
部分决策树在软件缺陷预测中的应用
2020-05-28 09:36张洋
软件导刊 2020年3期

摘 要:由于多个特征属性的存在以及属性间存在关联和冗余等因素,导致软件缺陷预测方法计算量较大,且降低了模型预测性能。因此,提出一种基于部分决策树(PART)的特征属性选择算法,使用PART作为特征属性选择的评价准则,然后采用SMOTE方法使数据集达到平衡后,运用回溯爬山算法搜索属性集子空间,找到最优属性子集,最后采用随机森林分类算法预测结果。通过在NASA MDP基础数据集上进行实验,并与基于相关性关系、主成分分析(PCA)两种特征属性选择方法进行比较,得出新方法在分类预测中的准确率比相关性分析方法高出1%~11%,比主成分分析方法高出3%~19%。所以该方法不仅能够有效选取特征属性子集,而且显著提高了分类预测精度及效率。
关键词:软件缺陷预测;部分决策树;特征属性选择;随机森林分类算法
DOI:10. 11907/rjdk. 191625
中图分类号:TP319 文献标识码:A 文章编号:1672-7800(2020)003-0182-04
Application of Partial Decision Tree in Software Defect Prediction
ZHANG Yang
(Ministry of Information Technology, Hunan Rural Credit Cooperatives Union, Changsha 410000, China)
Abstract:Because there is a connection between the existence of multiple attributes and attribute and redundancy, leading to large amount of software defect prediction method to calculate and reduce the performance forecast model, is proposed based on a PART of the decision tree (PART) feature attribute selection algorithm, using PART as an evaluation criterion of feature attribute selection, then the SMOTE method is used to balance the data set and the backtracking hill-climbing algorithm is used to search the subspace of attribute set to find the optimal attribute set, finally uses the random forest algorithm to predict the results. Through experiments on the basic data set of NASA MDP and comparison with two feature selection methods based on correlation and principal component analysis (PCA), it is concluded that the new method has the best effect and the accuracy of classification prediction is 1%~11% higher than that of correlation analysis method and 3%~19% higher than that of principal component analysis method. Therefore, the new method not only effectively selects the subset of feature attributes, but also significantly improves the accuracy and efficiency of classification prediction.
Key Words:software defect prediction;partial decision tree;feature attribute selection;random forest algorithm
0 引言
隨着计算机技术的快速发展,计算机软件的应用范围也越来越广,与人们生活息息相关的银行系统、电信系统、证券系统等都是通过计算机软件进行运作。同时在专业细分领域,越来越多软件系统逐步取代了人们原先需要手工处理的工作,比如银行自动柜员机、无人值守停车场以及正在研发的无人驾驶汽车等。因此,软件的可用性成为一个重要问题,但现实情况是没有人能开发出百分之百可靠的软件,即使号称具有99.999 999%可靠性的腾讯云也在2018年7月20日发生宕机,导致部分公司数据永久丢失,而且类似事件还在不定期发生,而软件缺陷是导致相关事件最主要的原因。因此,如何尽早尽快发现软件中的缺陷成为软件工程领域的主要研究课题之一[1]。
软件缺陷预测分为静态软件缺陷预测与动态软件缺陷预测[2],解决的主要问题是根据给定的软件描述信息判断软件是否存在故障或缺陷。目前采用的主要方法有数据挖掘[3]、神经网络[4]、逻辑回归(logistic Regression)[5]、支持向量机(SVM)[6]、贝叶斯模型[7]、集成学习方法[8]等。对给定的数据集进行特征属性选择,能有效减轻分类预测计算工作量,所以本文主要研究如何有效选择软件缺陷数据集中的特征属性,并进行软件缺陷预测。
1 相关研究
在软件缺陷预测研究中,有缺陷的样本数量一般非常少,而无缺陷样本数量很多,这种不平衡性严重影响了分类预测效果[9],所以首先需要解决数据集的不平衡问题。目前针对数据集不平衡问题有多种解决方法,包括:向上过采样补充少数样本方法[10]、向下欠采样减少多数样本方法[11],以及将过采样和欠采样相结合,减少多数类样本、增加少数类样本的方法[12]等。
众多学者针对软件缺陷预测数据集的特征属性进行了研究,如文献[13]将主成分分析方法(PCA)應用于特征属性选择,从而有效地对多数据集进行降维,同时解释了原始数据集特征间的关系;文献[14]提出一种基于互信息的特征属性选择算法,通过计算两个特征间的依赖关系辅助特征属性选择,并取得了一定效果;文献[15]提出一种基于聚类分析的特征属性选择方法,根据特征间的关联关系,使用K中心点聚类算法进行特征属性选择;文献[16]构建基于深度信念网与支持向量机的软件缺陷预测模型,使用深度信念网进行学习与分析,并依据该方法进行特征属性选择;文献[17]提出将遗传算法应用于特征属性选择,基于遗传算法的随机搜索特性找到一个最优特征集。
本文在静态软件缺陷预测基础上分析以上多种特征属性选择方法,提出基于部分决策树的特征属性选择方法,使用回溯算法调用部分决策树算法以判断特征属性集的预测能力,并选择具有最优预测能力的特征属性子集与随机森林分类算法相结合进行软件缺陷分类预测。通过NASA MDP数据集[18]上的实验表明,该方法能保留主要特征属性,在预测效果上优于其它两种方法。
2 基于部分决策树的特征属性选择方法
2.1 数据集平衡处理
本文借鉴SMOTE(Synthetic Minority Oversampling Technique)方法实现数据集的随机向上采样,以随机增加小类样本,使样本间达到平衡状态,具体实现步骤如下:
设测试数据集少数类的样本数为T?,需要插入N个少数类新样本,N为正整数。
(1)首先从该少数类的T个样本中找到样本?xi,并使用欧氏距离计算得到?k个近邻,记为{xi1,xi2,…,xik}。
(2)然后从近邻集合实例中随机选择一个样本?xik,并生成一个[0,1]的随机变量,新样本合成公式如式(1)所示。
(3)重复执行N?次步骤(1)、(2),最终生成N个新样本{xnew1,xnew2,…,xnewN}。
(4)输出平衡后的数据集。
2.2 部分决策树介绍
部分决策树(PART)[19]是一种不需要应用全局优化策略生成决策规则的局部优化决策树算法。具体实现策略是采用分治策略生成一组决策规则,然后从训练集合中删除所有符合该决策规则的实例,接着递归运行直到数据集中没有任何实例时结束,并返回决策规则集。用该方式生成决策规则不需要构建整棵决策树,而是在生成单个决策规则后,马上从生成树中删除决策规则子树,从而避免了早期泛化结果,同时加快了决策规则生成速度。基于部分决策树的算法能快速生成决策规则,且算法效率优于其它传统决策树算法。本文选择部分决策树以快速对特征属性集的分类能力进行预判,最后根据预判结果选择特征属性子集。
2.3 部分决策树特征属性选择
输入:属性集合(A1,A2,…,Am),属性个数为m,以及样本数据集合。
输出:最佳特征数据集 。
(1)对输入的样本数据集中的数据进行处理,删除重复数据,并计算数据集的不平衡度,不平衡度=无缺陷样本数/有缺陷样本数。
(2)判断样本类别不平衡度是否大于阈值minBalance,如果大于阈值,则先执行步骤(4),然后执行步骤(3),最后执行步骤(5)并返回结果,否则按顺序执行以下步骤。
(3)使用SMOTE随机过采样方法增加数据集中少数类样本数量,如果样本总数大于阈值minNum,则新插入到数据集中的样本比例为N=int(((多数类样本数量/少数类样本)-1)*100),否则按两阶段插入的方式首先执行第一阶段新插入样本数N1(N1=int((多数类样本数量/少数类样本)*100)),然后执行第二阶段插入新样本N2(N2=int(((多数类样本数量/少数类样本)-1)*100)),N=N1+N2。
(4)采用回溯的爬山算法遍历整个特征子集列表与分类正确率,找到分类预测能力最大的对应特征子集,其中爬山算法搜索范围k=5。具体过程为:①随机初始化一个属性子集,使用部分决策树计算属性子集的分类预测能力并返回;②根据搜索策略找到当前特征集,随机扩大特征集,并使用部分决策树计算特征集的分类预测能力,找到k个特征子集,保存与替换分类预测能力最大的特征子集及分类预测能力值;③回溯整个特征集,特征子集的分类预测能力不重复计算,重复步骤①和②,直到整个特征集都回溯完成。
(5)返回预测能力最大的特征子集。
3 实验结果与分析
3.1 数据集
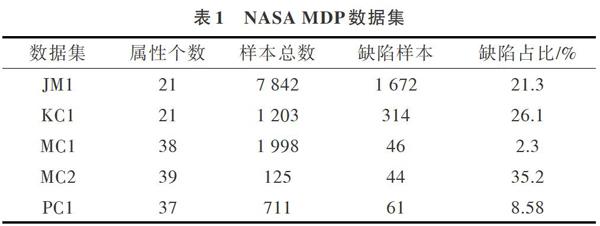
本文采用NASA公布的MDP软件缺陷数据集作为实验数据集。文献[20]发现研究人员广泛使用的NASA 数据集内部存在一些噪声,并证实该噪声将对研究人员得出结论的有效性造成影响,故对数据集进行了清理,本文使用的是清理后的数据集。NASA数据集描述了多个特征及大量样本数据,从多个角度描述了软件的静态状况。表1列出了数据集名称、属性数目、样本总数、有缺陷样本数、缺陷样本占比5个方面的数据集信息,并能直观看到数据集的不平衡性,缺陷样本占比约为2.3%~35.2%。
3.2 评价标准
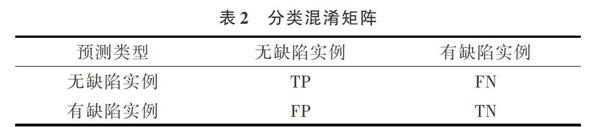
为有效评价各算法性能,使用分类混淆矩阵(见表2)表示预测完成后的各项结果数据,其中TP表示有缺陷样本被正确预测的数量,FN表示无缺陷样本被预测为有缺陷样本的数量,FP表示有缺陷样本被预测为无缺陷样本的数量,TN表示无缺陷样本被正确预测的数量。
准确率(Acc)用于评价有缺陷样本和无缺陷样本都被正确预测的个数之和在整个样本中的比例,体现了算法的全局正确性。
AUC值是以查全率为纵坐标、以误报率为横坐标构成的曲线与坐标轴围成的面积,取值区间为[0,1]。其值越接近1,表示分类器预测性能越好。
G-mean值是综合考察无缺陷/有缺陷样本被正确预测以及无缺陷/有缺陷样本被错误预测的指标,比如样本被正确预测的概率高,同时被错误预测的概率也高, G-mean值则会比较低,若相反则会较高。
3.3 实验结果与分析
本文经过多次实验得出,在样本差异较大的数据集上先进行特征属性选取,再对数据集作平衡处理,能保留更多特征属性信息,而且在样本数较少的情况下无法发挥特征属性选择方法的优势,故本文设定算法的两个变量minBalance=10,minNum=300。实验主要分为4个步骤:①采用SMOTE方法对数据进行过采样,使数据集达到平衡;②使用本文提出的特征属性选择方法找到预测能力最好的特征属性集合,表3列出了使用本文方法选择的特征属性集合;③使用随机森林分类算法作为基分类算法,验证选择特征属性的预测效果;④在步骤①的基础上,基于WEKA平台实现基于关联规则方法和PCA方法的特征属性选择,然后使用随机森林分类算法和J48决策树算法对生成的特征属性子集进行分类预测,并与本文方法预测结果进行比较。其中表4列出了使用随机森林算法对上述3种特征属性选择方法选择的特征属性子集进行分类预测的结果比较情况,图1则以直方图形式更直观地展示了使用J48决策树算法对上述3种方法选择的特征属性子集进行分类预测的对比情况。
通过表3可以看到,本文方法选择的特征属性子集在随机森林分类算法和J48决策树算法上的分类预测精度都比较高,说明本文提出的特征属性选择方法相比另外两种方法能更有效地选择特征属性,而且分类预测效果较好。图2列出了使用随机森林分类算法在特征属性选择前后算法建模时间的对比曲线,可以直观地看到选择特征属性后,预测算法建模计算时间明显减少。
4 结语
本文针对在软件缺陷预测中数据集属性数目多,且存在冗余的现象,以及多属性导致的计算量过大等问题进行研究,提出一种基于部分决策树的特征属性选择方法并进行软件缺陷预测。通过在NASA MDP数据集上进行实验,并与基于PCA与相关关系方法的特征属性选择方法选择的特征属性子集,在随机森林分类算法和J48决策树算法上进行缺陷预测性能对比。实验结果表明,本文方法选择的特征属性子集有很高的分类预测精度。同时本文还验证了精简的特征属性子集在分类预测算法上建模时间较短,且样本数量越多,两者差距越大。虽然本文方法测试结果较好,但仍有一定的提升空间,所以下一步工作将研究如何集成多个特征属性预测方法,以实现更好的预测效果。
参考文献:
[1]基于机器学习的软件缺陷预测方法研究[D]. 徐州:中国矿业大学,2017.
[2]王青,伍书剑,李明树. 软件缺陷预测技术[J]. 软件学报,2008,19(7):1565-1580.
[3]李麗媛, 江国华. 一种面向软件缺陷预测的特征聚类选择方法[J]. 计算技术与自动化, 2018,37(2):126-131.
[4]JIN C,JIN S W,YE J. Artificial neural network-based metric selection for software fault-prone prediction model[J]. IET Software,2012,6(6):479-487.
[5]BRIAND L C,MELO W L,WUS T J. A ssessing the applicability of fault-proneness models across object-oriented software projects[J]. IEEE Transactions on Software Engineering,2002,28(7):706-720.
[6]LARADJI I H,ALSHAYEB M,GHOUTI L. Software defect prediction using ensemble learning on selected features[J]. Information & Software Technology,2015,58:388-402.
[7]OKUTAN A,YILDIZ O T. Software defect prediction using Bayesian networks[J]. Empirical Software Engineering,2014,19(1):154-181.
[8]WANG T,ZHANG Z,JING X,et al. Multiple kernel ensemble learning for software defect prediction[J]. Automated Software Engineering, 2016, 23(4):569-590.
[9]李勇,刘战东,张海军. 不平衡数据的集成分类算法综述[J]. 计算机应用研究,2014,31(5):1287-1291.
[10]CHAWLA N V,BOWYER K W,HALL L O,et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research,2011,16(1):321-357.
[11]SUN Z,SONG Q,ZHU X,et al. A novel ensemble method for classifying imbalanced data[J]. Pattern Recognition,2015,48(5):1623-1637.
[12]戴翔,毛宇光. 基于集成混合采样的软件缺陷预测研究[J]. 计算机工程与科学,2015,37(5):930-936.
[13]陈佩,辛云宏. 一种有效的加权物质分类方法[J]. 计算机与应用化学,2014,31(4):466-470.
[14]王培,金聪,葛贺贺. 面向软件缺陷预测的互信息属性选择方法[J]. 计算机应用,2012,32(6):1738-1740.
[15]刘望舒,陈翔,顾庆. 软件缺陷预测中基于聚类分析的特征属性选择方法[J]. 中国科学:信息科学,2016,46(9):1298-1320.
[16]甘露. 基于深度学习的软件缺陷预测技术研究[D]. 南京:南京航空航天大学,2017.
[17]陈翔,陆凌姣,吉人,等. SBFS:基于搜索的软件缺陷预测特征属性选择框架[J]. 计算机应用研究,2017,34(4):1105-1108.
[18]SHIRABAD J S,MENZIES T J. The promise repository of software engineering databases[EB/OL]. http://promise.site.uottawa.ca/SERepository.
[19]EIBE F,IAN W. Generating accurate rule sets without global optimization[C]. Proceedings of the International Conference on Machine Learning,1998:144-151.
[20]SHEPPERD M,SONG Q B,SUN Z B,et al. Data quality: some comments on the NASA software defect datasets[J]. IEEE Trans on Software Engineering,2013,25(9):1208-1215.
(責任编辑:黄 健)
收稿日期:2019-04-29
作者简介:张洋(1986-),男,硕士,湖南省农村信用社联合社信息科技部工程师,研究方向为软件测试。
