
机器阅读理解的技术研究综述
2020-05-12 09:40:24徐霄玲郑建立尹梓名
小型微型计算机系统 2020年3期
徐霄玲,郑建立,尹梓名
(上海理工大学 医疗器械与食品学院,上海 200093)
E-mail:172702146@st.usst.edu.cn
1 引 言
机器阅读理解(MRC,Machine Reading Comprehension)是自然语言处理的长期目标,是人工智能向前迈进的关键一步.互联网日益普及,深度学习等人工智能技术蓬勃发展,人们在图像识别、语音识别、围棋AI等领域已经使计算机达到接近人类甚至超越人类的水平.于是,人们开始往更为复杂的机器阅读理解领域进行探索.机器阅读理解是为了培养计算机对自然文本理解的能力,让其能像人类一样对文本进行阅读、推理,也就是意味着计算机在接受自然语言输入后能够给出正确的反馈[1].此概念在1972年首先[2]被提出.经过几十年的变化发展,已经由最初依据规则和词性、依存句法、语义角色等传统特征,演变为基于大数据和深度学习进行阅读推理.本文将从其具体任务,数据集和关键技术三方面,对机器阅读理解做出进一步阐述.
2 机器阅读理解任务概述
机器阅读理解实际上是由自然语言理解所衍生的子任务,用以衡量计算机“理解”自然语言所达到的程度.首先由Hirschmann[3]等人提出利用文本阅读并通过回答问题的形式评估机器阅读理解,此种评估方式延续至今.通常情况下,机器阅读理解任务主要由Document(需要机器阅读的篇章)、Question(需要机器回答的问题)、Answer(机器阅读理解的答案)三个要素构成.根据任务的不同,Answer可能是篇章中的单个实体或者是篇章中的片段,也可能是机器生成的句子.当任务是阅读选择题时,在上述基础上需要增加Candidate(候选答案)要素,Answer来自于候选答案.近年来,在篇章数据集上学者们做了大量工作,使阅读理解更加贴近真实应用场景:内容上,由虚构故事向真实问答靠拢;回答方法上,由单纯依靠篇章回答向依赖外部知识推理发展;数据量上,从以前的几百到现在动辄上万.数据集的具体比较详见第3节.
机器阅读理解虽然在认知智能领域是一个极具挑战的任务,但却有着较为悠久的历史.最初由Terry Winograd提出构想[2],认为语法、语义和推理是实现阅读理解的三大要素.1999年,出现首个自动阅读理解测试系统Deep Read[3],该系统以故事为基础衡量阅读理解任务,利用词袋模型BOW和人工编写的规则进行模式匹配,达到了40%的正确率.考虑到阅读理解需要大量常识,Schubert[4]等人在2000年率先提出一个基于情节逻辑的叙事理解框架,情节逻辑被用于语义表示和外部知识表示.总的说来,机器阅读理解早期发展速度缓慢,大量依靠手工提取的语法特征以及三元组信息,具有耗时长、鲁棒性差等缺点.直到Hermann等人[5]提出使用神经网络模型,该领域近年来才开始逐步发展起来.其提出的Deep LSTM Reader、Attentive Reader和Impatient Reader三种神经网络模型,奠定了机器阅读领域的方法基础.在此之后,Match-LSTM[6]、BiDAF[7]、Dynamic Coattention Networks[8]等大量优秀模型频现,权威刷榜评测任务排名不断更新,为机器阅读理解提供了统一衡量标准,极大地促进了自然语言理解的发展.
3 MRC数据集
机器阅读理解实际上是一个数据驱动型任务,因此数据集是其技术发展的基础.无论是基于人工规则还是基于深度学习等热门手段,数据集的质量和难度都直接关系到模型的质量和实用性,每次不同形式数据集的出现都会带来模型的创新.随着数据集规模增大和考查形式的变化,任务难度不断上升,对模型的要求也越来越高[9].到目前为止,已经出现很多经典英文数据集.这两年,国内对阅读理解任务逐步重视,积极向国际靠拢,开放了DuReader[10]等中文数据集.
表1 各个数据集基本统计信息比较
Table 1 Comparisons of basic statistical Information in datasets
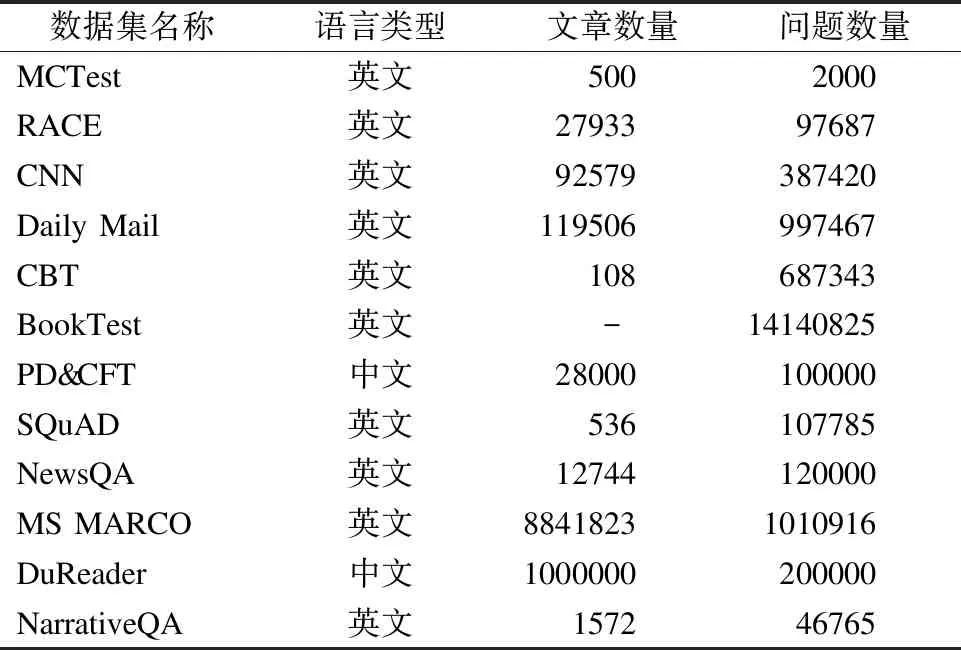
数据集名称语言类型文章数量问题数量MCTest英文5002000RACE英文2793397687CNN英文92579387420Daily Mail英文119506997467CBT英文108687343BookTest英文-14140825PD&CFT中文28000100000SQuAD英文536107785NewsQA英文12744120000MS MARCO英文88418231010916DuReader中文1000000200000NarrativeQA英文157246765
3.1 选择型数据集
选择题能有效避免模棱两可的答案,因此于2013年微软推出MCTest[11].MCTest是一个面向开放领域的数据集, 文章内容是适合7岁孩子理解的童话故事,提问形式为四选一选择题,且问题选项基本来自于原文,这说明基于此数据集的MRC评估模型基本不需要推理能力.MCTest虽然通过众包的方式反复检查校验以确保高质量,但由于其数据规模较小(仅包含了近500篇文章和2000个问题),无法满足神经网络等更加复杂的训练模型.2017年学界开放了RACE数据集[12].RACE同样利用选择题的方式评估MRC任务.相较于MCTest,它数据量上占绝对优势,详见表1.RACE数据来源于中国12-18岁中学生的英语考试试题,由语言专家出题,59.2%的问题需要联系上下文进行推理,能更加真实地以人类标准衡量机器阅读理解的能力.在SemEval-2018任务11发布了基于常识的阅读理解[13],要求模型引入外部知识,从两个候选答案中选出一个作为正确答案.
3.2 填空型数据集
填空就是要求读者补充句子中缺失的词语[14].以填空形式构造问题,数量上可以任意扩充.CNN/Daily Mail[5]率先解决了MRC领域数据量不足的问题.Hermann等人从美国有线电视新闻网和每日邮报网中收集了近100万新闻数据,利用实体检测和匿名化算法,将新闻中概括性语句转换为<文章(c),问题(q),答案(a)>三元组.文章中的实体用随机数字代替,模型利用数字回答相应问题,有利于帮助研究者注重语义关系.CBT[15]和BookTest[16]等也是填空型数据集.两者任务类似,都是从书中抽取连续21个句子,前20句子作为文章,预测第21句中缺失的词.但是BT数据规模更大,将近是CBT的60倍,更能满足复杂深度学习模型的数据需求.哈尔滨工业大学讯飞联合实验室于2016年7月提出首个中文填空型阅读理解数据集PD&CFT[17],增加了该领域语言的多样性,促进了中文阅读理解的发展.
3.3 篇章片段型数据集
篇章片段数据集指的是:在该数据集中,问题的答案不再是单一实体,而是文章中的片段(span).既可以是单一片段,也可以是多个片段的组合,答案类型更加丰富.由于答案的特殊性,因此多采用F1值、EM(准确匹配)、Bleu[18]和Rouge[19]等作为衡量预测值和真实值重叠程度的指标.
SQuAD[20]和NewsQA[21]是篇章片段数据集的代表,数据分别来自于维基百科和CNN新闻.目前,SQuAD数据集已经成为权威刷榜评测任务,且到发文为止在SQuAD1.1数据集中,机器表现已经超越人类.由于SQuAD1.1数据主要集中在可回答的问题,因此斯坦福在其基础上增加了50000个不可回答问题,提出SQuAD2.0[22],进一步提升了数据集难度.2018年第二届“讯飞杯”在其评测任务中发布了首个人工标注的中文篇章片段抽取型阅读理解数据集,填补了中文在这方面的空白.
3.4 多任务型数据集
4 机器理解方法分析与研究
解决机器阅读理解问题需要关注以下三个问题:
1)问题和文档表示:将自然语言文本转换为计算机能够理解的形式;
2)检索上下文:联系上下文并适当推理,检索出文档中与问题最相关的文章片段;
3)获取答案:对检索出的文章片段进行归纳总结,得到答案.
用于解决机器阅读理解问题方法有传统方法和深度学习方法.传统方法更多地是在句子粒度上回答问题.将问题和文档提取特征后表示成矩阵,或利用人工规则,对问题Q的每个候选答案句应用相应类型规则集中的所有规则,累计计算得分,总得分最高者为问题Q的答案句[26];或把阅读理解当成分类任务,根据已经得到的特征,利用SVM等传统机器学习算法,得到答案A[27].传统方法核心是特征抽取,包括抽取浅层特征和深层语义特征.目前被认为有效的特征主要有依存句法、词频共现、语篇关系等.虽然传统方法能在一些数据集上取得较好结果,但是由于特征需要专家根据数据集制定,鲁棒性差;再加之,只能从现有文本中提取特征,不能对文本进行推理,因此无法真正解决机器理解问题.
如今随着数据量几何级增长,硬件计算能力不断增强,深度学习方法被广泛运用到词粒度的机器阅读理解任务中.深度学习的最大优势在于能够通过通用的端到端的过程学习数据的特征,自动获取到数据的高层次表示,而不依赖于人工设计特征[28].用于MRC任务的深度学习模型基本包含嵌入层、编码层、语义交互层和答案抽取层.嵌入层将文章和问题映射成包含相关文本信息的向量表示,便于计算机理解;编码层利用RNN、LSTM等神经网络对文章和问题编码,得到上下文语义信息;匹配层根据将上述文章和问题编码信息进行融合匹配,最终得到混合两者语义的交互向量,这是整个模型中最重要的部分;答案预测层,根据语义交互向量,或选择答案,或抽取答案边界,或生成答案[29]
4.1 预训练模型
研究工作表明,预训练模型能有效提升大多数自然语言处理任务效果,MRC任务同样也适用.预训练模型是前人为了解决类似问题所创造出来的模型,该模型参数能直接应用于当前任务中,既能弥补在语料不足的情况下构造复杂神经网络,又能在语料充足的情况下加快收敛速度.预训练模型的输出值,一般被应用于嵌入层,用以得到通用文本特征.
自然语言处理的所有任务本质上都是对向量的进一步使用,词作为语言表示中的基本单位,如何将其转化为向量是基础工作之一.通常情况下,词向量是预先训练好的,可以将其看成单层的预训练模型.在深度学习时代未到来以前,最为简单的词向量表示方法就是one-hot编码.但由于其无法解决维度灾难和语义表达问题,Rumelhart等人[30]提出分布式词表示,使用稠密的低维向量表示每个词.研究者在此理论基础上,提出众多构建词向量的方法:Word2Vec[31]、Glove[32]和FastText[33],这些方法被广泛应用于自然语言处理领域的各项任务中.
4.1.1 ELMo
近年来,出现三大预训练模型.ELMo(Embeddings from Language Models)[34]是其中之一,它利用双向LSTM提取到训练数据的单词特征、句法特征和语义特征.包含N个词的语料(t1,t2,…,tN),前向LSTM根据已知词序列(t1,t2,…,tk-1),求词语tk的概率,如公式(1)所示.后向LSTM则反之,根据已知词序列(tk+1,tk+2,…,tN)求概率,如公式(2)所示.ELMo就是结合前向和后向LSTM,求取联合似然函数的最大值,见公式(3),其中Θ表示神经网络中的各项参数.ELMo用于MRC任务时,将模型的每层输出按照权重相乘得到词向量ELMok,再将ELMok与普通词向量xk或者是隐层输出向量hk拼接作为模型嵌入层输入.实验表明,ELMo使当时最好的单模型[35]在SQuAD数据集上F1值提升了1.7%.
(1)
(2)

(3)
4.1.2 GPT
GPT(Generative Pre-Training)(1)https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf是生成式预训练模型,是一种结合了无监督预训练和监督微调(supervised fine-tuning)的半监督方法.在预训练阶段,使用谷歌提出的单向Transformer[36]作为特征提取器.Transformer依靠自注意力机制抽取特征,能力强于LSTM,被认为是NLP领域效果最好的长距离特征提取器.其他方面,仍然采用标准的语言模型训练目标函数,根据已知前k-1个词,求取当前词概率的最大似然估计:
(4)
式(3)和式(4)比较,不难发现,GPT只依靠上文信息进行预测,而ELMo则结合了上下文信息.
Radford等人提出GPT-2[37],是GPT的升级版.GPT-2与GPT最大的区别在于数据规模更大,模型层数更多,高达48层.GPT应用于具体NLP任务时,要保证任务的网络结构与GPT一致,最简单的做法就是在GPT的最后一层Transformer层接入softmax作为任务输出层,通过训练对网络参数进行微调.实验表明,GPT应用于RACE数据集,使最佳模型结果提高了5.7%.
4.1.3 BERT
考虑到GPT模型的不足,谷歌团队提出BERT(Bidirectional Encoder Representations from Transformers)预训练模型[38],得到了学术界广泛关注.BERT预训练模型在流程上,与GPT保持了一致,都包含了预训练阶段和微调阶段.它与GPT最大的不同在于其使用双向Transformer完成了语言模型的训练,是GPT模型的进一步发展.同为双向语言模型,但其与ELMo训练的目标函数是不同的.ELMo分别将P(tk|t1,t2,…,tk-1)和(tk+1,tk+2,…,tN)作为目标函数,求两者结合后的最大似然概率.而BERT则以P(tk|t1,t2,…,tk-1,tk+1,…,tN)为目标函数,真正意义上表征了上下文语境特征.BERT提出后,在11个NLP任务中均取得了最好效果.在MRC任务中,单个BERT模型在SQuAD数据集中较最优模型F1值提高了1.5%.
三大预训练模型结构差异详见图1.Trm代表Transformer,(E1,E2,…,EN)为预训练模型输入,(T,T2,…,TN)则表示输出.ELMo使用双向LSTM的输出用于下游任务,而GPT使用单向Transformer,BERT使用双向Transformer.

图1 预训练模型结构对比图
4.2 注意力机制(Attetion Mechanism)
阅读理解任务中,篇章往往较长,但与答案相关的内容只是其中的一小部分.在传统方法中,通常利用循环网络将篇章编码成固定长度的中间语义向量,然后利用该向量指导每一步长输出.此举既造成了信息过载,限制了模型效果,也降低了模型的运行效率.为改变上述状况,学者们从机器翻译领域借鉴注意力机制[39],在MRC模型的语义交互层加入注意力机制,获取文章中与问题最相关的部分以提升效果.
4.2.1 基本概念
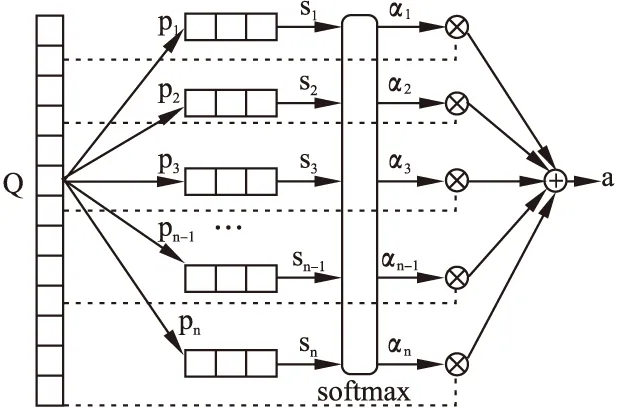
图2 注意力机制流程
谷歌指出注意力机制就是加权求和[36].注意力实现机制如图2所示,分为两个步骤:计算注意力分布和加权平均.MRC任务中,P=[p1,p2,p3,…,pn-1,pn]代表篇章信息,向量pi为篇章中的每个词的向量表示,i表示词在文中的索引,i∈[1,n];Q为问题的向量表示.通过打分函数s计算篇章中每个词与问题Q的相关性分数,然后经过softmax函数层,得到和为1的注意力分布αi,如公式(5)所示:
(5)
其中函数s为注意力打分函数,可以是简单的计算,也可以是复杂的神经网络,常见的主要有点积运算、双线性模型、缩放点积模型和加性模型(2)https://nndl.github.io/,分别见公式(6)-公式(9):
(6)
(7)
(8)
s(pi,Q)=vTtanh(Wpi+UQ)
(9)
其中W、U、v为神经网络模型可学习参数,d表示篇章向量的维度.不同的打分函数对模型的意义是不一样的,例如点积运算相较于加性模型,能更好的利用矩阵乘法,有利于训练效率地提高;双线性模型相较于点积运算,引入了非对称项,有利于信息提取等.因此,需要根据数据和模型需要选择合适的打分函数.
注意力分布αi获取了篇章中与问题强相关的部分,最后根据加权平均聚合所有篇章信息,强化相关信息,弱化甚至舍弃无关信息,用于最后的答案预测,见公式(10).
(10)
4.2.2 相关模型
Attentive Reader[5]率先将注意力机制应用于机器阅读理解中,使用双向LSTM对文章进行编码,利用注意力机制求出每个词对应的权重,加权求和后最终表示出文章.其中使用公式(9)作为计算注意力分布的打分函数.Stanford Attentive Reader使用双线性项(公式(7))代替上述模型中tanh函数计算权重,在其基础上效果提升了7%~10%[23].Impatient Reader[5]模型基本结构与Attentive Reader一致,但同时考虑了问题对文章权重的影响,因此每当从问题中获取一个词就迭代更新一次文章表示的权重.Attention Sum Reader[40]通过点积运算获取注意力权重,同时将相同词概率进行合并获取概率,得出答案.Gated-Attention[41]在AS Reader模型基础上,增加网络层数,并改用Hadamard乘法求解权重,提出新的注意力模型.Match-LSTM[42]则是第一个适用于SQuAD数据集的端到端神经网络模型.
之后,出现很多关于注意力的变体.2016年,科大讯飞提出Attention-over-Attention Reader层叠式注意力模型[43],在原有注意力上增加一层注意力,来描述每一个注意力的重要性.并在其基础上衍生出交互式层叠注意力模型(Interactive AoA Reader)和融合式层叠注意力模型(Hybrid AoA Reader),在SQuAD数据集上均表现不俗.针对选择题型机器阅读理解,朱海潮[44]等人提出Hierarchical Attention Flow,通过使用词级别和句子级别注意力,将文章、问题和选项进行充分交互,在RACE数据集上取得优于基准模型的效果.DCN[45]利用Co-attention技术分别生成关于文档和问题的权重分布并结合,通过多次迭代得到答案;BiDAF[7]在交互层引入双向注意力机制context-to-query和query-to-context;DFN[46]将一般模型中固定的注意力机制扩展到多策略注意力,使模型能根据问题类型动态选择出适宜的注意力机制;Reasonet[47]则将Memory Network(见4.3节)和attention结合,动态决定阅读次数,直至能回答问题为止.这些均为MRC任务中注意力的使用提供了新思路.具体模型在数据集上的实验结果详见表2、表3.
表2 模型在RACE数据集上的正确率
Table 2 Accuracy on RACE datasets

模 型 RACE-MRACE-HRACEStanford AR44.243.043.3GA Reader43.744.244.1Hierarchical Attention[44]45.046.446.0DFN[46]51.545.747.4Human Performance95.494.294.5
表3 模型在CNN/DailyMail和CBT数据集的正确率
Table 3 Accuracy on CNN/DailyMail and CBT datasets

模 型 CNNValTestCBT-NEValTestDaily MailValTestAttentive Reader[5]61.663.070.569.0--Impatient Reader[5]61.863.869.068.0--Stanford AR[23]73.873.677.676.6--AS Reader[40]68.669.575.073.973.868.6GA Reader[41]73.073.876.775.774.969.0AoA Reader[43]73.174.4--77.872.0ReasoNet[47]72.974.777.676.6--BiDAF[7]76.376.980.379.6--
4.3 记忆网络(Memory Network)
随着数据量不断增加,学者认为传统机器学习模型(如RNN、LSTM等)利用隐含状态记忆,容量太小,无法完整记录文本内容.除了使用注意力机制提取与问题最相关的文章内容之外,他们提出一种可读写的外部记忆模块,与问题相关的信息保存在外部记忆中,需要时再进行读取.并将其和推理组件联合训练,最终得到具有长期记忆推理能力的灵活记忆能力.MRC任务中,不仅文章篇幅较长,而且还有可能需要添加先验知识,记忆网络的使用能有效改善网络容量不足、长距离依赖等问题.
4.3.1 基本概念
记忆网络的概念在2014年首次被提出[48].从某种程度上说,记忆网络是一个框架,包含输入模块、输出模块、记忆模块等.学者可以根据自己的需要定制框架下的各个模块.记忆网络常见模块构成如图3所示.
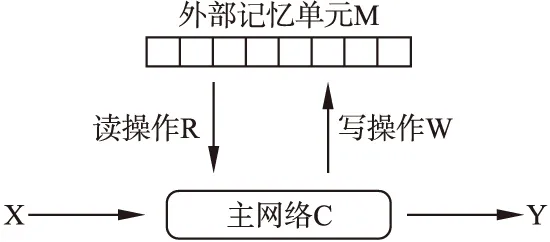
图3 记忆网络基本组成模块
输入模块X:输入训练数据,包括篇章、问题等.
输出模块Y:输出答案.
主网络C:控制信息交互.既包括与外界信息交互:根据输入X,获取篇章内容P和问题Q;得到预测答案后输出到Y.也包括与外部记忆单元交互,控制读写操作完成外部记忆单元的动态更新.
读操作R:根据输入中的问题Q、主网络在多次推理过程中生成的问题向量qr,从外部记忆单元中读取相应的信息.
写操作W:根据主网络在多次推理过程中生成的问题qw、待写入的信息a,更新外部记忆单元内的相关信息.
外部记忆单元M:引入的外部记忆模块,用于存储信息.存储形式可以为数组、栈、队列等,也就是说每个记忆单元都是拥有自己的地址的,读写操作都是根据寻址后完成的.
4.3.2 相关模型
Weston等人[48]首先提出记忆网络的雏形,指出记忆网络由一个记忆模块m和四个组件I(输入)、G(泛化)、O(输出)、R(回答)组成.将上下文和问题输入之后,利用记忆模块进行存储,并能根据相关信息动态更新,最后找到与问题最相关的记忆作为答案并输出.上述模型虽然能解决网络容量不足的问题,但模型每一层都需要监督,无法进行反向传播计算,这与现阶段端到端的模型思想相违背.为了解决上述问题,End-to-End Memory Networks(MemN2N)[49]被提出.它在满足基本组成模块的前提下,重新搭建模型框架,使用加权求和的方式得到输出向量,是一个端到端的反向传播记忆网络,同时支持多跳推理.Key-Value Memory Network[50]在端到端记忆网络的基础上,优化了网络结构,扩大了记忆规模,使其能更好地存储先验知识.上述三个模型为记忆网络的发展奠定了理论基础,却一直没有运用到相关机器阅读理解数据集上,直到MEMEN模型的出现[51].MEMEN对篇章和问题采取多层次输入,包括字向量输入、词向量输入、词性输入和命名实体输入,充分融合文档和问题当中的信息,将其存储到记忆单元中.同时使用一种新的分层注意力机制寻址记忆单元,并动态更新单元内容.类似地还有MAMCN[52],增加额外记忆单元,并利用BiGRU更新,尝试解决长距离依赖问题,实现跨文档预测答案.
表4 模型在SQuAD测试数据集上的EM值和F1值
Table 4 Exact Match(EM)and F1 scores on SQuAD 1.1 test
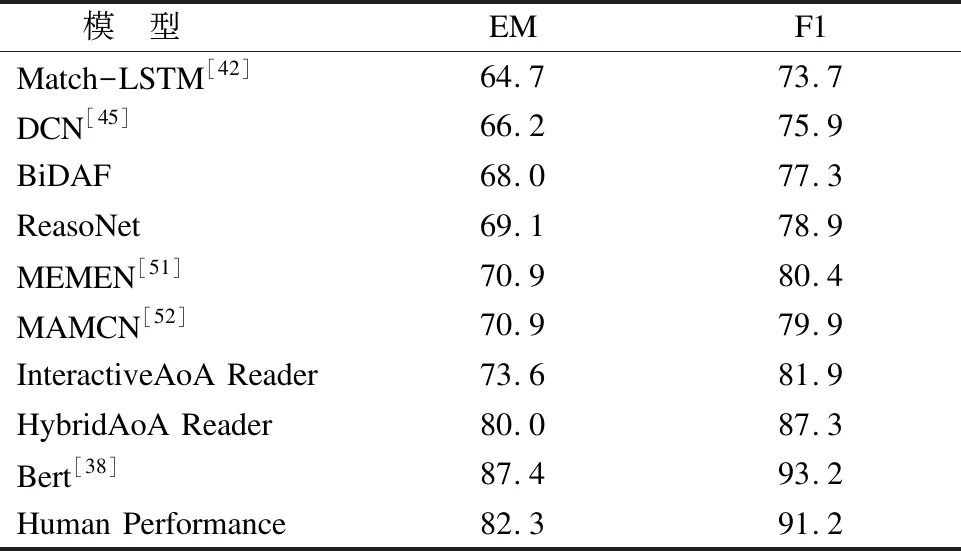
模 型 EM F1Match-LSTM[42]64.773.7DCN[45]66.275.9BiDAF68.077.3ReasoNet69.178.9MEMEN[51]70.980.4MAMCN[52]70.979.9InteractiveAoA Reader73.681.9HybridAoA Reader80.087.3Bert[38]87.493.2Human Performance82.391.2
从表2-表4中,我们不难发现现阶段模型往往是针对特定类型数据集设计,大多数模型不具备迁移到其他类型数据集的能力.即使迁移成功,模型也不是一成不变,相同模型在不同类型数据集上的效果也不同.我们需要根据数据集特点对模型进行选择、设计和改进.
5 总 结
机器理解能力是机器从感知智能走向认知智能的关键,机器阅读理解近些年来取得了较快的发展.在答案形式上,从最初的选择题,变成单词填空,最终发展到篇章片段抽取或自主生成答案;在数据集内容上,从简单的孩童虚构故事,往依托常识、看重推理能力的真实世界人类问答发展;在关键技术上,由通过基于传统特征完成阅读理解,到如今使用深度学习技术并结合预训练模型、注意力机制、记忆网络等新型技术提升效果.近两年,注意力机制较记忆网络发展更为火热,出现很多变体.
对机器阅读理解未来发展有以下几点值得关注:
1)纵观现有阅读理解数据集,针对专业领域数据集较少,适用于通用领域的模型并不一定在特定领域有好的效果,因此,应该结合行业趋势,推出如金融、医疗领域的相关数据集.
2)从上述研究方法中,不难发现attention的设计与任务息息相关,如何根据任务设计合理的attention方法仍会是研究热点.
3)现阅读理解模型基本是在没有融合外部知识的情况下,直接从给定文档中抽取相关信息作为答案,这与人类阅读习惯有较大差异.因此,如何整合多数据源外部知识,并将其融入现有模型是值得我们关注的.
4)大多数相关中文模型依赖于英文模型,应该综合考虑中文和英文语言特点上的差异,构建更加适用于中文的模型.
5)将机器阅读理解技术与其他自然语言处理任务相结合,有利于促进自然语言处理技术整体发展.
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
环球时报(2022-03-14)2022-03-14 18:19:44
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
电影(2018年8期)2018-09-21 08:00:06
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
