
挖掘软件源代码的代码注释自动生成方法
2020-05-20 01:19:36张丽萍
计算机工程与应用 2020年10期
白 杨,张丽萍
内蒙古师范大学 计算机科学技术学院,呼和浩特 010022
1 引言
代码注释是软件开发的一个重要组成部分,能够辅助编程人员有效地理解源代码。代码注释一般用自然语言的形式阐述代码背后实现的逻辑或功能[1],开发人员依赖代码注释了解源代码描述的功能。在规范的软件开发过程中,编程人员会被要求在源代码的适当位置添加适量的代码注释[2]。
在实际中,缺乏代码注释是软件工程领域中的常见问题,大多数软件代码注释较少,大部分程序员只注重所编写的代码,而忽略与代码相对应的注释或者文档,这就导致程序的可读性和可维护性大大降低,同时降低开发效率。再者,如果程序员在编写代码的同时手动书写代码注释或者文档,既浪费程序员的时间,又使得工作效率降低。因此,自动生成代码注释是必要的,它不仅可以节省开发人员编写注释的时间,提高工作效率,而且程序可读性和可维护性也会大大提升。
本文通过检测原项目软件和目标软件的相似性代码,对提取的代码和注释进行精简优化处理,最终为目标软件自动生成代码注释。
2 相关工作及概念
2.1 代码注释的概念及类型
代码注释即对代码的解释和说明,主要是为了让开发者迅速理解代码,是程序员为语句、程序段、函数等给出的解释或提示,能提高程序代码的可读性。换句话说,代码注释就是用自然语言的形式阐述代码背后实现的逻辑或功能,是描述软件功能的可读性自然语言,是架起程序设计者与开发者之间的通信桥梁,与此同时能够提高团队开发合作效率,因此,自动生成代码注释在整个注释的研究中是至关重要的。
代码注释按照注释对象可以分成三种类型[3],即文档注释(Javadoc/Document Comment)、块注释(Block Comment)和行注释(Line Comment)。为了直观说明,图1给出了三种代码注释类型的例子。其中,文档注释包括类注释、方法注释、属性注释、包注释和概要注释,一般以/**...注释内容...*/或者@...的形式表示;块注释分隔源代码区域,该区域可以跨越多行或单行的一部分,使用起始分隔符和结束分隔符指定此区域,通常以/*...注释内容...*/的形式表示;行注释是指以注释分隔符开始并一直持续到行的结尾,或者在某些情况下,从源代码中特定列(字符行偏移)开始,并继续直到行的结尾,简单地说,行注释是指跟在代码行后面,描述当前代码所表达的功能,例如Java 语言中,单行注释以“//”开头,跟在“//”后面的文本就是注释内容。其中文档注释可以由工具自动生成[4-5],而块注释和行注释则需要由编程人员手动添加。
2.2 国内外研究现状
对于代码注释自动生成国内外均有一定的研究基础,Wong等人提出了一种从StackOverflow上挖掘大规模问答数据来自动生成代码注释的方法[6]。该方法计算目标软件代码和StackOverflow上的代码片段之间的相似性,并将StackOverflow 上的代码片段的描述用于生成目标软件代码段的注释。该方法虽然生成相应的代码注释,但只能自动生成有限数量的注释。
在此方法的基础上,Wong 等人又提出了另一种通过挖掘现有软件代码库来自动生成代码注释的方法[7]。该方法使用代码克隆检测技术从软件代码库中发现语法相似的代码片段,并将代码注释应用于其他语法类似的代码片段上。该方法虽然可以产生良好且可提交的注释,但自动生成注释的产量和精度相对较低。
Sridhara等人提出了一种对Java方法生成注释的方法[4]。该方法给定一个方法名和方法体,在自动生成注释的同时描述该方法的功能。Sridhara等人还使用启发式算法对Java方法的参数自动生成注释[5]。这些方法虽然可以直接从代码元素中合成自然语言的句子,但过度依赖于程序中的标识符名称和方法名。
Moreno 等人对Java 类生成注释[8]。该方法根据一组启发式方法,并使用现有的文本生成工具编写注释。生成的注释主要描述了类本身涵盖的内容以及该类的功能。虽然该方法是第一种自动生成类的自然语言摘要的技术,但其质量还需提高。
McBurney 和 McMillan 也提出了一种对 Java 方法生成注释的办法[9]。该方法总结了上下文,而不是方法内部的细节。该方法使用PageRank在该上下文中找到最重要的方法,并使用SWUM(Software Word Usage Model)来收集描述这些方法行为的关键字。同时设计了一个自定义NLG(Natural Language Generation)系统来创建关于此上下文的自然语言文本。该方法虽然生成注释的质量优越,但评估方法单一,影响结果。
综上所述,在代码注释自动生成方面,大多数对代码注释的研究都存在注释稀少、准确度不高的问题,而且程序理解本身就存在一定的难度,因此本文针对这一问题,使用注释复用的方法来提高代码注释的产量和质量。
2.3 注释复用及克隆检测
研究者试图利用人工及自动化的方法为代码添加注释,其中自动化方法主要包括注释复用及注释抽取[4-5,8]。本文使用了注释复用的方法,从已有软件项目和目标软件项目中找出相似代码,将已有项目中的注释信息处理后映射到目标项目中的相似代码段上。因此,找出相似代码是其中的关键步骤,本文使用克隆检测加以解决。在克隆研究领域,人们普遍将相同或相似的代码段叫作克隆代码,简称克隆[10]。现在比较权威的说法,克隆代码可以被分为Type-1、Type-2、Type-3和Type-4四类[11]。克隆检测指的是查找并反馈软件系统中的克隆代码,为软件开发、维护、软件重构和演化等活动提供最基本的参考信息。

图1 代码注释类型示例
国内外关于克隆检测方法和技术的研究已经相对成熟。很多研究者对克隆检测进行了实验,Roy等人开发的Nicad应用灵活的过滤和规范化机制对文本检测进行改进[12],可有效检测Type-1、Type-2以及Type-3克隆。
Kamiya等人开发了一款名为CCFinder的克隆检测工具[13]。此工具将每一行代码单独转化为Token 序列,然后合并所有的Token序列,这样做是因为即使变量名和代码结构发生变化,也不会影响检测结果。
Gabel等人将PDG(Program Dependence Graph)中的子图同构问题规约为子树同构问题[14],再利用Deckard进行检测,来提高检测的速度和可扩展性。
本团队在克隆检测方面也进行了大量研究。史庆庆等人使用优化后缀数组的方法进行克隆代码检测[15],并实现了一款检测软件源代码中克隆群的工具FCD(Function Clone Detector);张久杰等人实现了基于Token编辑距离的检测方法[16],能有效检测Type-3 克隆代码。这些为本文的后续研究奠定了基础。
3 代码注释自动生成
3.1 研究框架
本文自动生成代码注释分为四个阶段:(1)克隆检测阶段;(2)代码和注释提取阶段;(3)克隆代码和注释优化精简阶段;(4)代码与注释映射阶段。图2 显示了自动生成代码注释的步骤。
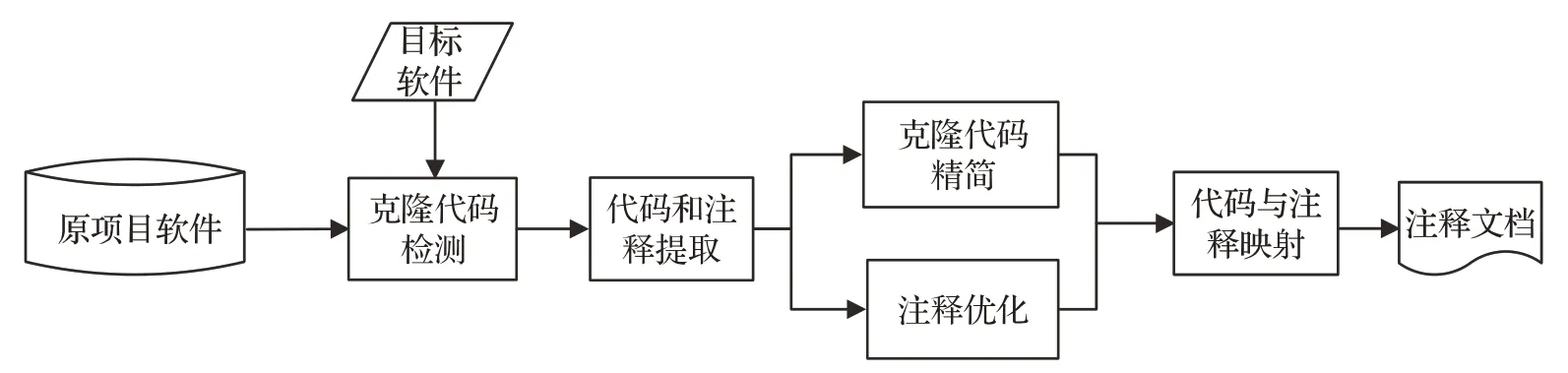
图2 总体研究路线
本文提出的代码注释自动生成的方法,需要提供两个输入:(1)原项目软件,拥有数量丰富、质量较高的代码注释,可以从中提取规范的代码注释信息,本文从Github下载开源项目。(2)目标项目软件,通过该方法为其添加代码注释的项目软件,即从原项目软件中提取注释信息,经过精简优化映射到目标项目软件中相应的代码段上,本方法的输出则是为目标项目自动生成的代码注释文档。
3.2 克隆代码检测
自动生成代码注释之前需要检测克隆代码,即原项目软件与目标软件的相似代码片段。检测软件中的克隆代码是提取代码和注释的基础,因此精准的克隆检测是自动生成代码注释的关键步骤。本文使用当前领域较成熟的克隆检测工具Nicad 进行克隆检测。Nicad 是基于文本的克隆检测工具,可以较准确地检测出Type-1、Type-2、Type-3的克隆代码。此工具可以检测软件内部的克隆代码,也可以检测跨版本软件的克隆代码,为本文后续代码注释的研究提供更加准确的数据来源。
本文在原项目软件和目标软件之间找到相似的代码段。从GitHub上下载了100个开源项目软件,这些开源项目软件的代码注释是由开发人员编写。原项目的代码注释是经过软件演化过程最终沉淀形成的,相对完善成熟,质量高并且规范化,极具参考价值,因此可以选取其作为标准集。本文将100款原项目软件和5款目标软件作为输入,利用Nicad 检测这些原项目软件和5 款目标软件,检测结果以克隆对和克隆群的形式反馈。本文只采用克隆群形式的检测结果,检测结果存储到XML(Extensible Markup Language)文件中。下面以FreeMind为例,介绍克隆检测结果。图3呈现了以克隆群形式反馈的部分内容检测结果。该XML显示了检测到的克隆代码的相似度、文件路径和文件名等详细信息。

图3 克隆检测结果存储方式
3.3 克隆代码及其注释的提取
通过克隆检测结果只得到了这些克隆代码的存储路径,在获取克隆检测结果之后,需要对克隆代码和注释进行提取。自动生成代码注释是以提取的克隆代码和注释为线索映射成的集合,因此这一步骤是后续研究的基础。
3.3.1 克隆代码的提取
在克隆代码提取阶段,从克隆检测阶段获取的XML 文件中,得知有文件名、文件路径等信息,本文使用字符流读取XML 文件,通过文件路径和行号读取文件,然后创建一个可以往文件中写入字符数据的字符输出流对象以便存储数据。写入数据时,首先判断文件是否存在,如果文件不存在,则自动创建,如果文件存在,则会被覆盖。然后将在指定行内文件与不在指定行内文件区分,存储在两个缓冲区中。最后获取指定行内文件的内容写入文件中,完成克隆代码的提取。具体实现方法如下。
算法1 克隆代码提取算法
输入:克隆检测XML文件。
输出:克隆代码提取文件。
1. def getdata(path,filename)
2. file1,buffer #定义生成的文件
3. For length in data do
4. buffer=read data
5. End For
6. If file1 no exist then
7. create file1
8. Else cover file1
9. write content
10. End If
3.3.2 代码注释的提取
在代码注释提取阶段,需要提取出克隆代码相对应的注释,通过XML文件提供的信息,获取文件ID号、文件名、文件路径、源文件起始行和结束行等信息。首先获取克隆代码,在得到克隆代码文件以后,将克隆代码文件解析成AST(Abstract Syntax Tree),然后从数据库克隆代码段的AST中检索代码注释,最后将提取的代码注释存储到文本文档中。具体的代码注释提取算法如下。
算法2 代码注释提取算法
输入:XMLpath。
输出:克隆代码、注释内容文档。
1. def getXMLdata(xmlpath)
2. ElementTree 将XML文件解析为元素树
3. List
4. content 注释内容
5. tar_file
6. For Clone Group in List
7. If element.getName equals“clones”then
8. Return id,clones,sourcecode,startline,endline
9. End If
10. End For
11. While content
12. If linenumber in tar_file
13. Return content
14. End If
提取的克隆代码和注释如图4所示,图中提取出的fireTreeNodesChanged()表示提取的以方法为粒度的克隆代码,/**…*/和//后面表示此克隆代码相应的注释。

图4 提取文档部分示例
3.4 代码及注释精简优化
提取出所要的克隆代码和代码注释后,不能直接将这些注释映射到目标文件的代码,需要对提取的克隆代码和注释进行精简优化,提高实验结果的质量和准确度。因此对代码和注释的优化是自动生成代码注释的关键步骤之一,此步骤直接影响最后的注释质量。这一阶段分为两个步骤:(1)克隆代码精简;(2)代码注释优化。
3.4.1 克隆代码精简
代码中包含许多的无用词,这些词对后续代码与注释映射的研究作用较小,而且无用词的出现会对实验结果的准确度产生噪音,因此需对这些词进行处理。提取出克隆代码以后,并不是每一段代码都适合为其添加注释,有的克隆代码对于研究没有很重要或者是必然的意义,克隆代码检测工具有时无法区分有意义匹配和无意义匹配,因此需要根据研究的实际情况来筛选出有意义的克隆代码。本文采用两条启发式规则过滤各类型的停用词,具体内容如表1所示。

表1 停用词规则表
3.4.2 代码注释优化
原项目软件中提取的代码注释与目标软件中代码所描述或者表达的意思或功能不一定一致,亦或者表达太过冗余,这样就会大大降低软件代码的可读性和可维护性,同时浪费读者的时间。在进行代码与注释匹配之前,首先预处理所有提取的代码注释,去除无关项以及与代码所表达的功能或含义不太相符的字符,然后对这些注释进行优化,这样可以使注释变得更加浅显易懂,开发者可以快速地理解此部分代码所要表达的含义,提高其效率。因此,对于提取出的代码注释,本文通过三条启发式规则对提取出的注释进行了精简优化,如表2所示。

表2 优化注释规则
3.5 代码与注释映射
提取的克隆代码和代码注释经过精简优化处理后,得到了相对较高的用于实验研究的结果,此时,本文将优化的代码注释映射到目标软件的代码,即将目标代码提取出来,和原项目软件提取优化的注释进行匹配,将注释映射到目标软件的代码段上。通过Nicad配置文件的行号过滤,如果是这些行号内的代码,加上源文件提取出的对应的注释,为每一个方法和语句添加对应的注释,重新生成目标软件;如果不是这些行号内的代码,则直接写入文件。其对应的代码注释映射算法如下。
算法3 代码与注释映射算法
输入:优化后的XML文件和生成的注释文件。
输出:新的带有注释的代码目标文件。
1. def writeFileContent(filepath,newstr)
2. Temp
3. If file exists then
4. filein=newstr+" ";#新写入的行,换行
5. End If
6. For temp=br.readline()!=null do
7. Buffer.append(temp)
8. End For
3.6 生成代码注释
目标软件的代码与原项目软件的代码进行克隆检测,找到二者相似的代码,本文将克隆检测出的代码进行精简处理,然后从原项目软件中提取代码注释,利用4个启发式算法对提取的代码注释进行优化处理,最后将优化后的注释映射到目标软件的代码上,此时代码注释自动生成已经基本完成。本文最后自动生成的注释和代码的映射生成一个Java文件,其详细内容如图5所示。

图5 代码注释生成结果图
4 实验结果与分析
目标软件的注释比较稀少且质量不高,因此本文通过克隆检测找出原项目软件和目标软件的克隆代码,对提取的代码和注释精简优化,得到质量较高、数量适合的代码注释。本文为5 款目标软件经过克隆检测得到的55个代码段生成了总共75条注释。显示了每个项目生成的代码注释(NC)的数量。平均为每个项目产生15条注释,但是5 款软件有超过105 万行代码,产量仍然很低。
4.1 数据来源
本文从Github上下载了100款软件项目,然后在评估中为5个Java目标软件生成注释,分别为Jabref、Jbidwatcher、Vuze、MegaMek、FreeMind,基本信息如表 3 所示。其中包括评估时使用的软件,也包括通常评估的代码克隆检测项目。这5款软件在该领域被经常使用,具有代表性,且都有很长的历史时间,比较成熟,也有其他团队在自动生成代码注释时选用了这些软件,因此适合用于实验。使用CLOC计算每个项目的代码总数如表3所示。CLOC是一款在许多编程语言中计算空白行、注释行和源代码的物理行的软件。
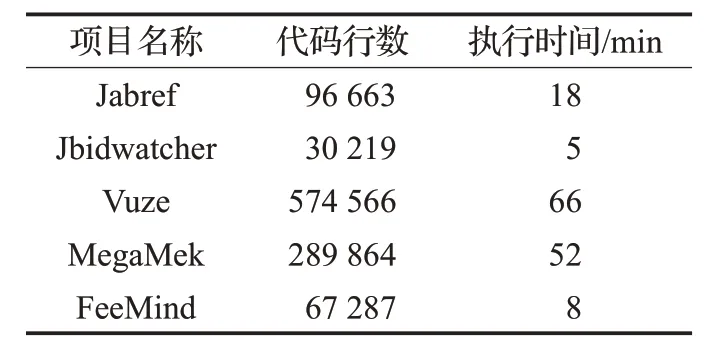
表3 软件基本信息
本文在检测原项目软件与目标软件的克隆代码时,使用Roy 团队开发的检测工具Nicad,此工具检测方法基于文本检测,能够高效检测出原项目软件和目标软件的 Type-1、Type-2 以及 Type-3 克隆代码,并将检测结果存储在XML文件中,便于后期数据的提取和使用。
4.2 评估标准
本文对所得实验结果进行了手动验证,为了获得更加准确的代码注释,考虑到自动生成注释的准确性、充分性、简洁性等性能,运用了以下的排名标准:
良好:自动生成的代码注释在描述目标软件代码时是准确、充分、简洁、符合逻辑的,则被视为是好的注释,保留此注释。
中等:自动生成的代码注释在描述目标软件代码时不够准确、充分、简洁,但经过小小的修改或改变可以正确描述,则被视为是中等注释。
不好:自动生成的代码注释在描述目标软件代码时不准确、不简洁或者不充分,经过修改或改变以后还是无法被修正,则被视为是不好的注释,不予以推荐。
以上标准对自动生成的代码注释的质量进行评估,如果评估结果是良好或者中等的,那么在以后的应用研究中就适当地推荐给程序开发人员。好的代码注释可以帮助程序开发人员节省阅读代码的时间和精力,提高效率。
本文主要对5款软件进行了自动生成注释的应用,以评估生成的代码注释的产量和质量,采用Wong 等人的标准进行评估,为了在以后的研究中可以进行对比。
4.3 实验结果
(1)生成的代码注释的产量
从NC、CG、LC、DC 这四方面对生成的代码注释的产量进行了评估,实验结果的详细信息如表4所示。其中NC表示每个项目生成的代码注释的数量;CG表示克隆组;LC 代表目标软件的每个克隆组中的平均代码克隆数;DC 描述了软件存储库的每个克隆组中的平均代码克隆数;CM表示目标项目软件已经存在的代码注释。

表4 生成注释结果的产量
根据表4 可以看出,每个克隆组包含平均2.4 个本地克隆和3.4 个数据库克隆,5 款软件总共生成75 条代码注释,平均每款软件生成15 条代码注释。产量相对较低,后续研究将进一步对产量进行提高,目前本实验使用的是Nicad克隆检测,检测的克隆代码数量还是很低。在以后的研究工作中,可以通过改进克隆检测技术或利用更高级的代码克隆检测工具来提高生成的克隆代码的数量,还可以通过使用更多项目扩展数据库来增加克隆组的大小。
表5显示了克隆组大小的分布。根据所得数据,知道有76.8%的克隆组包含2 个size。在以后的研究中可以通过使用更多项目扩展数据库来增加克隆组的大小,或者利用更高级的代码克隆检测技术。

表5 克隆群代码克隆的频率分布
(2)生成的代码注释的质量
根据上一节中提到的评估标准,本文将自动生成的代码注释进行手动验证,分为良好、中等和差三个等级,具体信息如表6所示。其中GD表示好的代码注释,FX代表可以修复的注释,BD 表示坏的代码注释。从表中可以看出,得到的好的代码注释的数量不是平均分布的,每一款软件得到的结果不同,本文分别计算了自动生成良好代码注释、中等注释以及差的注释的总和来表现生成代码注释的质量。本实验总共生成75条代码注释,其中有21(28%)条代码注释是良好的,3(4%)条代码注释需要被修改,有51(68%)条代码注释是坏的。根据这些数据可以发现,需要被修改的代码注释很少。对于中等和差的代码注释,将在后续研究中进行总结,分析问题的来源,通过改进实验进一步提高生成代码注释的质量。
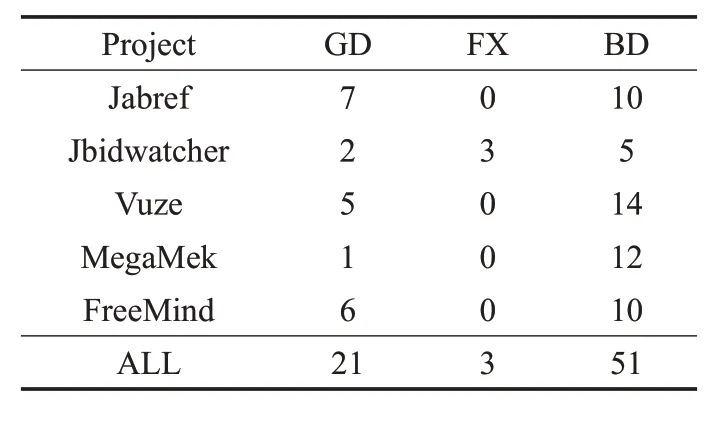
表6 生成注释结果的质量
自动生成的代码注释中,部分注释在目标软件中是已经存在的,本实验比较了已经存在的和自动生成的代码注释,人工评估这部分自动生成的代码注释与原有注释比较,是否有改进,以便在后续实验中进行改进。根据表2可知,5款目标软件已有的注释总数为26条,占自动生成代码注释总数(76)的34.7%。具体的比较信息如表7所示。其中Better表示生成的代码注释比现有的代码注释好,Similar表示生成的代码注释和现有的代码注释相似,Worse表示生成的代码注释比现有的代码注释差。

表7 自动生成代码注释VS现有的代码注释 %
由表可以看出,自动生成的代码注释相比原有的代码注释,在良好的代码注释中,3.5%的代码注释比原有的更好,25.4%的代码注释与原有的代码注释相似;在中等的代码注释中9.2%的注释更差。可以看出,目标软件已有的代码注释优于自动生成的代码注释,但有25.4%自动生成的代码注释与现有代码相似,由来自表4的结果知,目标软件中有65.3%(100%-34.7%)的注释以前没有,是新生成的。这意味着虽然自动生成的代码注释通常不如已有代码注释更贴近主题,由于生成注释的工作还没有很成熟,得到比原有更优的3.5%已经很不容易,在后续的实验中会逐步提高,但为没有代码注释的代码段生成代码注释仍然是有益的。因此,本实验对于自动生成代码注释是有价值的,为以后的工作奠定了一定的基础。
对于自动生成的代码注释,在代码注释的相应代码段没有现有注释的前提下,本文将评估出的良好的自动生成的代码注释报告给5位专家,让他们也根据本文的评估标准对这些良好的代码注释再次进行评估。目前专家对两款软件的注释给予了好评,即也将其视为是良好的代码注释,开发人员认为可以将其作为代码最后的注释。
4.4 对比实验及分析
国内外通过使用注释复用自动生成代码注释的方法较少,其中具有代表性的方法是文献[6]。文献[6]中Wong 等人通过基于Token 的方法进行克隆检测,而本文使用Nicad基于文本的方法进行克隆检测,中间对于代码和注释的处理方法也不同,因此仅对生成的代码注释的产量和质量进行对比。Wong等人实现了一个代码注释自动生成工具Clocom。本文研究与文献[6]都使用从Github上下载的Java开源软件,实验的平台均为操作系统Ubuntu 16.04 64位、8 GB内存。产量对比结果如表8所示。
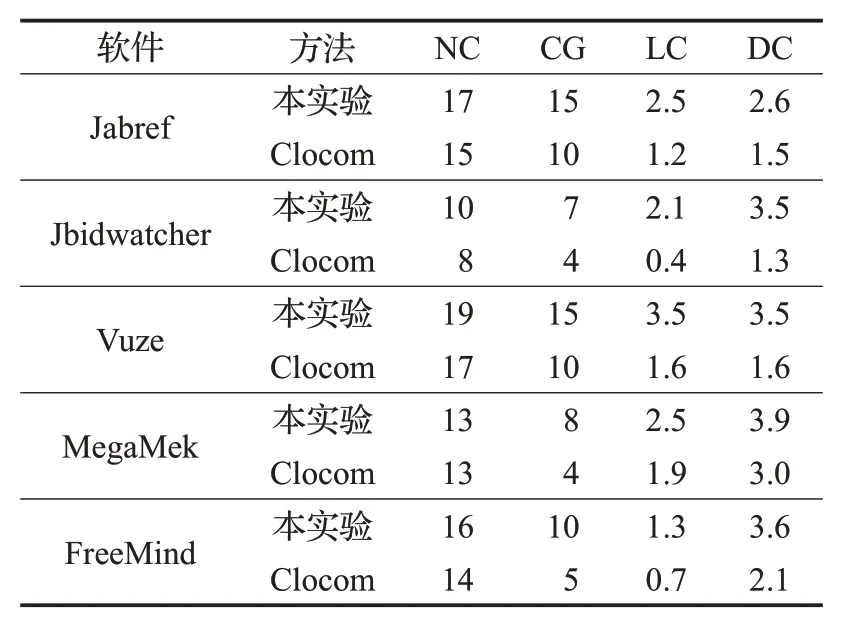
表8 代码注释产量对比结果
本实验在克隆检测阶段检测出的克隆代码类型比Clocom检测出的类型多。实验结果显示,在这5款软件中,本实验总共生成75 条代码注释,Clocom 生成67 条代码注释,本实验比Clocom多生成8条代码注释,在代码注释产量上高于Clocom。因此在这4个参数中,本实验生成代码注释的产量相对Clocom较多。
然后对生成代码注释的质量进行了对比,如表9所示。通过表9 可以看出,在生成的代码注释中,对于每一款软件,本实验生成的代码注释的质量都比Clocom大约提高5个百分点,5款软件中有4款在生成的注释中良好的代码注释所占的比例比Clocom大,质量较高,有一款软件良好的代码注释所占的比例略微低于Clocom。
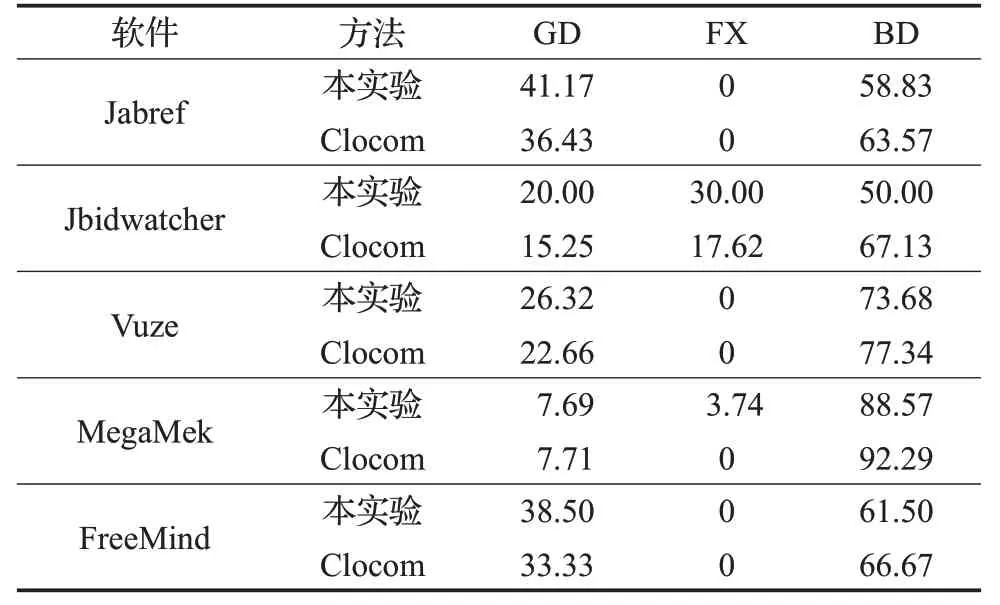
表9 生成代码注释质量对比结果 %
综上,本实验自动生成代码注释的产量比Clocom提高了约12%,质量也相比于Clocom提高了约5个百分点,均高于Clocom。
5 结束语
对于现在行业中代码注释数量稀少、质量不高等,导致软件的可读性和可维护性下降的问题,本文提出了一种自动生成代码注释的方法来提高注释的数量和质量,帮助程序员提高代码的可读性和可理解性。本文首先通过克隆检测工具Nicad检测出开源项目软件库和目标代码软件库之间的相似代码即克隆代码,根据代码注释提取算法通过Nicad 生成的XML 文件提取出克隆代码;其次根据行号等提取出相对应的代码注释;然后对提取出的代码和注释经过一系列的启发式规则,将克隆代码和注释精简优化成所需要的代码和注释;最后将注释与代码匹配映射,自动为目标代码生成注释。
本文的研究工作还存在一些不足之处,例如检测相似克隆代码时用到的工具,虽然检测的克隆代码数很多,包含Type-1、Type-2和Type-3三种类型,但是时间复杂度会很高,这会影响到最终实验结果的时间效率。在最后的评估中生成代码注释的质量也很低。本文将在后续的研究中考虑这些问题,为人们在该领域的研究提供更有力的数据,并奠定坚实的基础。
猜你喜欢
环球时报(2022-09-20)2022-09-20 15:18:57
今日农业(2020年24期)2020-12-15 16:16:00
学生天地(2020年5期)2020-08-25 09:09:08
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
电子测试(2018年10期)2018-06-26 05:53:36
汽车博览(2016年9期)2016-10-18 13:05:41
兽医导刊(2016年12期)2016-05-17 03:51:50
