
基于混合神经网络的智能问答算法
2020-05-22 12:33:28付燕,辛茹
计算机工程与设计 2020年5期
付 燕,辛 茹
(西安科技大学 计算机科学与技术学院,陕西 西安 710054)
0 引 言
问答技术是为了让用户通过自然语言就可以与计算机进行交互的技术。但是由于目前问题和潜在正确答案之间的匹配度并不高,给智能问答带来了挑战[1]。
梁敬东等[2]提出了一种通过word2vec和LSTM来计算句子相似度实现的FAQ问答系统,模型相较于传统的算法较大提高了答案匹配的准确率;荣光辉等[3]提出的基于深度学习的方法解决了传统人工构造特征中特征不足以及准确率低下的问题;陈静[4]以句子的词向量矩阵作为模型的输入,以问答匹配的置信度作为模型的输出,提高了问答系统的准确率。类似的基于深度学习的智能问答算法可参考文献[5-8]等。
以上方法主要利用关键词对文档进行定位,得到的结果与用户想要的答案有一定差距。基于此提出了一种基于word2vec的考虑文档关键词之间关系的混合神经网络的智能问答算法。
1 LSTM_CNN算法模型的构建
LSTM网络解决了长时依赖问题[9]。LSTM在抽取特征之后,针对不同时序产生的特征状态,通过max-pooling或者avg-pooling获得最终的特征。无论是max-pooling或者avg-pooling只是对不同的特征做出最后的选择,因此提出的LSTM_CNN算法采用一些其它的技巧对特征进行选择。该算法即是对这里的特征选择进行改进,采用CNN算法的结构对所有的时序特征做出最后的选择,即LSTM_CNN算法。算法框架如图1所示。
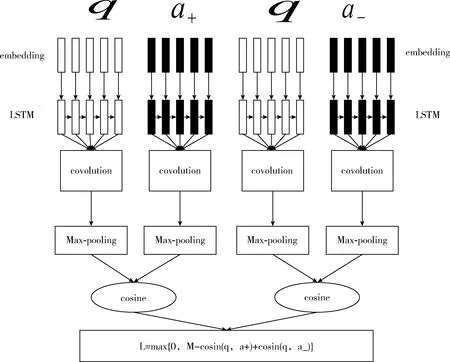
图1 LSTM_CNN算法流程
1.1 文本分词处理
为了选择合适的分词工具作为本文数据预处理操作中的分词处理,在同一实验环境下,测试了现有常用的3种分词方法(THULAC、LTP、JieBa)的性能。实验环境为Intel Core i5 2.8 GHz。评测结果见表1。

表1 SIGHAN Bakeoff 2005 MSR,560 KB
以上是对标准测试集的实验结果,同时也对各方法从速度上进行了实验,结果见表2。
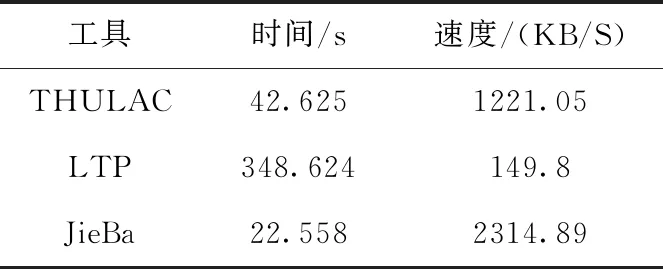
表2 数据集:CNKI_journal.txt(51 MB)
评测结果显示,在速度与正确性上,结巴分词(JieBa)均具有较好的性能,故采用结巴分词(JieBa)的Python版本进行分词操作。
1.2 词向量的构建
本文选取的语料库为搜狗新闻语料库,其中的语料来自搜狐新闻2012年6月-7月期间,国内、国际、体育、社会和娱乐等18个频道的新闻数据。
具体处理流程如图2所示。
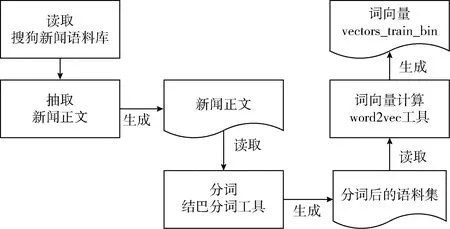
图2 词向量计算流程
1.3 数据预处理
本次实验以答案对的形式存储数据 (q,a+,a-),q表示问题,a+表示正向答案,a-表示负向答案。实验所用的训练数据已经包含了问题和正向答案,因此需要对负向答案进行选择,实验时采用随机的方式对负向答案进行选择,组合成 (q,a+,a-) 的形式。
1.4 词向量的表示
对所得到的问题、答案对的形式,利用word2vec将一个句子转换成固定长度的向量表示,从而便于进行数学处理。Word2vec矩阵给每个词分配一个固定长度的向量表示,这个长度可以自行设定,比如300,实际上会远远小于字典长度(比如10 000)。而且两个向量之间的夹角值可以作为它们之间关系的一个衡量。通过简单的余弦函数,计算两个单词之间的相关性,如式(1)所示
(1)
1.5 特征提取
LSTM_CNN算法选择共享的LSTM模型来计算问题和答案的语义特征。LSTM对输入的问题答案信息的词向量进行特征选择,可以对距离相对较远的词与词之间的联系选取出更好的特征。
CNN[10]最大的优势在特征提取方面。当使用LSTM模型计算的到问题和答案的特征后,再通过共享的CNN做进一步的特征选取,这种方法得到的实验结果性能更优。
1.6 目标函数的计算
采用问题和答案最终获取的特征,计算目标函数(cosine_similary),如图3所示。其中,P是1-MaxPooling; T是tanh层。目标函数计算如式(2)所示
L=max{0,M-cosine(q,a+)+cosine(q,a-)}
(2)
M是需要设定的参数margin,q、a+、a-分别是问题、正向答案、负向答案对应的语义表示向量。
2 算法的实现过程
2.1 实验条件及实验数据
本章算法的实验环境见表3,算法在不同的环境下计算时会产生一些差异。
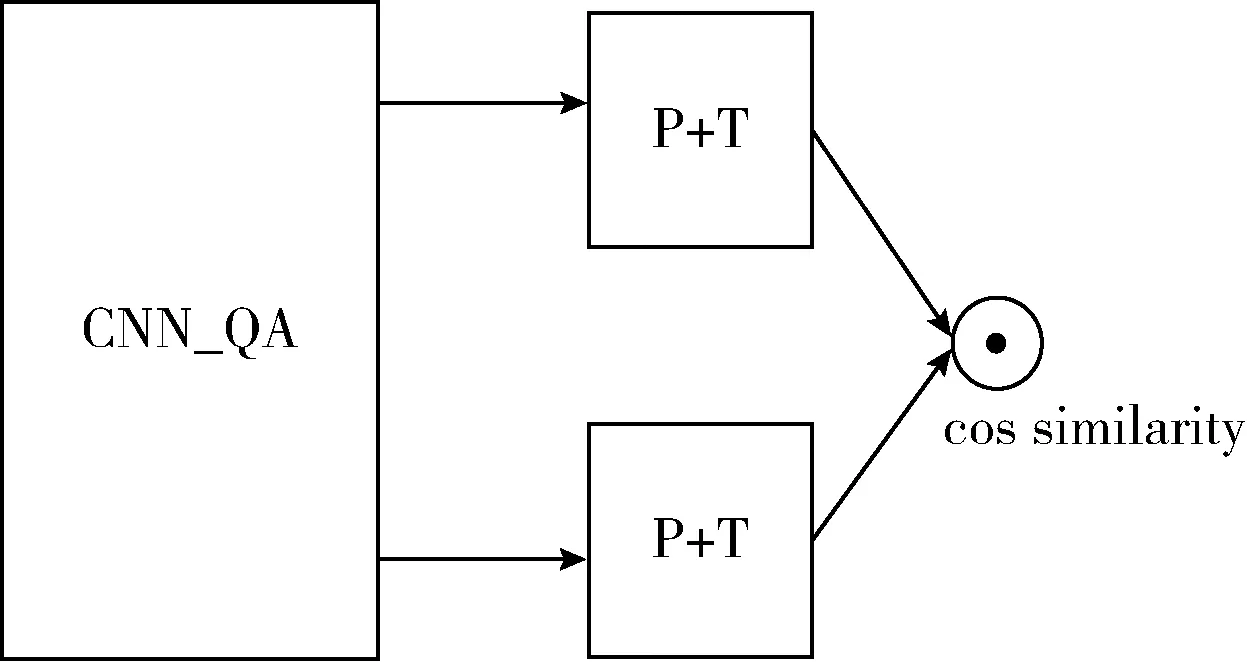
图3 计算目标函数

表3 实验环境
实验所使用的数据集来自第六届“泰迪杯”官方给出的全部训练数据train_data_complete.json(170.6 MB),测试数据test_data_sample.json(552 KB)。其中训练数据的格式为:问题-答案-标签。标签为1表示是问题的正确答案,标签为0是无关内容。测试数据的格式为:问题-答案,未标注标签。数据样例见表4。

表4 数据集示例
2.2 数据预处理
数据预处理需要对原始问答数据进行分词处理,数据集分词后的结果一部分如图4所示。测试集与训练集的区别为测试集的标签默认全是0。对原始数据进行分词处理后,再构建相应的词向量,构建的词向量结果如图5所示。

图4 数据集分词结果
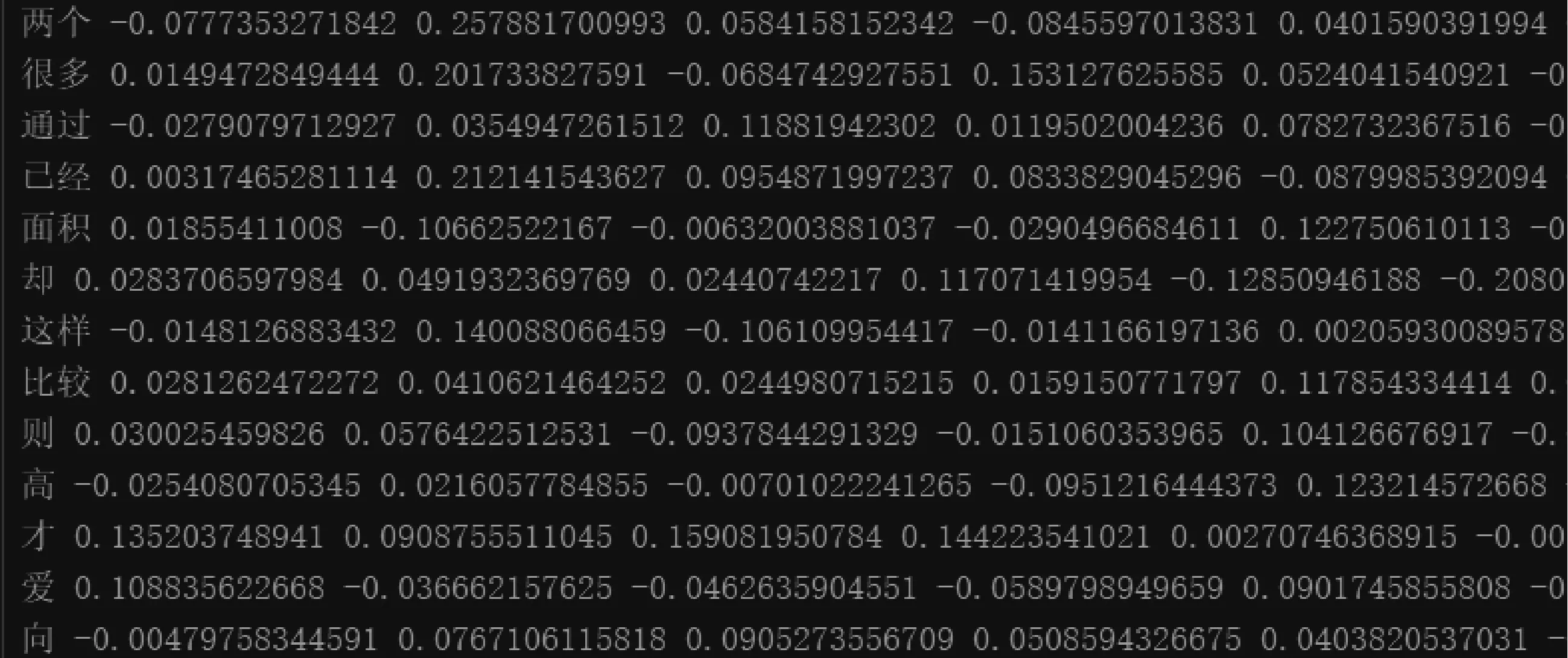
图5 词向量结果
3 实验结果及分析
3.1 实验数据
本模型使用结巴分词处理后的训练集、测试集数据以及词向量进行实验,数据集样例见表4。
3.2 实验过程
实验中训练设置的参数如下:学习率=0.05,每1000轮验证一次,滤波器的尺寸=[1,2,3,5],滤波器的数目=500。经过多次实验发现,训练迭代轮数为3000次即可达到预期的目标,所以本次训练迭代轮数为3000轮。经过3000轮的迭代训练后,模型准确度已达到90%以上。已达到预期的训练目标。模型准确度随着迭代训练轮数变化的趋势如图6所示。
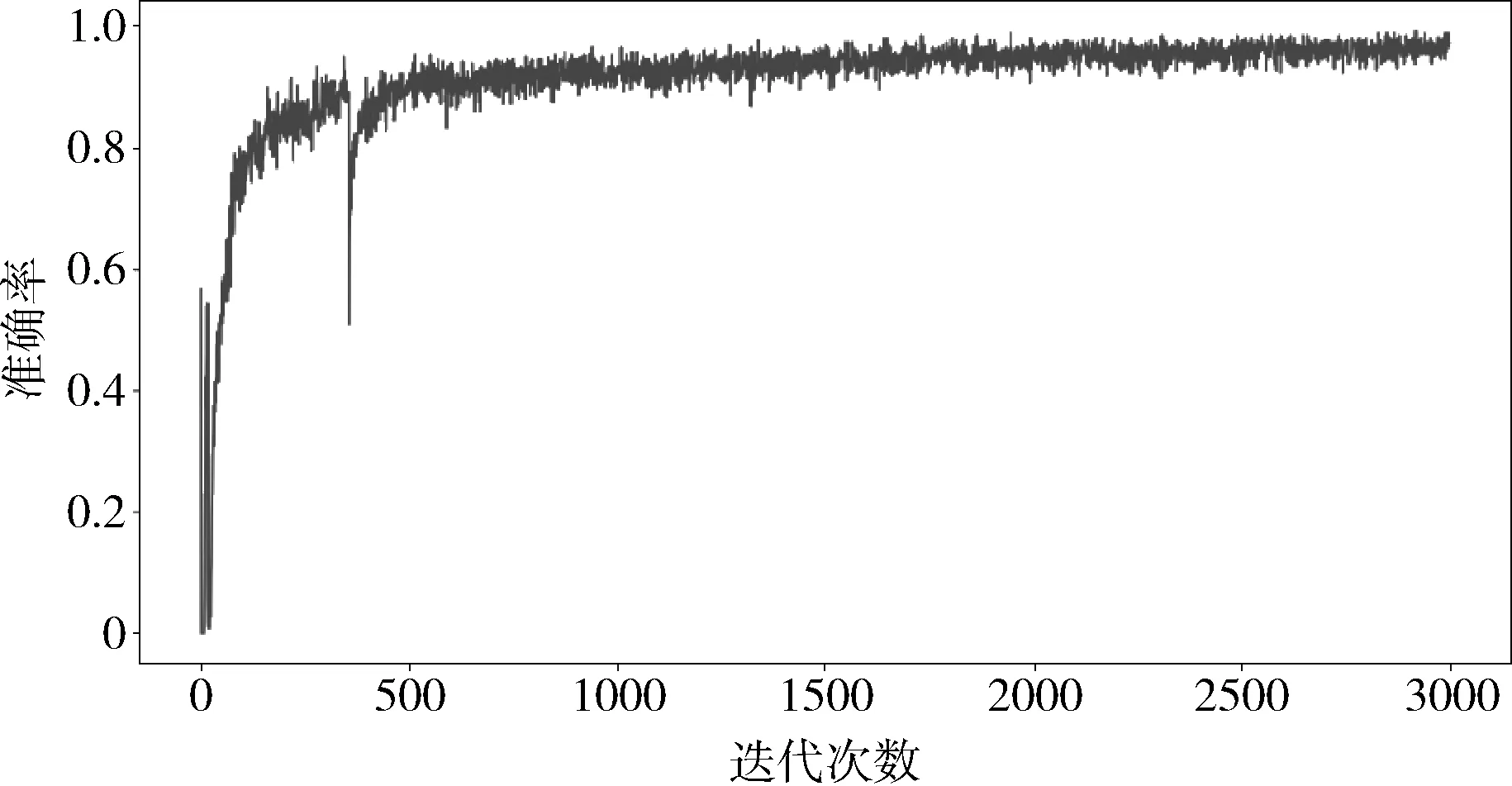
图6 模型准确度变化趋势
在模型的训练的过程中,为了对模型进行校验,在每经过1000轮训练迭代后,就会用测试集对模型进行校验,并利用当前的模型求解问题与候选答案的关联度,其值越接近1,则说明候选答案与问题的关联度越高,也能说明候选答案是问题正确答案的可能性越大。训练结束后,关联度集部分结果如图7所示。通过分析关联度集中的数据,本文设置0.83为正确答案与错误答案的界限,关联度低于0.83为错误答案,高于0.83为正确答案。根据此阈值,对测试集中的候选答案的标签进行标注。
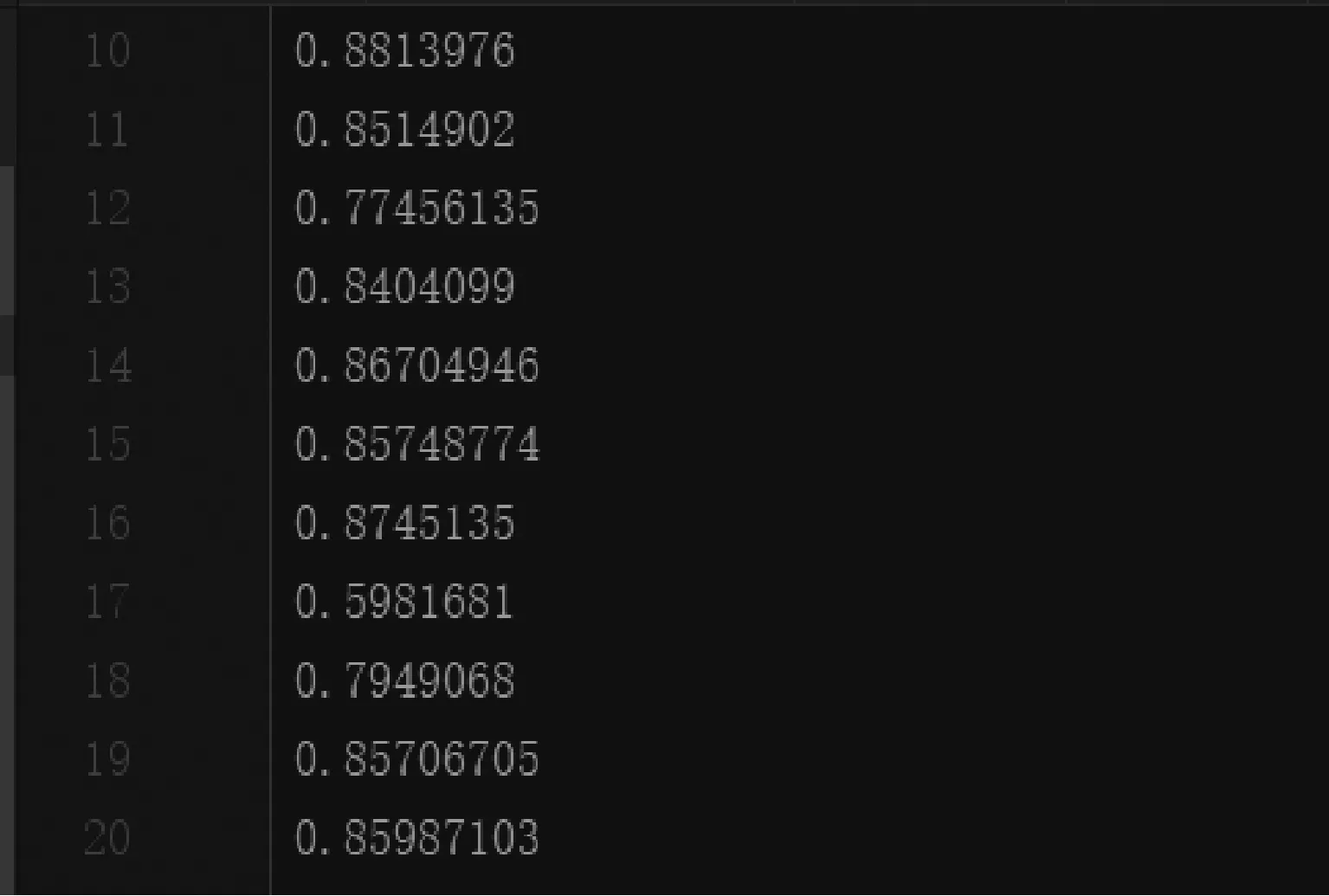
图7 测试集关联度集部分结果
3.3 实验结果分析
为了验证提出算法的有效性,将该算法分别与CNN和LSTM算法同等实验条件下进行了对比。实验结果见表5。
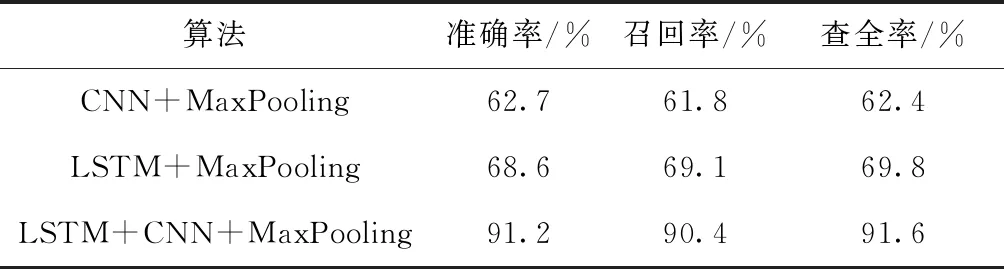
表5 不同算法的实验对比结果
由表5中数据可以看出,CNN与LSTM都是比较好的深度学习方法,对于自然语义处理尤其是LSTM独特的特点,通过循环重复利用网络模块,以便于更好处理语义之间的联系;CNN可以直接通过词向量作为神经网络的输入从而提取词语直接的特征值,不必人工提取特征,从而使得对大型数据的语义处理效率更高,通过将二者结合,实验结果验证了该算法的有效性。
4 结束语
本文对LSTM及CNN等方法进行了深入的分析与研究,并详细阐述了本文的考虑文档关键词之间关系的LSTM_CNN模型。但随着现实应用需求的不断变化,对智能问答算法的执行效率和答案的准确度也越来越高。因此未来还可从以下两点对智能问答模型进行深入研究:①在线文本的处理;②模型性能的进一步优化。未来可通过对模型算法的进一步优化,给出准确率更高的答案,从而进一步提高模型的性能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
智富时代(2019年6期)2019-07-24 10:33:16
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
高中生·天天向上(2016年9期)2016-11-22 09:10:34
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
河南科技(2014年23期)2014-02-27 14:19:15
