
基于YOLOv3的红外行人小目标检测技术研究
2020-05-07 09:30:16李慕锴崔文楠
红外技术 2020年2期
李慕锴,张 涛,崔文楠
(1.中国科学院 上海技术物理研究所 上海 200083;2.中国科学院大学,北京 100049)
0 引言
行人检测是图像处理研究中的经典课题,其研究成果在视频监控、地区侦查、人体行为理解、遇难目标搜救等领域都有诸多应用。随着近年来计算机视觉、机器学习和深度学习等新技术的突破,可见光图像中的行人检测技术已经逐渐发展成熟,出现了许多具有高可用性的方法。然而可见光相机的工作依赖于白天或者其他光照充足的条件,无法满足很多夜间场景下的监控需求,其工作的可持续性存在问题。红外相机基于目标对红外光的反射和目标自身的热辐射进行成像,受光照强度条件的影响很小,可以覆盖大多数夜间的场景,在白天也有很好的工作能力,因此红外相机能够更好满足持续工作的需求。并且随着红外成像系统价格的逐年降低,红外相机越来越成为各类监控系统中的重要组成部分,而红外图像中的行人检测技术问题也成为计算机视觉研究中的重点课题。
与可见光图像相比,红外图像仅有一个颜色通道,提供的信息更少,并且红外图像往往有分辨率低、物体边缘模糊、含有噪声、对比度较低等问题,使得红外图像中能够提取到的特征信息减少。红外图像中目标往往具有较高的亮度,特征更加明显。传统的行人检测方法主要是使用人为设计的特征提取器,如Haar[1]、histogram of oriented gridients(HOG)[2]、aggregate channel features(ACF)[3]等,来提取图像中行人目标的特征,然后再通过滑动窗口的方法对图像的局部提取特征,最后通过support vector machine(SVM)[4]、adaboost等分类器来判断区域是否有目标。深度学习将图像领域中各个问题的处理精度都提升到了一个更高的水平,在目标检测领域,主要分为两类方法,一类通过区域打分来预测目标区域,然后通过神经网络来对区域进行分类,这类方法以R-CNN[5]系列为代表,包括后续的fast R-CNN[6]、faster R-CNN[7]以及single shot multibox detector(SSD)[8]等;另一类方法通过回归得出目标区域再通过神经网络分类,这类方法以YOLO[9],YOLO9000[10]和YOLOv3[11]为代表,这一系列的算法都在红外图像处理中有很多应用。
现有的检测算法中,以深度学习的目标检测算法最为优秀,不过SSD、R-CNN系列的网络复杂度过高,即使使用运算速度非常高的GPU也仍然运行缓慢,而YOLO系列的方法解决了网络复杂度过高的问题,在主流的GPU上算法的运行速度达到60 fps以上,能够满足实时性要求。本次研究中就以增强了小目标检测能力的YOLOv3为主要网络,通过对网络进行改进,进一步增强了特征描述能力,使其能够在实际的红外小目标处理问题中得到应用。
1 原理简介
1.1 YOLOv3算法简介
YOLO目标检测算法是Redmon等[9]在CVPR2016上提出的一种全新的端到端目标检测算法。与同期的fast R-CNN,faster R-CNN等算法使用区域建议网络预测目标可能的位置不同,YOLO直接一次回归得出所有目标的可能位置,虽然定位精度有所降低,但是大幅度地提升了算法的时间效率,得到了具有高实时性的目标检测方法。经过近几年的改良,Redmon等[10-11]在YOLO的基础上又提出了YOLO9000、YOLOv3目标检测算法,到YOLOv3其检测精度已经超过faster R-CNN,与精度最高的Retina net基本持平,在保持高精度的同时,YOLOv3的速度比其他算法要高3倍以上,是目前目标检测领域的最优秀的算法之一。
YOLOv3在目标位置预测方面引入了faster R-CNN中使用锚点框(anchor box)的思想,在每一个特征图上预测3个锚点框。对于一幅输入图像,YOLOv3算法将其分成13×13块,在每一个小块上预测3个目标的边界框,并且YOLOv3引入了多尺度融合的方法,对图像在3个尺度上进行目标边界框的预测,从而大幅提升了小目标检测的精度。目标边界框参数的计算如图1所示[11]。
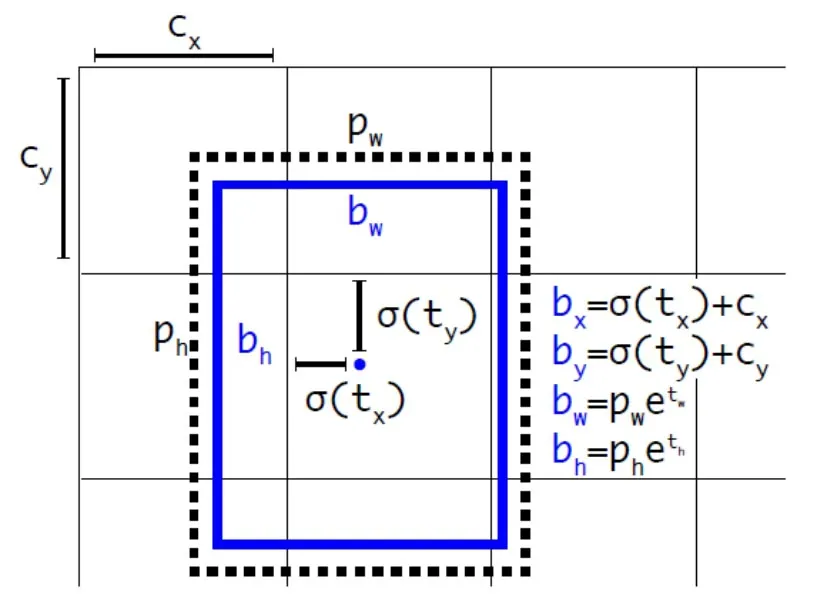
图1 YOLOv3边界框计算 Fig.1 YOLOv3 bounding box calculation
YOLOv3在目标的分类上使用了比之前深度更大的神经网络,其网络中大量3×3和1×1的卷积核保证了良好的特征提取,使用多尺度预测提升了小目标的检测精度。在深度学习领域,更深的网络意味着可以提取更为复杂的特征,然而随着网络深度加大会出现训练难度加大,准确率下降的问题,Resnet很好地解决了这个难题。YOLOv3借鉴Resnet的思想,引入多个Resnet模块,设计了一个新的层数更多并且分类准确率更高的网络,由于其包含53个卷积层,作者将其命名为darknet-53,其结构如图2[11]。
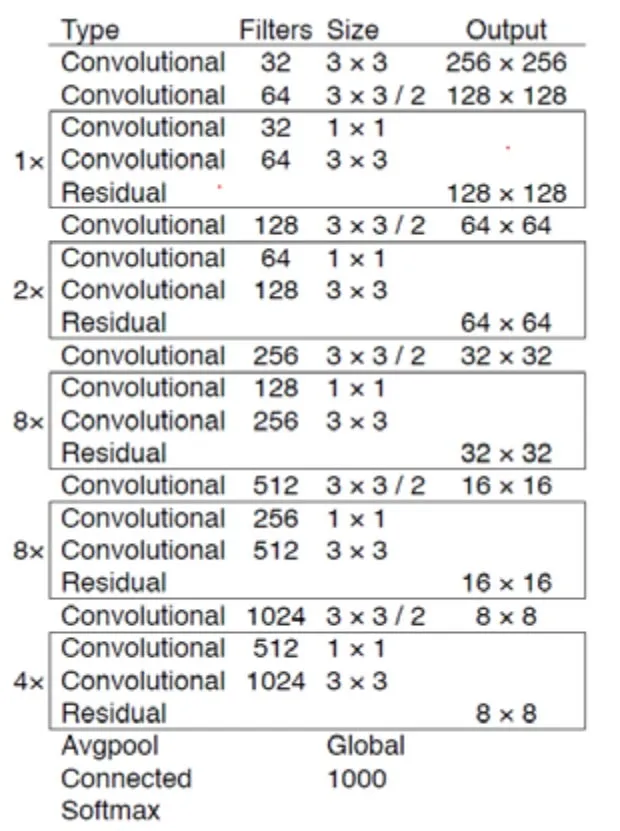
图2 YOLOv3网络结构Fig.2 YOLOv3 network structure
1.2 SENet简介
Squeeze-and-Excitation Networks[12]由Momenta公司的Jie Hu等人提出,是一种能够显著提高网络性能的新型网络模型。目前在提升网络性能方面已经有大量的前人工作,有从统计角度出发的方法,例如dropout通过随机减少网络间的连接来减少过拟合;有从空间维度层面寻找提升的方法,例如Inception结构嵌入多尺度信息,聚合多种不同感受野上的特征来获得性能提升。而SENet从前人很少考虑到的特征通道间的关系出发,提出了一种特征重标定策略,这种策略通过显示建模特征通道间的相互依赖关系实现,可以通过学习来获取到每个特征通道的重要程度,然后根据这个主要程度来提升重要特征的权重并抑制不重要的特征。
SENet中包含两个关键操作,压缩(Squeeze)和激励(Excitation),其主要流程如图3[12],其中Ftr和Fsq为压缩操作,Fex为激活操作,X为输入,U为中间变换结果,H、W、C为网络的宽高和层数。压缩操作顺着空间维度来对提取到的特征进行压缩,将每个二维的特征通道换算为一个实数,这个实数在某种程度上会具有全局感受野,并且输出的维度和输入的特征通道数相匹配,它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野。激励操作类似于循环神经网络中的门的机制,通过学习参数w来为每个特征通道生成权重,它可以通过两个全连接层实现,学习得到的参数w即表征了每个特征通道的重要性。最后的操作是权重重标定(Reweight),它将之前学习到的每个特征通道的权重归一化,然后通过乘法加权到原来的特种通道上,即完成了每个特征通道的重要性的标定。SENet可以很方便地插入在Resnet之后,得到一个SE-Resnet模块,如图4[12]所示。经过作者的多番验证,在不同规模的Resnet上引入SENet后,均能够大幅提升网络的准确率,并且作者依靠SENet赢得了ImageNet 2017图像分类任务的冠军。
2 改进YOLOv3网络
YOLOv3在当前各类目标检测任务中已经取得了非常优越的效果,不过算法仍然有很多改进的空间,尤其对于小目标方面。在实际的红外行人小目标数据中,直接使用YOLOv3对数据进行训练,最后得到的模型具有良好的召回率,但是准确率不够。为了得到一个具有实时性,同时目标检测的准确率和虚警率都良好的算法模型,以YOLOv3为基础网络,结合SENet以提升分类网络的准确率是一个可行的思路。
根据SENet的思路,对网络进行改进一般有几种方式,一种是直接在卷积层后面直接加SENet模块,这种方法对所有网络都通用,但是由于现在的网络中都含有大量卷积层并且参数量巨大,这样添加SENet模块增加的参数量大,且需要大量实验来确定在哪些卷积层后面加入新模块。一种是用加入了SENet的模块替换原有网络中的inception或者residual层,这类方法替换位置较为明确,需要反复实验的可能性较小,并且作者也积累了一定经验。在YOLOv3中含有较多的Residual层,于是对网络的改进采取引入SE-Resnet模块的方法。
SE-Resnet模块中,用Global average pooling层做压缩操作,将每个特征通道变换成一个实数值,使C个特征图最后变成一个1×1×C的实数序列。被处理的多个特征图可以被解释为从图像中提取到的局部特征描述子的集合,每个特征图无法利用到其他特征图的上下文信息。使用Global average pooling可以使其拥有全局的感受野,从而让低层网络也能利用全局信息。
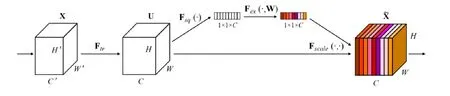
图3 SENet工作流程Fig.3 SENet workflow
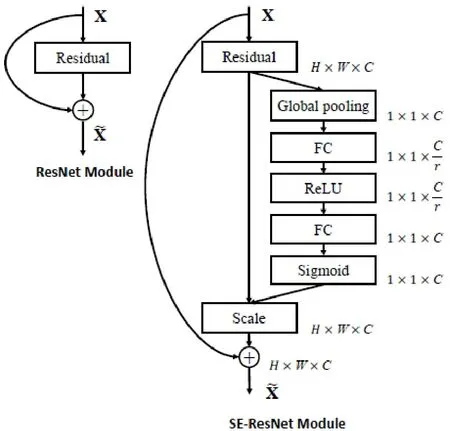
图4 SE-Resnet模块Fig.4 SE-Resnet module
激活操作是SENet中用于捕获特征通道重要性和依赖性的关键操作,对于它的实现原作者使用了两个全连接层(full connected layer)结合ReLU函数去建模各个通道之间的相关性,并且其输出的权重数与输入的特征数相同。为了减少参数并且增强泛化能力,第一个全连接层将参数降维r倍,这里r取值为16,然后经过一个ReLU后再经过一个全连接层升维到原来的维数。第二个全连接层后使用sigmoid激活函数作为阈值门限,得到了一个1×1×C的序列,即每个特征通道的权重。最后将权重直接用乘法叠加到开始的特征通道上,即完成了所有特征通道的权重重标定。
引入SENet的SE-Resnet模块可以简化表示为一个Residual模块下添加了一个SE模块,如图5[12]所示。
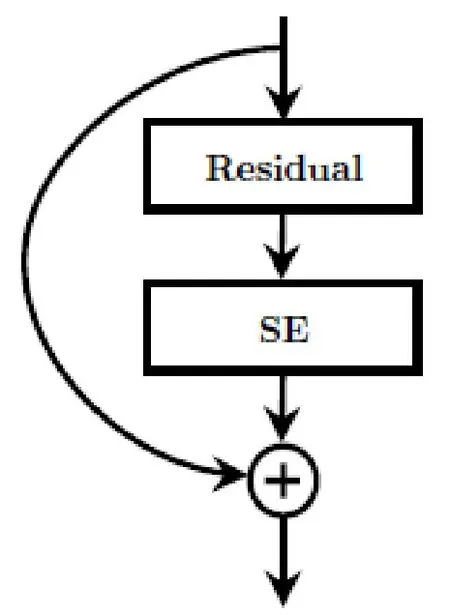
图5 SE-Resnet模块简化示意图 Fig.5 SE-Resnet module simplified diagram
SENet模块的激活操作的实现中包含两个全连接层,全连接层的参数量相对其他类型的网络层是最大的,因此添加过多的SENet模块将会导致网络参数规模增大,影响目标检测算法的时间效率。根据原作者的经验,添加在网络末端的SE模块对准确率的影响较小,所以末端的几个Residual块不做处理。YOLOv3包含23个Residual块,从减少模型参数量优化避免增加太多算法运行时间的角度考虑,只对每组卷积和残差层的最后一个残差层进行替换,于是改进后的网络结构如图6所示。
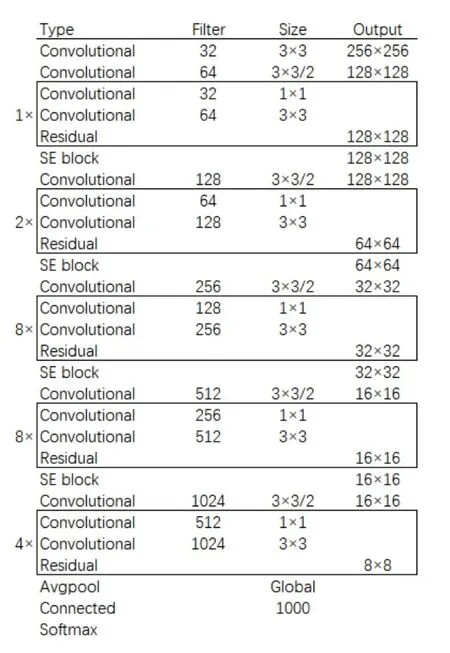
图6 改进后网络结构 Fig.6 Network structure after improvement
3 实验过程与结果
3.1 数据收集与处理
实验使用焦距20 mm,波段8~12 μm的长波红外热像仪在50 m的高度拍摄了570张单场景红外行人图像。数据拍摄地点在城市中,拍摄目标主体为从楼顶斜视的城市街道,因此数据集中的场景包含城市道路、建筑物、树木等,背景非常复杂。数据集图像中行人目标很小,在图像中的矩形框大小约为13×8个像素,形态特征较少,用传统特征提取方法将很难提取到有效特征,适合用深度学习方法进行目标检测。
数据中只对行人的目标进行了标注,为了能够提升目标检测的性能,提高泛化性,对一部分受到遮挡的行人目标也进行了标注,希望最后得到的模型能够应对一定程度的目标遮挡。由于图像数量较少,考虑对数据集进行数据增强,YOLOv3在训练过程中有多尺度训练的部分,因此数据增强时不需要做尺度缩放,只使用翻转、加噪、随机光照改变等方法,数据增强后得到2280张图像,采集的红外图示例如图7。

图7 采集的红外图像示例Fig.7 Infrared image example collected for experiment
3.2 模型训练
实验平台使用Linux 16.04 LTS系统,CPU i7 8700 k,GPU为NVIDIA GTX1080 8 G,16 G内存。模型训练主要思路是使用已经在大规模数据集上训练好的模型进行fine-tune,在新数据集上继续训练模型。以YOLO原作者在COCO和VOC上训练好的darknet53模型为基础模型,随机选取自建数据集中的1710张图像作为训练集,其余的570张图像为测试集,训练时初始学习率为0.001,衰减系数为0.0005,对于YOLOv3原网络和改进后的网络都进行训练。
3.3 实验结果
由于本次实验中的数据集只有一类目标,采用召回率(recall)和准确率(precision)作为模型的评价标准,其中准确率为网络预测的所有目标中真目标的比例,表征此网络的分类准确率;召回率为网络预测成功的真目标数与实际存在的真目标数的比值,表征此网络的查全率;以目标交并比(IOU,intersection over union)大于0.5为真目标,IOU为预测目标矩形框和目标标签矩形重叠区域面积占二者并集面积的比值。
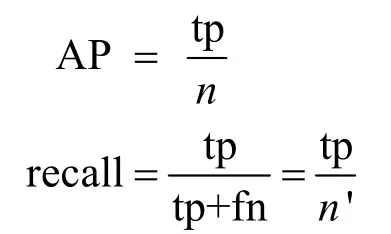
式中:tp为网络预测出的真目标数;fn为未能成功预测出的真目标数;n为预测的总数;n′为标签目标数。
在训练好的模型上,用570张图像的测试集进行验证。YOLOv3原网络和改进后网络的准确率和召回率对比如表1所示。
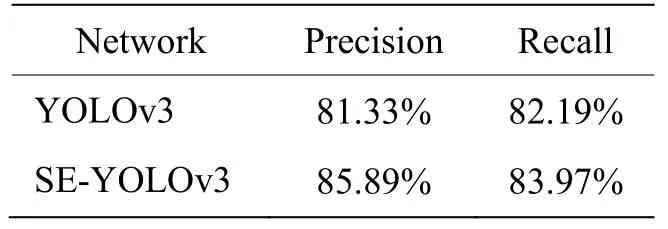
表1 主要指标对比 Table 1 Comparison of primary specifications
网络在测试图像中的检测效果如图8所示,可以看到红外图像中黯淡模糊的行人目标能够被检测出来,并且部分被遮挡的目标也有较好的检测能力。
从表1可以看到改进后的网络在两项主要指标上都优于原网络,由于SENet的特征权重重标定,增强了重要特征对分类结果的影响,抑制了非重要特征,使网络的特征描述能力进一步增强,最终令网络的召回率和准确率都得到提升。算法运行时间方面,在GTX1080显卡,CUDA9.0运行环境下,570张测试图片YOLOv3计算了10.77 s,SE-YOLOv3计算了11.15 s,都在50 fps以上,网络增加的SE block带来的额外计算时间较少。


图8 检测结果示例Fig.8 Detect results of samples
4 结语
文章研究了当前主流的深度学习目标检测方法,以YOLOv3网络为基础,学习了SENet对特征进行权重重标定的思路,将SE block引入到YOLOv3网络中,得到了召回率和准确率都更高的新网络,并且保持了原有的高实时性。对实际收集的复杂红外图像进行试验,新网络取得了良好的行人小目标检测效果。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
健康之家(2021年19期)2021-05-23 11:17:39
金桥(2021年4期)2021-05-21 08:19:20
医学食疗与健康(2021年27期)2021-05-13 18:46:23
意林(2021年5期)2021-04-18 12:21:17
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年7期)2019-04-25 13:17:14
扬子江(2019年1期)2019-03-08 02:52:34
中国交通信息化(2018年5期)2018-08-21 03:37:40
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
