
基于机器学习的柴油机颗粒物浓度预测
2020-05-21 05:12邹浪何超李加强王艳艳谭建伟
车用发动机 2020年2期
邹浪,何超,李加强,王艳艳 ,谭建伟
(1.西南林业大学机械与交通学院,云南 昆明 650224;2.云南省高校高原山区机动车环保与安全重点实验室,云南 昆明 650224;3.北京理工大学机械与车辆学院,北京 100081)
随着科学技术的发展,减少空气污染的来源已成为一项重要任务。而应用于机动车的内燃机作为城市空气污染增加的主要原因,对人体健康危害尤为显著。研究表明,死亡率和发病率与人体接触包括颗粒物在内的污染物浓度之间存在联系[1-2]。因此,制定严格的法律法规限制污染源和污染物的排放水平,提高内燃机的燃烧效率,是减少尾气排放的重要措施。
与汽油机相比,柴油机因燃油经济性好、压缩比高、污染低及使用寿命更长久等优点,成为许多重型车辆及欧美轿车的动力装置。当前研究的主要方向是在不对内燃机机械结构作重大修改的情况下,寻找降低排放的有效途经。Mahmudul等[3-4]针对柴油机替代燃料进行了研究,研究表明,柴油机使用生物柴油时功率会略微降低,但排放的有害物质显著减少。针对自然吸气柴油机[5]、增压及增压中冷柴油机[5-7]、高压共轨柴油机[8]、二级可调增压柴油机[9]的减排研究以及以减排为目的的起动燃油喷射控制参数优化和匹配[10-12]研究已得到广泛开展。柴油机在高海拔地区工作时,大气压力和空气密度减小,吸入气缸的空气量也随之降低,导致柴油机的可靠性、燃油经济性和动力性下降,进而使柴油机尾气中有害物质增加。因此,建立不同海拔下发动机燃烧特性与污染物排放之间的联系至关重要。
研究人员[13-17]针对EGR、发动机转速、负荷、空燃比、喷油时间、温度、气缸压力等燃烧特性与颗粒物的形成进行了大量测试与研究。Agarwal[18]在恒定转速、不同燃油喷射压力和喷油正时工况下进行研究,结果表明,当燃油喷射压力较低和不断改善喷油时间时,燃油消耗率和制动热效率降低,但CO2,CO,HC和NOx的排放量减少。 Scafati等[19]在柴油机不同转速、负荷和EGR率等条件下对8~381 nm范围内的颗粒分布进行有效预测,绝对均方误差仅为3%~7%。Michael等[20]以柴油机点火延迟角、燃烧持续时间和峰值压力为变量,提取气缸压力作为神经网络的输入对HC,CO,CO2和NOx的排放进行预测。Y.H.Pu等[15]利用气缸压力预测15~1 000 nm的颗粒物粒径分布,结果表明,预测的PM数与实测值之间具有良好的一致性,其R2值达到0.93。利用气缸压力预测柴油机NOx和CO2排放[21-24]、炭烟排放[25]等已成为可行方法之一。
然而,在目前的研究中,通过对实际道路柴油机燃烧特性进行多海拔试验或数值预测,在此基础上对柴油机纳米颗粒进行精确、详细的建模预测尚不成熟。因此,本研究采用机器学习与神经网络相结合的方法,建立柴油机在不同海拔下基于气缸压力的颗粒物排放模型。
1 试验设备
试验采用了基于货车的发动机便携式试验台架,可以在不同实际环境中进行测试。采用的主要设备连接示意见图1。

图1 发动机便携式试验台架设备示意
当发动机在高海拔地区工作时,相同工况的喷油提前角变化不大,通过改变喷油脉冲的宽度来增加喷油量,以达到测试所需功率。试验用重型柴油机规格见表1。测试所用燃料为符合国Ⅳ标准的0号柴油,各项参数见表2。
选取CW440D电涡流测功机,实时测量柴油机的输出转速和扭矩。为实现气缸压力和燃烧放热率的即时显示,采用DEWETRON 5000燃烧分析仪对缸压传感器与角标仪所采集的数据按每0.2°曲轴转角间隔进行存储和处理。同时,使用DEKATI低压静电式冲击采集器(ELPI)实时采集不同粒径的颗粒物数浓度信息,在ELPI第一级冲击器后加入一片滤纸,使测量微粒尺寸扩展到7 nm,利用ELPI自带的软件数据处理功能获得颗粒物数量粒径分布,粒径分级见表3。
由于稀释比、湿度及排气温度对颗粒的数浓度和粒径分布的影响较大[26-28],因此,本次试验利用射流喷嘴稀释器对尾气进行二次稀释,以减少尾气中颗粒的凝聚、水分的凝结及挥发性物质的过度饱和导致的成核现象。此外,由于海拔对稀释比的影响较大,因此对稀释器的CO2体积分数进行测试,以此来确定稀释比。
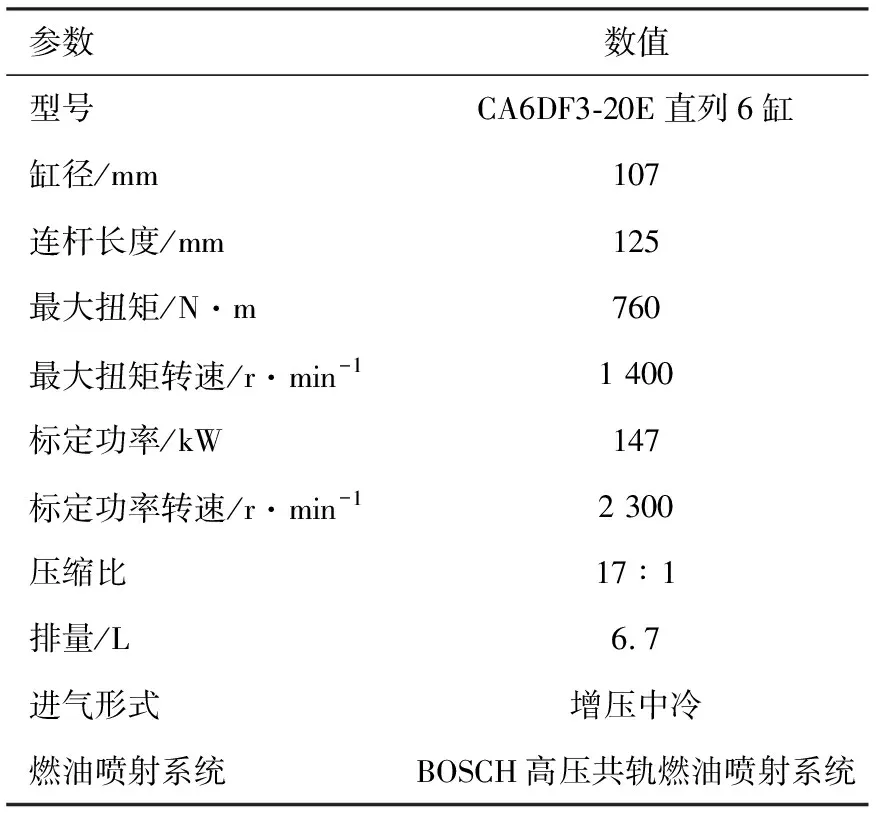
表1 柴油机技术参数

表2 试验柴油参数
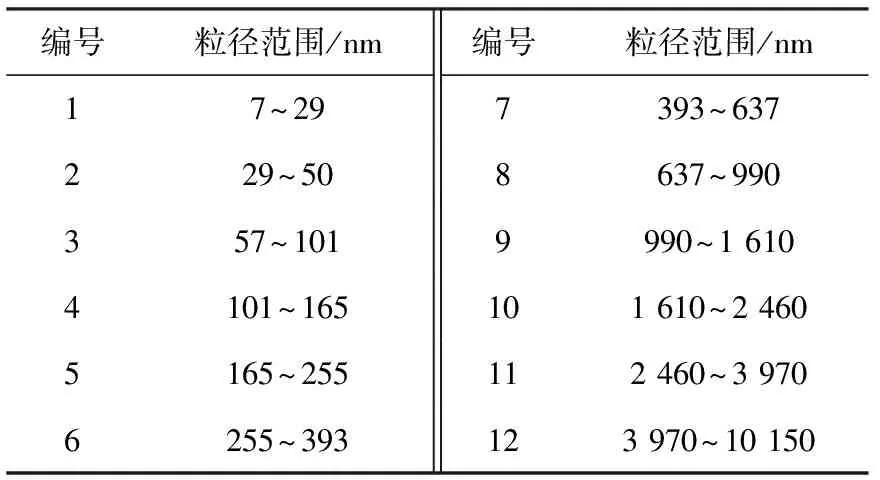
表3 ELPI粒径分级
2 试验方案
2.1 试验设计
该试验在4个海拔(0 m,1 608 m,2 408 m和3 284 m)下进行稳态工况测试,每个海拔下5个转速(1 400 r/min,1 600 r/min,1 800 r/min,2 100 r/min,2 300 r/min),每个转速下测试10%~100%共10个扭矩点,共计200个工况。在试验中,每个工况点的转速和扭矩保持不变,待发动机排气、机油及冷却水温度稳定后,再开始数据采集。经过多次测试,采集到大量气缸压力和不同粒径的颗粒物浓度数据,并对气缸压力进行快速傅里叶变换(FFT)平滑滤波及标准化处理,以降低干扰信号和各变量量纲的影响。
2.2 主成分分析法
主成分分析(PCA)是一种大数据降维的方法[29]。它的优点是将一组观测数值转换为主成分集的正交变换,用较少主成分表示复杂的多维数据,最大程度地反映原始数据的特征。在工程中,新的主成分也称为潜在变量、因子、荷载和模态。因此,主成分分析是目前探索性多元统计应用最广泛的方法之一,它广泛应用于计算机、图像识别及模型预测等领域。主成分分析原理公式为
(1)
式中:X∈RM为测试数据集,M为变量的维数;P=[p1,p2,p3,…pJ]为由主成分到组成的基向量矩阵;C为J个系数组成的空间矩阵;e为误差。
当J≪M及误差e达到一定精度时,由式(1)得到式(2),该式表明C的每个分量可表示与原始数据对应的特征向量。
C=X×PT或X=CT×A。
(2)
由于奇异值分解(SVD)具有信号降噪的作用[30],因此,对数据矩阵X进行SVD分解,其原理为
(3)
式中:X=(x1,x2,x3,…xn)∈Rm×n为任意实维矩阵;U∈Rm×m和V∈Rn×n为单位正交向量矩阵;当m≤n或m≥n时,奇异值矩阵为S=(diag(σ1,σ2,…σj0,0)∈Rm×n或其转置,且奇异值σ1≥σ2≥σ3≥…≥σj≥0 ;U的列向量uj是左奇异向量,是奇异值矩阵相对应的特征向量;V的列向量vj为右奇异向量。
2.3 模型设计
由于柴油机的燃烧周期和排放特性受大气压力、转速,负荷、温度、喷油时间、EGR率等参数的影响,因此,采用一个反向传播的多层前馈神经网络建立非线性映射模型。该模型能够建立两个数据集之间的相关性,并且适用于在输入和输出之间的数学或物理关系模棱两可或难以定义边界过程中的建模,例如基于气缸压力预测PM排放。
本研究选择单隐层的BP神经网络。BP神经网络是一种基于梯度下降与误差反向传播的学习算法,其目标是最小化训练样本与网络输出之间的均方误差。它具有自学习和概括的能力,尤其适合于解决复杂的内部机制问题,是目前最成熟、应用最广泛的人工神经网络。其拓扑结构见图2。在图2中,对原始数据的影响指标Z=(Z1,Z2,…Zm)进行主成分分析,其主成分X=(X1,X2,…Xn)作为BP神经网络的输入样本;Wij和Wjh分别是输入层与隐藏层、隐藏层与输出层的连接权重; 通过设定期望误差e来评估实际模型的精度,如果预测输出与实际输出之间的误差大于预期误差,则进行多次反向传播修正,直到预期误差终止,得到相对应的输出结果y。最终建立了主成分分析与神经网络的组合模型。

图2 BP神经网络结构
但BP网络易陷入局部极小值,初始权值和阈值随机性较大,稳定性差且收敛缓慢,为此采用贝叶斯函数最小化平方误差和权值,增强网络的泛化能力,避免过拟合,以达到优化的目的。
由于气缸压力直接影响发动机的功率输出、燃烧特性和排放特性,因而气缸压力数据成为分析发动机各种参数变化最为有效的工具。余林啸等[31-32]的研究表明,相同转速下随着扭矩的增大,柴油机最大燃烧压力增加,颗粒物的排放量也随之增大。由此可知,气缸压力与颗粒物的排放呈正相关关系。因此,神经网络的输入是经过主成分分析的气缸压力,输出为不同海拔下的前8级粒径范围的颗粒物数浓度,其中训练数据和测试数据比例为8∶2。模型的最大训练次数为1 000次,训练误差为0.001,学习率设置为0.01。
此外,对神经网络的输入输出数据进行归一化处理,提高训练的收敛速度。图3示出用于预测发动机输出纳米级PM的神经网络的总体方法。Z-score标准化和归一化原理分别见式(4)和式(5)。
(4)
(5)
式中:xij为原始数据,其中i为样本序号,j为变量维数;uj为均值;Sj为标准差;xjmax和xjmin为j维变量的最大值和最小值;Z和X为处理后的样本数集。
误差验证的评价指标包括绝对误差err、相对误差K、平均绝对误差MAE、均方根误差RMSE和模型运行时间TIME[33]。
err=ETM-ETS,
(6)
(7)
(8)
(9)
式中:ETM实际颗粒物浓度;ETS为网络预测值;J为变量维数。

图3 试验方案流程
3 试验结果及分析
3.1 气缸压力的主成分分析
在采用主成分分析法提取气缸压力轨迹时,需要大量的缸压数据,为此试验采集了每个燃烧周期-360°~360°曲轴转角(间隔0.2°)共计3 600个数据。柴油机的燃烧放热过程集中在着火延迟期、速燃期、缓燃期及后燃期,此时缸内压力变化最大,其变化趋势足以代表整个周期的燃烧特性。因此,选择活塞上止点-30°~45°曲轴转角[15]提取信息以减少数据分析的难度。本研究在每个海拔下,从每个工况随机抽取50个燃烧周期取平均值,得到4个海拔下50个测试工况共计75 000个样本,结果见图4,其中气缸压力越小,灰阶越黑。

图4 气缸压力数据灰度图
通过MATLAB对气缸压力进行数据分析,其奇异值见图5。由图可知,随着海拔的升高,奇异值总体呈现不同程度的微小增幅。这是由于随着海拔的增加,进气压力下降,燃料在缸内的滞燃期延长,燃烧始点延迟,引起最高平均燃烧压力下降,降幅约为7%[21],导致其他因素的影响增大。当j>10时,各海拔下奇异值σj/σi均小于1.22%,且前10个σ与奇异值总和之比大于94%,因此选择前10个σ作为有效奇异值进行特征提取。
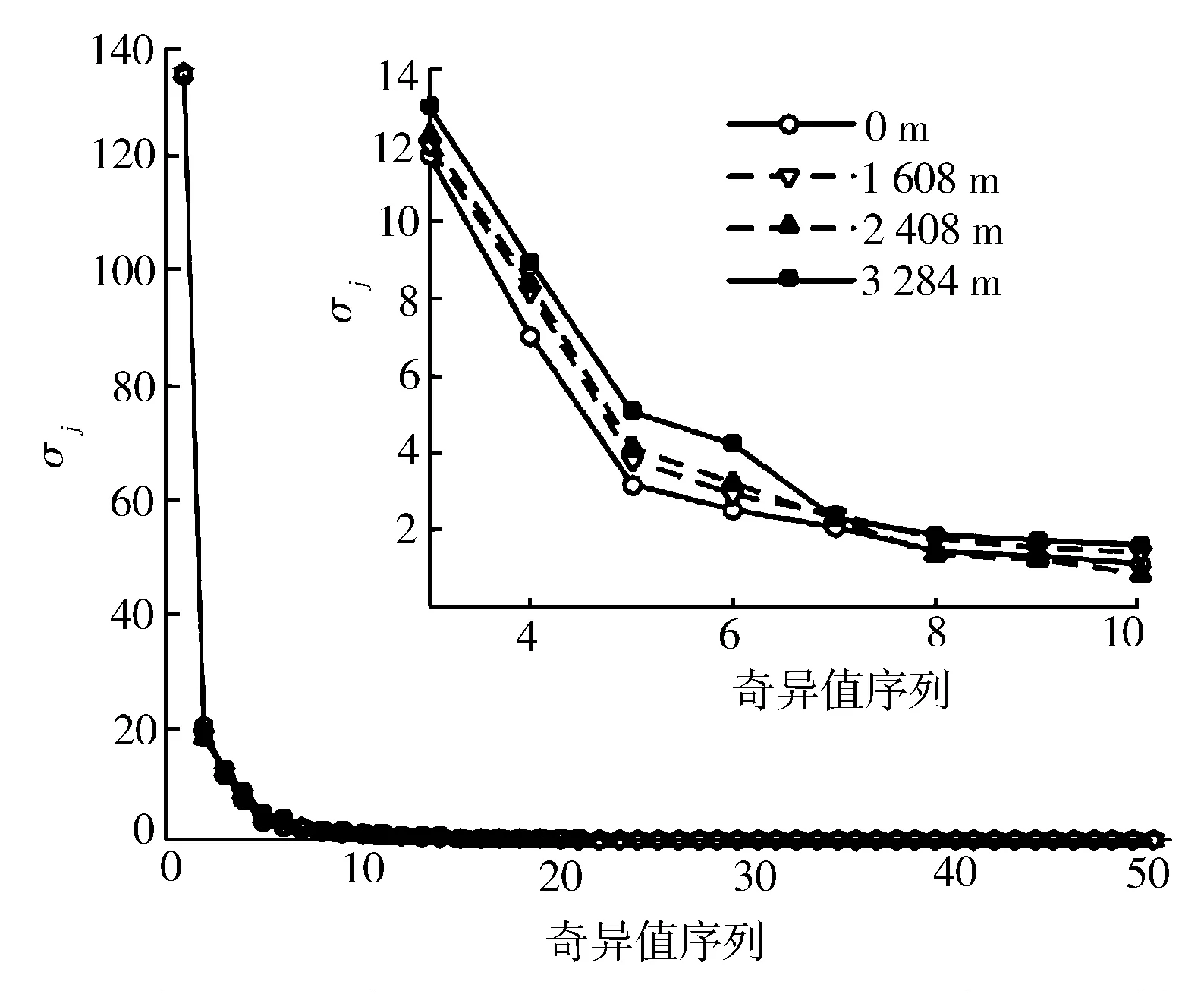
图5 不同海拔下缸压奇异值
对每个海拔下气缸压力的前10主成分进行重构分析,其中最高转速2 300 r/min下10%,50%及100%扭矩工况的重构曲线见图6,箭头为扭矩增大的方向。由图可知,重构压力与原始数据的特征高度吻合,不同海拔下主成分分析对气缸压力随扭矩的增加而增大的趋势影响较小。这是由于PCA的本质是空间坐标的变换,且数据结构保持不变,获得的主成分集是原始变量的线性组合引起的结果。图7示出重构值与实测值的均方根误差检验,由图可得各海拔均方根误差最大为0.069 MPa,数据信息的损失较少。此外,每个工况的相对误差不超过0.005 4 MPa,表明10个主成分提取原始信号的精度达到了94.6%。
综上所述,采用主成分分析气缸压力轨迹是一种可行方案。

图6 2 300 r/min下气缸压力重构曲线
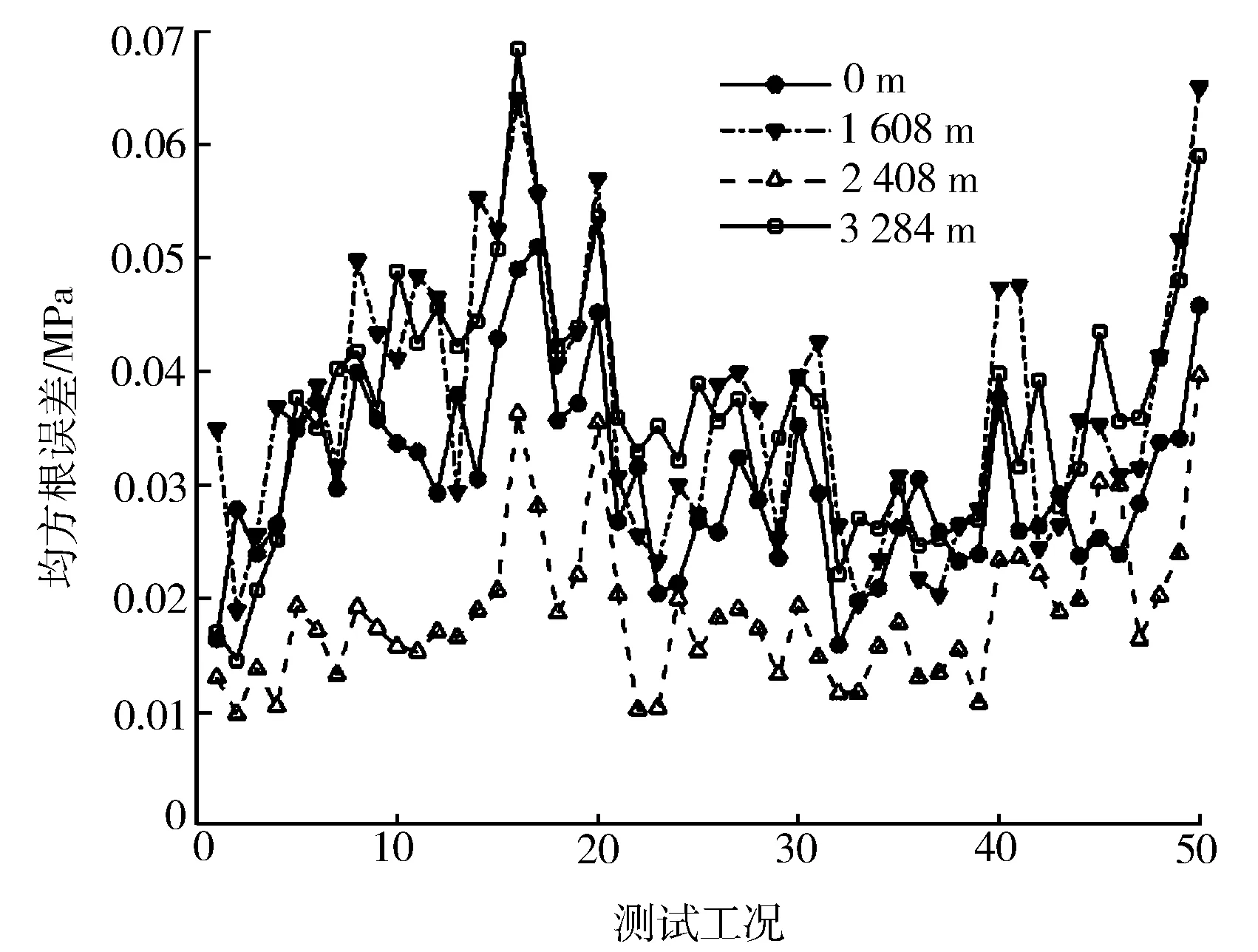
图7 气缸压力均方根误差
3.2 模型预测结果分析
对神经网络模型进行多次调试,建立4个海拔下气缸压力与不同粒径的纳米级PM数浓度的相关模型,其模型的网络训练时间依次为1.551 s,2.292 s,1.752 s及2.652 s,运算效率较高。如图8所示,各模型训练样本的回归系数R2均大于0.99,测试样本的回归系数R2均大于0.93,说明模型的非线性拟合程度较高,经主成分分析的气缸压力与颗粒物浓度相关性较好。
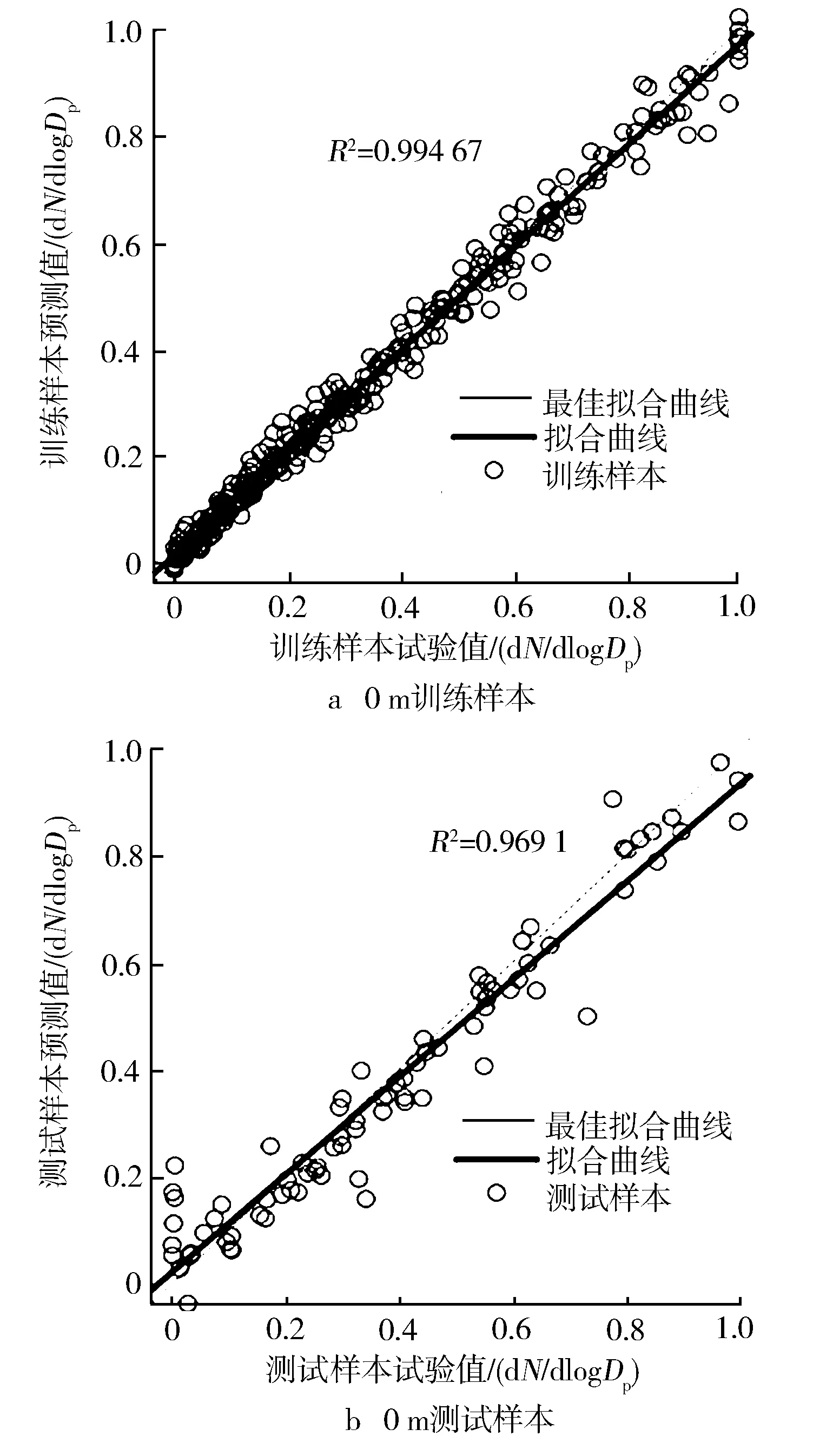

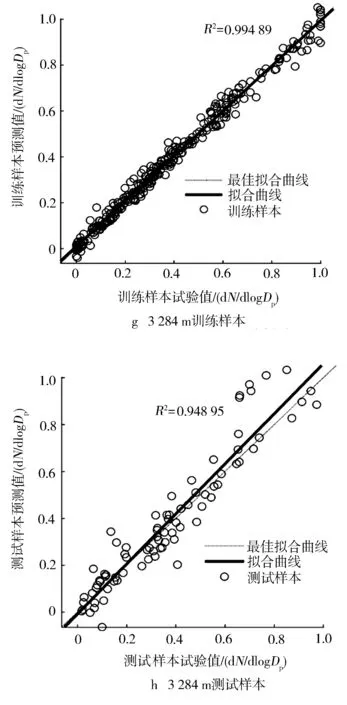
图8 不同海拔下模型回归分析
对上述4个海拔预测模型进行仿真测试,各模型颗粒物浓度的反归一化仿真结果见图9,其中散点表示实测值,曲线表示预测值,并对其进行误差验证。0 m,1 608 m,2 408 m,3 284 m海拔下的最大绝对误差依次为1.89×107/(dN/dlogDp),9.98×106/(dN/dlogDp),1.41×107/(dN/dlogDp),9.14×106/(dN/dlogDp)。此外,4个海拔8级粒径的相对误差均在3.89%~13.02%范围之内,而最大平均绝对误差均小于5.49×105/(dN/dlogDp),均方根误差不超过7.39×106/(dN/dlogDp)。
此外,由图9可知,柴油机燃烧排放的核膜态(1~50 nm)颗粒物与积聚模态(50~1 000 nm)相比较少,粒径3(57~101 nm)和粒径4(101~165 nm)的颗粒数浓度最大,因其主要成分为吸附有机物产生的碳基凝聚物,对人体健康的影响较大。
综上所述,模型预测精度较高,能实现不同海拔下基于气缸压力对颗粒物浓度进行预测。同时,该模型与传统神经网络直接预测相比,收敛速度加快,相对误差平均降低了6.44%,说明先运用主成分分析降低变量之间的相关性,再训练BP神经网络建立模型,是一种行之有效的颗粒物浓度预测方法。


图9 不同海拔下颗粒物粒径浓度的预测值与实测值
4 结论
a) 运用主成分分析法对不同运行工况下的气缸压力进行降维时,提取的主成分对缸压燃烧特性具有优异的代表性;
b) 在实际道路中,柴油机燃烧产生的核膜态微粒偏少,而积聚模态微粒较多,尤其是粒径3级和粒径4级的颗粒物数量较大;
c) 各模型的平均相对误差达到8.63%,7.01%,8.77%,8.01%,模型能够准确预测实际道路基础路段的颗粒物排放水平;应用此模型还可进一步预测8级粒径的颗粒物分布,为制定合理的颗粒物排放及节能减排提供技术支撑。
猜你喜欢
南京航空航天大学学报(2022年4期)2022-08-30
煤气与热力(2022年2期)2022-03-09
能源环境保护(2022年1期)2022-03-04
中国食用菌(2021年10期)2021-11-04
昆钢科技(2021年6期)2021-03-09
汽车维护与修理(2020年9期)2020-11-04
汽车维护与修理(2020年7期)2020-10-15
汽车零部件(2020年9期)2020-09-27
汽车维护与修理(2019年1期)2019-07-09
绿色科技(2018年24期)2019-01-19
