
基于深度特征的人群密度估计方法
2020-06-01 07:01
浙江工业大学学报 2020年3期
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
近年来,由人群聚集引起的安全事故频发,为了预防类似问题,许多国家出台了相关的安防政策予以应对。此外,对人群的分析也逐渐成为各国企业和研究者关注的重点。其中,人群密度估计是人群分析中十分重要的一部分。
人群密度估计是指对图像或视频帧中的一定区域内所包含的人数进行估计,通过人群密度情况来反映该区域内的人群聚集情况。人群密度估计问题一般使用人群密度等级分类的方式予以解决,其大致步骤为:首先,通过对人群图像中一定区域进行人群特征提取;然后,利用提取的特征训练分类器;最后,使用训练得到的分类器对给定图像的人群密度等级进行划分。
1 相关工作
在人群密度估计领域,已经有许多人进行了相关的研究,并提出了一些解决方法。这些方法主要可分为两类:基于像素特征的人群密度估计方法以及基于纹理特征的人群密度估计方法。
基于像素特征的人群密度估计方法,一般通过统计人群像素点的数量,并计算像素点在图像中所占的像素比进行人群密度估计。Chow等[1]提出先分别获取人群前景像素值占图像总像素值的比例,边缘像素值、背景像素值占图像总像素值的比例,并对这三个特征值使用神经网络进行训练,得到对应的人群密度分类器。人群图像中存在阴影会使得该方法估计得到的人群密度有偏差。为了解决人群图像中的阴影对人群密度估计的影响,Ma等[2]提出对人群图像的不同前景赋予不同权重,来进行射影畸形矫正,以此提高人群密度估计的准确率。为了进一步提高人群密度估计的准确率,Damian等[3]改进Ma等[2]的方法,提取分块化的像素特征,并利用提取的像素特征训练人群密度分类器。基于像素特征的人群密度估计方法在低密度场景下表现较好,但是在高密度场景下,由于人和人之间存在遮挡,这会导致人群密度估计准确率下降。
为了解决高密度场景下人群密度估计准确率下降的问题,基于纹理特征的人群密度估计方法逐渐被提出,该方法将人群视为一种特殊的纹理,通过提取人群图像中纹理特征进行人群密度估计。Wu等[4]通过提取人群图像中每个子块的灰度共生矩阵特征(Gray-level co-occurrence matrix, GLCM),并结合所有子块的GLCM特征得到图像的密度等级。Ma等[5]提出使用改进的局部二值模式特征(Local binary pattern, LBP)进行人群密度估计。提取图像的纹理特征能够较好地解决高密度场景下的人群密度估计问题,但是当人群背景较复杂时,上述方法无法提取到较好的人群特征[6]。因此,还存在提升的空间。
由于卷积神经网络(Convolutional neural network, CNN)能够提取具有较强数据表达能力的深度特征,该特征能够更好地反映人群密度情况。因此,笔者提出使用卷积神经网络提取人群的深度特征,并利用该特征进行人群密度估计。
2 基于深度特征的人群密度估计
深度学习是一种能够学习所提供数据中的潜在分布特性的复杂算法,能够进行有监督学习和无监督学习,利用大数据[7-9]自主学习数据中的特征。卷积神经网络是处于有监督学习下的一种深度学习模型,卷积神经网络通过对图像进行迭代学习,由低级纹理特征慢慢学习到高级语义特征,最后得到深度特征具有很强的特征表达能力。由于深度特征的优点,笔者使用两种不同的卷积神经网络提取深度特征,以此来训练人群密度估计分类器。具体的算法流程如图1所示。

图1 基于深度特征的人群密度估计流程图Fig.1 Crowd density estimation flow chart based on deep feature
2.1 深度特征提取
卷积神经网络是一个多层次结构的深度网络,一般由卷积层、池化层、全连接层组成。随着深度学习的发展,研究者们通过对基本卷积神经网络进行改进,提出了一系列新的网络,近年来典型的CNN网络有AlexNet[10],VGGNet[11],GoogleNet[12]等。本研究用于人群特征提取的两种卷积神经网络分别为VGGNet-16和ResNet-152。
2.1.1 VGGNet-16网络
与AlexNet相比,VGGNet使用连续的几个3×3的卷积核代替AlexNet中的较大卷积核。在具有相同感受野的情况下,使用小卷积核叠加的形式能够增加网络深度,减少训练参数,从而提升网络的效果。笔者首先使用VGGNet的16 层结构进行人群特征提取,所使用的具体结构如图2所示。

图2 VGG-16网络结构图Fig.2 VGG-16 network structure diagram
对于卷积模块,首先将人群图像的尺寸都转换为224×224作为输入图像,在每个卷积层中,卷积核先对输入图像进行线性滤波,并通过激活函数处理得到特征图。该过程可以表示为
(1)
式中:y(l)表示第l个卷积层的输出;ai为输入向量;*为卷积运算符;Wij为该层卷积核的权值;b(l)为偏置量;n为输入特征图的总数。每个卷积层都会对前一层的输入ai使用Wij进行卷积,产生新的输出y(l)。f(x)表示激活函数,本网络中使用ReLU作为激活函数,其公式可表示为
f(x)=max(0,x)
(2)
在卷积核参数的设计上,本网络和VGGNet-16保持一致,卷积核大小全部设置为3×3,对于最大值池化层,其核大小设置为2×2,步长设置为2,最大值池化能够有效减少参与训练的神经元数量,同时使得提取到的特征具有平移不变性。
在全连接层的设计上,考虑到不同图像中的人群密度特征多变,且在人群图像的特征尺度较多,笔者使用两个4 096 维的全连接层与一个5 维的全连接层组成本网络的全连接模块,这样的设置能够更好地学习到多个尺度的人群特征。
2.1.2ResNet-152网络
由于卷积神经网络能够提取不同等级的特征,所提取到特征的信息丰富程度与网络层数呈正相关关系。但如果只是简单地增加网络深度,就会导致梯度爆炸问题。一般来说,该问题可以通过添加正则化层(Batch normalization, BN)来解决。虽然添加正则化层解决了梯度爆炸问题,但是退化问题并不能得到解决。退化问题是指随着网络层数的增加,卷积神经网络的性能反而下降,其主要原因在于网络的优化难度增大。针对这个问题,He等[13]提出残差网络(ResNet)结构,该结构使用了一种名为快捷连接(Shortcut connection)的连接方式,该连接方式如图3所示。

图3 快捷连接方式示意图Fig.3 The schematic diagram of shortcut connection
在图3中,假设原始的卷积映射函数为H(x),直接拟合该映射函数比较困难,因此该结构不是让网络直接拟合原始的映射函数,而是拟合残差映射函数。如果将拟合原始映射转换为拟合残差卷积单元F(x)=H(x)-x,则网络的映射函数可表示为H(x)=F(x)+x。同时,在该网络中,新增加的快捷连接不会增加网络的参数大小和复杂程度。文献[13]中还提出两种典型的ResNet结构,这两种结构分别为ResNet-34和ResNet-50/101/152,具体结构如图4所示,图4(a)表示构建块(Building block)结构,图4(b)表示“瓶颈”构建块(“Bottleneck” building block)结构。
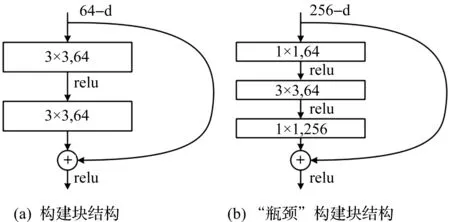
图4 残差网络瓶颈结构示意图Fig.4 The schematic diagram of residual network bottleneck structure
使用“瓶颈”构建块结构的目的是为了降低训练参数的数量,该结构通过第一个1×1的卷积把256 维变为64 维,最后在末端再用一个1×1的卷积来把64 维恢复成256 维。对于参数的数量,使用瓶颈结构后,整体的参数数量为1×1×256×64+3×3×64×64+1×1×64×256=69 632;若不使用瓶颈结构,整体的参数数量为3×3×256×256×2=1 179 648,是使用瓶颈结构的参数数目的16.9倍。由于ResNet-152的优异表现,笔者也使用ResNet-152的网络结构来提取人群特征。
在全连接层的设计上,由于本研究只需要将人群密度等级分为5 类,所以将ResNet-152模型中1 000 维的全连接层降低到5 维。
2.1.3Softmax分类器
在分类器方面,使用Softmax分类器[14]对人群密度等级进行分类,若人群密度等级标签数为k,则Softmax分类器可表示为
(3)

由于本实验将数据集划分为5个密度等级,为了与之对应,在训练时需要将Softmax分类器的参数k设置为5。
2.2 网络训练
在网络训练时,将预处理后的人群图像及对应的人群密度等级标签输入网络,使用Adam优化算法以及交叉熵损失函数展开训练,学习率设置为le-4,批量大小(Batch size)设置为10。实验证明,在此参数的设置下,网络能够得到充分训练,loss值逐步下降,不易发生过拟合情况,且收敛速度较快,分类的准确率也稳定提升。
3 实验及分析
笔者算法是在Ubuntu平台下通过Pytorch深度学习框架实现的。运行环境为Ubuntu 16.04.3系统,32 G内存,E5-2630CPU和GeForce GTX 1080Ti显卡。使用CUDA对训练以及测试过程进行加速。所使用的数据集来自于PETS2009视频数据库[15],该数据库包括S0,S1,S2,S3等4 个子数据集:其中,S0数据集用于相关背景训练;S1数据集用于人群计数和人群密度估计;S2数据集用于行人跟踪;S3数据集用于人流分析和行为检测。本节使用S1数据集中的相关视频序列作为实验数据进行分析对比。
3.1 图像预处理
Fradi等[16]提出将人群密度划分为5 个等级:极低、低、中等、高和极高,使用不同的密度等级来描述人群密度特征。在PETS2009的S1数据集中,每帧图片有R0,R1,R2等3 个区域,一般使用R1和R2区域进行人群密度估计研究,具体区域划分情况如图5所示。

图5 S1数据集区域划分示意图Fig.5 The schematic diagram of regional division on S1 dataset
先根据坐标范围,将R1和R2从每帧图像中分割出来,再将分割出的图像进行灰度化操作,同时将灰度化后的图像尺寸都调整为224×224,最后对图像进行归一化处理。
在图像预处理之后,需要制作实验所需的训练集和测试集。首先,根据表1所示的密度等级分类标准,将数据集划分为5 个密度等级,划分后的各个密度等级样本数量如表2所示。接着,将划分后各个密度等级的样本随机分为两份,一份作为训练集,一份作为测试集。各个密度等级的样本示例图如图6所示。从图6中可以看出:划分后的样本能够较好地体现不同的人群密度情况,有利于提高训练所得分类器的性能。

表1 密度等级分类标准Table 1 The standard of density classification 单位:人

表2 各人群密度等级样本数量Table 2 The number of samples for each crowd density level 单位:个


图6 各个密度等级样本示例图Fig.6 Sample diagram of each density level
3.2 实验设置
为了证明使用深度特征能够提高人群密度估计的准确率,首先利用处理好的训练集训练基于HOG,LBP和HOG-LBP这3类传统特征的SVM分类器;接着,利用同样的训练集训练基于VGG-16和ResNet-152的Softmax分类器;最后,使用训练得到的分类器对测试集进行测试,并对得到的结果进行比较分析。
3.3 实验结果分析
使用基于HOG,LBP和HOG-LBP这3类传统特征训练的分类器进行人群密度估计,所得结果如图7所示;使用基于VGG-16和ResNet-152网络提取的深度特征训练的分类器进行人群密度估计,所得结果如图8所示。

图7 基于传统特征的人群密度估计实验对比Fig.7 Experimental comparison of crowd density estimation based on traditional feature

图8 基于深度特征的人群密度估计实验对比Fig.8 Experimental comparison of crowd density estimation based on deep feature
从图7的实验结果可以看出:在R1和R2两个人群区域中,基于HOG-LBP特征的方法准确率比基于HOG特征的方法准确率分别提高2.8%,6.3%,比基于LBP特征的方法准确率分别提高1.4%,1.4%。此结果证明,由HOG特征与LBP特征结合得到的HOG-LBP特征比起单一特征能够更好地描述人群特征,提高人群密度估计的准确率。
从图8的实验结果可以看出:在R1和R2两个人群区域中,基于ResNet-152的方法准确率比基于VGG-16的方法准确率分别高0.6%,0.1%。与图7中基于传统特征的方法相比,基于深度特征的方法在两个人群区域中都取得了最好的密度等级分类准确率。综合图7,8可以得出:深度特征比起传统特征有着更好的特征表达能力,对人群密度估计更有帮助。
4 结 论
为了进一步提高人群密度估计的准确性,笔者提出一种基于深度特征的人群密度估计方法,使用卷积神经网络来提取人群图像的深度特征,提取的深度特征能够更好地反映人群密度情况。从实验结果来看,基于深度特征的人群密度估计方法比基于传统特征的人群密度估计方法有更高的准确率。所提方法虽然有较高的人群密度估计准确率,但该方法仅仅使用了两种单独的卷积神经网络进行深度特征的提取,接下来的工作将考虑结合多种深度特征,进一步提高特征的表达能力,从而提高人群密度估计的准确率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电子产品世界(2022年4期)2022-04-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
科技视界(2021年4期)2021-04-13
现代信息科技(2021年17期)2021-04-05
农业科技与信息(2021年2期)2021-03-27
计算机系统应用(2021年2期)2021-02-23
农业机械学报(2021年1期)2021-02-01
健康体检与管理(2021年10期)2021-01-03
