
大数据时代下电视产品的营销推荐研究
2020-05-07 02:08:24
生产力研究 2020年3期
(江苏师范大学 数学与统计学院,江苏 徐州 221000)
一、引言
随着数字电视、网络电视的快速普及,服务提供商可以根据数字电视或网络电视的收视纪录,来更好地了解用户的收视行为和偏好[1]。迄今为止,个性化推荐的算法技术发展迅速,其中,最常用的是协同过滤算法和聚类算法。例如:黄贤英等(2018)[2]提出了新闻文本内容相似度的计算方式和时间窗的概念,考虑了特征词的词性以及它在新闻中的位置的因素,建立了个性化新闻推荐模型。此外,还有其他的算法应用于个性化推荐,例如:徐宏等(2018)[3]建立了基于MC-Apriori 算法的面向旅游用户个性化搜索的关键词推荐模型,向用户推荐满足其当前搜索兴趣的旅游信息。由于每户家庭的电视用户类型不同、收看的节目类型也不同,因此本文针对不同的数据集,采用了基于电视产品内容的协同过滤算法和基于电视用户的协同过滤算法,为用户做出合理化的推荐。
二、基于内容(CB)的推荐模型的建立与求解
(一)算法的理论介绍
基于内容(CB)的推荐算法[4]的原理很简单:它是根据用户过去喜爱的物品,提取出每个物品的一些特征,并利用这些特征数据,学习该用户的喜好,最后与候选的物品特征进行比较,为用户推荐相似度较大的物品。
(二)基于jieba 分词的文本特征抽取
1.jieba 分词。本文采用Python 软件对附件1 中的文本信息进行中文jieba 分词[5-6]。分词是对于一个特定的字符串Q,将其切分成多个词语组成的字符串,会有q 个分割方案。我们采用概率语言模型的分词方法来选择最佳的切分方案。
2.概率语言模型的分词方法。对于多个切分方案,我们需要计算出可能性最大的切分序列,其概率模型表示为:
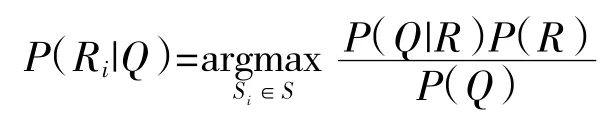
其中Ri表示第i 种切分方案,(1,2,…,q)。
计算P(R1|Q)和P(R2|Q),选择概率值较大的切分方案。根据贝叶斯公式:
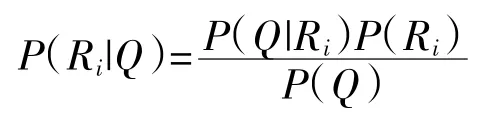
其中P(Q)是字符串在语料库中出现的概率,且P(Q|Ri)=1。
因此,比较P(R1|Q)和P(R2|Q)的值,也就是比较P(R1)和P(R2)的大小,因此P(Ri)的概率表达式即为:
P(Ri)=P(Ri1Ri2…Rim)≈P(Ri1)×P(Ri2)×…×P(Rim)
其中,对于不同的Ri,m 的值不同,一般来说m的值越大,Ri越小。也就是说,分出的词越多,概率越小。下面,我们需要计算P(Rij):
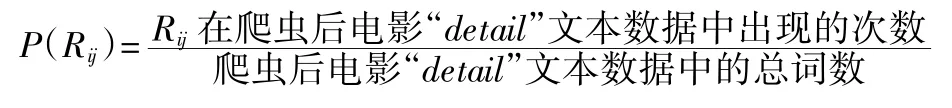
因此,我们可以推导出:
logP(Rij)=log(Freq(Rij))-log(N)
本文基于概率语言模型,分别对电视剧、电影、综艺、动漫的“detail”文本数据进行jieba 分词,得到所有的分词结果,并将它们保存在向量text 中。
3.计算分词词频。根据上一步text 中的分词结果,我们遍历每个单词,计算出每个单词在该“detail”文本中出现的次数,找出词频大于1 的单词,舍弃词频为0 的单词,并且通过dict 创建字典,对每个词频大于1 的单词进行编号。
(三)基于内容推荐的文本向量模型
1.建立向量表示的语料库。根据分词对所有的电影“detail”文本数据的分词结果进行向量表示,并保存在语料库中。
2.TF-IDF 分词权重模型。设所有电影的“detail”文本数据的集合为:
C={C1,C2,…,CN}
而所有电影的“detail”文本数据中出现的分词的集合为:
T={T1,T1,…,TW}
即:这些“detail”文本数据中包含了W 个词,使用一个向量表示所有的电影。比如第j 个文章被表示为:
Cj={W1j,W2j,…,Wnj}
其中Wij表示第i 个词Ti在第j 个电影“detail”中的权重,值越大表示越重要。在大多数已有的基于内容的推荐算法中,Wij的取值常用的是词频-逆文档频率[6-7](TF-IDF)。TF-IDF 的分词权重模型表示为:


(四)基于奇异值分解(SVD)的降维模型
假设我们的矩阵A 是一个m×n 的矩阵,那么我们定义矩阵A 的SVD 为:

其中U 是一个m×m 的矩阵;∑是一个m×n 的矩阵,主对角线上的元素称为奇异值;V 是一个n×n的矩阵。U 和V 都是酉矩阵[8]。
(五)TOPSIS 评价模型
TOPSIS 是计算诸评价对象与两者方案的距离,得到相对接近程度,找出最优方案和最劣方案。计算步骤如下:
第一步:设某一问题,决策矩阵为F。构成规范化的决策矩阵Z',其元素为,且有:

第二步:决定理想解、负理想解。决策矩阵Z 中元素Zij值越大说明方案越好,则:
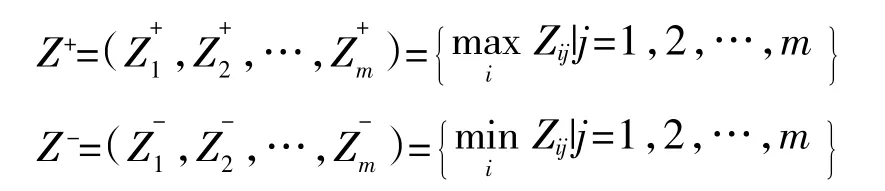
第三步:计算每个方案到正负理想点的距离,找到距离最短的最优解。
(六)基于余弦相似法的相似度模型
余弦相似度,是计算两个向量的夹角余弦值,评价两个方案的相似度[9-10]。
(七)均方根误差(RMSE)检验
均方根误差是观测值与真值偏差的平方和观测次数n 比值的平方根,可以检验模型预测的偏差程度。
(八)基于内容的推荐模型的求解
模型求解步骤如下:
我很小很小的时候,在澡盆里洗澡,洗完了,澡盆被端走,地上有一个圆圆的水印,我就指着水印说:“太阳!太阳!”据说我当时这样说的时候,是十分激动的。夏天,我赤着脚在地上走,脚上有水,地上就有脚印,我又指着脚印说:“小船!小船!”看来我小时候是有些想象力的,而我现在想象力要比那时糟得多。
第一步:通过Python 软件中的Pyspide 系统进行网络爬虫,爬取出附件中用户单片点播和点播的所有收视节目的相关信息以及所有电视剧、电影、综艺等的相关信息。
第二步:数据预处理:补充点播和单片点播数据中文本数据的缺失值,用“无”代替;对点播中的“用户付费金额”“用户收视时长”的数据进行标准化;用中位数法分别对单片点播、点播中的演员、导演、细节、地区、种类、类型的数据矩阵中的缺失数据进行补充;采用最小-最大值规范化方法对点播数据矩阵“点播2”和单片点播数据矩阵“单片2”中的每一列数据进行归一化处理。
第三步:对用户点播、用户单片点播的数据进行分析:(1)将点播的演员、导演、细节、地区、节目种类、节目类型、二级目录的文本数据分别生成列表,并通过计算词频将文本数据转换成数字向量;(2)计算TF-IDF 权重;(3)采用SVD 模型对每一列的TF-IDF 权重数据进行降维,得到奇异值矩阵,并存入DataFrame 二维数据结构中[11]。
第四步:采用topsis 综合评价法对每位用户观看节目的所有信息数据进行综合评价,得到综合评价值,并将用户、节目名称、评分构成新的矩阵[12]。
第五步:将爬虫后得到的所有电视剧、电影、综艺节目、动画片的相关信息做第一步至第四步的同样的分词处理。
第六步:采用交叉验证方法验证模型的可靠性,本文我们随机分了80%的训练集,20%的测试集,计算训练数据与测试数据之间的均方误差来检验模型。
第七步:采用余弦相似度模型对处理后的爬虫数据与点播、单片点播数据进行相似性分析,得到爬虫数据与用户点播、单片点播数据的相似度即为推荐指数。
第八步:采用均方值误差对模型进行检验,得到误差为:RMSE=0.65。

表1 用户11004 的推荐结果
三、基于用户的协同过滤推荐算法
基于用户的协同过滤算法,是一种采集用户之前的爱好习惯预测用户对商品和内容的嗜好,将同类型的用户放在一起,进行推荐。
(一)算法的具体实现步骤
1.寻找用户间的相似度。我们利用上文建立的余弦相似度模型,计算用户之间的相似度,对用户进行分类。
2.推荐物品。在选取上述方法中的一种得到各个用户之间相似度,针对目标用户u,进一步选出相似的k 个用户,用集合S(u,k)表示;提取出S 中所有用户喜欢的物品,去掉目标用户u 曾经喜欢的物品;对剩下的物品进行评分与相似度加权,最后根据相似度从高到低对目标用户u 进行推荐。
3.数据连接。把55 个销售产品作为电影产品,提取出它们的标签,对于缺失数据,我们采用支持向量机模型进行预测,得到所有的电影产品的标签,部分数据如表1 所示。然后根据爬虫后的数据与用户的收视数据进行分析,得到基于用户收视行为的标签。
4.相似性分析及RMSE 检验。本文采用余弦相似度计算用户与用户之间标签的相似性和55 个销售产品与用户之间的标签的相似性,并进行RMSE模型的检验。
(二)结果与营销对策
采集用户之前的收视爱好习惯以及用户的基本信息,我们可以将用户进行分类,分成很多个用户群,如表2 所示。

表2 用户群以及观看特征
根据表2 的用户群特征,用户群1 可以基本定位为儿童用户群体,可以估测该电视用户的家中有儿童,针对这一用户群体,可以重点宣传与突出营销,对此类群体可以通过动画产品的宣传不断吸引用户的观看兴趣,提高用户的持续观看的概率。
用户群2 偏女性居多,且观看电视的时长较短,针对此类用户群,不进行重点推销,运用宣传手段进行趣味主页和趣味活动的引导,挖掘或者激发用户的观看兴趣。此外,还可以向该用户群提供有关厨艺和家务劳动小技巧的短视频,既能节约用户群的观看时间,又能吸引用户的兴趣,而不产生厌恶感。
用户群3 可以定位为TFBOYS 的粉丝,因此,电视产品供应商可以在电视主页进行推荐,吸引用户的观看兴趣。同时,对于该用户群中的VIP 用户,采取优惠政策,推送一些VIP 专享节目,既能满足用户群3 中VIP 用户的观看需求,稳固用户群,还能吸引用户群3 中非VIP 用户的VIP 充值兴趣,增加会员制的营销收入,促进电视产品的营销。
四、结论
针对电视产品的推荐,我们采用了基于内容的协同过滤算法,分析用户的收视内容以及爬虫后得到的数据信息,为每位用户推荐了相似度(从高到低)前20 的电视产品。此外,我们利用基于用户的协同过滤算法,分析用户的观看行为,将用户进行分类,为用户做出了推荐。本文采用的RMSE 检验法得到的RMSE 检验值为0.67 和0.69,数值较高,结果完美,但是结果与用户的记录有些出入,我们还需要对中文文本挖掘进行深入探讨。
猜你喜欢
纺织科学研究(2023年12期)2023-12-19 12:36:06
消费电子(2021年6期)2021-07-17 10:47:38
求知导刊(2019年17期)2019-10-18 09:17:04
智富时代(2019年6期)2019-07-24 10:33:16
电源技术(2017年1期)2017-03-20 13:37:58
高中生·天天向上(2016年9期)2016-11-22 09:10:34
电源技术(2015年1期)2015-08-22 11:16:34
电力建设(2015年2期)2015-07-12 14:15:59
黑龙江史志(2014年12期)2014-11-24 18:00:58
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
