
命名实体识别在数字人文中的应用
——基于ETL的实现*
2020-05-12 07:51朱武信夏翠娟
图书馆论坛 2020年5期
朱武信,夏翠娟
0 引言
命名实体识别NER(Named Entity Recognition)是自然语言处理NLP(Natural Language Processing)组成部分,是指从文本中提取出命名实体,而命名实体是指人名、地名、时间等信息。图书馆用NER进行数据挖掘,从摘要、正文提取大量的命名实体,为构建知识图谱、支持数字人文研究和服务打下了基础。学界在命名实体应用方面做了很多研究,提出了规则提取、关系提取、正则提取、神经网络、机器学习等方法。
上海图书馆(以下简称“上图”)有大量数字化馆藏资源,其挖掘离不开NER技术的推动。上图在构建数字人文平台初期,便使用了各种工具与方法进行数据加工,包括OpenRefine、基于Python的正则提取等,解决了一些问题,但也存在不足:一是识别效率低、人工成本高;二是识别的内容仅仅是文本,后续若要和其他数据进行关联,还需投入更多人力、物力和时间。为解决上述问题,本研究研发基于数字人文与汉语言处理包HANLP(Han Language Processing)技术的命名实体识别工具。HANLP是一个在github平台上开放的NLP开源工具包,开发语言是JAVA,提供中文分词、词性标注、命名实体识别、依存句法分析等功能。本研究主要采用隐马尔夫(HMM)模型进行分词模型训练、最短路分词和依存句法分析中基于神经网络的高性能依存句法分析器。
命名实体识别工具的词典源于上图的数字人文知识库。选用之有3个原因:(1)NER要提取的实体信息与数字人文所定义的人名、地名、时间、事件不谋而合。(2)2014年以来,上图通过本体建模方法搭建了多个数字人文平台与知识库,有大量的数据基础。上图数字人文平台在功能上分为两类:一类是家谱知识服务平台、盛宣怀档案知识库等以提供文献服务为主的文献知识库;另一类是人名、地名、时间、事件为一体的基础知识库。本研究选择作为词典的知识库指的是上图数字人文基础知识库。(3)上图的数据是关联数据,具有语义性,将其作为词典,则命名实体识别的结果也具有关联数据的特性,可以通过本体获取更多相关信息。
本研究结合数字人文与NER,研发基于关联数据的命名实体识别工具,并对文本进行数据挖掘,提取相关人名、地名等实体信息,优化上图ETL流程。
1 现状调研
关联数据概念于2006年由蒂姆·伯纳斯-李提出[1],其时互联网上已发布大量数据集。国内外大学、图书馆通过数字人文构建了知识库与知识图谱,比较著名的有哈佛大学中国历代人物传记资料库(CBDB)、基于维基百科的DBpedia、OCLC的虚拟国际规范档、复旦大学中国历史地理信息(CHGIS)系统、上海图书馆数字人文开放平台等。上图在数字人文领域的探索取得较多成果,比如构建家谱知识服务平台,提供人物、地名、时间相关的基础知识平台。2017 年上图搭建人名规范知识库,运用关联数据技术发布了近130 万人名实体;地名基础数据包含1,800余个县与县级以上的地名;2019年发布上海地名志信息,包括2,264条马路三元组。目前这些实体已经对外开放服务。
命名实体识别技术在数字人文中的应用,国外起步较早,2011年研发了名为DBpedia Spotlight的 NER 工具。Palo 基于 DBpedia Spotlight 工具,通过质量测量方法与DBpedia本体进行文本自动标注[2],验证了利用实体进行命名实体识别的可行性,该工具在互联网上开放给大众使用。Ferragina等发布基于TagMe算法,以维基百科实体为基础,实现快速标注文本短语的工具,标注结果信息丰富且与维基百科信息互相关联[3],但所用知识库仅支持英语。Usbeck 等提出将AGDISTIS 方法用于命名实体识别,以标签与HITS 算法进行提取[4]。Speck等研发FOX 工具,通过实体关联技术与EL 算法,实现文本转换,提取出RDF(Resource Descripition Framework)数据,F值(F-Measure)达95.23%[5]。张海楠、Lample 等提出运用神经网络来解决NER 问题,通过非监督学习进行识别,以降低人工成本[6-7],此方法虽然识别度高,但提取的文本仅是字符串,缺少语义性与关联性。
上述命名实体识别工具虽然识别效果较好,具有借鉴作用,但无法满足上图所需场景:一是上述工具的词典与上图需要加工的历史人文数据不匹配;二是识别工具要根据人名、地名、时间、事件、自定义标签等进行识别;三是识别结果应是关联数据,与上图已有关联数据形成关联。
2 命名实体识别工具需求与设计
2.1 命名实体识别系统需求
上图在众多基础知识库与服务平台的建设实施过程中,通过OpenRefine工具与人工处理的方法,对大量文本进行数据加工与实体提取,取得了一定成果,但需要耗费大量人力、时间,尤其是在处理新数据时,人名、地名实体重复出现,需要再次加工。为优化数据处理流程,降低成本,加快数据处理速度,快速将识别结果转为关联数据,本研究基于上图基础语义知识库,在ETL加工环节增加命名实体识别功能。其主要特征有:对中文文本进行实体识别,命名实体识别词典基于上图数字人文基础知识库;识别实体与上图数字人文知识库的关联数据实现关联;可识别不同类别的实体,包括人名、地名、机构、姓氏等,可自定义新的分类。

图1 命名实体识别系统架构图
2.2 系统架构设计
本研究开发的命名实体识别系统以上图已有关联数据作为识别词典,通过命名实体识别算法对文本中的内容进行识别,识别结果与上图关联数据进行对应。系统架构见图1。
(1)输入层。输入层以需识别的文本为输入参数,通常是文献中的摘要、正文信息。在输入层对识别内容的标签进行预选择,如人名、地名、姓氏,以此根据不同需求进行特定内容的识别。
(2)识别层。识别层是命名实体识别的核心模块,通过关联技术的本体模块与命名实体识别算法模块的结合,实现对输入文本的识别。由于识别结果是关联数据,一定程度上解决部分命名实体识别工具识别结果仅是字符串的问题,具有关系发现的特性。由于是在上图已知数据源中识别,精准的识别对命名实体消歧起到了改善作用。
(3)输出层。输出层包括识别结果的展示与下载。当识别完成后,会展示文本的识别结果,展示结果添加了关联数据的URI。通过URI,此文本与上图的数据形成关联,可通过上图API接口获取更多的内容信息。
2.3 识别词典设计
本研究使用的识别词典主要来自上图,包括人名规范库、地理名词表、上海历史文化年谱,3个知识库分别对应数据中的人名、地名、事件。使用上图知识库的主要原因包括:(1)上图知识库数据采用语义网RDF框架,通过三元组形式构建本体。正因为以本体作为词典进行识别,识别结果也是本体。(2)上图人名规范库的人名本体有130万个,来源于上图馆藏。因为上图搭建了大数据级别的人名关联数据,所以能作为命名实体识别的词典。(3)上图知识库是开放的,提供通用API接口,支持JSON、XML等格式,调用方便,兼容性好。关联数据的特征是每个本体都有一个URI标示,数据以三元组形式进行描述。将本体作为识别词典,当识别的实体与本体形成关联,则能通过关联数据的本体结构,获取文本之外的信息。例如,识别出一个人名实体,通过关联数据就可以获取此人的籍贯、朝代、年龄等信息。通过关联获取的信息,一方面丰富了识别内容,另一方面也为识别结果的消歧提供了依据。
2.4 命名实体识别功能设计
本研究命名实体识别流程见图2。下文结合样例对上述过程进行说明。
(1)定义词典。识别前,首先引入2部词典作为语料:1998 年的人民日报语料库和上图关联数据词典。上图关联数据词典包含人名、机构、姓氏3部分,其中人名词典收录近130万个人名、607个姓氏、42个机构。
(2)中文分词。中文分词通过HANLP提供的基于隐马尔可夫模型的HMM-Bigram模型对输入文本进行分词。使用HANLP 的主要原因是,其对命名实体识别、机器学习算法进行封装,使用便捷。例如,“长江剧场位于黄河路35号,原名卡尔登大戏院”这段话,通过分词得到的结果是“长江剧场/名词……卡尔登大戏院/名词”。
(3)句法分析。句法分析使用HANLP提供的基于神经网络的高性能依存句法分析器,依存句法分析是对文本的内容进行关系标注。语文关系有15种,包括主谓关系、动宾关系、间宾关系等。引入句法分析主要是为了进行过滤操作。例如,“长江剧场位于黄河路35号”在未引入词典的情况下,通过中文分词会提取到“长江,剧场”,通过依存句法分析可知,“长江”与“剧场”是定中关系,排除了“长江”这个识别结果。
(4)结果处理。结果处理包含结果过滤与数据关联。结果过滤主要是将中文分词的结果与句法分析的结果进行过滤,进一步提高实体结果准确性。数据关联是将识别的结果与上图本体一一匹配与关联,可通过上图API接口获取更多相关信息[8]。

图2 命名实体识别流程图

图3 关联数据词典转换实现图

图4 命名实体识别伪代码
3 命名实体识别工具的实现
3.1 命名实体识别的实现
(1)关联数据词典转换实现。关联数据词典转换方法的实现见图3。图3以人名为例,首先从RDF数据中提取人名的名称与URI,将其按词典的要求进行转换,再通过HANLP提供的自定义词典方法将命名实体添加到词典。提取人名的作用是使其成为词典的语料,URI的作用是保留关联数据的关联性,最终的识别结果可以通过URI来获取关联数据的其他信息。
(2)命名实体识别实现。其伪代码见图4。以文本A的输入为例,先加载关联数据词典,通过词典识别方法对输入文本进行命名实体识别,得到基于词典的命名实体识别结果B;再通过依存句法分析文本A获得结果C,结果C主要记录的是定中名词与状中名词,以此在结果B中排除状中名词与定中名词,最终生成的就是经命名实体识别得到的实体。
3.2 NER工具效果
图5展示的是基于年华人名词典的NER识别结果。该词典包含出身年月介于1840-1950年的7万多个名人。选用年华人名词典的主要原因是其时间与输入事件的时间吻合,通过此词典可提高结果的准确率与召回率。图5中,以橙色标注的是识别出的实体,其中数字代表识别对应的个数,通过单击实体,可以跳转到上图人名规范库的对应实体,从而获取此实体更详细的信息。

图5 实体识别功能展示图
3.3 实体识别工具效果对比
对上图命名实体识别工具(简称“上图识别工具”)、人工方法、BosonNLP工具的处理结果进行比较,共用10组数据。综合来看,上图识别工具在降低少量准确率的前提下,可以对文本进行快速处理,这是人工方法无法比拟的。上图识别工具识别的结果是关联数据,其丰富性、关联性、可挖掘性远胜于人工与BosonNLP所识别的结果。三者的识别效果见表1。
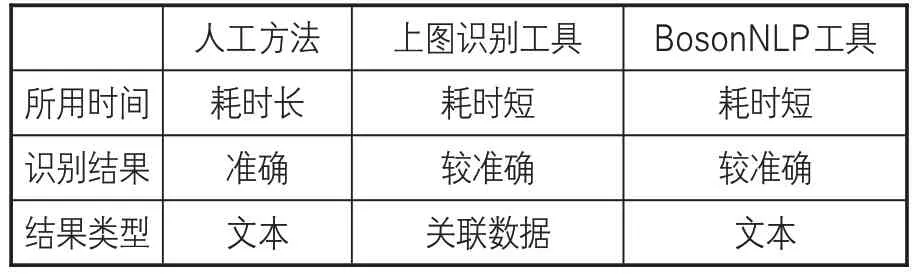
表1 实体识别效果对比
4 结论及展望
上图研发的命名实体识别工具在ETL数据处理过程中起到了很大作用,弥补了上图没有命名实体识别的短板,主要特色包括:(1)实现了基于数字人文词典的命名实体识别,识别的实体不再是简单的字符串,而是关联数据。关联技术与命名实体识别技术形成互补,使命名实体识别可以在更多文本中挖掘关联数据,提升了识别结果的质量。(2)命名实体识别加强了ETL功能,数据处理效果得到改善。在大量文本中,通过NER工具可以快速识别其中的实体,在其识别的基础上加入部分人工,可以更高效率地获得高质量数据。
本研究的命名实体识别工具也有需要改进的地方:(1)基于已知数据进行挖掘,把不在词典中的命名实体过滤了,在今后的功能设计中应引入新的工作流来处理这些被过滤的命名实体。这样既能对这些命名实体进行发现,又能将其转换成关联数据。(2)中文词性分析上有欠缺,文本挖掘中实体的词性分析还需要重新梳理,缩小范围,以提高实体识别的准确度。
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
科技视界(2014年27期)2014-08-15
中关村(2014年5期)2014-05-15
中国科技术语(2012年5期)2012-03-20
