
基于DPDK的多端口并行通信机制
2020-05-14 07:09:24姜海粟陈庆奎
小型微型计算机系统 2020年5期
姜海粟,陈庆奎
(上海理工大学 光电信息与计算机工程学院,上海 200093)
E-mail :1072668856@qq.com
1 引 言
随着物联网大数据应用的增加,物联网终端需要处理大量数据.过去的手段都集中于云端处理,现在由于数据量暴增造成云端负担过大,因此一种新兴的边缘计算技术应运而生[1].边缘计算可以在外围对数据进行预处理,再汇集到云中心.它的核心则是通过若干个节点形成的小型计算机集群构成.边缘计算的一个核心问题必须是有一个高性能通信机制.实现边缘计算节点通信的方法有多种,其中一方面是采购专用的通信网络设备比如智能网卡和P4交换机等[2],但是这些设备价格高昂,无法进行普及.另一方面随着普通网卡设备日渐廉价,速率也在提升,服务器多口设备也在日益增加.但是如何充分利用这些设备一直是业界探讨的问题.基于这些问题,Intel在2014年推出了一种数据平面开发套件DPDK(Data Plane Development Kit)[3],DPDK通过绕过传统的系统内核协议栈,直接进行内存访问,减少中断等机制提升通信效率,同时将底层数据处理移至用户态.
据此,本文对DPDK的原理进行深入研究,基于这一思想提出一种数据链路层多端口并行通信机制,在每个节点上配置了多个千兆端口,使其复合端口通信能力接近万兆.该通信机制不仅降低了设备通信成本,而且具有优越的通信性能和良好的扩展性.本文的通信机制具有如下特点:
1)实现基于DPDK通信的多进程数据快速交互;
2)实现基于DPDK的管道模型及高速数据传输;
3)实现具有动态调整的多端口多任务通信.
2 相关工作
2.1 DPDK通信研究现状
随着用户态数据平面框架的出现,许多人开始采用DPDK、NETMAP等框架进行数据开发处理,通过绕过内核提升通信效率.但是大都只针对数据进行过滤和转发,很少直接处理后直接交付上层[7,11].
传统的DPDK上下层通信方式是通过内核协议栈交换数据.DPDK用户层通过ioctl系统调用在系统内核创建kni虚拟设备实现.并通过ioctl提供接口和DPDK空间地址信息,由kni重新映射到内核栈的地址空间,并将信息保存至虚拟设备中.这种方式通过已绑定的DPDK端口进行数据包捕获,然后通过KNI驱动将需要交付上层的数据包重新交付给内核协议栈进行所有数据处理,最后进入上层.这种方式并没有真正的解决上下层数据通信效率的问题,数据仍然通过内核处理交付上层,内核瓶颈依然存在.
随着对DPDK的研究逐渐深入,一些人开始将其应用在改进数据传输方面.Wenjun Zhu,Peng Li等人利用了DPDK的技术优势,提出一种基于DPDK的数据包捕获方法[4],使用 RSS分发算法充分发挥了多端口通信性能.但是他们只能在假设数据包经过哈希后分发均衡,并且只进行单任务的多端口发包处理.一旦端口已经处于已占用部分带宽条件下,没有考虑实际环境的RSS分发算法反而会造成端口拥塞,无法持续多端口并行通信.
Kourtis MA则是将DPDK应用在网络虚拟化,将SR-IVO与DPDK结合,利用DPDK底层的高速数据处理性能,用来提升云计算网络中密集型数据在转发面的通信性能[5].金玲等人针对大象流数据,提出基于DPDK的EFLB机制[6].通过设定网络负载阈值,在超过阈值的情况下,利用SDN控制器将大象流分裂成老鼠流通过多端口通信,并根据网络拓扑和负载动态计算下一跳节点.该机制是在已经检测到大象流条件下进行分裂,容易出现数据洪峰效应.
针对边缘计算集群通信效率问题,本文从单机节点底层通信出发,提升单机通信效率,提出基于DPDK的数据链路层多端口并行通信机制.该机制改进了基于DPDK的上下层通信,并提出权值相似匹配的端口动态绑定分发策略和优化反馈控制策略,可以通过发起多个上层应用任务向底层多个端口进行通信.
2.2 DPDK介绍
DPDK的核心组件主要由一系列网卡驱动和基本操作模块构成,是基于数据平面开发的一款套件.利用该套件可以直接绕过内核访问网卡,允许用户直接对数据进行处理.DPDK主要特点如下:
1)页表(TLB)技术:处理器具有预读取连续内存地址的能力,能够快速的找到对应的内存地址,获得内存数据.DPDK采用页表技术,将零散的内存统一为一个独立于系统内存的内存池,并且将其划分为连续虚拟地址的空间[12,13].
2)用户态(UIO):DPDK利用UIO技术,绕过系统内核,直接利用驱动调用网卡,将大部分数据包处理过程暴露给用户,使得用户可以根据所需要的功能开发各自的模块.
3)DMA技术:传统的系统内核协议栈处理数据需要大量的拷贝以及多次的系统调用,大大占用了CPU资源.DPDK采用了DMA技术[7],使CPU一直处于轮询状态.网卡获得总线控制权限直接将数据拷贝至内存,减少了拷贝的次数和CPU中断.
4)亲和性:DPDK通过将控制线程绑定到指定处理器核心上,使得线程仅在该核心上运行,线程之间不能互相干扰,减少了线程切换时处理器核心的开销.
DPDK主要框架如图1所示.
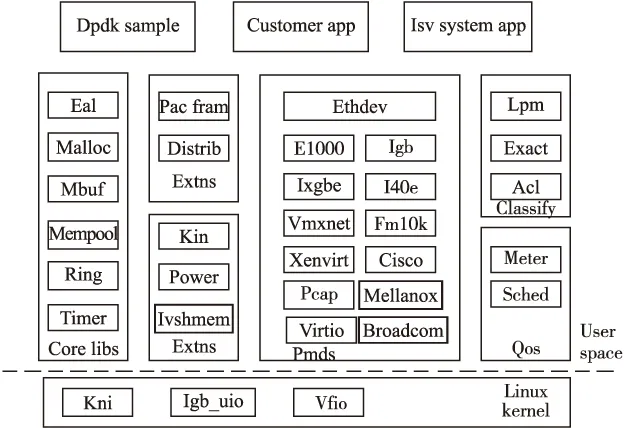
图1 DPDK主要框架(来自文献[3])
DPDK整体框架结构由图1的各个模块组成.在Linux kernel上提供了三种驱动KNI、IGB和VFIO.KNI用于兼容传统内核协议栈,IGB驱动是将数据完全交给DPDK进行处理,VFIO则用于支持虚拟化.在用户层面上,DPDK的主要处理函数库都在core libs上,包括内存控制,队列控制和定时器等.以及为了支持多种型号的网卡提供不同的pmd驱动方式.
3 整体设计
3.1 通信框架
本文通信机制是基于Linux系统和DPDK平台实现,可以在单机上充分利用多核多端口,同时支持多应用与底层连接.
在以往的服务器通信系统中,往往只用到少数网卡端口进行通信,同时为了避免竞争,多采用加锁的方式.由于处理器比内核和内存快很多,导致处理器常常处于等待状态,造成了极大的资源浪费[8,9],此外大量时间耗费在无意义的上下 文切换和锁的处理上.该通信机制设计之初就绕过传统的内核协议栈基于IGB驱动进行多核多线程处理.主逻辑核用于维持底层进程处理,其余逻辑核绑定单一线程用于动态轮询管道及网卡端口.通信框架如图2所示.
上层应用和底层同时共享DPDK内存池空间.上层应用通过外部消息队列的方式在底层进程注册一个通信连接,底层进程就会将DPDK内存池中某个空闲通信管道与应用进行绑定.上层可以直接申请mbuf内存块填充数据,然后将数据指针放入管道.底层通过另一个逻辑核线程从管道进行轮询,然后调用端口将数据发出.
当上层应用完成通信就会通过连接向底层进程发出关闭请求,底层进程回收上层申请的管道和内存块.若需继续传输,则会发出维持连接请求,否则超时也会自动关闭连接回收内存池空间.
通信模型在DPDK内存池中建立共享命名区域实时传递控制信息.上层与底层双方通过公共命名直接找到对应DPDK共享区域的指针.底层在共享区域内会实时更新上层所需的速率控制信息、应用信息和端口信息等.上层应用实时读取共享区域的控制信息反馈自适应的调整封装速率和可用端口.当发起多个上层应用传输时建立多个通信连接,根据上层应用创建的顺序,自动调整不同的优先级进行多端口通信.
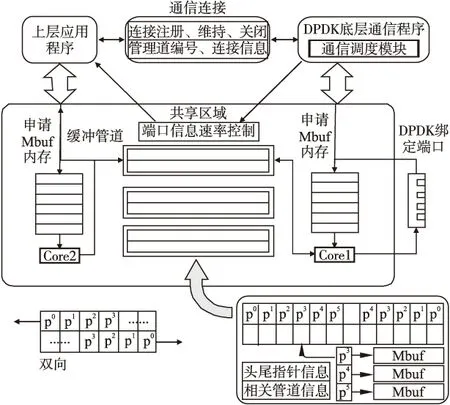
图2 通信框架
3.2 管道模型
管道主要用来建立端口和上层应用的数据传输通道,同时会返回管道负载和管道占用等参数提交给通信调度模块进行控制信息计算.
DPDK在环境初始化过程中,使用了内存池机制,将固定分配到的内存进行了连续虚拟地址映射,分配成连续内存块,每个内存块拥有2Kb的Mbuf空间.连续虚拟地址的设计提升了处理器的预读取性能,提高了内存命中率,是本机制实现数据包快速处理的一个关键.
本文针对应用数据的快速处理,设计了如图2右下角所示的双向缓冲管道.每个管道对应一个双向循环队列,每个队列拥有16384个存储内存块指针空间,该循环队列引入头指针和尾指针负责循环队列中内存块的快速数据传递.循环队列的片区存储内存块的起始地址,指向连续的内存区域.当循环队列中有数据处理出现超时或者管道内数据持续溢出,则计算后通过共享区域通知并上层限制数据封装,提高了管道的可用性.
3.3 通信逻辑设计
本文通信逻辑主要由端口分发策略和反馈控制策略.通过端口分发可以选择合适的端口进行传输,反馈控制是统计和计算各个参数得到控制信息状态,并将状态通过共享区域快速反馈给上层应用以达到控制上层封装数据速率.反馈控制统计参数包括有应用编号、端口数量设置、数据包大小、管道负载、管道趋势和每个端口负载等.
3.3.1 端口分发策略
传统端口分发算法采用端口平衡循环算法或者权重轮询算法进行数据包分发.平衡循环算法对外通过多个端口聚合成一个端口进行通信,在其内部通过直接循环多个物理端口分发数据[10].然而,一方面由于它对外绑定成一个虚拟端口,无法实现自定义端口功能,对内未针对无序数据分发,也容易出现丢包问题.另一方面使用传统算法只考虑数据分发和接收的公平性,并未考虑实际运行环境(包括对方端口负载,核心负载,端口性能等),容易出现分发失误导致资源使用不均匀和端口拥塞等问题,最终造成通信故障.权重轮询算法则根据当前本地端口使用率以及当前端口权重比来分配使用端口.节点之间的网卡端口使用率和权重很难动态的进行调整,无法充分发挥端对端通信性能[14].
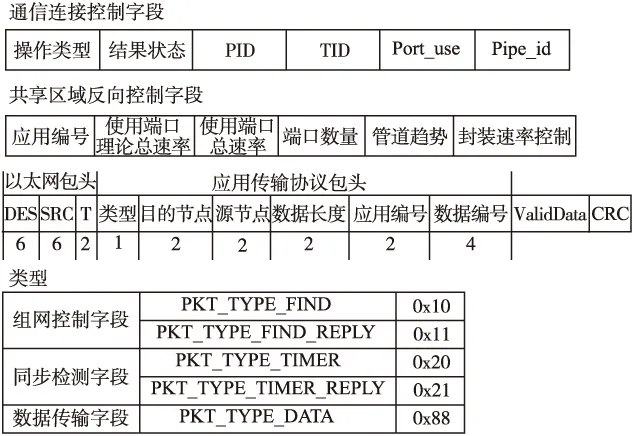
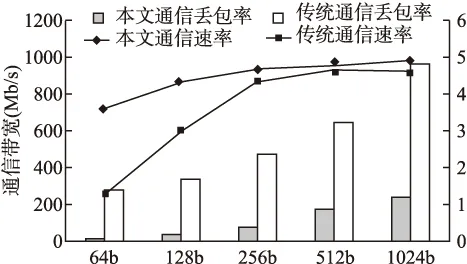
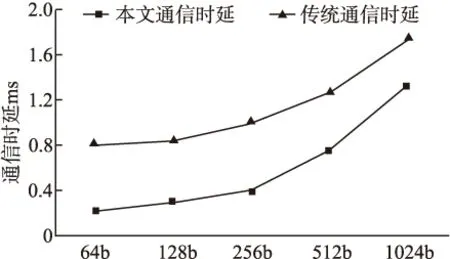
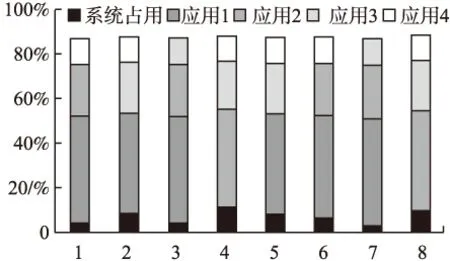
由于是在边缘集群中,各节点经过同步都能获得其他节点端口信息.因此本文在传统轮询负载权值基础上加入目的节点端口信息进行匹配计算.本机权值Wsend{M1,M2,M3,…}每个端口由当前端口i负载U(0 定义权值公式如下: (1) (2) (3) 公式(1)使用每个参数的系统平均值,作为公式(2)中计算端口i综合占用L的参数.通过公式(3)获得该端口在单机的权值Mi. 确认目的节点后,本机通过节点信息表对目的节点端口进行评估,计算出对方权值Wrecv{M1,M2,M3…}.然后通过双方进行端口相似匹配.匹配过程如下: 本机节点通过公式(3)计算获得本机节点和目的节点的Wsend{M1,M2,M3,…}和Wrecv{M1,M2,M3,…}.Mi分别表示每个端口的权值信息,由于各个端口硬件性能可能不同,需要加入端口性能信息E{E1,E2,E3,…,En} 辅助相似计算: (4) 循环匹配(Msend_i,Esend_i)和(Mrecv_j,Erecv_j)代入计算公式(5)计算曼哈顿距离,距离越小说明相似度越高. distman(i,j)=|xi-xj|+|yi-yj| (5) 对相似度最高的一对作为端口绑定保存到序列中,然后对队列剩余部分继续进行匹配.最终经过相似度匹配和排序后获得端口绑定序列{(isend,jrecv),(msend,nrecv)…},然后根据上层选择匹配较高的N个端口进行通信. 3.3.2 反馈控制策略 通信调度模块通过获得不同模块的参数,并建立对应的多个上层应用与底层参数对应表,然后经过反馈控制策略将结果通过共享区域反馈给上层应用和底层通信程序以实现对上层应用控制.反馈控制逻辑如图3所示. 反馈控制模块通过获取端口、管道等多个信息通过计算反馈给上层.上层获得控制信息后调整内存申请和封装速率,逻辑核获得控制信息后会修改端口发送效率和缓冲管道使用效率.因此,该反馈控制策略的衡量参数为缓冲管道使用趋势Q(0 图3 反馈控制逻辑 本文通过前面的端口分发策略获得可用端口N个,然后获得其各个端口的当前负载Nload和端口型号速率E并计算它的理论总速率,计算总速率表示为公式(6).已知信息还包括缓冲管道容量Pa、上层封装速率Vu、统计周期T和基于层次化带宽算法设置的比例系数k.Q值根据前次计算结果进行迭代计算,表示为公式(7),并设置初始Q值为0. (6) (7) 层次化带宽算法是基于效用函数针对适用带宽方法提出的[15].效用函数主要用于在经济中衡量消费者和消费商品组合数量关系的函数,用来衡量消费者的满足程度.在反馈控制逻辑中,主要用于衡量不同应用任务对带宽资源的层次化需求.因此,本文将根据应用任务的创建优先级对带宽资源进行层次化分配. 反馈控制主要根据Q值进行,当Q过高则判断Pa占用以及Va和Vu. Feedbackcontrolcodedescription: 1.while(data) 2.foreach app in socket_connect 3. get k from upper layer 4. calculate Q and Va; 5.ifQ>0then 6.ifPaused higher or Vuabove the linethen 7. reduce Vu 8.elsereduce Va 9.endif 10.elseboth raise Vuand Vauntil one meet the line; 11.endif 12. Write control information into the shared area; 13.endfor 14.endwhile 应用在启动时确定使用端口数量,然后在进行通信传输中需要满足公式(6)-公式(7).同时根据任务优先顺序自动设置占用剩余带宽比值k.随着多个应用的加入,根据应用总速率k呈接近反比例下降趋势.过程中若某个任务先结束,则底层会根据周期更新控制信息重新调整应用k值. 由于在传统的应用通信协议中,除了以太网包头,通信协议占用数据28-48字节,在应用通信中占用了大量资源,降低了通信效率.因此针对上文的通信机制,设计了对应的通信协议,只占用了大约13字节.同时也设计了包括通信连接控制字段和共享区域反馈控制字段两个部分.控制字段和通信协议如图4所示. 图4 控制字段及通信协议 通信连接控制字段:上层应用在启动时会向底层通信程序注册连接,用来维护连接状态,同时底层返回内存池字段并绑定管道编号.连接状态包括注册、注销和保持三种状态.通过绑定的管道,上层可以在DPDK内存池申请的内存块封装数据包丢入指定缓冲管道进行处理. 共享区域反馈控制字段:每注册一个上层应用程序,底层就会增加一条对应上层应用的反馈控制信息,并定时进行数据更新.端口速率控制由底层通信程序实时读取相关参数计算后返回,上层应用程序通过实时读取反向控制字段中的参数进行数据封装速率控制. 应用传输协议:初始环境下通过主节点组网广播建立节点地址连通机制,然后向所有节点下发节点地址通信表,并定时同步更新维护节点表内容,所有节点通过表内容可以向指定节点进行通信.然后进行上层应用发起及通信传输,具体通信步骤如下: 1)所有子节点先上线,底层进程启动并建立节点通信空表,同时获得本机编号信息、端口、处理器、内存等信息状态. 2)主节点上线并等候30秒,启动底层进程及获取本机信息,然后发起广播组网通信.所有子节点以及主节点自身收到并过滤广播组网信息向主节点返回主机所有信息,主节点对通信表进行节点数据填充. 3)主节点处理完毕后向所有节点下发节点通信数据,子节点收到并填充到节点通信表.然后定时进行所有节点同步维护通信表的更新.此时,所有节点都拥有任何一方的节点的端口信息. 4)接收方在节点发起上层应用,向底层进行连接注册并绑定管道,底层开始对端口及管道信息进行计算并通过共享区域返回上层. 5)发送方同 4),在读取共享区域的控制信息后,申请Mbuf内存块并根据传输协议字段封装数据.底层轮询线程读取数据字段的目的节点、源节点和类型信息查找节点通信表,然后填充地址和目的地址后送入绑定缓冲管道. 6)底层进行另一个轮询线程从管道中获得Mbuf指针,读取目的地址和源地址,并从指定端口将数据发出. 7)接收方端口轮询线程从端口接收数据,并申请Mbuf内存块封装数据,读取数据的目的节点送入绑定管道.另一个轮询线程从管道获得数据,通知上层.上层完成数据重组释放Mbuf内存块,关闭连接,完成应用通信. 本节对多端口通信机制的各项性能指标进行实机测试.实验设定多台测试服务器,配置信息如表1所示. 表1 配置信息 Table 1 Configuration information CPU:E3-1230v23.3GHzMemory:8g ddr3∗21600MHzSystem:Centos 7NIC:i350-T41Gb/s each portDPDK:17.11.3 本文对该模型通信性能主要从带宽利用率、丢包率、时延以及多端口通信等多方面测试进行性能评估. 带宽利用率:DPDK支持绑定多个网卡端口,本文在并行条件下测量多个DPDK端口的带宽使用率. 丢包率:本文采用不可靠交付方式进行通信,因此对比传统UDP方式进行丢包率评估. 时延:时延主要包括发送时延、传输时延和处理时延.由于本文是以边缘集群节点环境为目标,因此可以忽略集群节点的传输时延.发送时延定义如公式(8): (8) N表示数据块大小,R表示传输速率,DT表示发送时延.本文的处理时延包PT括三个部分:应用处理时延AT、DPDK底层处理时延MT、进程交互处理时延GT,M为当前内存速率.因此公式定义如式(9)-式(11): (9) PT=AT+2MT+2GT (10) D=PT+DT (11) 最终到达对方应用的总时延需要经过两次DPDK底层处理和两次进程交互处理. 在通信性能和丢包测试中配置主机使用双核单端口测试,这里和经过内核的传统应用通信进行对比测试.测试包从64字节到1024字节,数据量为6GB.通信性能和丢包率如图5所示. 图5 通信性能测试 由图5可知,折线图为通信速率对比,直方图为丢包率对比.通过折线图可以看出本文单端口通信在64字节和128字节的包处理上明显优于系统内核传输.通过直方图可以看出传统通信丢包率在万分之一到万分之五左右,而本文机丢包率在十万分之一到万分之一之间,丢包率大大降低. 通过使用4.2的时延计算公式计算时延并进行对比,通信时延测试结果如图6所示. 图6 通信时延测试 如图6所示,得益于底层高效的数据包处理性能,在忽略传输时延的条件下,本文的通信时延明显低于传统的通信时延,主要在于减少了内存拷贝次数以及提升了单个包的数据处理,测试过程发现本文在单个数据包的处理速度小于60ns,相对于内核数据处理性能提升了10倍以上. 多端口测试主要采用一对一多端口测试模型对比传统MPI多端口测试模型,同时设置不同端口数量.节点上线同步完成后,打开接收方和发送方.然后令发送方设置1024字节发送6GB数据量文件.实验结果如图7所示. 图7 多端口测试 通过图7可以发现,本文的机制对比传统MPI通信优势明显.根据应用端口数量效率提升幅度分别为(1,44.4%)、(2,43.5%)、(3,48%)、(4,45.7%)、(5,56%)、(6,70.3%)、(7,80%)和(8,85.8%).而MPI通信受限于内核,无法充分发挥多端口性能. 最后是节点之间的多应用测试,主要适用于端到端的多文件或者多应用通信.该实验在设置应用6个可用端口,总端口为8个的条件进行,发送节点设置4个应用进行通信.实验结果如图8所示. 图8 多应用多端口测试 如图8所示,应用1通过计算按照端口分发策略获得较高匹配的6个端口进行通信,其后的应用也同样通过策略获得匹配度较高的6个端口.从图8可以明显看出,应用2使用了应用1未使用的匹配较低的端口,应用3则在前两个应用的基础上重新计算获得相对匹配较高的端口.通过本文的机制最终达到所有端口充分使用的效果. 本文通过对DPDK通信技术的研究,针对传统端对端通信效率低下,受限于内核瓶颈,浪费大量计算资源和带宽资源的问题,提出了一种基于DPDK的多端口并行通信机制.该机制在支持多端口通信的基础上,能够支持多进程高速交互及端口分配和多任务通信的动态调整,避免了端口拥塞的问题.实验结果表明,该通信机制可以充分利用计算资源和带宽资源,极大地提升通信效率,最高能够同时支持多个万兆网卡,缓解了终端节点的通信瓶颈.本文的后续工作是对底层通信继续优化以及数据可靠传输的实现.
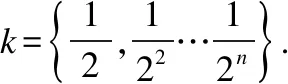
3.4 控制字段及通信协议
4 性能评估
4.1 实验环境说明

4.2 性能评估指标
4.3 测试流程及结果评估

5 结 语
猜你喜欢
科技与创新(2023年17期)2023-09-17 12:26:12现代装饰(2022年4期)2022-08-31 01:41:24军民两用技术与产品(2022年2期)2022-06-01 06:29:44今日农业(2021年9期)2021-07-28 07:08:36网络安全和信息化(2019年1期)2019-02-15 02:45:42成都信息工程大学学报(2018年4期)2019-01-23 06:57:18信息安全研究(2018年12期)2018-12-29 11:01:56电脑爱好者(2015年15期)2015-09-10 07:22:44小说林(2014年5期)2014-02-28 19:51:47杂文选刊(2013年7期)2013-02-11 10:41:11
