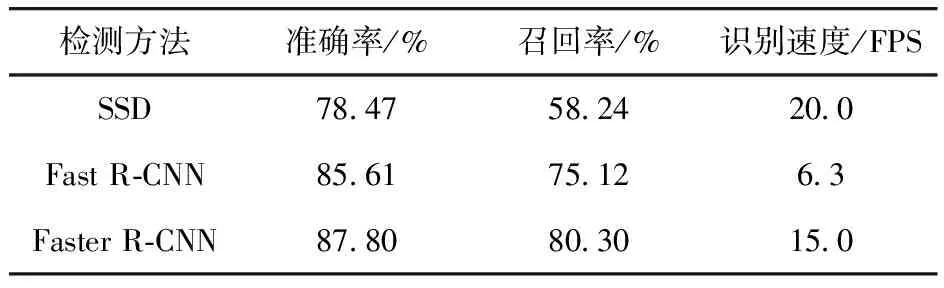
表2 不同检测模型的检测性能对比
4 结 论
本文以航空航天中的装配精度要求较高的惯性陀螺作为研究对象,在Tensorflow深度学习框架之上构建了Faster R-CNN目标识别网络,通过COCO数据集的深度模型进行迁移训练。为了解决深度学习过程中需要样本数量大以及在实际运用中数据采集困难的现象,本文采用了数据加强的方式来丰富训练数据集,有效解决了图像数据不足的问题,降低了训练过程中过拟合的风险。实验结果表明:
(1)Faster R-CNN在对惯性陀螺的识别上,相较于传统目标识别算法、SSD、Fast R-CNN网络有着明显的优势,虽然在识别速度方面不及SSD,但15.0FPS已经能够胜任大多数的工作任务。
(2)当环境光不理想、背景复杂且待识别物体被其他物体遮挡时,Faster R-CNN网络仍有较好的工作性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
小学生学习指导(低年级)(2019年10期)2019-10-16
学生天地(2019年6期)2019-03-07
故事作文·高年级(2016年6期)2016-06-21
少儿科学周刊·儿童版(2015年2期)2015-07-07
科普童话·百科探秘(2015年4期)2015-05-14
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
