
高校图书馆用户群体的阅读偏好
——对“热门图书”数据的考察*
2020-05-12 07:51章成志周清清
图书馆论坛 2020年5期
张 恒,章成志,周清清
0 引言
1970 年代中期诞生的OPAC 系统(Online Public Access Catalog,又称“联机公共检索目录”)[1]在日常运行中,积累了用户大量的图书检索、浏览等信息,图书馆分析这些数据,生成了一些应用。比如,OPAC系统按照《中国图书馆分类法》(以下简称《中图法》)划分的22个类别,基于图书浏览次数生成“热门图书”排行榜推荐给用户,用户对OPAC系统中图书详情页面的浏览,表明用户对该书感兴趣[2]。因此,基于所有用户浏览次数生成的“热门图书”在一定程度上代表整个用户群体的阅读偏好。由于热门图书只是每所高校馆根据各自的OPAC数据统计生成的,存在局限性,所以本文采集多所高校馆的热门图书数据,生成每所高校的用户群体阅读偏好向量,然后对这些高校进行聚类分析。这项工作将聚类分析应用于用户群体阅读偏好研究,扩展了该类研究的思路;帮助高校馆把握用户群体的阅读偏好,通过聚类发现具有相似群体阅读偏好的高校;聚类结果可对资源建设提供帮助。
1 相关研究概述
1.1 OPAC数据挖掘
用户在OPAC系统中进行图书检索,系统以日志形式保存相关信息,挖掘检索日志有助于理解用户行为与兴趣,有针对性地优化系统,还可以为图书馆管理决策提供参考。对OPAC检索日志挖掘一般遵循一定的框架,如将检索日志挖掘分为数据采集、数据处理和数据分析3个阶段[3]。姜婷婷等搜集武汉大学图书馆18天的检索日志,遵循日志挖掘框架,从关键词、查询式、搜索会话3个层次分析用户行为[4]。侯志江等基于OPAC检索日志挖掘用户需求,从短缺图书和馆藏覆盖率等角度指导图书采购[2]。刘高军等基于北方工业大学图书馆10年的借阅记录,首先使用基于用户的协同过滤算法生成粗召回的推荐结果,然后针对具体用户提取相关特征,构建用户偏好模型,对粗召回结果集进行过滤,得到更精准的推荐结果[5]。OPAC 系统通常包含简单的数据统计与分析功能,可以对系统中积累的数据进行初步挖掘,并且将结果在系统中展示,为用户选择图书提供帮助。热门借阅、热门评分、热门收藏、热门图书、借阅关系图等都是在此基础之上进行的。陆艳以河海大学2003-2013年借阅量排名前100 图书数据为主,结合其他院校信息,分析高校馆读者阅读特征[6]。刘丽帆等基于89 所高校馆TOP 图书数据,参考全评价理论,结合层次分析法和决策树模型,预测高校馆用户阅读趋势[7]。
1.2 用户阅读偏好
用户会由于个人喜好、专业背景、研究领域等偏向于阅读某一些书,称为用户阅读偏好。阅读偏好是一种心理特征,也是一种行为倾向[8]。OPAC系统提供的热门图书排行榜依据所有用户的浏览次数生成,可以代表高校用户群体的阅读偏好。相关研究包括:门淑华等总结大学生阅读的多样性、广泛性、时代性、休闲型和实用性特点[9];于向前等发现大学生阅读出现盲目跟从、追求功利实用和偏好网络阅读现象,应通过树立高尚阅读动机、举办读书活动等进行引导[10];卢章平等将生物反馈技术引入就不同题材书籍对阅读偏好影响的探索,发现大学生心理因素与书籍内在元素都会影响阅读偏好[11]。
整体而言,OPAC数据研究多使用一所或几所高校数据来分析用户行为,且大多针对单个用户构建图书推荐模型。本文使用多所高校OPAC数据,从用户群体阅读偏好角度进行研究。
2 研究设计
2.1 研究框架
本文的研究框架如图1所示。(1)采集103所中国高校馆网站的“热门图书”排行榜数据,以“题名+责任者”对图书去重。(2)使用DF(Document Frequency)[12]特征选择法过滤图书,选择部分图书来反映高校用户的群体阅读偏好。(3)使用TF-IDF(Term Frequency-Inverse Document Frequency)[13]方法来计算图书在各高校中的权重,生成高校用户群体的阅读偏好向量。(4)使用AP聚类[14]方法对这些高校进行聚类,调整参数得到最优聚类结果。(5)对聚类结果中不同类簇高校的“热门图书”就类别分布、题名高频词、图书高频学科主题词进行分析。
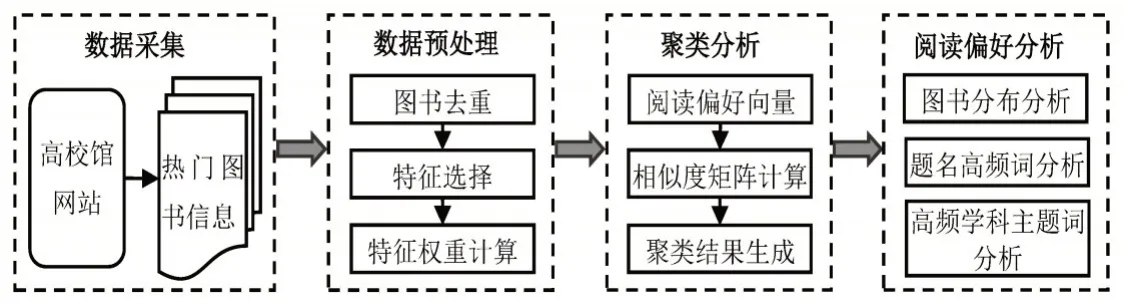
图1 高校馆用户群体阅读偏好研究框架
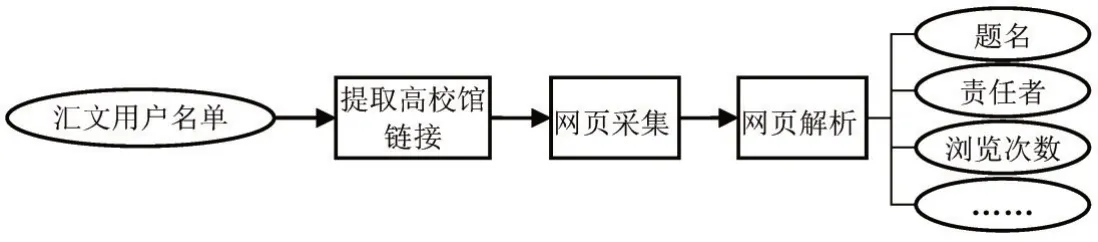
图2 数据采集流程
2.2 研究问题
“热门图书”排行榜是高校馆OPAC 系统根据用户浏览次数生成。出于兴趣用户才会在OPAC系统中检索相关图书,进而对检索结果中的图书详情进行浏览。高校馆中被大量用户浏览过的“热门图书”可以在一定程度上反映该校的用户群体阅读偏好。那么,基于用户群体阅读偏好是否可以将高校聚成若干个类簇?因此,本文主要研究两个问题:如何基于用户群体阅读偏好对高校进行聚类?不同类簇的高校用户群体阅读偏好有何不同?
2.3 关键技术描述
2.3.1 数据采集
江苏汇文软件有限公司(以下简称“汇文”)“Libsys图书馆管理系统”在国内高校馆中应用较为广泛,按照图2流程,本文设计爬虫程序自动采集高校馆“热门图书”排行榜数据。
首先,人工从汇文网站的“用户名单”中筛选一批可访问的高校馆网站链接。汇文系统按照《中图法》22个图书大类,为每个大类分别生成基于浏览次数的“热门图书”排行榜,每个榜单一般为100 种图书(少数情况下会低于100 种)。(1)本文采集各个类别的“热门图书”排行榜网页,(2)提取出每一种“热门图书”的题名、责任者、浏览次数等信息。最终采集到103所高校共225,734 条“热门图书”数据,采集时间为2018年10-11月。部分数据见表1。
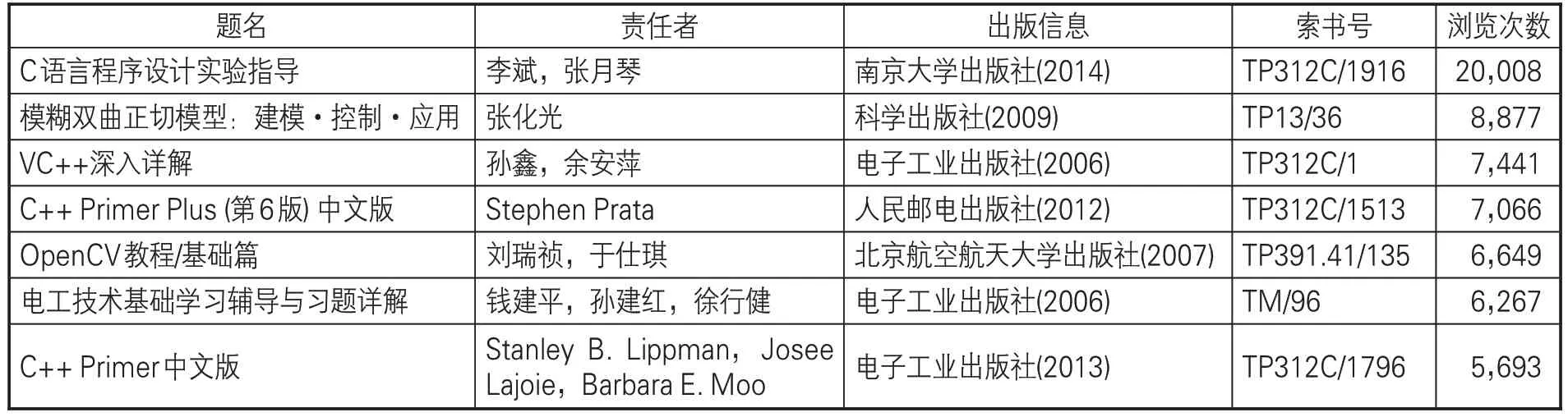
表1 部分“热门图书”信息
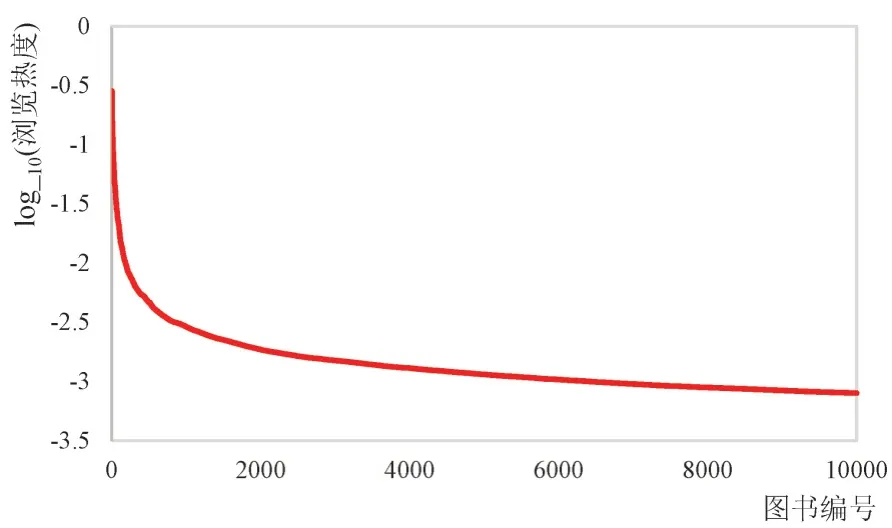
图3 图书浏览热度分布
研究榜单数据一般要估计数据分布,确保榜单中的数据具有足够的代表性。本文以高校馆热门图书排行榜中的图书及其浏览次数来刻画用户群体的阅读偏好,进行聚类分析,因此,要验证排行榜中的图书是否能代表绝大部分用户的阅读偏好。本文定义浏览热度指标来反映图书在所有高校的受欢迎程度,图书的浏览热度通过如下方式计算:(1)对每所高校的热门图书浏览次数作归一化处理,以图书浏览次数除以该高校22个排行榜中所有图书的浏览次数之和;(2)取1本书在所有高校中浏览次数经过归一化之后的值,以这些值的平均值作为该书的浏览热度。浏览热度最高的前1万本书的浏览热度取对数后的分布情况见图3。这1万本书的浏览热度取对数后服从幂率分布,少许部分图书获得了绝大部分热度。从排行榜中提取最热门的前1万本书尚且如此,可见排行榜之外图书仅能反映极少数人的阅读偏好。因此,热门图书排行榜中的图书能代表绝大部分高校用户的阅读偏好。
2.3.2 图书去重
本文以部分热门图书作为反映高校用户群体阅读偏好的特征,对103所高校进行聚类分析。首先要对不同图书进行区分,本文使用“题名+责任者”作为图书的唯一标识。通过观察采集到的热门图书数据发现:同一种图书在不同图书馆网站上的“题名”信息存在一些差异,如“毛泽东传:中文版”“毛泽东传:[中文版]”“毛泽东传-中文版”“毛泽东传.中文版”。因此,本文通过计算机程序对“题名”做如下处理:一是去除题名中的标点符号(“?”“:”“[”“]”等)和空格;二是将所有英文字母转化为小写。前面提到的4个“题名”样例都将变换为“毛泽东传中文版”。对“责任者”数据同样也做如上处理。
2.3.3 特征选择
以“题名+责任者”对图书进行去重后,需要再从中选择具有代表性的图书作为特征。聚类分析常用的特征选择方法有卡方检验(CHI)[15]、信息增益(Information Gain,IG)[16]、文档频率(Document Frequency,DF)[12]等。本研究中编写DF算法程序进行特征选择,DF值是针对文档集中的词语计算的,指文档集中包含某个词语的文档数量与文档总数量的比值。本文计算收藏某本图书的高校数量与高校总数量的比值来进行特征选择,由于高校的总数量一定,只需要比较同时收藏某本图书的高校数量(School Number,以下简称SN)即可。考虑到22 个类别各有一个“热门图书”排行榜,且观察发现不同高校的图书浏览次数在类别上的分布存在差异。笔者认为特征选择时应考虑类别因素,因此,在每个类别中,都利用DF方法提取一次图书特征,最后将22个类别各自提取的图书特征综合起来。
使用DF方法进行特征选择时,一般选取DF值适中的特征,具体做法是设定阈值过滤DF值过高和过低的特征。因为DF值过高表明该特征几乎出现在所有的样本中,不能够反映具体样本的特点。DF值越低,表明特征出现在越少的样本中,这样的特征更能够反映具体样本的特点,但DF值过低的特征数量庞大,需要进行过滤以控制最终选出的特征数量,从而避免“维数灾难”。本文提取图书作为特征时,首先在整体上(不分图书类别)对同时被N所高校收藏的图书数量分布情况进行分析。如图4所示,横轴表示收藏同一本图书的高校数量(即SN值),纵轴表示同时被N所高校收藏的图书数量,可见大部分图书只被少数高校馆收藏。
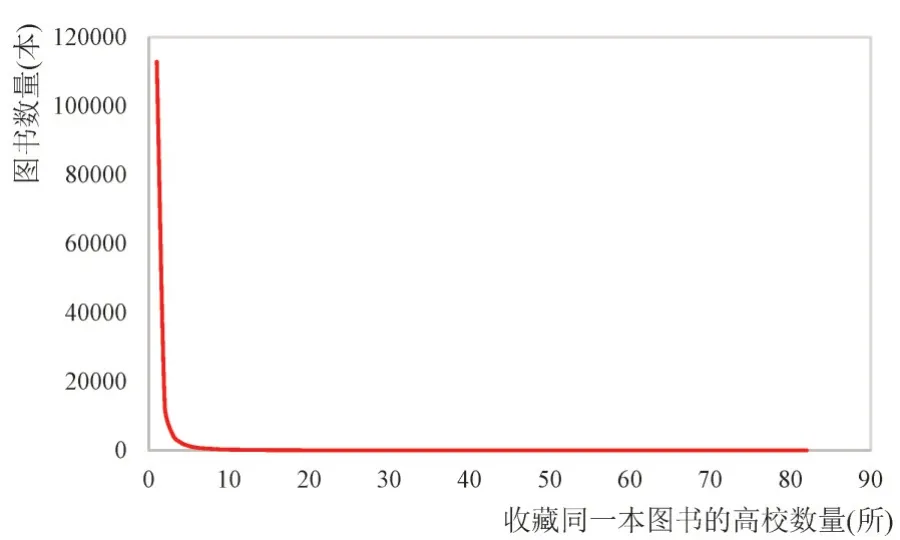
图4 同时被N所高校收藏的图书数量分布
为提取出能够反映不同高校阅读特点的图书并且避免“维数灾难”,需要过滤掉SN值过高和过低的图书。那么,如何确定过滤的阈值?为此,本文统计了低SN值对应的图书数量的占比。如表2所示,SN值小于4的图书数量占了图书总数量的94.82%(即:接近95%,在统计上具有足够的代表性),因此以4作为SN值的下限。图书被收藏的高校数量最大值(SN_max)为91,本文取SN_max的1/2(取整为46)作为上限,而SN值大于46的图书只占图书总数量0.05%。所以提取每个类别中的图书特征的做法如下:在每个类别中统计图书被收藏的高校数量,剔除SN小于4的图书,同时统计各类中SN的最大值,以最大值的1/2作为上限,剔除SN超出上限的图书。各类别提取到的特征数量如图5所示,22个类别的特征数量总和为6934。

表2 同时被较低数量高校收藏的图书数量占比
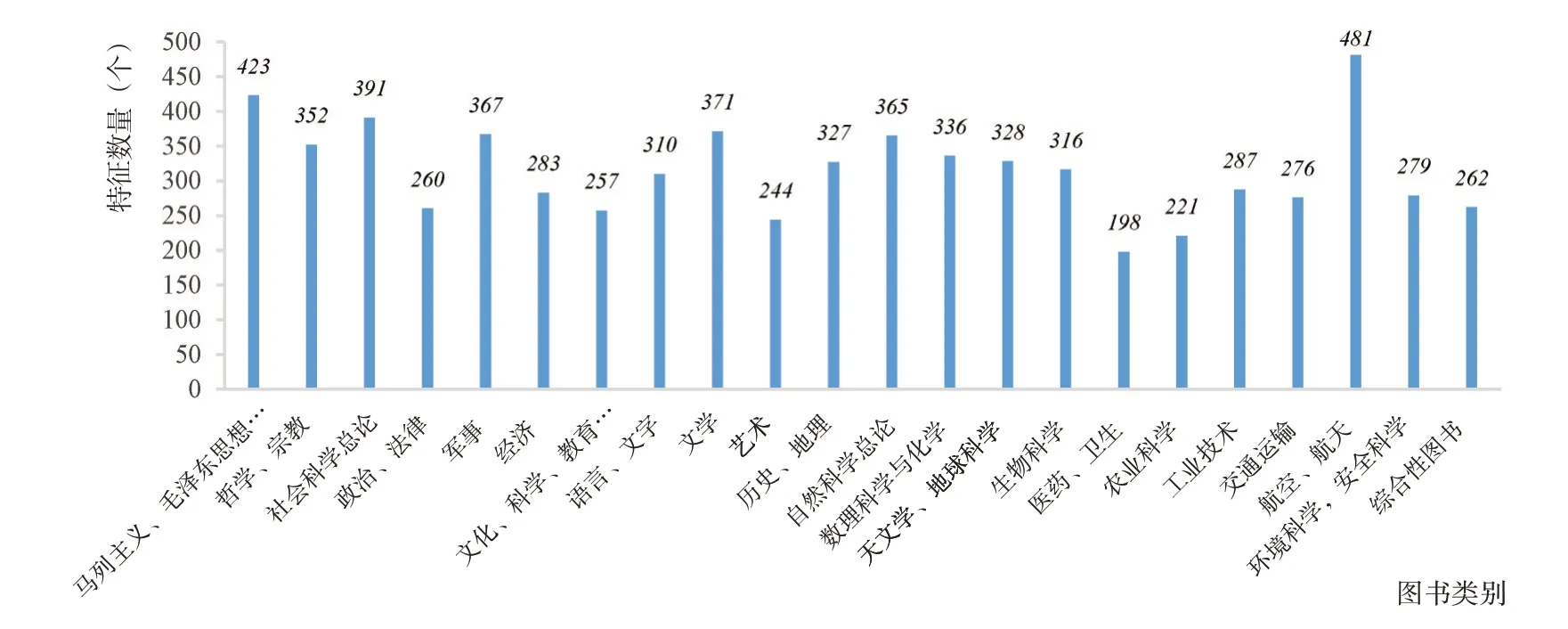
图5 图书类别及其特征数量
2.3.4 特征权重计算
在确定作为特征的图书集合后,基于TFIDF算法[13]原理,按照下面公式计算每所高校的特征权重:

TF-IDF的思想是用词频乘以词语的逆文档频率作为特征词的权重。将所有高校及其热门图书当作文档集,每一个高校即为一篇文档,高校的热门图书相当于文档中的词语。那么一所高校中,图书TF值(词频)即为图书浏览次数除以该高校的图书总浏览次数,图书的TF值体现了图书在具体高校中的受欢迎程度,TF值越高,说明该图书相对于其他图书更受欢迎。图书IDF值(逆文档频率)即为高校总数除以收藏该图书的高校数量,图书的IDF值体现了图书在所有高校中的重要程度,IDF值越高,说明图书出现在较少的高校中,更能够体现出具体高校的阅读特点。因此,本文以图书的TF值乘以IDF值作为图书的权重,综合考虑图书在具体高校中的受欢迎程度以及图书在所有高校中的重要程度。
2.3.5 AP聚类
AP聚类即为近邻传播聚类(Affinity Propagation)法[14]。AP 聚类应用了图论理念,将每个聚类样本当作图中一个节点,通过图中节点之间的信息传播来寻找聚类集合[17]。AP聚类的输入为相似度矩阵,首先需要计算样本之间的相似度,得到N*N 的相似度矩阵S(N 即样本个数)。本文计算高校之间的余弦相似度来生成相似度矩阵。假设两所高校的阅读偏好向量分别为A和B,那么它们的余弦相似度计算公式如下:
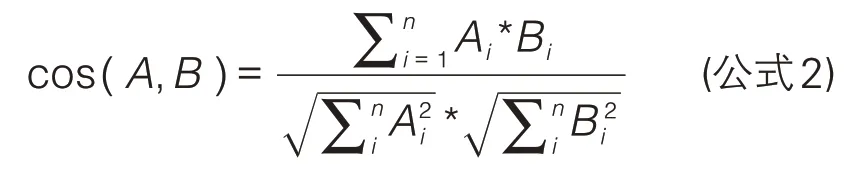
AP聚类过程中,进行两种信息传递。吸引信息(Responsibility)矩阵R:r(i,k)描述了数据对象k适合作为数据对象i的聚类中心的程度;归属信息(Availability)矩阵A:a(i,k)描述了数据对象i选择数据对象k 作为其聚类中心的适合程度[18]。Preference是AP聚类中一个重要的参数,即相似度矩阵中的S(i,i),是指点i 作为聚类中心的参考度。查阅相关文献发现,Preference的取值一般有如下几种:相似度矩阵中最小值、平均值、平均值的1/2或者2倍、中位数、中位数的1/2 或者2 倍,或者根据实际情况再做相应调整。一般来说,Preference 的取值越小,聚类的个数越少。
为得到较好的聚类结果,对Preference 参数进行调整,得到多组聚类结果。然后利用误方差和(Sum of Squares for Error,简称 SSE)[19]对不同Preference 参数下的聚类效果进行评估,SSE值越小,说明聚类效果越好。SSE计算公式如下:
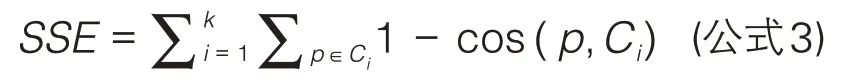
其中,k表示聚类结果的类簇个数,Ci指类簇i的质心,p表示类簇中的点。
3 实验结果与分析
3.1 AP聚类结果
为识别用户群体阅读偏好,使用AP算法对103 所高校进行聚类。调试AP 聚类中的参考度(Preference参数),当设置为前面提到的相似度矩阵的最小值、平均值、中值等数值时,得到的类簇个数比较多,很可能会使得原本属于同一类簇的高校被划分到不同的类簇中。所以本文将参考度调得更小一些,设为负值。在-1~0之间每隔0.05 取一个值作为参考度,得到了多组不同的结果。不同参考度下,计算聚类结果的SSE值如图6所示。根据SSE值越小聚类效果越好的原则,选择参考度为-0.05时的聚类结果进行分析,这时103所高校聚成13 个类簇,详细结果见表3。
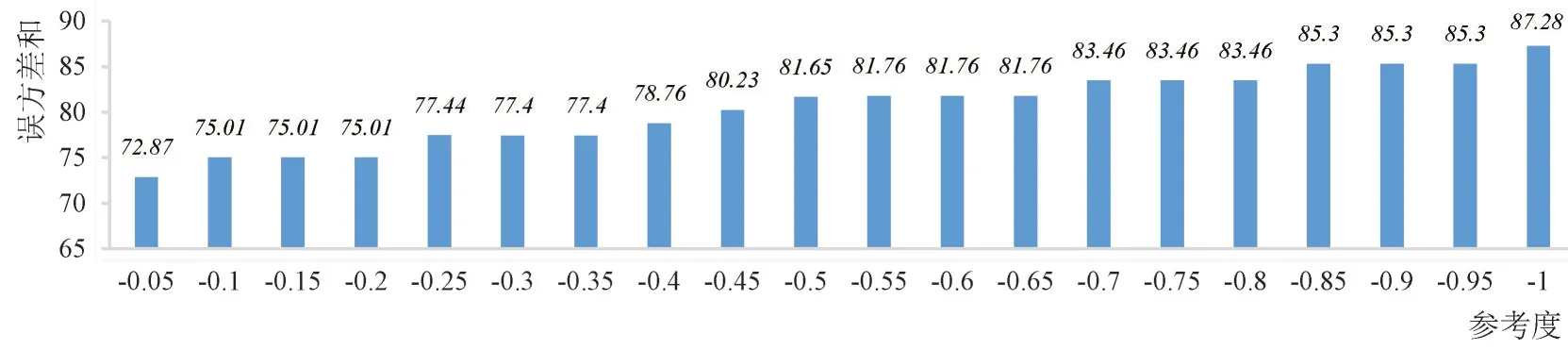
图6 不同参考度下聚类结果的误方差和
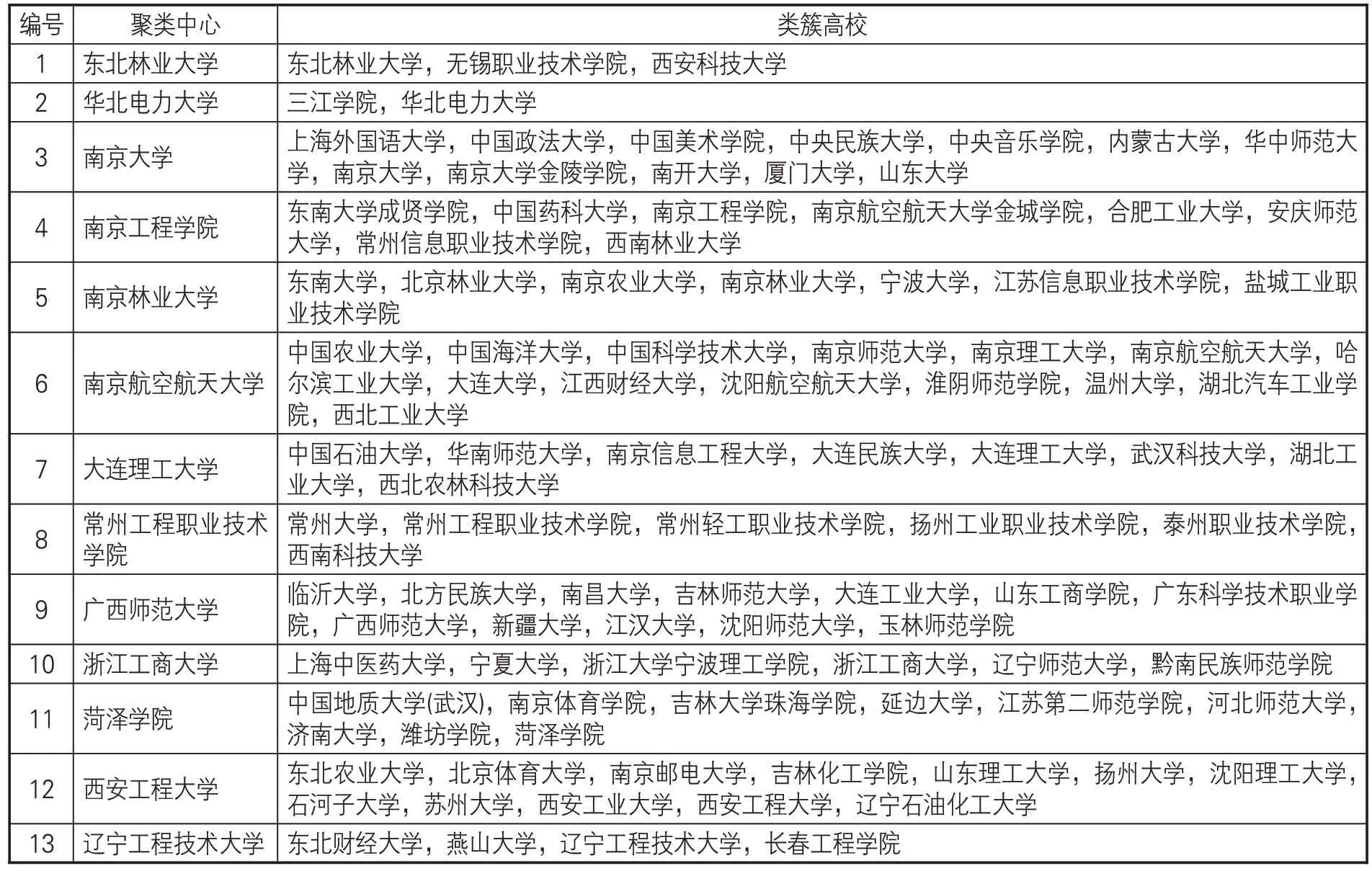
表3 AP聚类结果
表3中高校数量较少的类簇有3个:类簇1、2和13,这3个类簇的高校都不超过5所。一般来说,相似度越大的高校越容易聚在一起,同一类簇中的高校基本上都属于对方相似度最高的几所高校。计算每一所高校与其他所有高校的余弦相似度,并且按照相似度从大到小排序,部分结果见表4。可以发现与类簇1、2和13中高校最相似的1~2 所高校,相似度相比于剩下的高校有较大的差距。然而,其他10个类簇中的高校,与之最相似的前几所高校的相似度相差不大。在聚类时会优先选择相似度最大的高校聚在一起,如“三江学院”和“华北电力大学”会先聚在一起,而“西安工程大学”与“三江学院”的相似度只有0.1982,但与“东北农业大学”的相似度为0.2389,“西安工程大学”会更倾向于与“东北农业大学”聚在一起。因此,相似度最高的前1~2 所高校与剩下的高校相似度差距较大是导致类簇1、2和13中高校数量较少的主要原因。
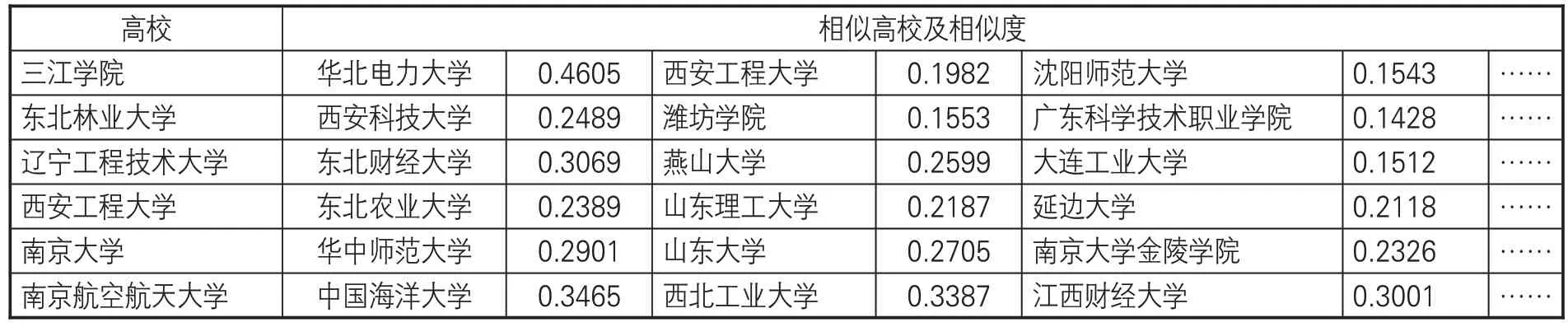
表4 部分高校的相似高校及相似度
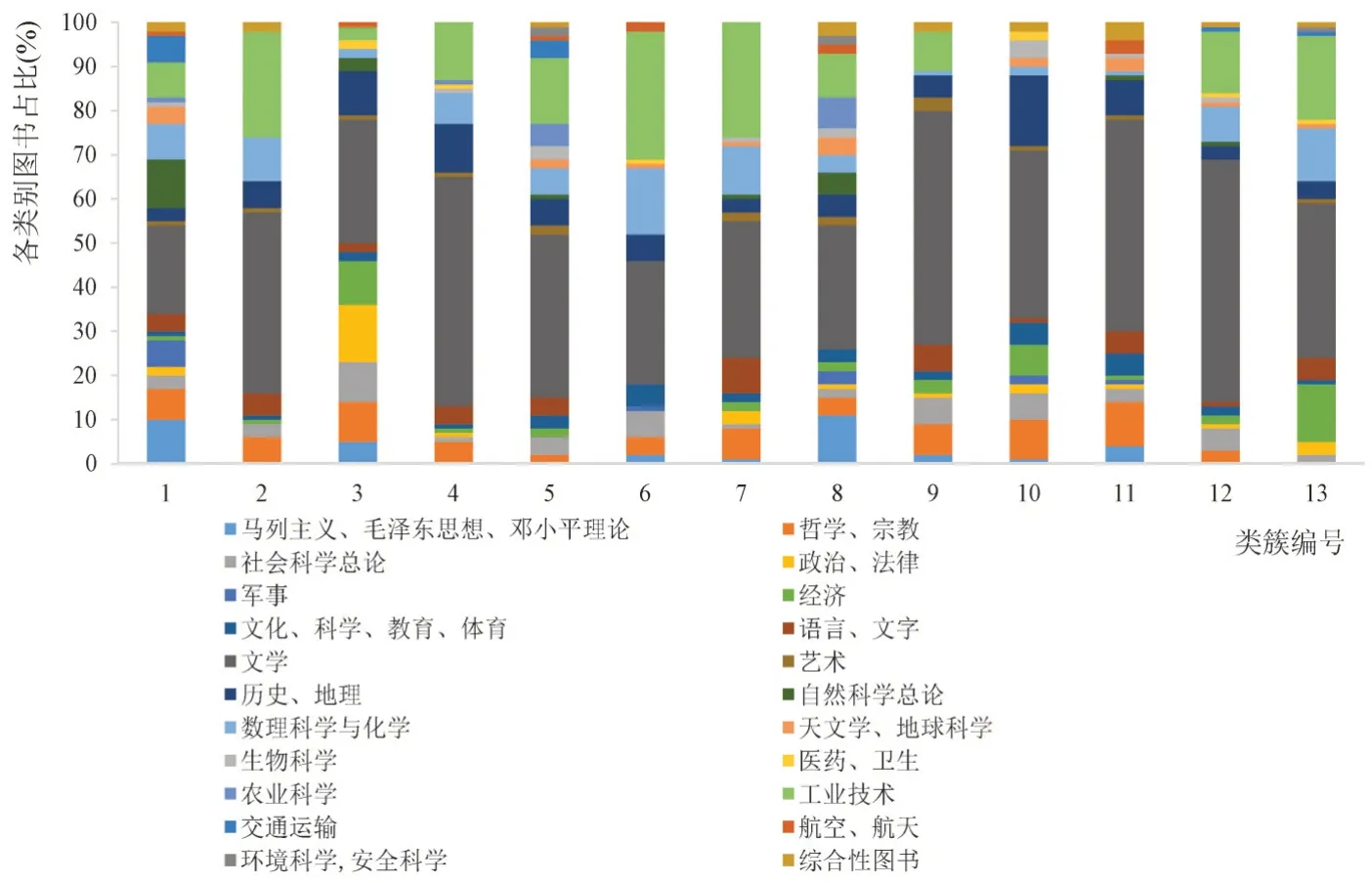
图7 各类簇高权重图书在不同类别上的分布
类簇5中北京林业大学、南京农业大学、南京林业大学等农林类高校聚在一类。类簇6中包含南京理工大学、南京航空航天大学、哈尔滨工业大学、西北工业大学,这4所高校隶属于工信部。类簇8中常州工程职业技术学院、扬州工业职业技术学院、泰州职业技术学院等职业技术学院聚在了一起。由此可见聚类效果是可靠的。
3.2 不同类簇的高校用户阅读偏好
3.2.1 图书类别分布
对于聚类得到的13个高校类簇,计算每个类簇中所有高校用户偏好向量的平均向量,然后对平均向量中的图书特征权重按照从大到小排序,得到每个类簇取权重最高的前100本图书。本文统计这100本图书在22个图书类别中的分布情况,如图7所示。各类簇中平均特征权重最高的前100种图书中,文学类书占比最多,尤其是类簇4、9、12,比重均超过50%,表明文学类图书几乎在所有高校中都很受读者欢迎。在工业技术类中,类簇2、6和7的图书数量占比明显高于其他类簇,反映出这两个类簇和其他类簇高校用户阅读偏好的差异。观察这3个类簇中的高校发现,工科类高校较多。另外,类簇3 在政治、法律这一类别中的图书占比远高于其他类簇,类簇1和8在马列主义、毛泽东思想、邓小平理论类别中的图书占比也远高于其他类簇,表明这3个类簇的用户阅读偏好与其他类簇高校存在差异。
3.2.2 题名高频词
先获取每个类簇中平均特征权重最高的前100本书,对题名进行分词、去停用词,然后统计词频。取各个类簇中前50的高频词分别生成词云,见图8。从13个类簇的图书题名高频词词云图中可以看出,“中国”和“世界”这两个词几乎在每个类簇中都属于词频最高的几个词之中。13 个类簇平均特征权重最高的前100 本书中,包含“中国”一词的图书有33种,而且这33种图书出现在不同类簇中的次数也较为平均,都不超过3次。“中国”一词在图书题名中均对图书的主题起到限定作用,如“中国近代史”“中国人的精神”“中国人的气质”。包含“世界”一词的图书有40种,有几种图书出现在不同类簇中次数较高,“平凡的世界”出现在7个类簇中,且“平凡的世界”这一书名还有几种其他形式,如“平凡的世界第2版”“平凡的世界普及本”“平凡的世界第1部”,这3种图书均出现在4个类簇中。因此,“世界”一词占有很大权重的类簇中,“平凡”一词往往也占有较大的权重,如类簇4、10、12 和13。“苏菲的世界”也出现在5 个类簇中,包含“世界”一词的图书多是文学类图书。
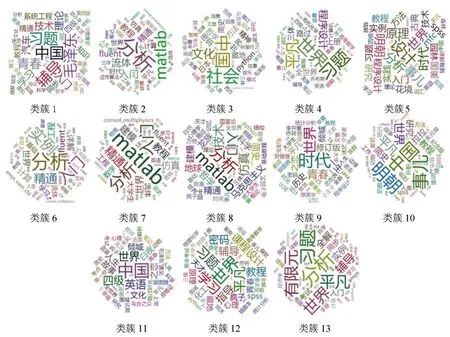
图8 各类簇图书题名高频词
类簇7和8中词频最高的3个词均为“分析”“入门”“matlab”,大体看,这两个类簇的高校用户阅读偏好十分相似。但是,除词频最高的3个词,类簇8中的“龙族”“马克思主义”“哲学”等词与类簇7 区别明显。类簇3 中的高校多为“音乐”“美术”类高校,一般来说,该类高校的主要学科为人文社科,而类簇3的高频词中包含“社会”“文化”等,这些词语也代表了人文社科领域的主要研究话题。
3.2.3 图书高频学科主题词分析
获取每个类簇中平均特征权重最高的前100本书,然后从高校馆网站上采集这些图书的学科主题词数据,并统计学科主题词的词频。取各个类簇中前50 的高频词分别生成词云,如图9 所示。与图书题名高频词的情况类似,有几个学科主题词几乎在每个类簇中频次都很高,它们是“中国”“长篇小说”“当代”“现代”,包含这几个学科主题词的图书多为小说或其他体裁的文学作品,说明文学类图书最受欢迎,与图书类别分布中的结论一致。有几个类簇学科主题词相比于其他类簇表现出一些差异,如类簇1中的“普及读物”和“高等学校”的频次也比较高,但在其他类簇中的频次却相对较低。类簇6中“应用软件”的频次最高,甚至超过了“中国”,包含学科主题词“应用软件”的图书多是各种应用软件的使用介绍,类簇6中的学校以理工科高校,而这些学校的师生在学习和科研中经常需要使用各类应用软件。

图9 各类簇图书高频学科主题词
3.3 对图书馆工作的参考价值
本研究对于图书馆工作有着重要的参考价值。图书馆在进行图书推广时,一般是选择本校浏览次数较高的一些图书或者网络热门图书生成推荐列表,然后向读者宣传。本研究可以生成有别于传统的图书推荐列表为图书推广提供更多的选择,本研究中获取了不少高校的热门图书浏览数据,可以统计图书在这些高校中的浏览次数,从而生成基于大量高校读者阅读偏好的图书推荐列表。除此之外,对于具体高校,可以统计与其同类簇中高校的图书浏览次数,生成图书推荐列表,同类簇中的高校用户具有相似的阅读偏好,这样的推荐列表具有较为重要的价值。
另外,高校图书馆进行资源建设工作时可以参考在大量高校中都热门的图书,如果本高校图书馆的馆藏中还没有其中的一些图书,就可以及时采购。本研究生成了一些具有相似阅读偏好的高校类簇,类簇中的高校需要采购图书时,还可以参考同类簇中其他高校的热门图书。以南京理工大学为例,其图书馆网站上公布了热门图书排行榜,采集到前10本图书的题名数据信息分别是:c语言程序设计实验指导、苏菲的世界、狼图腾、平凡的世界1、追风筝的人、平凡的世界第2版、平凡的世界第一部、明朝那些事儿朱元璋卷、c++ primer plus第6版中文版、围城第2版。与其同类簇的高校有13所,这13所高校最热门的10本图书的题名数据信息分别是:深度学习入门之pytorch、c++ primer第3版、消失的航班、平凡的世界、狼图腾、strategic management、追风筝的人、高质量程序设计指南:c++/c语言第3版、挪威的森林、外国经济与管理。可以看到,同类簇高校的热门图书的题名数据信息与南京理工大学有所不同,在扩充馆藏资源时就可以考虑这些不同的图书。
4 总结与展望
本文基于用户群体的阅读偏好,对中国103所高校进行聚类分析。AP聚类结果显示这些高校被聚成了13个类簇,进而对各类簇中的高平均特征权重的图书类别分布、图书题名高频词以及图书高频学科主题词进行了分析,发现这些类簇的图书类别分布大体上比较相似,文学类图书在各类中均占了较大的比重,但在工业技术等几个类别的图书占比上,有些类簇与其他类簇存在非常明显的差异。而图书题名的高频词也反映了文学类图书占有很大比例这一情况,同时也体现了部分类簇中高校的阅读偏好特点,且不同类簇的高频词存在差异。图书高频学科主题词和题名高频词的情况相似。由此可见,部分类簇之间的用户群体阅读偏好在图书类别分布、图书题名高频词及图书高频学科主题词上存在明显差异。
本文为用户群体阅读偏好研究提供了一种新的思路,并且本研究有助于高校图书馆了解用户群体的阅读偏好,发现与本校具有相似群体阅读偏好的高校,对于图书馆的图书推广和资源建设工作具有重要的参考价值。此外,同一类簇的高校图书馆也可展开合作,为用户提供馆际互借服务。当然,本研究还存在一定的局限性,比如受限于数据获取的途径,本文选择的高校在代表性上有所欠缺。未来工作可以扩展高校相关数据,收集这些高校更为详细的其他信息,探索聚类结果生成的原因,从而更加深刻地理解不同类簇高校图书馆用户群体阅读偏好的差异。
猜你喜欢
小康(2022年7期)2022-03-10
小康(2022年7期)2022-03-10
西江月(2021年2期)2021-11-24
小康(2021年7期)2021-03-15
小康(2021年7期)2021-03-15
中国介入影像与治疗学(2019年1期)2019-01-06
中国介入影像与治疗学(2019年8期)2019-01-06
海外星云(2016年7期)2016-12-01
中华奇石(2015年7期)2015-07-09
大众创业(2009年10期)2009-10-08
