
中概股的新闻极性市场预测研究
2020-05-12 09:09:44王万良
小型微型计算机系统 2020年3期
赵 澄,童 川,王万良
(浙江工业大学 计算机科学与技术学院,杭州 310023)
E-mail:zjutwwl@zjut.edu.cn
1 引 言
股票市场的预测可以帮助投资者进行投资决策,提供关于股票市场行为的深刻见解以规避投资风险.然而,股市预测并不是一件易事,因为其数据的性质是可变的、非线性的、不稳定的、接近随机游走的[1];金融新闻对股票市场有很大影响,投资者经常依赖金融新闻信息决定买卖,根据可获得的信息做出投资决策[2].上市公司重大资产重组是调整业务、实现战略目标的重要途径,对其价值影响颇大,该类新闻一般都会引起股价的波动[3],这使新闻报道成为金融预测的重要数据来源[4].如果新闻是积极的,股价上涨的可能性就更大;反之,股价可能会下跌[5].
金融新闻属于非结构化数据,获取途径多,但结构不规则或不完整,没有预定义的数据模型,格式多样化,比结构化数据更难标准化及使用.而通过研究金融新闻对股市的影响可以为投资者提供一个新的角度,提前洞察股价波动,规避不必要的风险,起到决策辅助的作用.
中概股即中国概念股,是指在国外上市的国内注册公司,或虽在国外注册但业务和关系均在大陆的公司股票.国内外上市机制存在着明显差异,中国资本市场对于流程时间、信息披露要求以及企业、风险管控上更加严格,导致越来越多的国内企业在国外上市.本文研究中概股的原因主要有3点:1)中概股在国外上市,但属于中国企业,业务主要集中在国内,国外相关的外语新闻较为稀缺,相反,中文新闻则较为丰富;2)包括中概股在内的传统股票市场,对企业新闻都比较敏感;3)中文自然语言处理(Natural Language Processing,NLP)由于其特殊性,在分词任务中,会碰到交叉歧义和组合歧义两种歧义现象,虽然信息获取较其他语言有更大困难,但所含的信息量巨大,值得研究与应用.
本文研究的主要内容是最具代表性的在美上市中概股价与相关新闻之间的联系,通过NLP技术分析新闻极性,使用Support Vector Machine(SVM)模型预测新闻对股价的影响,为股市操作者提供参考意见.
2 相关工作
华尔街“德温特资本市场”公司通过判断全球3.4亿微博账户留言的情绪决定股票买、卖,于2012年第一季度获得7%的收益率[6].Bing等[7]利用数据挖掘技术研究NLP提取的推特数据中的公众情绪与真实股价走势的关系.Martin等[8]利用对法语推文的情绪分析和主体性分析的结果训练一个简单的神经网络预测了法国CAC40指数的收盘价.黄润鹏等[9]通过格兰杰因果关系检验上证指数时间序列与情绪倾向时间序列间的关系,建立SVM模型预测股票市场价格的变化来验证假设的正确性.杨晓兰等[10]利用计算机文本挖掘技术定量描述投资者基于博客进行社会互动的程度和情绪倾向,检验社会互动对股票市场的影响.Khatri等[11]对推特和股票推特中提取的数据进行情感分析,通过数据分析出用户评论的语气来预测股市投资.
现有成果虽然通过对相关社交媒体发布的文本数据进行情感分析来预测股市价格变化,但所用数据中存在一定数量受心理影响产生的主观情感误差数据,不能准确反映事实.然而,对于股票预测最重要的影响因素是数据的时效性与真实性,新闻是众多信息媒介发布数据中时效性与真实性兼优的文本数据,能够即时反映股票相关联公司的真实动态变化.因此,通过对新闻的极性进行分析,可以更加及时且准确地预测股价变动趋势.
Hagenau等[2]利用SVM和朴素贝叶斯、ANN将消息对市场价格的影响分为正、负面,研究表明SVM在文本挖掘的表现更好.Kalyani等[12]创建了随机森林(RF)、SVM和朴素贝叶斯三个分类模型来研究新闻与股票走势关系,结果表明RF和SVM在所有类型的测试中表现良好.Kirange等[13]使用朴素贝叶斯、kNN和SVM分类器将股票新闻分为适当的类别,将结果与人工标注进行比较,实验显示SVM准确率高于其他两者.Ou等[14]使用总共10种数据挖掘技术来预测香港股市恒生指数的价格走势,实验表明SVM和LS-SVM比其他模型均具有较好的预测性能.Heo等[15]发现利用SVM的财务信息输入进行股价的可预测性优于专家预测.
由于SVM在金融市场预测中具有广泛的适用性,结合文献综合考虑,本文选择SVM作为预测模型的基础.但上述SVM模型存在一些不足之处:1)训练过程都不经历迭代操作,属于“一次线性模型”,存在过拟合的风险;2)在特征提取时没有突出重要特征的作用;3)没有综合考虑高维输入参数和噪声数据对模型的影响.针对这些问题,在传统SVM基础上分别进行改进:1)针对金融新闻数据复杂多样的特点,通过随机分配语料并循环进行训练,降低其“一次线性模型”存在的过拟合风险;2)以降维特征作为输入,降低噪音特征对研究结果的影响;3)通过对比不同类型的核函数以及数量不等的特征空间对模型进行调参.
本文主要贡献包括:1)通过分析对股价变动有显著影响的短语权重来提高中文NLP的分析性能;2)提出了一种将金融新闻和股票波动结合的标签模型,在保证正确率的前提下降低人工标注的经济与时间成本;3)提出一种新的CE-SVM模型,综合优化SVM的预测性能,提高股价趋势预测的准确率.
3 解决方案
本文提出的解决方案整体流程如图1所示.
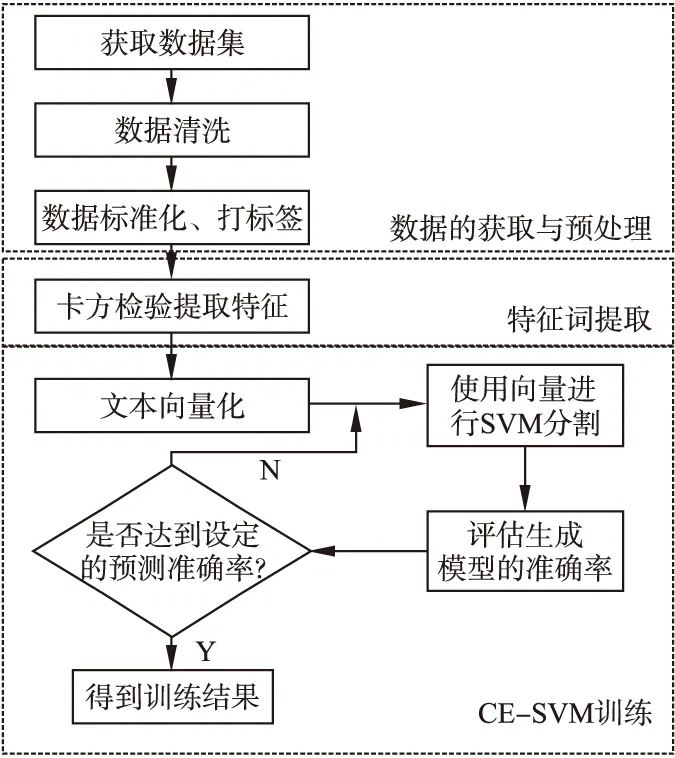
图1 方案整体流程图
3.1 数据的获取与预处理
本文研究需要获取股票交易数据和中概股相关的金融新闻数据.其中,文本数据预处理具体包括:
1)金融新闻数据的清洗.虽然在获取金融新闻数据时使用了关键词匹配机制,但中概股在新闻中经常被用来与其他同行比较,因此语料中存在部分相关性较低的新闻,即噪声.利用正则表达式将数据分段,统计与其相关的关键词,若关键词数少于所设阈值,则判断为相关性低的冗余数据并去除.
2)金融新闻的极性标记.可将新闻划分为两类,即积极与消极.Dang等[16]指出在文档标签上有两种不同的方法.第一种是根据专家意见手动为每一篇文章分配一个类,尽管准确率很高,但数据集中包含大量文章,人力成本较高、工作周期较长;第二种是根据文章对股市的影响来自动标注,但不如第一种准确.
考虑到股票市场大环境以及不同中概股之间的相互影响,本文自定义了中概股指数使标签标准化,并设计了全自动机器打标签模型,将金融新闻和股票波动相结合.中概股指数指的是中概股股票平均股价变动率(上涨为正,下降为负),具体计算详见公式(1),模型如图2所示.通过公示(2)的逻辑关系,根据文章对股市的影响来自动标注可以实现基本的标记功能,且节省了人力与时间.默认交易日当天报道的新闻会即时影响到当天股价的变动,同时考虑到非交易日报道新闻的影响力,将非交易日的新闻合并至下一交易周期的第一个交易日的新闻数据集中.结合交易日当天金融股票交易数据中的开盘与收盘价格的变化进行打标签操作.将股票交易数据与金融新闻数据同时输入全自动机器打标签模型中,经过模型处理后输出完成打标签操作后的语料,其结构组成为“极性标签+新闻标题+新闻内容”.

图2 标签流程图
(1)
(2)
式中:β为中概股指数,αi为第i只中概股的股价变动率,n为中概股股票总数,li为与第i只中概股相关新闻的极性标签.
3.2 特征词提取
如果将金融新闻全文本输入,由于数据量巨大、信息多样化,将出现处理时间过长、分类效果不理想的现象.因此,需要对非结构化数据进行特征提取,提取与股价变动较为相关的关键特征词.Chiong等[17]提出在预处理阶段进行情绪分析,从金融新闻中提取与情绪相关的特征,能够显著降低特征维度,提高预测模型性能.
表1 类别与词条四格表
Table 1 Category and entry four-table

属于类别c不属于类别c总计包含词条tABA+B不包含词条tCDC+D总计A+CB+DN=A+B+C+D
特征提取的代表方法有TF-IDF和卡方检验等.前者单纯以“词频”衡量一个词的重要性,没有考虑特征词在类间的分布以及在类内部文档中的分布,不能全面提取与金融新闻极性相关的特征,而卡方检验做了综合考虑,所以本文选择卡方检验作为特征提取的方法.
如表1所示,将四格表运用于金融新闻语料,假设类别c为积极类,词条t为“收购”,N为训练集文本总数,那么,A为属于积极类且包含词条“收购”的文本数,B为不属于积极类且包含词条“收购”的文本数,C为属于积极类且不包含词条“收购”的文本数,D为不属于积极类且不包含词条“收购”的文本数.
(3)
卡方检验的思想是通过观察值和理论值之间的偏差来判断理论值的正确率是多少.它是以χ2分布为基础的一种常用假设检验方法,通常使用四格表方法进行特征提取.通过计算χ2分布的结果进行排序,结果越大则关联性越强.四格表是研究两个定性变量相关性的有力工具,在四格表中的卡方检验公式可以变换为公式(3).
如果给定一个文档集合和类别,则N,M和N-M(即A+B+C+D,A+C和B+D)对同一类别文档中的所有词来说是一样的,而本文只关心一堆词对某个类别开方值的大小顺序,并不关心具体值,因此把它们从公式(3)中去掉是完全可以的,实际计算时都使用公式(4).
(4)
在一般情况下,新闻中的“动词+名词”与“名词+动词”的出现对于股价的变动影响较大,例如:“抛售股票”、“大额资金买入”等.由此,首先将新闻语料进行中文分词处理,采用精确模式分词将文本拆分开;增加新闻中“动词+名词”和“名词+动词”短语组合的权重,使得与股价相关词组的卡方检验关联性计算结果更为有效,提高特征提取的精确性.通过设置卡方阈值与词个数阈值,即可在卡方检验运算结果中返回一系列特征词,将全部特征词合并,就构建出了本文的文本词典.
3.3 CE-SVM分类
SVM算法旨在学习一种决策函数,将具有不同类标签的实例划分为不同的类.基本模型定义为特征空间上的间隔最大的线性分类器,最终可转化为一个凸二次规划求解问题(Quadratic Programming,QP)[18].它可以表示原始空间中的线性或非线性决策边界.线性决策边界函数定义为公式(5):
w·φ(x)+b=0
(5)
式中,x为低维特征空间矩阵,φ(x)为映射函数,w为超平面的法向量,b为截距(实数).
在新的特征空间中,不同类之间的最佳分区超平面称为最大边缘超平面,可通过求解公式(6)得到.

(6)
式中,yi为低维特征空间中第i个点(xi,yi)的纵坐标,n为特征空间中点的个数.
实质上,通过构造拉格朗日函数,上述优化问题可以表述为一个双重问题:
(7)
式中,Lp为拉格朗日函数,λi为第i个拉格朗日乘子.
在线性不可分的情况下,SVM首先在低维空间中完成计算,通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上不可分的非线性数据分开.
通过定义为K(x,z)的核函数求解(7),则决策函数f(x)获得如下:
(8)
通过使用卡方检验提取的特征词集合为每一篇新闻建立向量表示模型,达到文本向量化的目的,从而得到语料向量集合.传统SVM系统在实现过程中,由于一次结果即可得到SVM最优分类超平面,可能会出现过拟合的情况.因此,在传统SVM实现机制上进行改进,提出了CE-SVM模型,系统实现如图3所示.
将SVM模型训练与评估操作嵌入模型预期预测准确率已设定的循环中,使用交叉验证思想,重复地使用数据,把得到的样本内数据进行切分,在此基础上可以得到多组不同的训练集和验证集.通过引入随机数种子作为参数,将语料向量集合随机划分为训练集和验证集,其中,训练集占语料向量集合总数的80%,验证集占语料向量集合总数的20%.

图3 CE-SVM模型系统实现图
重复实验时,在其他参数不变的情况下,设置不同的随机数种子以确保得到不一样的随机序列,避免伪随机数序列的产生,增加实验训练与验证集组合的多样性.在不断训练与评估的过程中寻找预测准确率达到设定要求的模型.经过实践可得,预期预测准确率设定为0.65时得到的结果较为合理.通过调用SVM模型评估函数,获取当前模型的精确率(precision)、召回率(recall)、f1值(f1-score)等信息,并计算准确度(accuracy).
4 参数优化
通过调整特征空间数与不同的核函数两个超参,一方面确认模型的泛化性能,另一方面优化模型,提高预测的准确率.其中,特征空间指的是所有特征向量存在的空间;核函数的作用是隐含着一个从低维空间到高维空间的映射,而该映射可以把低维空间中线性不可分的两类点变成线性可分.
4.1 特征空间数的确定
对于分类器来说,特征空间数越多准确率不一定越高.通过不同空间数对CE-SVM预测准确率的对比实验,得到特征空间数与CE-SVM预测准确率的关系.如图4所示,随着特征空间数的增加,CE-SVM预测准确率先升高后降低,在800左右达到最高.因此选择自由度为1的四格表法,提取数量为800的特征词集合.

图4 特征空间数对CE-SVM准确率的影响
4.2 核函数的选择
常用的核函数有高斯(RBF)核函数、多项式(Polynomial)核函数和Sigmoid核函数等,其定义分别见公式(9)、公式(10)、公式(11),RBF核函数应用最广[15].
K(x,y)=e-γ‖x-y‖2
(9)
K(x,y)=(γxTy+r)p
(10)
K(x,y)=tanh(γxTy+r)
(11)
式中,x,y为特征空间矩阵,γ,r,p均为核函数参数.
表2 不同核函数的CE-SVM准确率对比表
Table 2 Comparison table of CE-SVM accuracy with different kernel functions

RBFPolynomialSigmoid训练集准确率/(%)65.462.361.2测试集准确率/(%)66.764.763.5
三种核函数中,RBF核函数表现相对稳定,而Polynomial核函数和Sigmoid核函数稳定性较差,运用支持向量机分类时,可优先考虑RBF核函数[19].本文复现了文献[19]中的交叉验证网格优选参数Matlab程序,获得使用不同核函数的CE-SVM模型预测准确率对比表.由表2可知,RBF核函数对打标签后的语料集分类性能高于Polynomial核函数和Sigmoid核函数3%~5%.
5 实验结果与对比分析
5.1 实验基础与思路
将本文提出的CE-SVM模型与广泛运用于文本分类的卷积神经网络(Convolutional Neural Networks,CNN)及朴素贝叶斯模型进行预测性能比较,并结合BAT中概股金融数据走势,实时对比三种模型的预测趋势以及不同策略的模拟交易结果来证明CE-SVM模型的优势.其中,CNN模型主要包括五层,依次为:词嵌入层、卷积层、最大池化层、全连接层以及softmax层.CNN通过卷积和池化操作抽取特征,并基于这些特征去训练分类器从而实现文本分类.
算法实现的开发环境为PyCharm_2018.1.1、MATLAB_R2014b,使用的处理器为2.9GHz IntelCorei7,内存为16GB,操作系统为macOS 10.14.1系统.
5.2 实验数据
本文为了在保证研究说服力的前提下简化实验,选取了在美上市中概股中最具代表性,新闻语料也最为丰富的三只股票,即百度(纳斯达克代码:BIDU)、阿里巴巴(纳斯达克代码:BABA)、腾讯(纳斯达克代码:TCEHY),简称BAT中概股.获取的数据时间段为2014年09月19日至2018年11月26日,其中,2014年09月19日至2018年07月05日的数据为训练及验证数据,2018年07月06日至2018年11月26日为样本外测试数据.具体包括两部分:
1)金融股票交易数据.本文研究的BAT中概股票历史价格数据均来自雅虎财经网(1)https://finance.yahoo.com,具体数据包括交易时间、开盘价、当日最高价、当日最低价、收盘价等.
2)与BAT中概股相关的金融新闻数据.具体数据包括新闻标题、内容、发布时间、出处等.数据来自各大权威金融新闻网站(新浪财经、雅虎财经、腾讯新闻、网易新闻、中国金融新闻网、中国财经新闻网、雪球网、证券时报网、今日头条等).经统计,BAT中概股金融历史新闻数据总计3150篇,与百度、阿里巴巴、腾讯相关的新闻分别为1022篇、993篇、1135篇.其中,95%作为样本内训练数据,5%作为样本为测试数据.
5.3 对比实验
5.3.1 预测性能的对比
由表3可知,三种模型的预测性能表现如下:CE-SVM对积极类新闻在精确率、召回率和f1值方面的表现均优于CNN、朴素贝叶斯;CE-SVM对消极类新闻除了精确率与朴素贝叶斯相当、稍逊于CNN外,在召回率和f1值方面的表现均更优;总体而言,CE-SVM对新闻的识别准确率相对于CNN提高了2%的同时比朴素贝叶斯提高了4%.产生该结果的原因是:CE-SVM对非结构化新闻数据的泛化能力比CNN以及朴素贝叶斯更出色,能够更有效地识别样本中的特征.因此,在相同训练集下CE-SVM拥有更好的预测性能.
表3 模型评估结果对比表
Table 3 Comparison table of model evaluation results

模型 类别精确率召回率f1值准确率CE-SVMpositive0.680.640.66-negative0.610.650.63-avg/total0.650.640.650.65CNNpositive0.650.630.63-negative0.620.640.62-avg/total0.630.630.620.63朴素贝叶斯positive0.610.580.59-negative0.610.640.62-avg/total0.610.610.610.61
5.3.2 预测趋势的对比
由表4可知三种模型关于BAT股价在100个交易日测试数据内走势预测正确与错误的数量对比情况,CE-SVM与CNN以及朴素贝叶斯对于同一天的股价趋势预测结果大体保持一致,但实际预测结果显示CE-SVM最佳,其次是CNN,再者是朴素贝叶斯.
表4 三种模型关于BAT股价走势的预测值实时对比图
Table 4 Real-time comparison of the predicted values of the three models on BAT′s stock price trend

模型类别百度阿里腾讯总数CE-SVM正确数677261200错误数332839100CNN正确数646859191错误数363241109朴素贝叶斯正确数616757185错误数393343115
相同条件下,结合BAT中概股价走势来看,在股价波动幅度比较大的时期CE-SVM的预测准确率较高.这是由于在股价波动期间会产生大量同一极性的新闻,所含特征数量多且易于区分,CE-SVM对于新闻的识别分类能力强于CNN和朴素贝叶斯.
5.3.3 模拟交易的对比
利用CE-SVM与CNN、朴素贝叶斯三种模型,通过与时间相对应的新闻预测BAT三只中概股价变动趋势,同时与买入并持有(Buy and Hold,B&H)策略进行模拟交易对比.为更直观地比较四种算法的收益情况,在模拟交易过程中不考虑买卖操作产生的交易成本等费用.

图5 BAT使用CE-SVM模型、CNN模型、朴素贝叶斯模型与B&H策略的模拟交易对比图
如图5所示,测试数据时间范围共计100个交易日.其中,CE-SVM模型的BAT平均收益率为11.49%;CNN模型的BAT平均收益率为7.77%;朴素贝叶斯模型的BAT平均收益率为3.87%;B&H策略的BAT平均收益率为-21.09%.结果表明,在相同的初始资金前提下,CE-SVM模型模拟交易的三只股票的平均收益率最高,其次是CNN模型,接着是朴素贝叶斯模型,最后是B&H策略.
虽然图5中B&H策略所示三只股票的价格在100个交易日内均属于下跌趋势,但是CE-SVM模型与CNN模型及朴素贝叶斯模型预测获得的超额收益一直处于上升趋势.同时,由于CE-SVM具有较强的泛化能力以及对高维数据较好的处理能力,在新闻数据越多的情况下,其分析新闻极性的能力越佳,策略所得收益率也越高.
6 总 结
本文通过增加关键短语的权重,实现自定义全自动机器打标签模型,提出一种新的CE-SVM模型,将语料随机分配生成不同的训练集合与验证集合,加入循环评估机制进行训练,在达到设定的预测准确率后退出循环得到最终训练结果,并通过样本外集合进行测试证明其合理性及有效性,从而改善了在中概股方面关于新闻对股票影响与预测的研究.未来,将进一步对标签进行升级,从定性分析向定量分析改进,提高算法的准确性.
猜你喜欢
中国外汇(2022年12期)2022-11-16 09:10:38
小资CHIC!ELEGANCE(2021年36期)2021-10-15 02:25:24
中国外汇(2021年8期)2021-08-11 23:46:38
证券市场红周刊(2020年17期)2020-05-10 06:15:41
四川文学(2020年11期)2020-02-06 01:54:30
当代陕西(2019年23期)2020-01-06 12:18:04
当代陕西(2019年9期)2019-05-20 09:47:38
数理化解题研究(2017年4期)2017-05-04 04:07:54
金融经济(2016年10期)2016-11-12 15:35:56
铁道通信信号(2016年6期)2016-06-01 12:10:20
