
航空电子系统机载网络实时性能评价技术
2020-06-01 09:04何锋周璇赵长啸李峭王鹏熊华钢
北京航空航天大学学报 2020年4期
何锋,周璇,赵长啸,李峭,王鹏,熊华钢
(1.北京航空航天大学 电子信息工程学院,北京100083; 2.中国民航大学 适航学院,天津300300)
航空电子系统(以下简称航电系统)是飞机的“大脑”和“神经中枢”,其综合化程度决定了飞机的性能和发展水平,至今已经历4代典型技术发展[1]。机载网络在航空工程领域苛刻的空间限制和功能/性能约束条件下,对信息密集型的航电系统进行信息综合和功能综合,是航电系统的重要组成部分,其每一次技术革新都与航电系统的升级演变密切相关,已成为航电系统架构代纪演化的重要标志。
目前,机载网络经历了从最初分立式航电系统采用的点到点总线ARINC 429,到联合式航电系统采用的集中控制总线MIL-STD-1553B,再到采用分布式控制的光纤数据接口(Fiber Distributed Data Interface,FDDI)和线形令牌传递总线(Linear Token Passing Bus,LTPB)的总线式互连发展[2]。随着航电系统综合化、模块化程度的深入,以及数据通信在带宽、实时性、可靠性等方面需求的极大增强,交换式组网技术成为机载网络系统的首选。以光纤通道(Fiber Channel,FC)[3]、航空电子全双工交换式以太网(Avionics Full Dup lex switch ethernet,AFDX)[4]和时间触发以太网(Time-Triggered Ethernet,TTE)[5]为代表的新一代航电系统互连技术已经在综合电子系统中得到典型应用和考虑。
考虑到航电系统任务关键和安全关键特征,不同于一般的商用计算机网络,机载网络更加强调组网的实时性,体现于消息在网络传输中的端到端延迟与消息传输截止期限之间的相对大小关系。具体到消息的传输过程,其端到端延迟大小取决于网络中的发送延迟、处理技术延迟和排队延迟,其中排队延迟是消息传输延迟不确定性的最主要构成部分。典型的可以采用解析方法、仿真(simulation)方法、模型检查(Model Checking,MC)方法、测试方法(test)等实现端到端传输延迟的分析与评价。不同的实时性能评价方法具有不同的计算紧性(calculation tightness)和效率;同时,不同的总线网络协议也将导致不同的评价模型。
本文首先研究了机载交换式网络中消息端到端传输延迟模型,在其基础上给出了衡量不同实时性能评价方法在评估悲观性和计算紧性的对比指标,然后针对每一类实时性能评价方法,依据于其发展过程和实施手段进行细化梳理,重点讨论各种方法在计算紧性和效率方面的差异,最后以2种典型网络拓扑为应用背景对上述方法进行性能对比,并展望机载网络实时性能评价技术的发展趋势。
1 机载网络端到端延迟分析
1.1 消息端到端传输延迟模型
随着计算机技术、网络技术和通信技术的发展,航电系统对机载网络的实时要求逐渐提高。机载网络的实时性能评价结果不仅可用作航电系统设计好坏的总体评价指标,还可用作资源调度分配、消息路径设计、优先级配置等关键技术实施的重要考核指标。依照实时性能评价结果,可以对机载网络的设计过程进行反馈,形成迭代优化[6-8]。对于民用航空来说,实时性能评价结果还是航电系统能否取得适航认证的关键[9-10]。
当前先进的航电系统多采用基于交换式结构的组网手段,比如FC、AFDX和TTE等。相比于总线式组网技术,交换式组网技术在多网段交换结构、带宽、组网复杂性、消息调度机制、消息传输路径等方面都具有更大的复杂性,由此也带来其实时性能评价的巨大挑战。
对机载网络实时性能进行评价,取决于对每一条消息端到端传输延迟的分析结果。考虑机载交换式网络中具体的某一条消息τi,沿其传输路径Pi进行传输,传输路径Pi由源端系统(source ES)、转发交换机(switch)和目的端系统(destination ES)及其相连的物理链路构成,形成从源端到目的端的整个完整路径。与消息τi共享路径的其他消息与τi竞争端口输出,从而造成流量τi传输的不确定性,而这种不确定性还会随着级联的深入而进一步放大。
不失一般性,可以把消息τi端到端传输延迟表示为D(τi,Pi)=LD(τi,Pi)+SD(τi,Pi)+WD(τi,Pi)式中:LD(τi,Pi)为数据帧在物理链路上的发送延迟,在全双工工作模式下,单个帧发送延迟取决于消息帧长和物理链路传输带宽的比值。当消息经过多条物理链路时,发送延迟是单个帧的传输时间与经过物理链路数量的乘积。
SD(τi,Pi)为消息对应的数据帧从交换机输入端口发送到输出端口的时间,不包含数据帧在输出端口排队的时间。从模型简化角度一般称SD(τi,Pi)为交换机固有的技术延迟,其值为单交换机固定技术延迟与消息经过交换机的个数的乘积。

因此,消息端到端传输延迟D(τi,Pi)可以被分成固定值LD(τi,Pi)+SD(τi,Pi)部分和变化值WD(τi,Pi)部分。固定值部分可以根据事先配置的消息参数和路径进行简单计算,而变化值部分高度依赖于组网的动态特征和具体配置,是导致消息传输不确定性的最大来源。结合消息端到端传输延迟和消息传输截止期限,可以进行消息传输是否满足实时性能的基本判断,以及传输时间裕量的计算。

称消息τi的实时性能能够保障;否则,消息τi实时性能不能够得到保障,在最坏情况下,其数据帧传输不能及时到达目的节点。在实时性能可保障条件下,消息传输截止期限与最大传输延迟之间的差值称之为消息传输时间裕量,即
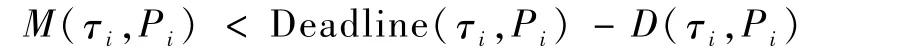
显然M(τi,Pi)越大,消息在规定的截止期限前能够越快地传输到目的节点,潜在的实时性能保证能力也越强,可以将其作为机载网络系统优化设计的目标进行整体考虑。
1.2 实时性能评价方法性能对比指标
由于消息传输截止期限通常由应用需求产生并决定,对于机载网络实时性能评价工作来说是一个给定值;因此,如何能够更有效地得到消息最大传输延迟D(τi,Pi),是整个评价过程中的关键。由此也发展了多种消息最大传输延迟及其相关的实时性能评价方法。典型的,解析方法可以得到传输延迟的理论上确界,存在网络演算(Network Calculus,NC)[11-13]、轨 迹 法(Trajectory Approach,TA)[14-15]、整 体 法 (Holistic Method,HM)[16-17]等典型分析方法。仿真方法[18-19]通过通信行为模拟,实现网络运行时态行为仿真,是网络性能评价的常用方法,利用仿真方法获得的平均延迟提供了网络运行时态性能评价参考。模型检查[20-21]方法通过状态穷举,可以实现消息最坏传输延迟的精确评价。测试方法[22]与仿真方法类似,通过对真实机载网络系统进行测试,获得实际的机载网络实时性能。
实时性能评价技术还典型依赖于机载网络协议本身的通信机制。比如,针对FC存在解析方法[23]、仿真方法[24]、测试方法[25]等评价手段;针对AFDX存 在 解 析 方 法[26-28]、仿 真 方 法[18,29]、模型检查方法[30-31]、测试方法[32]等评价手段;针对TTE存 在 解 析 方 法[33-34]、仿 真 方 法[19]、测 试 方法[35]等评价手段,此外其实时性能与可调度性设计紧密相关[36-39]。
不同的实时性能评价方法具有不同的评价效率和计算紧性。一旦机载网络配置参数形成,可以认为网络中消息最坏传输延迟为一固有的确定值,也即:消息准确最大传输延迟Dact(τi,Pi),而采用不同评价方法获得的最大传输延迟为Dacq(τi,Pi)。虽然Dact(τi,Pi)客观存在,但很难通过实时性能评价方法获得。当Dacq(τi,Pi)>Dact(τi,Pi)时,则通过评价方法获得的最大延迟具有评估的悲观性。因此,可以将Dacq(τi,Pi)>Dact(τi,Pi)的 比 例 定 义 为 该 评 价 方 法 的 悲 观 性Pess(τi,Pi),也即:反映其实时性能分析能力的悲观程度。
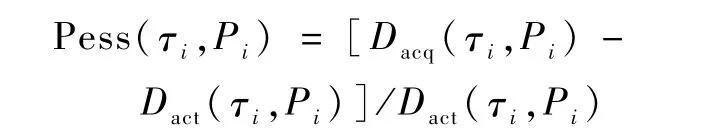
当Dacq(τi,Pi)<Dact(τi,Pi)时,则通过评价方法获得的最大延迟具有评估的乐观性,同样将其定义为Dacq(τi,Pi)<Dact(τi,Pi)的比例,反映其实时性能分析能力的乐观程度,即

具有乐观性的评价方法不足以进行系统最坏性能预估,只是提供了系统最坏性能的某种参考,但具有评估悲观性的方法可以支持系统最坏性能预估,可以用来进行系统实时性能评价。
不同方法的评估悲观性就代表了各种方法在最坏性能预估过程中与真实最坏传输延迟的接近程度,悲观性越小,其预估值就越精确。但实际上系统真实最坏传输延迟往往不能获得,由此发展了计算紧性的指标来刻画不同评价方法的相对优劣程度。计算紧性被定义为不同评价方法其端到端传输延迟分析结果的比例。当采用2种具有悲观性的方法分别进行最坏性能分析时,得到延迟结 果 Dacq1(τi,Pi)和Dacq2(τi,Pi),如 果 以Dacq1(τi,Pi)为参考标准值,则Dacq2(τi,Pi)所对应的评价方法的计算紧性为

当Dacq2(τi,Pi) >Dacq1(τi,Pi)时,则Dacq1(τi,Pi)对 应 的 评 价 方 法 悲 观 性 较 小,Dacq2(τi,Pi)对 应 的 评 价 方 法 悲 观 性 较 大,而Tight(2,1)(τi,Pi)则反映了这2种方法之间的相对优劣性:相对于Dacq2(τi,Pi)所对应的评价方法,Dacq1(τi,Pi)对应的评价方法在最坏传输延迟预估方面更接近真实值,也即具有更好的计算紧性。反之亦然。进一步,计算紧性也可以衡量具有乐观性的评价方法之间的相对优劣性。当参考标准值为精确最坏传输延迟时,计算紧性实际上也是评估悲观性的一种变体。
因此,在精确最坏传输延迟难以获得的情况下,采用评估结果相对比的方法提供了不同评价方法计算紧性的相对度量手段。具有空分交换结构的交换式组网拓扑,以及针对不同关键级别的不同调度机制,为消息相干分析带来了巨大的复杂性。如何获得更接近真实最坏传输延迟的方法,也即如何实现更具有计算紧性的上确界计算,一直是实时网络领域不断追求的目标。
2 解析方法
2.1 网络演算


图1 确定性网络演算模型Fig.1 Deterministic network calculus model
经过本级网络节点输出数据流的不确定性可以在原有不确定性的基础上,通过延迟换算为突发度增加来逼近,从而实现从源节点到目的节点的流量求解和最坏延迟的累加计算。随机网络演算在确定性网络演算的基础上,利用大偏离原理结合概率运算,计算数据流在保证条件下的最坏延迟上界,是对确定性网络演算在概率随机方向上的扩展。
1991年,Cruz[11-12]首次提出了确定性网络演算的基本概念和方法,2001年,le Boudec和Thiran[40]正式将最小加代数引入到网络演算中,论述了基于最小加代数的确定性网络演算模型,包括到达曲线、服务曲线、最小加代数下的卷积与反卷积运算等基本概念和相关结论,将之发展完善并系统化为理论体系。
针对网络演算理论在机载网络方面的应用,Grieu[46]将确定性网络演算方法应用于AFDX性能评价中,利用虚拟链路的流量整形特点,采用漏桶模型[45]实现数据流到达模型的建模,结合非抢占模式的传输特点,对固定优先级(Fixed Priority,FP)/FIFO调度策略下的端口服务模型进行建模,实现了AFDX实时性能评价。
考虑数据帧序列化的影响,来源于相同上一级物理链路的数据帧无法同时到达本级输出节点,因此节点处聚合数据流[40]到达曲线并不是各单条数据流到达曲线的简单叠加。Grieu[46]率先提出分组(group)方法解决此问题,引进实际最大可能突发度和物理链路传输速率的约束,实现了分组网络演算的优化设计。针对包含8个交换机,1 000多条虚拟链路(VL)的AFDX拓扑,采用分组思想带来的端到端延迟优化程度平均可达24.21%[47],后续相关改进可以参考文献[48-49]。
同时存在考虑流量调度偏置的网络演算方法[50],通过定义绝对偏置量(definitive offset)将源端系统流量不同的调度偏置与周期性的虚拟链路相关联,进一步利用相对偏置量(relative offset)计算同一分组内不同流量到达曲线组合的上包络,以此优化消息延迟计算。在工业应用规模例子中,利用消息偏置得到的端到端延迟上界与分组网络演算方法相比平均减少了49.93%[50]。消息调度偏置往往来源于不同分区执行窗口相对于主时间框架(MAF)的位移,由此导致属于不同分区的消息之间存在固定偏置。因此,调度偏置可以认为是消息产生时刻之间的一种固有属性。
针对TTE网络同样存在利用网络演算进行延迟计算的文献。由于TT流的强制抢占性特征,直接将TT流考虑为高优先级流,利用基本网络演算理论进行速率约束(Rate-Constrained,RC)流延迟分析会带来计算上的乐观性[51]。考虑在每个TT触发窗口前增加一个最大帧长的保护带宽(guard band)再利用基本网络演算理论进行RC流延迟,又会导致结果过于悲观[51]。Zhao等[33]在TT流量多孔(porosity)调度模型[52]的基础上,通过引入偏置量[50]计算TT流量到达曲线组合的上包络,进而获得节点对RC流量的服务曲线,从而实现RC流量端到端延迟上界的分析;并进一步[34]在抢占传输模式(preemption mode)和及时阻止传输模式(timely-block mode)下,对比不同TT流量调度密度以及预留方式下网络的实时性能,发现RC流量的延迟上界在TT流量稀疏(sparse)排列、动态(dynamic)预留时比密集(intensive)排列、静态(static)预留时更紧。
基于基本网络演算理论,以及其分组思想进行的网络性能分析还见于针对其他总线式、交换式[53],或者异构网络[54]的性能分析工作,同时还存在利用典型组网参数进行网络性能预测的泛化网络演算模型[55],以实现典型组网特征下的网络性能画像。
确定性网络演算分析结果可以作为网络性能验证及认证的基本参考数据,但往往也过于悲观。考虑到某些非安全关键航电应用在设计过程中允许在部分帧错过截止期限的情况下仍能提供准确的结果,可以使用随机网络演算分析流量延迟最坏情况下的概率上界,即:允许数据帧在一定概率范围内超过该上界。Chang等[56]最早提出了一种基于确定性流量和确定性服务的统计上界模型。Vojnovic和le Boudec[57-58]针对单交换机简单模型使用Hoeffding不等式给出了消息延迟概率上界分析方法。Ridouard等[59]对Vojnovic方法进行扩展,将随机网络演算理论应用于多跳AFDX网络中,介绍了FP/FIFO调度策略下概率延迟上界计算方法。赵露茜等[60]通过切诺夫(Chernoff)边界定理构造TTE网络中RC流量的两状态伯努利分布模型,得到概率保证下的延迟上界,与利用确定性网络演算获得的确定性延迟上界对比,结果表明随机网络演算模型可以有效减小确定性网络演算模型性能分析的悲观性。
2.2 轨迹法

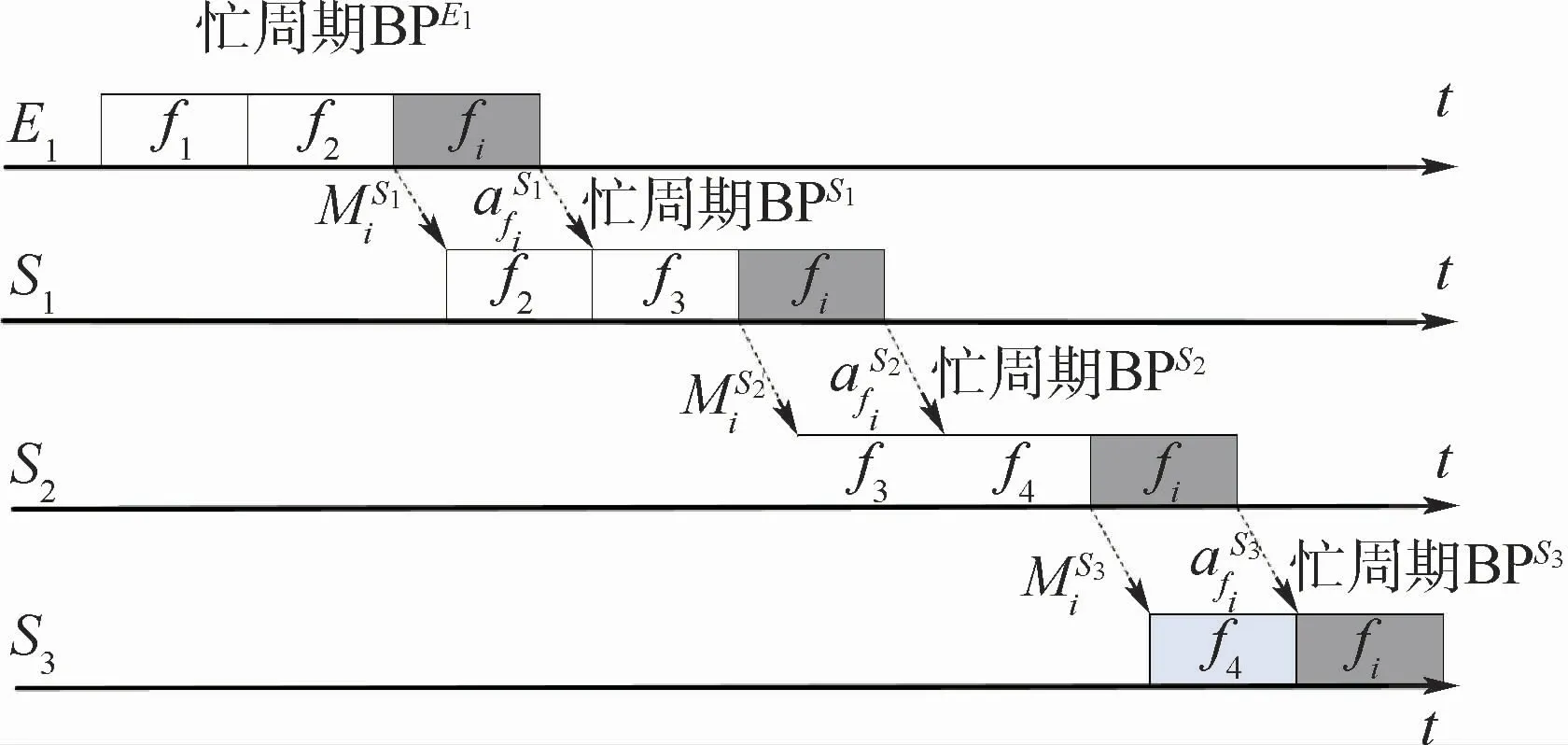
图2 轨迹法分析模型Fig.2 Trajectory approach andlysismodel
轨迹法最早由Martin和Minet[14]提出,约定节点Nh处与数据帧fi相匹配的繁忙区间[t1,t2)内无空闲时间,且所有在时刻t1之前到达Nh的优先级高于或等于τi的数据帧在繁忙区间开始时均已到达并准备输出,由此推导出FIFO策略下端到端最坏延迟计算公式。之后Martin和Minet[15]通过引进参 数Xi,t和δi分 别 表 示 高 优 先 级数据帧以及非抢占传输模式对fi传输的最坏影响,进一步完善轨迹法使之适用于采取FP调度策略的分布式系统。


类似于流量调度偏置在网络演算中的应用,也可以在轨迹法中引入调度偏置以进一步优化消息端到端传输延迟[66]。其基本思想来源于对数据帧干扰窗口的可重叠程度的判断:当调度偏置导致相干数据帧到达窗口不重叠时,则相干数据帧不会对待分析流形成阻塞干扰;反之,则存在阻塞干扰。
相比于网络演算方法,轨迹法的计算紧性得到了10%[47]以上的程度提升,但依然存在固有的计算悲观性,Li等[67]分析了轨迹法悲观性的来源,认为包括:低估了序列化影响、高估了竞争流负荷、高估了忙周期等。通过构建可达不利场景(reachable unfavorable scenario)[26]实现轨迹法计算悲观性的评估,在工业应用规模例子下,分组轨迹法的平均悲观性在12%[67]左右。
基于轨迹法的实时性能分析手段还可以见于针对其他组网协议的研究工作,如:AVB(Audio Video Briding)[68]、TTE[69]等。
同时存在以轨迹法为基础而发展的类似实时性能分析方法,如转发延迟分析法(Forward endto-end delay Analysis,FA)[70],能够处理链路最大瞬时负载超过100%情况下的延迟分析处理,在这种情况下传统轨迹法则不能得到闭合解。
2.3 整体法
整体法同样是一种针对分布式实时通信系统进行实时性能分析的解析方法。所谓的“整体”并不是像轨迹法那样对数据流传输路径上的干扰进行统筹分析,而是通过引入时延抖动(jitter)和偏置(offset)刻画数据帧在每一个输出节点上的最大不确定性;然后从源端到目的端,依照上一节点计算的抖动和偏置,形成本级节点最大干扰分析的依据,由此又形成本级新的抖动和偏置;通过对各个输出节点的延迟进行累加从而获得最终端到端延迟分析结果。
整体法最初来源于任务调度分析[71],当考虑任务之间存在消息交互时,需要将整体法从任务调度扩展到网络调度。基于此目的,Tindell和Clark[16]首先给出了分布式系统中采用固定优先级任务调度和时分多址(Time Division Multiple Address,TDMA)通信调度模式下应用层到应用层的最坏延迟分析算法,通过迭代计算实现了任务到消息的整体调度延迟分析,并证明当处理器和总线物理链路的利用率低于100%时,迭代计算公式总是可以收敛的。随后,Tindell等[17]又将整体法扩展到采用定时令牌通信协议(timed token communication protocol)的分布式系统中。Spuri[72]沿用Tindell等[17]的思路,针对最早截止期限优先(Earlist-Deadline First,EDF)调度系统进行了任务与消息延迟的联合分析。以上研究工作中都假定通信系统采用总线形式。
Gutierrez等[73]将整体法应用到交换式AFDX网络中,考虑终端系统对信息的分包处理与调度发送,以及交换机对消息的存储转发过程,如图3所示。图中:Φi为消息的初始相位;Ji为释放抖动;LT为技术延迟;LTmin为最小技术延迟;JTech为最小固定技术延迟;Nbw为链路带宽;LS为交换机最大硬件延迟;LR为接收端最大技术延迟;LRec为接收端延迟;LTr为传播延迟;LSW为交换节点延迟;LVL为源端发送延迟。同时针对多包(multipacket)消息和子虚拟链路(Sub-VL)调度都一并进行考虑,相应的最坏传输延迟Di计算公式如下:

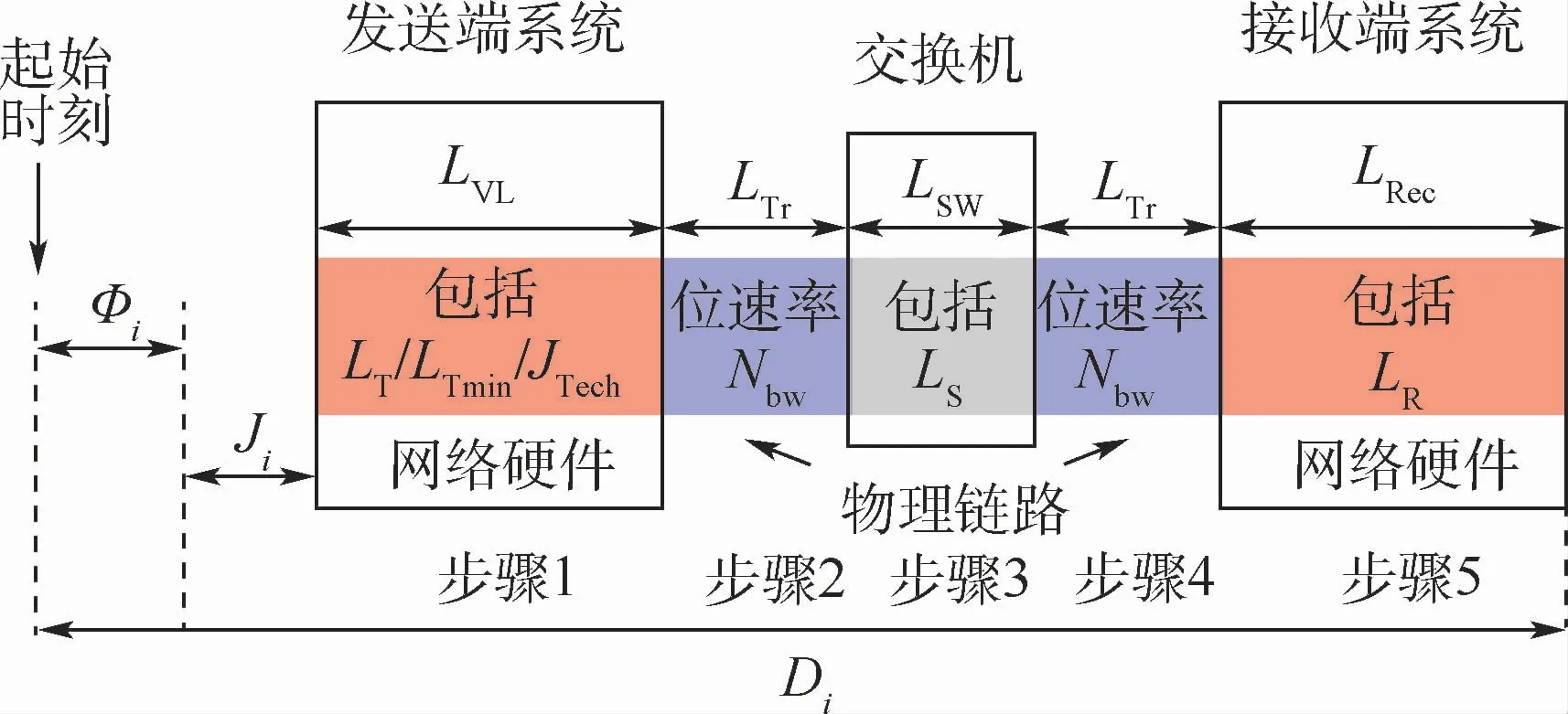
图3 整体法分析模型[73]Fig.3 Holistic method analysismodel[73]
3 仿真方法
仿真方法通过在计算机上运行程序来模拟系统的运行过程,以软件的方式记录并分析仿真输出结果,从而对真实环境下系统的实际运行性能进行预测。针对机载网络的仿真通常采用离散事件建模方法,通过对网络设备、通信流量,以及通信协议进行抽象,采用离散事件定义网络元素的交互行为,从而实现整个网络系统的仿真模拟,以此获取网络设计或优化所需的关键性能数据。
仿真方法一直都是机载网络实时性能评价的基本 手 段,从 总 线 式1553B[74]、TTP(Time-Triggered Protocol)到 交 换 式 FC[24]、AFDX[18]和TTE[19]等,存在大量的文献探讨其仿真方法,通常将网络元素(例如:端系统、交换机)分解为单向链路、缓冲区、解复用器和调度复用器等基本元素,并把系统性能评价归结为排队问题。
民用领域下存在大量关于FC应用于存储局域网(Storage Area Network,SAN)的仿真评价研究[75]。考虑到航电环境下FC组网的实时性能和复杂性,文献[24]从航电系统对数据传输的需求出发,在协议分析的基础上,将不同拓扑结构的网络抽象成终端与交换机模型的组合并分别建模,构建了适合航电环境的FC网络仿真平台。
针对AFDX网络仿真建模,Charara等[18,76]考虑终端系统的应用调度、流量整型、复用和解复用队列,以及交换机的输入、缓存和输出队列等模型,在 QNAP2(Queuing Network Analysis Package)[77]环境下对AFDX网络消息的端到端延迟分布情况进行了统计。类似的工作还包括:基于排队网络仿真机制(queueing network simulation mechanism)[78]的仿真模型等。特别的,Scharbarg和Fraboul[79]将VL相干流量分成3类:直接相关流量、间接相关流量、无关流量,通过剔除不影响虚拟链路VLi沿指定路径Pi传输的无关虚拟链路,得到VLi在AFDX网络中传输时的VL影响子集,可以有效减少仿真空间,支持对大规模AFDX网络进行快速仿真和增量仿真。
对TTE网络进行仿真的方法基本参照AFDX网络,但是更强调TTE网络支持不同关键性等级的通信行为以及时钟同步过程。例如Abuteir和Obermaisser[80]根据指定的TT通信调度表与RC通信参数要求,对TTE交换机、终端系统和故障注入器(fault injector)3种通用模型构件进行建模,并在OPNET平台仿真分析网络流量的时延和抖动。此外还存在针对时间同步精度,以及其对通信层面影响等仿真研究。
4 模型检查方法
模型检查(MC)是一种适用于有限状态的形式化建模与验证方法[20],对实时系统的模型检查多基 于 时 间 自 动 机(timed automata)理 论[21,81]。时间自动机通过一个有限状态机加上一组时钟描述检查模型,包括位置、有向边、时钟变量、同步信道变量、本地变量和全局变量等要素。其中位置变量受到不变量约束,有向边受到守卫条件约束,并支持同步信道耦合和时钟更新,当有向边的守卫条件和目的位置的不变量约束同时满足时,时间自动机执行位置的转移。模型检查的本质是以时间自动机位置的转移体现系统状态的改变,通过遍历系统所有可能的场景获得准确的消息最坏端到端时间延迟。
Charara等[76]最早应用模型检查方法进行AFDX网络性能分析,使用各端系统产生的数据帧序列及各帧序列第1个数据帧的起始时刻来标记AFDX网络的不同场景,通过全局变量和同步信道实现不同自动机之间的交互,并利用多个时间自动机的积来构建完整的AFDX网络。在此基础上,将消息端到端时间延迟的求解问题转化为可达性问题,使用UPPAAL[82]工具对指定配置的小规模AFDX网络(仅包含8条虚拟链路)进行模型检查得到各消息准确的最坏传输延迟。
随着网络规模的扩大,采用模型检查方法进行状态遍历时无法规避状态空间组合爆炸问题。Adnan等[30-31,83-84]结合端系统对数据流的调度,利用分治法(divide and conquer)逐端口进行状态分解,证明数据流在FIFO策略下的最坏时间延迟只可能发生在特定场景,通过设计搜索空间优化算法以寻求有效场景子集,从而提高模型检查的遍历效率,可完成多达50条周期VL的最坏延迟准确计算,其示例如图4所示[83]。其中有向边守卫条件x=16/32/48依赖于数据帧调度偏置参数,update函数刻画数据帧的传输。
基于时间自动机的研究工作还见于用于实现时间自动机模型的硬件转换以及网络流量特性的约束和模拟等研究工作。

图4 时间自动机分析模型[83]Fig.4 Timed automata analysismodel[83]
5 对比分析与验证
5.1 计算紧性分析
本节主要以速率约束网络为应用背景,对上述各种实时性能评价方法的应用特征(feature)与计算紧性进行总结与定性对比。
网络演算方法因为易于理解与实现而成为最普遍使用的解析方法。其对到达曲线的上包络建模,对服务曲线的下包络建模构成了计算的基本悲观性;同时,利用输出曲线突发度增大模拟数据帧到达的不确定性,进一步扩大了计算的悲观性。采用分组技术或者引入时间偏置都是通过优化聚合流到达曲线来部分消除计算悲观性的有效方法。
相比于网络演方法,轨迹法更关注于构建数据帧在其传输路径上整体的最坏调度场景,克服了网络演算逐节点计算带来的悲观性,通常情况下轨迹法的延迟结果计算紧性更好,同样可以采用分组思想对轨迹法进行优化。但轨迹法依然存在固有的模型悲观性,当数据帧尺寸差异较大时悲观性更为明显[26]。
整体法通过对数据帧到达时延抖动的迭代计算,实现数据帧在每个输出节点的最坏延迟分析,然后对各个节点最坏延迟进行叠加形成最终端到端延迟。由于数据流进行传输时基本不可能在每个节点处都达到最坏情形,这种简单的叠加为整体法的计算带来了极大的悲观性。但整体法可以更好地与处理器的任务调度之间建立联系,同时具有更快速的计算效率。
仿真方法通过通信行为模拟,实现网络运行时行为仿真,是网络性能评价的常用方法,其仿真精度取决于模型精度。但仿真方法通常不能历经通信行为的所有可能状态,利用仿真方法获得的平均延迟提供了网络运行时态性能评价参考,但其可观察的最大延迟往往不具有对比意义。
模型检查可以实现消息最坏传输延迟的精确评价,但其对通信行为各态的遍历是一种穷举过程,当网络规模变大,流量变多时,受限于状态空间爆炸问题,模型检查方法往往无法在有限时间内完成延时计算。目前仅可以完成小规模网络分析(50条流量),而对实际工业规模的网络无能为力。
各种评价方法的计算紧性对比如图5所示,给出了消息传输延迟多次测量的概率分布示意,纵坐标为对应传输延迟的概率值。可以看到消息大部分传输延迟位于平均值附近,存在准确最大延迟和准确最小延迟的固有截断。图5可以定性表明:采用各种实时性能评价方法是为了实现准确最大延迟和最小延迟的估计。采用仿真方法获得最大延迟和最小延迟处于准确最大延迟和准确最小延迟之间。采用解析方法获得的是具有悲观性的延迟上确界,其与准确最大延迟之间的距离刻画了延迟分析的悲观性。而可达不利场景最大延迟很难实现精确最大延迟的模拟,不具有实时性能评价的确定性保障,只能作为实时性能分析的参考。
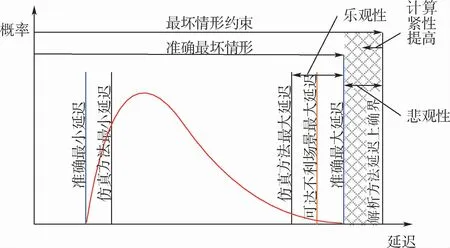
图5 不同实时性能评价方法计算紧性对比Fig.5 Calculation tightness comparison among different real-time performance evaluation methods
基于上述分析可以总结如下:
1)解析方法采用闭合公式进行延迟上确界的计算,主要的困难在于具有计算紧性的延迟上界的获取,采用分组方法可以提高其计算紧性。在进行系统实时性能的确定性分析以及为适航认证提供关键性能保障参数时,需要采用解析方法实现上确界分析。从计算原理上看,轨迹法的计算紧性优于网络演算方法,整体法次之,但整体法更加易于与处理系统性能分析集成。
2)仿真方法提供了系统运行状态性能评价的参考。在进行系统实际运行状态的性能评估时可以采用仿真方法进行模拟,其平均延迟可以代表系统运行时的大部分性能。
3)模型检查方法虽然能够提供精确的最坏延迟上界分析,但原理上其不具有大规模组网场景应用的手段。
5.2 简单拓扑对比
本节以典型文献案例对采用上述实时性能评价方法的计算结果进行对比。为了更好地体现不同方法之间的可对比性,消息端到端延迟统一起始于数据帧被提交到流量整形器的时刻,而结束于数据帧最后一个比特被目的端系统接收到。本文中分析的端到端传输延迟不考虑应用层面任务调度形成的延迟。对于消息的排队策略考虑最简单的FIFO模型。不失一般性,在本文讨论的案例中暂不考虑消息的优先级,以更好地与已有文献资料进行对比。
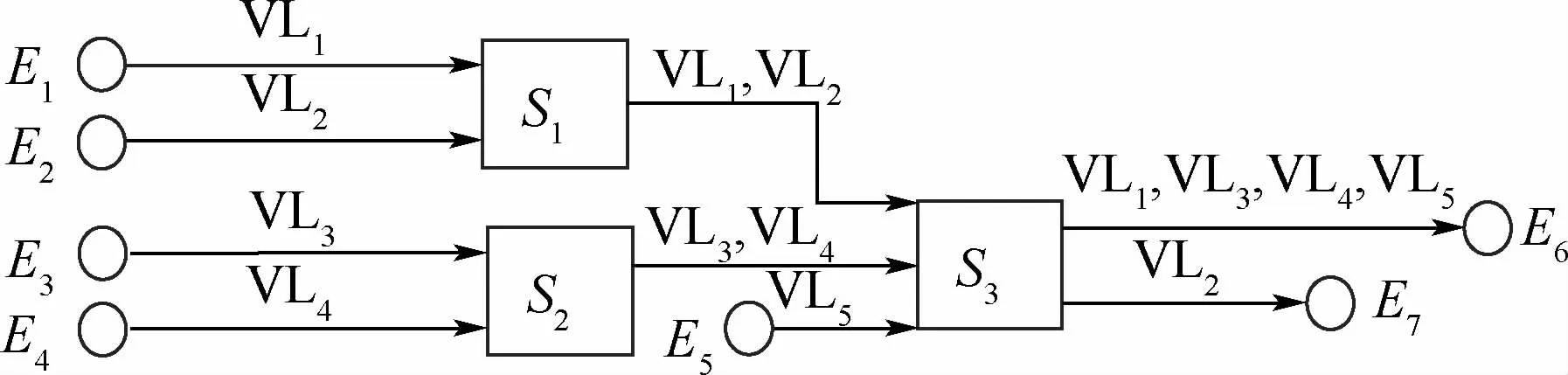
图6 典型小规模组网案例[26]Fig.6 Typical small-scale networking case[26]
以图6所示的典型小规模网络拓扑[26]为例说明不同分析方法的分析特点和计算紧性,该拓扑 结 构 在 其 他 多 个 文 献[47,61,73]中 也 得 到 有 效 展示,但本文给出上述所有评价方法的直接对比。简单网络包含7个终端系统和3个交换机,物理链路的传输速率C=100Mbit/s,交换机的技术延迟LT=16μs。网络中5条虚拟链路的具体传输路径如图6所示,且具有相同的带宽分配间隔(BAG=40μs)和最大帧长(Smax=500 Bytes)。各种方法对比结果如表1所示,其中仿真模拟运行时间为1 h。
在表1中不仅给出了各条VL在不同实时性能评价方法中获得的端到端传输延迟值,同时以模型检查结果为对比标准,给出了不同实时性能评价方法的相对计算紧性。可以看出:采用分组策略的分组网络演算方法和分组轨迹法相比于各自的基本方法,其计算紧性都有不同程度的提升。比如:针对VL1,分组网络演算最坏延迟273.6μs小于基本网络演算结果313.2μs,计算紧性也从基本网络演算的1.151变化到分组网络演算的1.006,因此也就更接近模型检查结果,也即:更接近真实最坏传输延迟结果。对于该例,无论是否带分组策略,轨迹法都优于对应的网络演算方法。整体法的计算紧性略好于基本网络演算方法,但比基本轨迹法差。模型检查可以获得精确的端到端最坏传输延迟。在本例中,模型检查结果与分组轨迹法一致,说明了分组轨迹法具有不俗的计算紧性,分组网络演算方法略次之。仿真方法获得最大可观察传输延迟明显小于真实最坏传输延迟,而平均值与最小可观察传输延迟十分接近,这种倾向性来源于本例子中较小的网络传输负载,即使考虑链路最高负载情况(链路S3→E6),也仅仅只占用了0.4%的链路物理带宽。在置信度为Q4(99.99%)水平下,随机网络演算结果低于模型检查结果,表明随机网络演算在Q4条件下还是引入了计算的乐观性。
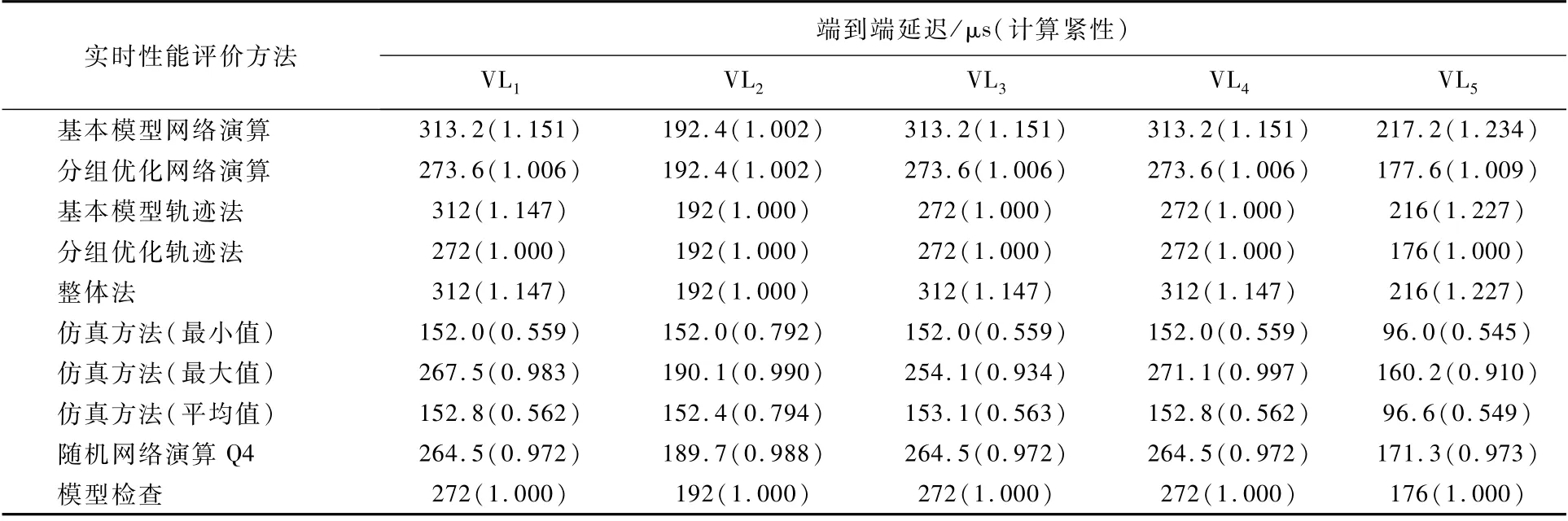
表1 小规模组网案例端到端延迟及计算紧性分析结果Tab le 1 Analysis resu lts of end-to-end delay and calcu lation tigh tness for sm all-scale networking case
5.3 工业组网案例对比
考虑典型工业规模下的组网案例[76,79],其拓扑结构如图7所示,一共包含8个交换机,1 000余条虚拟链路。

图7 工业组网案例Fig.7 Industrial networking case
由于缺乏具体的配置信息,本文采用随机方法生成这些VL的配置。具体来说:每条VL的源节点和目的节点随机从端系统列表中进行选取;参照ARINC 664 P7协议规范[4],从[2,128]ms范围内按照2的幂次率随机生成虚拟链路的BAG;从[0.05,0.3]Mbit/s范围内随机生成虚拟链路的持续流比特率ρ;根据随机生成的比特率ρ和BAG,反推虚拟链路的最大帧长,当最大帧长大于1538Byte时将其截断为1538Bytes。当流量生成完毕后,结合最短路径和流量均衡策略对这1 000条VL的路径进行自动分配,然后实施上述实时性能评价方法。由于缺乏真实最坏传输延迟的评价手段,各种方法计算紧性的对比采用分析结果的相对比例进行刻画;针对多条VL,采用算术平均值形成不同方法计算紧性的整体性评价结果,即

式中:N为VL的条数,在本案例中N=1 000。
分析结果如图8所示,并在表2中进一步给出其对应的统计结果。
图8以分组优化网络演算结果为参考值对其他各种方法的结果进行了归一化处理。从图8中可以看出:对于本案例,基本模型网络演算结果的计算紧性最差(图8中最外围边界),采用分组优化思想之后,其平均提升程度达到了22.9%,与文献[47]中给出的24.2%非常接近。整体法次之,相比于分组优化网络演算方法,其计算紧性平均差16.9%,但依然优于基本模型网络演算方法。基本模型轨迹法优于整体法,但弱于分组优化网络演算方法,相比于分组优化网络演算方法,其计算紧性平均差8.5%。当采用了分组思想之后,分组优化轨迹法具有了更高的计算紧性,相比于基本模型轨迹法,其平均提升程度达到了9.6%。分组优化轨迹法与分组优化网络演算方法相比,两者针对不同的虚拟链路具有不同的计算紧性,但平均下来分组优化轨迹法具有更好的效果,在本案例中,其计算紧性优势平均为2.4%。针对随机网络演算,对于每条VL,其在置信Q6(99.999 9%)水平下的计算结果均大于在置信Q4水平下的计算结果;总体上看,Q4结果为分组优化网络演算结果79.6%,而Q6结果为分组优化网络演算结果的86.5%。

图8 1 000条VL不同实时性能评价方法延迟分析结果对比Fig.8 Delay analysis result comparison among different real-time evaluation methods for 1 000 VLs

表2 工业组网案例计算紧性分析结果Table 2 Calculation tightness analysis resu lts for industrial networking case
采用仿真方法可以实现目标网络运行时的行为模拟,在平均延迟方面具有统计的意义。但是受限于其稀有事件的可遍历性,采用仿真方法很难覆盖所有事件中真正造成最坏阻塞延迟的场景,因此其可观察的最大传输延迟只能是网络性能验证的参考。在本案例中,通过仿真方法获得最大传输延迟与通过分组优化网络演算方法获得延迟上界的比值大多数分布在15% ~35%的区间,统计平均值为19.3%,意味着解析方法最坏延迟应该比通过仿真方法获得的最大延迟大5倍左右,而Q6置信水平的随机网络演算平均是仿真方法最大传输延迟的4.5倍。这与文献[85]结论中采用10-6的概率保证条件下,利用随机网络演算获得的延迟是通过仿真方法获得的最大延迟的4倍保持一致。
6 结论与展望
近年来,计算机技术、网络技术的迅猛发展使得航电系统对数据通信的实时性能需求逐渐提高,FC、AFDX、TTE等交换式组网技术凭借其良好的实时性能保障机制成为新一代航空电子互连的典型方案,但同时也带来了实时性能评价的复杂性。
利用网络演算、轨迹法和整体法可以获得端到端传输延迟理论上界,采用分组策略和调度偏置可以进一步提升延迟上界分析的计算紧性。相比而言:基本模型网络演算方法计算紧性最差,整体法次之,基本模型轨迹法优于整体法,但弱于分组优化网络演算方法,分组优化轨迹法具有最高的计算紧性,但依然具有内在的悲观性。模型检查方法可以获得精确的端到端延迟上界,但是无法解决状态空间组合爆炸问题,不适应大规模组网分析。仿真方法提供了运行时行为模拟,但观察到的最大传输延迟不具有实时性能上界的保证能力。随机网络演算采用置信区间平衡了解析方法上确界的悲观性和仿真方法最坏延迟的非遍历性。
采用包含1 000条流量的工业组网规模案例对上述各种方法的分析结果进行了展示和对比。采用分组思想的网络演算方法的计算紧性平均提高了22.9%,分组优化轨迹法计算紧性平均提高了9.6%。相比于分组优化网络演算方法,分组优化轨迹法计算紧性优势平均为2.4%,Q6置信水平的随机网络演算结果平均为分组优化网络演算结果的86.5%。
针对机载网络系统实时性能评价的研究需要持续关注于:
1)针对时间触发/时敏调度机制下不同安全关键级别的流量延迟上界分析的优化。
2)网络演算方法、轨迹法、整体法等解析方法固有悲观性的分析和改善。
3)寻找所有可能场景的有效子集并优化状态空间遍历算法,以提高模型检查方法的计算规模。
4)结合分区调度的IMA系统层面的延迟分析方法。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
移动通信(2021年5期)2021-10-25
通信产业报(2020年43期)2020-01-15
小学生学习指导(低年级)(2019年3期)2019-04-22
东坡赤壁诗词(2018年3期)2018-07-16
小学生导刊(低年级)(2017年1期)2017-06-12
科技创新导报(2016年27期)2017-03-14
