
基于噪声自适应的交互式多模型算法研究
2020-05-15 09:25:16张世仓
洛阳理工学院学报(自然科学版) 2020年1期
谷 鹏,颜 明,张世仓
(中国航空工业集团公司雷华电子技术研究所 第一研究部,江苏 无锡 214063)
目标跟踪过程中,最优状态估计方法主要采用单一模型的滤波算法,而当目标发生机动时很难达到理想的滤波效果,甚至会带来滤波发散。交互式多模型算法(IMM)[1],通过马尔科夫转移概率可以在多个模型之间有效切换,因此在目标作大机动的条件下,相比于其他算法具有更强的跟随性和鲁棒性[2]。传统的交互式多模型中每个模型的测量噪声和过程噪声统计特性都假设认为是先验已知的,然而在实际工程应用中,过程噪声和测量噪声都是无法预知的,这大大限制了交互式多模型的性能。为了能够解决过程噪声和测量噪声特性未知的问题,可以采用在线估计测量噪声和过程噪声的噪声自适应技术。SAGE等[3]提出了最优和次优自适应的贝叶斯算法,能够在线实时估计过程及测量噪声,已经在一些领域得到广泛应用。Hail等[4]提出了一种过程噪声自适应算法,当最优估计精确时,过程噪声保持不变,当估最优估计发生偏离时,由残差信息重新确定过程噪声的值。近年来,很多学者开始关注自适应噪声估计在机动目标跟踪中的研究[5-6]。有学者[7-8]将基于Sage-Husa噪声统计估值器的自适应算法应用于初始对准和传递对准研究中,然而该方法由于不能保证测量噪声和系统噪声协方差阵的正定性,容易产生滤波发散,且计算量较大。
为了解决目标机动过程中噪声特性未知的问题,本文提出了一种基于噪声自适应的交互式多模型(NA-IMM-EKF)滤波算法。针对传统的Sage-Husa自适应算法存在时变噪声的适应性差和滤波无法收敛等问题,引入了遗忘因子对自适应算法进行优化,使其能够应对噪声变化并且利用有偏估计的次优算法从整体上保证了算法的收敛性,从而得到了改进的自适应噪声算法。
1 自适应噪声估计算法及改进
Sage-Husa是一种自适应滤波算法,基于观测序列求得最优状态值并通过极大后验估计原理,估计出系统噪声和测量噪声。但是最优SAGE极大后验噪声统计估值需要在线调整计算滤波状态的全平滑值,计算过于复杂,无法进行实际应用, 因此常用递推次优无偏估计算法:
(1)
(2)
式中:k为时刻,K为滤波增益,P为误差协方差,εk=Zk-Hkxk|k-1为信息。
为改善算法对时变噪声的跟随性能,一些学者引入遗忘因子[9-10]改进递推子空间辨识算法。机动目标跟踪过程同样可以通过引入遗忘因子调整噪声,一般选取遗忘因子的原则是对噪声变化较大时要赋予较大的遗忘因子值,增强当前测量信息的修正作用,对噪声变化较小时赋予较小遗忘因子值,维持历史噪声信息,从而达到时时调整系统噪声的统计特性。引入遗忘因子调整噪声统计特性的表达式如下:
(3)
(4)
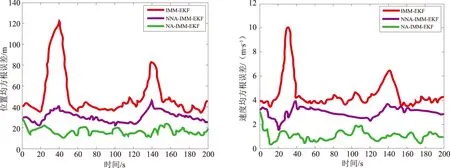
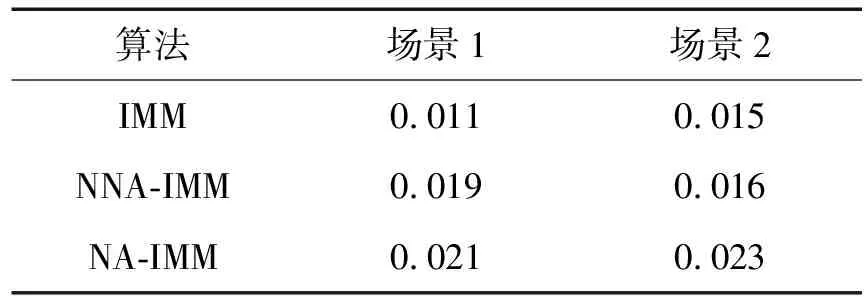
式中:dk-1=(1-b)/(1-bk),0 交互式多模型算法由多个滤波器组成,每个滤波器对应着各自的模型。假设模型概率切换是在马尔科夫链下进行的,那么不同时刻各模型之间的转换都是按照已知的马尔科夫链状态转移概率矩阵进行切换,交互式作用器则利用模型概率和模型转移概率来计算每一个滤波器的交互估计[13-14];此时N个滤波器同时进行并行工作,总的状态就可以通过新的状态估计以及相应的模型概率计算出来。基于以上结论,在噪声方差未知的情况下,本文将改进的噪声自适应算法引入到IMM-EKF滤波器中,推导了基于噪声自适应估计的IMM-EKF(NA-IMM-EKF)滤波算法的递推实现过程: (1)输入交互 (5) (6) 计算完k-1时刻的滤波器j的状态估计值和状态协方差矩阵后,还需要进一步的通过NA-IMM-EKF滤波算法利用过程噪声的估计值预测第j个滤波器在k时刻的状态协方差矩阵及预测状态等信息,该过程就是卡尔曼滤波[12]过程,此处不再赘述。 (2)模型估计 (7) NA-IMM-EKF滤波算法中模型估计的概率具体表达式如下: (8) (3)模型概率更新 根据NA-IMM-EKF算法估计出的噪声和模型估计推导出模型概率更新如下: (9) (4)融合输出 经过预测和更新后,NA-IMM-EKF算法的融合输出如下: (10) (11) (5)噪声自适应调整 假设k-1时刻的测量噪声方差估计值Rj(k-1)和过程噪声方差估计值Qj(k-1)是已知的,则k时刻的测量噪声方差估计Rj(k)和过程噪声方差Qj(k)为 (12) (13) 式中:加权系数dk-1=(1-b)/(1-bk),通常b的范围为0.95≤b≤0.995[11]。 通过监控的手段判断Qj(k)和Rj(k)是否满足正定性。若不满足,则采用有偏估计的方法来修正其估计值,即: (14) (15) 特别注意,为了确保系统噪声方差和测量噪声方差保持正定,本文采用的方法是近似有偏估计的方法,因此提出的NA-IMM-EKF算法在滤波更新过程中的滤波估计值不是最优解而是次优解。 假设目标在XOY平面运动,因此可以在该平面上建立CV和CT模型对目标运动进行仿真,目标运动可以分为以下时间段:1~13 s目标做匀速直线运动,速度为20 m/s;14~42 s目标做匀速转弯运动,角速度为12 °/s;43~122 s目标做匀速直线运动,速度为20 m/s;123~145 s目标做匀速转弯运动,角速度为-5 °/s;146~200 s目标做匀速直线运动,速度为25 m/s。 采用二维坐标的目标跟踪系统作为仿真环境进行100次蒙特卡洛仿真,假设目标的初始状态为x0={5 000,20,4 500,10},每个模型的初始测量噪声方差R=diag {202,0.22},仿真时间长度为200 s,采样周期T为1 s,参数遗忘因子b=0.97。 实验中假设测量噪声和系统噪声分别为独立的零均值的高斯白噪声,但是系统噪声的统计特性未知,可以按照系统噪声分为两种场景进行仿真。 场景1:Q=diag(0.52,0.52) 仿真实验的均方根误差[15](Root Mean Square Error, RMSE)定义为 (16) 式中:n表示仿真次数。 本文采用交互式多模型(IMM-EKF) 、不带遗忘因子的噪声自适应交互式多模型 ( NNA-IMM-EKF) 和带遗忘因子的噪声自适应交互式多模(NA-IMM-EKF) 3种算法对机动目标进行跟踪。仿真结果如图1~图4所示。传统IMM-EKF算法在1~13 s、 43~122 s、146~200 s目标跟踪精度较高,但在14~42 s、123~145 s目标跟踪精度较差,主要原因是测量噪声方差与实际噪声方差不匹配,导致跟踪精度下降。NA-IMM-EKF算法和NNA-IMM-EKF算法在平稳段精度与IMM-EKF算法相差并不大,但是在机动段由于采用了自适应的噪声调整方法,这两种算法更能适应该真实场景的目标跟踪,而NA-IMM-EKF算法相对于不带遗忘因子的NNA-IMM-EKF算法在机动段表现出更高的精度,原因是在自适应调整噪声进行滤波估计时,采用了遗忘因子b来减小以往数据的权重而增大新息的权重,从而更加适应机动目标噪声方差的估计问题。表1和表2为1~200 s位置误差和速度误差的均方根(RMSE)统计量和方差统计量。由表1和表2可知,NA-IMM-EKF算法的 RMSE 值明显小于另两种算法并且其方差相对也比较小,说明目标跟踪的精度和稳定性方面NA-IMM-EKF 要显著优于NNA-IMM-EKF和IMM-EKF算法。因此,不管是定常噪声还是时变噪声场景,NA-IMM-EKF跟踪精度更高且鲁棒性更强。 图1 场景1的位置均方根误差 图2 场景1的速度均方根误差 图3 场景2的位置均方根误差 图4 场景2的速度均方根误差 表1 场景1算法效果比较 表2 场景2算法效果比较 3种算法的仿真运行时间如表3所示。从表3可以看出,NA-IMM-EKF算法的时间复杂度较大,其原因是该算法利用遗忘因子在线自适应调整噪声方差增加了运算复杂度。这3种算法在运算的时间复杂度方面相差并不大,但得到的效果却截然不同。因此,在可承受范围内增加一些时间复杂度提高目标做机动时的跟踪精度是值得的。 表3 算法平均运行时间比较 本文提出了一种基于噪声自适应的交互式多模型算法,该算法可以在滤波的过程中同时调整噪声方差。仿真结果表明,NA-IMM-EKF算法能够有效地跟踪机动目标,该算法的适应性强、收敛性好,克服了传统交互式多模型算法在未知噪声方差情况下存在的精度下降等问题。2 基于噪声自适应的交互式多模型滤波算法
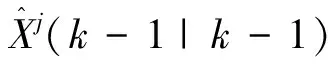
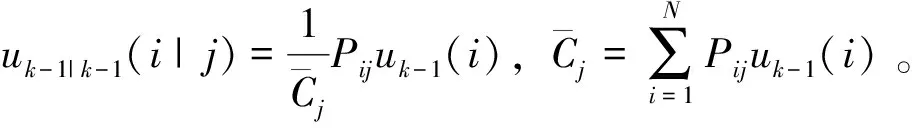
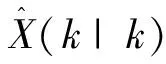
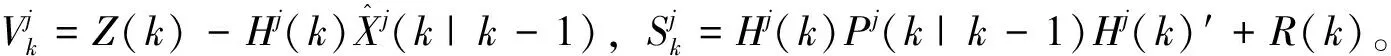
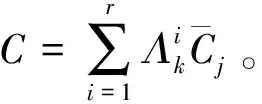
3 仿真实验
3.1 目标运动轨迹
3.2 仿真分析




4 结 语
猜你喜欢
计算技术与自动化(2024年3期)2024-10-10 00:00:00
中学生数理化·七年级数学人教版(2023年6期)2023-05-25 12:17:42
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09 06:09:10
装备制造技术(2020年3期)2020-12-25 05:21:52
当代陕西(2019年12期)2019-07-12 09:12:02
电子制作(2019年11期)2019-07-04 00:34:38
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:32
汉语世界(The World of Chinese)(2019年1期)2019-03-18 01:50:16
电子制作(2018年16期)2018-09-26 03:26:50
初中生世界·九年级(2017年10期)2017-11-08 21:30:36
