
基于Storm的局部放电信号集合经验模态分解
2020-05-20 01:19:40朱永利
计算机工程与应用 2020年10期
杨 航,朱永利
华北电力大学 控制与计算机工程学院,河北 保定 071003
1 引言
近年来,随着分布式计算框架的出现,数据流的实时处理技术逐渐在设备状态监测领域得到应用。目前,电力生产行业正朝着智能化的方向发展,各种电力设备的监测数据以数据流的形式源源不断地传到远程的监控中心。数据流有着产生速率快、数据量大的特点,因此往往难以存储,必须及时处理。电力大数据的出现,对数据中心的计算能力提出了更高的要求。目前国内外对变压器、容性设备、高压断路器等电力设备的在线监测都做了大量深入研究,监测量的范围也越来越广泛[1]。时序波形信号作为电力设备重要的监测量,为电力设备的状态评估提供了重要依据。局部放电信号是时序波形信号的一种,它既是变压器绝缘劣化的征兆,又是变压器绝缘劣化的原因[2]。不同类型的局部放电对变压器绝缘的破坏力有较大差异,因此有效分析和识别放电类型对设备的检修及维护具有重要的指导意义。
现阶段的电力设备在线监测平台大多仅能接收监测装置的“熟数据”,如一次设备绝缘放电电流波形信号须在监测装置处被处理成放电次数、峰值和平均电流后方能上传,这样就丢失了大量的频谱信息[3]。因此本文提出基于Storm 计算框架对监测到的原始时序信号进行特征提取,以保证信息的完整性。通过分析更完整的时序信号,可以对电力设备的运行状况进行诊断。其中特征提取是故障诊断的重要前提,针对非平稳信号目前有很多特征提取的方法,常用的有傅里叶变换、小波变换、经验模态分解(Empirical Mode Decomposition,EMD)等。其中EMD方法相对传统的信号处理方法有着更好的分辨率和自适应性,被广泛用于非平稳信号的分析。但EMD 存在着模态混叠和端点效应等问题,因此又有学者提出了改进的EMD 算法,即集合经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)。EEMD分解方法跟大多信号分解方法一样,都是计算密集型的算法,在很多要求有较高实时性的信号处理场景下,传统串行处理方法往往无法满足需求,因此本文结合Storm分布式计算框架部署EEMD并行算法,从而实现流式波形信号的快速分析。
EMD 算法是由Huang 提出的,到目前为止已经有很多学者将该方法应用到非平稳信号的分析当中。EMD的应用领域非常广泛,例如风速预测[4-6]、脑电波信号分析[7]、转动机械的故障检测[8-9]等。在电力设备的故障检测中也有很多应用,但大多是单机环境下的信号分析方法,只有为数不多的基于Spark 和MapReduce 的并行处理方法。文献[10]利用MapReduce 实现了并行EEMD分析,但是MapReduce适合离线的大批量数据处理,因此实时性较Storm 弱一些。文献[11]利用EEMD方法在Spark平台进行了不同长度的单个波形信号的并行分解,因为其读写是基于HDFS(Hadoop Distributed File System),所以对信号处理速度造成了一定影响。本文基于信号是否分段处理提出两种并行策略,利用Storm分布式计算框架设计部署并行EEMD算法来进行信号的并行化分解,使用Redis作数据源,并针对信号的流式处理给出了优化策略,以满足实际的应用需求。
2 EEMD算法基本理论
2.1 EMD算法
经验模态分解[12]是由Huang 提出的一种自适应的信号分解算法,其可将一个复杂信号分解为一组单分量信号,这些单分量信号叫作本征模函数(Intrinsic Mode Function,IMF)。其中,IMF要满足如下两个条件:
(1)在整个数据段内,极值点的个数和过零点的个数必须相等或相差最多不能超过一个。
(2)在任意时刻,由局部极大值点形成的上包络线和由局部极小值点形成的下包络线的平均值为零,即上、下包络线相对于时间轴局部对称。
EMD 算法获取IMF 是通过不断筛选得到的,最先得到的是频率较大的信号分量。其算法的步骤如图1所示。

图1 EMD算法流程图
2.2 EEMD算法
模态混叠最先是在含有间断信号的分解中发现的,其指的是在一个本征模函数(IMF)中包含了多种频率的分量,或者相近频率的成分分散在不同的IMF 中,导致分解结果失去意义。因此,为了改善EMD 的模态混叠问题,Wu 和Huang 提出了基于噪声辅助数据分析的方法——集合经验模态分解(EEMD)。EEMD 利用白噪声零均值[13]的特性来抑制噪声信号的影响,其通过对原始信号加入不同的白噪声进行EMD 分解,最后把获得的全体IMF分别按层求均值来抵消噪声,从而让真实信号凸显出来。虽然EEMD 是EMD 的改进,继承了原有的信号自适应分解、无需选择基函数的优点,且能较好地处理模态混叠的问题,但是对于所加白噪声的幅值大小、信号的染噪次数等参数往往需要根据具体的使用场景人为经验确定。根据文献[14],当添加的噪声幅值较大时,为了减少噪声对结果的误差影响,染噪次数一般设置得较大。这就造成了EEMD 算法的运算量大幅增加,普通的串行EEMD算法将无法满足实际应用中对处理速度的要求,因此考虑使用集群来并行化EEMD算法以提高处理效率。
3 Storm框架介绍
Storm 是一个由Twitter 开源的分布式实时计算框架,其主要用于流数据的处理,弥补了Hadoop批处理无法实时处理的不足,具有健壮性、容错性、动态调整并行度等特性。Storm 编程相对简单,可以使用多种编程语言。Storm 的实时性体现在可以支持纳秒级的时延计算,比SparkStreaming 这种基于时间窗口“微批”处理的准实时框架具有更低的延迟[15]。Storm在数据的实时在线处理方面有着独特的优势,主要用于日志分析、大数据实时统计、在线学习、持续计算和分布式RPC(Remote Procedure Call)等。
Storm 是一个主从架构的计算框架,任务通过运行在Nimbus 守护进程上的Master 节点分发给运行在Supervisor 守护进程上的 Worker 节点。在 Storm 中,任务被封装成Topology,每一个工作节点上运行着拓扑的一部分。一个Topology 一般由若干Spout 和Bolt 组成,不同的组件之间通过数据流Stream 产生联系,其中Spout 是消息的生产者,其可以从不同的数据源读取数据,比如消息中间件Kafka、RocketMq,也支持读取文件、数据库和网络数据等[16]。Bolt 是处理数据的组件,即从上一级组件(Spout 或Bolt)获取Tuple(Stream 的最小组成单元),经过处理加工生成新的Tuple传递给下一级组件。上下级组件通过订阅的方式决定数据的流向,常用的分组策略有以下几种:
(1)Shuffle Grouping:随机分组,通过轮询的方式,将Tuple均分给bolt task。
(2)Fields Grouping:按字段分组,将具有相同field-Name的Tuple分给同一个Bolt组件。
(3)All Grouping:广播发送,对于每一个Tuple,所有Bolt组件都会收到。
(4)Global Grouping:全局分组,把上游组件产生的Tuple 分配给同一个 bolt task 去处理,一般为 task id 最低的task。
Topology的总体结构如图2所示。

图2 Storm计算框架示例
4 基于Storm的EEMD并行分解算法
EEMD 算法是通过添加不同的白噪声形成不同的染噪信号,不同的染噪信号分别进行EMD分解,最终汇总求均值。染噪后的EMD分解过程是一个可以并行的阶段,因此并行化EEMD 算法可以有两种选择,其一是直接将EMD 分解过程并行化,其二是先将原始信号分段再过程并行化。为了方便描述,把前者在Storm平台上并行化的算法简称Spp-EEMD,后者简称Ssp-EEMD。下面详细分析这两种并行化策略。
4.1 Spp-EEMD
EEMD 的算法流程如图3,可以看出原始信号每次添加不同白噪声再进行EMD分解的过程是互不影响的独立过程。

图3 EEMD算法流程图
显然,此种分解方法的Storm拓扑图如图4,染噪过程和EMD分解过程都是并行的。分解步骤如下:
(1)Spout 从Redis 中读取原始信号,封装成Tuple,发送到下一级。
(2)每一个 AddNoise 组件通过 All Grouping 的分组策略从Spout 获取原始信号,然后各自添加白噪声生成新的染噪信号,生成新的Tuple。
(3)EMD分解组件订阅AddNoise组件的数据流,通过Shuffle Grouping 分组方式使每个EMD 组件均分地处理上级组件发来的Tuple,保证EMD组件并行地分解染噪信号。每个EMD 组件生成的Tuple 为(id,arr),其中arr是一个二维数组[i][j](i表示筛选出IMF的个数,j表示信号长度)。
(4)Average 组件通过Global Grouping 方式汇总所有EMD,即计算每层IMF的平均值,最后可以将结果写入Redis或持久化到数据库,用于后续的特征提取。

图4 并行Spp-EEMD的拓扑结构
4.2 Ssp-EEMD
基于分段并行的EEMD 分解是比Spp-EEMD 更细粒度的并行算法,其通过对原始信号进行分段,然后对子段信号进行Spp-EEMD分解,最终将不同子段对应层级的IMF合并即可。此种方法的并行度虽然提高了,但是信号的分段数的增加必然带来更多的端点效应。常用的解决端点效应的方法有镜像延拓法、极值点对称延拓、多项式拟合延拓、匹配延拓等。其中,极值点对称延拓算法较为简单,在镜像延拓的基础上进行了端点是否极值点的判断,可以提高准确性,同时只需要将原有的极值点向外延拓几个周期即可,显著减少了运算量,可以保证在Storm中较低的处理时延。
Ssp-EEMD 算法是基于Spp-EEMD 的,拓扑结构如图5,可以看出Spp-EEMD作为Ssp-EEMD的子过程,用于处理原始信号切分后的子段。
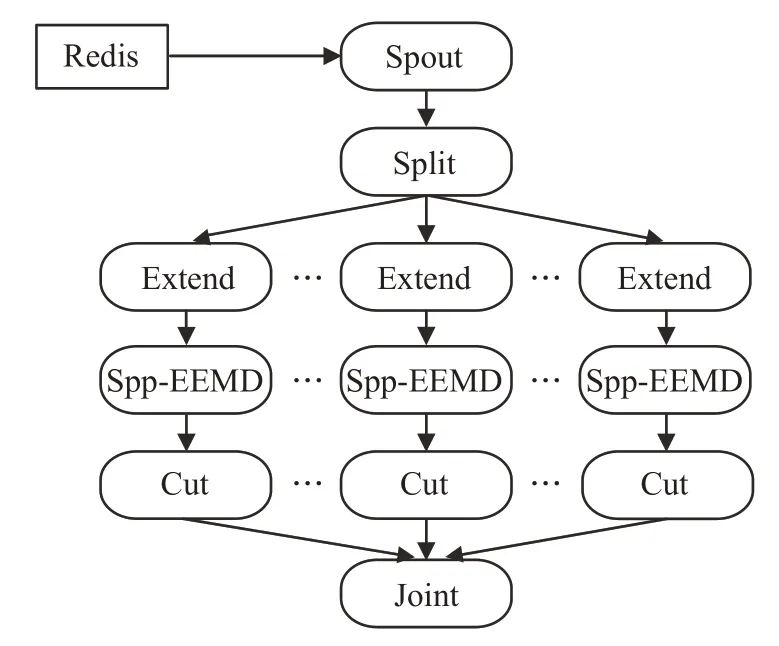
图5 Ssp-EEMD算法拓扑图
Ssp-EEMD进一步提高了EEMD算法的并行度,但是更细粒度的数据划分可能导致Storm 节点间通信量的增加。此种方法更适合信号长度较长的情况,分解步骤如下:
(1)Spout 组件读取Redis 中的原始信号x,发送至Split组件。
(2)Split 组件将原始信号划分为等长数据段,共n段,为了保证最终Joint组件合并时信号的有序性,Splite发出的Tuple 应为(i,arr),其中一维数组arr 为信号子段,Tuple 的id 值i为该子段在原始信号中的相对位置序号,i=1,2,…,n。

图6 原始信号分段处理示意图
(3)Extend 为延拓组件,采用极值点延拓的处理方式减少端点效应的影响。通过Shuffle Grouping的分组方式,保证裁切后的子段平均分配到不同的Extend节点处理。
(4)进入Spp-EEMD 的处理过程,该阶段需要特别注意的是Average过程。
①这里以原始信号的第一个子段为例,如图6,子段1 经过延拓和染噪过程形成子段1 的一组染噪信号arr_i(i=1,2,…,m),对每个染噪信号arr_i进行EMD分解,生成一组IMF存储在二维数组imf_arr_i中。
②EMD分解过后,将imf_arr_i封装为Tuple发出,由于Ssp-EEMD 将原始信号分为多个子段,使用Spp-EEM 中的单个Average 组件策略已经满足不了算法的并发性能。因此,Ssp-EEMD 算法需设置多个Average组件同时计算不同子段产生的IMF的均值。Average组件的分组策略应为Fields Grouping,以保证同一个子段的 imf_arr_i(i=1,2,…,m) 被同一个Average 组件接收,Average 最终产生的 Tuple 为 (a,imf_arr),其中a为子段序号,二维数组imf_arr 为该子段经EEMD 分解产生的一组IMF。
(5)Spp-EEMD处理完之后,Cut组件可采用Shuffle Grouping 随机分组方式对imf_arr 两端进行裁切,保证IMF与子段长度相同。
(6)Joint 组件采用 Global Grouping 方式对不同子段的IMF按子段序号进行拼接,最终输出一个二维数组Array,维数为m×L,其中m是IMF 的层数,L是IMF信号的长度,与原始信号保持一致。该Joint 过程是串行过程,至此信号x的EEMD处理结束。
4.3 并行EEMD的数据流处理的优化策略
上述两种基于Storm 的并行EEMD 算法都是针对单次读入一批数据点作为原始信号进行EEMD 分解,Ssp-EEMD的Average组件和Spp-EEMD中的Joint组件等这些都是并行度为1 的汇总型计算组件。在Storm中,并行度为1意味着计算过程只在集群中的一个节点中运行,其他节点会因为空闲造成资源浪费。然而在实际生产环境中,Storm的Spout组件会连续不断地从消息队列中拉取待分解原始信号段进行处理,而不是等待一个原始信号段处理完毕才开始拉取另一个。因此,拓扑中某一时间点就有多个原始信号在同时分解,在设置汇总型组件时就可以设置多并发,用来同时汇总不同批次原始信号的分解结果,以提高系统的吞吐量。
在解决了并行度的问题后,还需考虑集群的计算能力。如果Spout 组件无限制地读入数据、发送Tuple,也就是数据发送得快,处理得慢,会导致大量Tuple 堆积,造成线程阻塞,严重的话可能导致系统队列溢出。常见的方法就是设置Spout 每读入一个数据就休眠一段时间,通过在nextTuple()的方法体中设置Thread.sleep(long millis)即可。还有一种方法就是通过设置Storm的maxSpoutPending属性值为k,即spout task上面最多可以有k个没有处理完的Tuple(没有ack/failed)。当未处理完成的Tuple数量达到k时,Spout task将不再调用nextTuple继续发送数据。设置该属性是通过在main方法中调用如下代码:
Config conf=new Config();
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING,k);其中conf 为Storm 的配置对象,用来配置Storm 集群和Storm 拓扑上所有可能的配置的常量。在实际应用中,如果k值过小,则会导致某些工作节点算力的浪费,因此需要根据集群的计算能力与任务的复杂度设置合适的k值,才可以保障集群的高效运行。
5 实验设计与结果分析
5.1 实验环境
为了验证第3 章提出的并行EEMD 分解算法的效果,在集群环境下搭建Storm集群,各节点的配置如表1。配置环境变量,并且安装完Storm套件后,同时安装Redis充当实验数据源。

表1 Storm集群配置表
5.2 实验方案设计
Storm 的多语言协议支持各种编程语言去实现Spout 和Bolt 组件,本实验中采用比较常见的Java 去实现上文中介绍的两种并行EEMD 分解算法以及Storm的处理逻辑,然后根据运行结果分析比较两种算法。
实验数据来自几种常见的放电模型收集到的数据,信号的采集周期与工频周期一致,采样频率5 MHz,采集频带为40~300 kHz。实验中为了模拟数据流,预先根据仿真实验需要的信号长度将采集到的数据以String类型存放在Redis中。Spout组件读取Redis中的数据并利用Java自带的split()函数进行字符串的切分,然后通过类型转换为float 数组。但是由于Tuple 的value 默认只支持Byte 数组,因此需要自定义一个数据传输类将float数组封装进去,然后在配置文件storm.yaml注册该类声明序列化,这样就可以实现在task之间传递自定义的数据类型。
为了方便比较两种并行策略的分解速度,统一将染噪次数Ne设置为50,同时将IMF 的筛选次数设为10,以避免筛选IMF 的停止准则对分解速度造成影响。对于分段并行的Ssp-EEMD算法,设置分段数为10。在批量处理实验中,通过设置maxSpoutPending以防止Storm系统队列溢出。maxSpoutPending 的值通过实验选取,之所以没有使用线程休眠的方式是由于集群的处理能力并不是恒定的,可能受到外界突发状况的影响,当某一阶段的Bolt 组件出现数据拥堵时,Spout 的数据发送速度不变会导致拥塞的恶化,最终使程序无法正常运行,设置maxSpoutPending的方法可以有效避免该问题。
为了更好地利用CPU 资源,需要根据任务的复杂程度设置组件的并行度。同时考虑到Storm 集群自动负载均衡的特点,需要将并行度设为工作节点个数的倍数,即5 的整数倍。在本实验中对于染噪、延拓这类复杂度较低的任务,将组件的并行度设为10。而对于较为复杂的EMD 分解组件,设置并行度为30。组件的并行度需要在main方法中设置,以Spp-EEMD为例,代码如下:
TopologyBuilder tb=new TopologyBuilder();
tb.setSpout("spout",new Spout(),2);//并行度为2
tb.setBolt("add_noise_bolt",new AddNoiseBolt(),10).allGrouping("spout");//染噪
tb.setBolt("emd_bolt",new EMDBolt(),30).shuffleGrouping("add_noise_bolt");//EMD分解
tb.setBolt("average_bolt",new AverageBolt(),10).global-Grouping("emd_bolt");//求IMF均值
Config conf=new Config();//创建拓扑配置
conf.setNumWorkers(20);//设置工作进程数量
在本实验中,共设置了20个Worker(工作进程),一个Worker 就是一个jvm 虚拟机进程,组件并行度10 和30即为Executor(线程)的个数。Executor运行在Worker中,默认情况下一个Executor 中运行一个Task,三者的关系如图7所示。Storm的负载均衡机制会将Worker和Executor 平均地分配给集群中的Supervisor 工作节点,使每个节点的计算资源都得到充分利用。

图7 Worker、Executor和Task之间的关系
5.3 实验结果与分析
4.3 节提到通过设置maxSpoutPending 值来提高并行EEMD 算法对数据流处理的效率,但是maxSpout-Pending 需要根据Storm 集群的算力进行合理的设置。图8 是在待处理数据为200 条,数据长度为10 000 的条件下记录的不同maxSpoutPending对应的处理时间。从图中可以看出,两种算法分别在50 和60 左右取得最优值。在最优值的左侧因为未充分利用所有的算力,所以会随着maxSpoutPending的增加而处理时间变短。在最优值的右侧由于集群处理能力和内存的限制,导致线程拥塞,处理速度反而变慢,当达到150时,两种算法由于系统队列溢出都无法正常运行。因此两种算法的max-SpoutPending值取其各自的最优值,即可最大程度发挥算法的处理能力。与此同时,由于集群的处理能力是固定不变的,当信号长度成倍数增加时,maxSpoutPending值也应减少相应的倍数,例如信号长度为20 000 时,两种算法的maxSpoutPending值应分别设为25和30。

图8 maxSpoutPending值对批量处理的影响
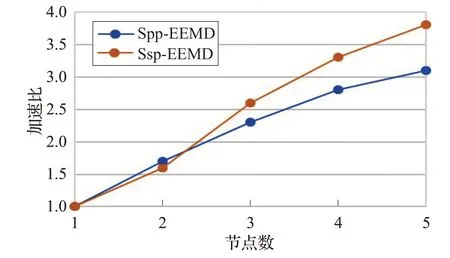
图9 记录了几种方法在分解不同长度信号时所花费的时间。其中标注为Java的曲线是在JVM(Java Virtual Machine)下执行的,为了充分利用多CPU 核心,EMD 分解阶段采用的是 Java 的 ThreadPoolExecutor 线程池技术来实现多并发。Local Mode 为Storm 在本地模式下执行(即单点执行)。可以看出两者的执行时间比较相近,Local Mode由于Storm的ack机制和tuple发送机制等,时间比Java 方式稍长一点。Spp-EEMD 和Ssp-EEMD 两种方法的时间曲线存在交点k(15 图9 数据运行时间 图10 为两种算法在批量处理中的加速比,并行算法的加速比最优的情况下是随着集群节点数的增加呈线性变化。但考虑到Storm 集群间的通信协调和序列化的Tuple 在节点间传递花费一些时间,因此实际效率会低一些。Ssp-EEMD算法具有更高的并行度,因此具有较Spp-EEMD更高的加速比,更适合做集群的扩展。 图10 两种并行算法加速比 表2 是两种算法分别以10 000 和20 000 点为单条数据长度处理不同大小的数据集所用的时间对比。在信号长度为10 000的情况下,基于分段的Ssp-EEMD算法在处理30 MB 以上大小的数据集时有较小的时间优势,但在20 000 信号长度下Ssp-EEMD 算法明显优于Spp-EEMD。造成这种现象的主要原因是当信号较长时,EMD分解组件因其本身算法复杂度较大,花费时间较长,造成数据流拥堵于该阶段,而其他组件则处于相对闲置状态。Ssp-EEMD 算法通过分段处理将信号变短,虽然比Spp-EEMD增加了子信号端点效应处理的时间花费,但是较短信号在EMD 分解阶段花费的时间也相对较少,缓解了数据流的拥塞状况。因此在信号的批量处理中,数据流在Ssp-EEMD的整个处理流程中分布较均匀,各级组件的线程都处于运行态,CPU的利用率比Spp-EEMD 更高,使得基于分段的并行算法Ssp-EEMD在批量处理场景下处理长信号有更大的吞吐量。 表2 不同EEMD批量执行时长对比 min 大数据技术的发展使时序信号的在线快速处理成为可能,本文基于Storm提出了两种并行EEMD分解算法。通过设置Bolt组件的并行度,将待处理数据封装为Tuple 发送给处理组件,实现EEMD 算法的并行求解。通过实验验证了两种并行分解算法的可用性以及各自适用的场景,在处理单个信号时,基于分段的Ssp-EEMD信号分解算法比Spp-EEMD 算法有更高的并行度和更好的加速比,在处理长信号时效率更高,而Spp-EEMD更适合10 000以内短信号的处理。在批量处理场景下,信号较长或者是数据量较大都推荐使用Ssp-EEMD 算法,该算法吞吐量大,处理速度更快。但是Ssp-EEMD会由于信号分段引入端点效应,如果要求准确率,则只能使用Spp-EEMD 分解方式。较传统的串行EEMD 算法,两种基于Storm的并行EEMD算法在处理速度上都具有较大的优势,且可以通过扩展Storm的集群规模来进一步提升处理速度。

6 结束语
猜你喜欢
能源工程(2022年2期)2022-05-23 13:51:50
数学物理学报(2021年4期)2021-08-30 08:28:02
重型机械(2020年2期)2020-07-24 08:16:16
装备制造技术(2019年12期)2019-12-25 03:07:36
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
太空探索(2016年9期)2016-07-12 10:00:04
