
基于知识图谱和协同过滤的电影推荐算法研究*
2020-05-04 07:05:34成振华
计算机工程与科学 2020年4期
袁 泉,成振华,江 洋
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学通信新技术应用研究中心,重庆 400065;3.重庆信科设计有限公司,重庆 401121)
1 引言
数据冗余是大数据时代的常见问题。协同过滤推荐系统可以过滤冗余的信息,以帮助人们减轻信息过载带来的负担。协同过滤推荐算法因为具有较高的准确率而被广泛应用于电影、音乐和电子商务等领域。算法的主要依据是假设用户行为习惯相似则他们对相似物品的喜好也相似[1]。例如2个用户在观影偏好上具有相似性,则可以向他们推荐对方未看过的电影。协同过滤推荐算法主要基于用户评级确定用户喜好,用户评级的数据完整性与真实性直接影响推荐的准确率。在实际应用中,协同过滤推荐受到数据稀疏性影响,即用户数量和物品的种类较多,用户对物品的评分较少,大部分物品没有用户的评分记录,则无法计算相似度,或者计算出的相似度精度不高。近年来研究者们提出各种基于协同过滤的改进算法并且取得了良好的效果。文献[2]提出采用矩阵填充的办法来提高评分矩阵密度。文献[3]提出采用矩阵分解的办法降低系统对稀疏性的敏感度。上述方法仅利用了用户对物品评级的信息,忽略了实际中物品之间的属性关系。文献[4]提出将内容与协同过滤的推荐算法相结合,在新闻推荐中表现良好。文献[5]利用知识图谱分析用户喜好原因,理解用户的兴趣点,根据兴趣点向用户推荐他们可能喜欢的物品。文献[6]采用异构网络数据,增加多个信息源,提升了推荐过程中的参考依据。通过观察发现,物品在嵌入知识图谱时2个物品之间可能具有多种关系。例如《终结者》系列电影之间存在着导演、编剧、主演等多个相似关系。基于TransE(Translating Embedding)算法[7]的知识图谱表示模型在计算相似度时只能处理实体间简单的单个关系,并不能真实地反映电影之间的多个关系。TransHR(Translating embedding for Hyper-Relational data)模型[8]将电影间的关系嵌入到关系空间中,可以保留电影间的多关系向量。但是,该算法在表示多关系时增加了时间与空间复杂度。
本文主要贡献如下所示:
(1)提出构建电影领域知识图谱弥补协同过滤推荐算法受到的数据稀疏性干扰问题。
(2)改进了知识图谱算法TransHR,用其取代TransE算法进行知识图谱构建,提升了计算出的电影间的相似度准确率。
(3)将知识图谱相似度与基于用户评分的物品相似度融合,结合SVD分解,提升推荐性能。
2 相关理论
2.1 协同过滤推荐算法
电影推荐中可以使用基于物品的协同过滤ICF(Item Collaborative Filtering),它以用户倾向于喜欢类似的电影为假设,将用户对物品的评分记为1个向量,利用评分向量计算物品间的相似度,推测用户最有可能喜欢的物品。其总体分为3个步骤[9]:
(1)构建评分矩阵。
以通过用户对某一物品进行打分等方式收集用户的观影偏好,用户评分是算法的数据基础。假设系统中有m个用户和n个物品,用U={U1,U2,…,Um}表示用户集合,用I={I1,I2,…,In}表示物品集合。则用户Ux对物品Iy的评分为Sx,y,用矩阵Rm×n表示如式(1)所示:
(1)
(2)计算物品相似度。
物品向量的相似度可以用余弦相似度作为评价标准。将用户对某个物品的评分当成1个m维向量,则某个物品Ii的评分向量为Ii={S1,i,S2,i,…,Sm,i},物品Ij的评分向量为Ij={S1,j,S2,j,…,Sm,j},计算Ii与Ij的余弦相似度:
(2)
其中,Ui和Uj分别表示对电影Ii和电影Ij评分的用户集合,Ui,j表示同时对电影Ii和电影Ij评分的用户集合。式(2)的取值为[0,1]。
余弦相似度在实际中未能考虑用户评分的差异。例如,有些用户给电影评分普遍评分较高,有些用户则普遍给出较低分数。这样用户对于同样评分的电影的喜好实际上并不相同。因此,采用修正的余弦相似度,公式如下所示:
(3)
(3)近邻选择。
近邻选择算法有K近邻选择和阈值法2种,其中K近邻选择算法是将相似度进行排序从而筛选出前K个最相似的物品进行推荐。阈值法是设置阈值T,将相似度高于阈值T的物品列入推荐列表。本文采用K近邻算法作为决策的参考依据。
2.2 知识图谱介绍
知识图谱是谷歌在2012年提出的,最初是为了提高检索的性能。知识图谱将知识信息嵌入到1个低维的图谱当中从而将知识用向量表示,利用知识向量可以进行实体相似度的计算。知识图谱的另一个作用是关系预测。知识图谱可以根据已有的关系数据集快速推断还未标注的实体间的关系,使得相似度计算的结果更加准确。大量的知识库为知识图谱的研究提供了丰富的数据集,常见的有FreeBase[10]、YOGA[11]、Wikidata[12]和DBpedia[13]等。
知识表示的过程是将零散知识嵌入到知识图谱中形成知识向量。知识表示模型主要分为神经网络模型、张量模型和翻译模型。文献[14]引入神经网络非线性模型刻画了实体相关性,但是该模型的计算开销较大。文献[15]介绍了将不同维度中的实体统一在一起的思想,描述了实体之间的关系,称为张量模型。Bordes等[7]受到平移不变性的启发提出了翻译模型TransE。由于基于翻译模型的知识图谱计算量小且能有效地表示语义知识库,因此本文在用户评分数据稀疏时利用知识图谱辅助算出实体间相似度,并应用于协同过滤算法中,以弥补数据稀疏问题。TransE在处理实体间只存在单关系时具有良好的效果,但是当实体间存在多个关系时,由于TransE的实体与关系嵌入在同一个平面内,无法准确反映出实体间的多关系模型,导致相似度计算不准确。本文采用改进的翻译模型TransHR,可以将实体间的多重关系表示出来。
知识图谱由知识三元组头实体h、尾实体t和关系向量r组成。翻译模型TransE将头向量h通过关系向量r映射于尾实体向量t,如图1所示。通过设置三者的值使得三者关系为真时有h+r-t≈0,当三者关系不成立时,其值应当很大。
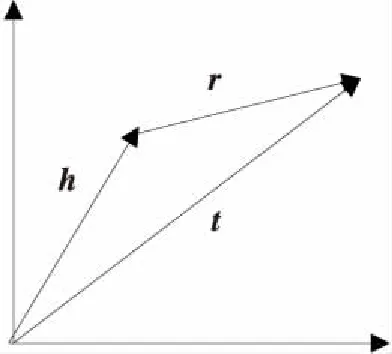
Figure 1 TransE model图1 TransE模型
实际应用中一对实体间可能具有多重关系,具有多个关系的电影应当具有更高的相似度,在推荐时出现在用户列表的可能性应当更高。TransHR的原理如图2所示。

Figure 2 TransHR model图2 TransHR模型
TransHR将头尾实体嵌入一个平面内,与TransE不同的是,TransHR将关系向量嵌入在特定的关系空间当中。当2个实体有v个关系时,第i个关系表示为ri,将所有的关系存在单独的矩阵空间中,记为Mr。则TransHR的关系向量为:
r′(h,t)=riMri,i=1,2,…,v
(4)
通过矩阵空间的关系映射将实体间的多重关系表示在关系矩阵Mri中,则通过映射形成的向量r(h,t)实现了头尾实体的关系链接。则在TransHR模型中头尾实体映射为:
h+r(h,t)≈t
(5)
TransHR表示出每个实体的同时保留了实体间多重关系,在知识图谱中计算电影相似度时可以依据多重关系进而加权计算出电影间的相似度。相较于TransE模型,TransHR提高了计算的相似度准确率。由于TransHR将实体间多个关系存储在矩阵Mri中,使得复杂度提升,因此本文采用对角矩阵Ari代替Mri降低了关系矩阵的复杂度,此时向量映射为:
r(h,t)=riAri,i=1,2,…,v
(6)
3 基于图谱权重的推荐算法
通过知识图谱辅助计算出电影间的相似度,与协同过滤推荐算法结合,可以缓解协同过滤算法数据稀疏性问题。基本原理为:通过融合因子将协同过滤算法得出的推荐结果与基于用户喜好构建的知识图谱得出的推荐结果相融合,作为最终的推荐结果向用户推荐。基于物品协同过滤算法实际是从外部向用户推荐;而基于知识图谱的语义相似度推荐是基于物品内容向用户推荐。
本文提出基于TransHR的知识图谱协同过滤推荐算法TransHR-CF(Translating embedding for Hyper-Relational data Collaborative Filtering),如图3所示,构建电影知识图谱,根据知识图谱计算电影间的语义相似度,形成基于知识图谱的相似矩阵。根据用户评分矩阵计算余弦相似度形成相似度矩阵。最终通过设置融合因子将2个矩阵融合。

Figure 3 TransHR-CF algorithm图3 TransHR-CF算法
3.1 构建语义图谱
在电影领域知识图谱中,实体主要包括片名、影片类型等。所有这些特征之间的关系形成一张电影领域的知识图谱。2部电影间往往存在着相同的演员或者导演等相同关系,如《回到未来》和《回到未来2》之间存在着影片类型、导演、主演等多个相同关系,因此在知识图谱中电影之间相同关系越多,则判定2部电影相似度越高。本文采用改进的TransHR模型,训练损失函数如式(7)所示:
(7)
其中,γ是边缘参数,d(·)为欧氏距离,(h,r,t)为正确的三元组表示,在正确三元组中随机选出1个实体进行替换得到(h′,r′,t′)。如正确三元组为(回到未来,类型,科幻),错误三元组在三者中随机替换1个实体,如(回到未来,类型,惊悚)。
最终通过TransHR模型将电影实体嵌入在一个低维空间中,电影实体间的多重关系存储在关系矩阵Ari中。该方法使得正确的三元组之间距离很近,错误的三元组之间距离很远。当用户给某个电影评分时,与之相似度较高的电影也会被判定为用户可能喜欢的实体类型。
3.2 知识图谱实体相似度
将物品电影嵌入知识图谱,物品Ii用向量表示:
Ii=(E1i,E2i,…,Edi)T
(8)
物品被嵌入成为d维向量,其中Epi为对应第p维度的值。构建知识图谱时采用欧氏距离训练损失函数,所以在计算物品相似度时也采用欧氏距离:
(9)
利用欧氏距离可以计算2个物品的相似度:
(10)
在TransHR构建的知识图谱中,2个实体之间的多关系向量被映射到关系空间中,扩展了关系数量。因此,2个物品之间关系越多,则相似度应该越高。定义C1(Ii,Ij) 函数统计知识图谱中Ii与Ij的直接关系数量,如《回到未来1》与《回到未来2》之间存在导演、主演1、主演2、影片类型等4种相同的属性关系,则它们的C1(Ii,Ij)=4。同理定义C2(Ii,Ij)为Ii与Ij间隔度为1的关系数量。Ii与Ij在多步关系权重下的相似度为:
simg(Ii,Ij)=
(11)
其中,x<1为权重因子,表征多步关系之间的重要程度。在用户选择时更倾向于直接关系,因此直接关系的权重值应当比间接关系的权重值大,设置直接关系权重为x,间接关系权重为x2,从而获得更好的相似度表示效果,这也符合预期。
根据图3的流程,按照知识图谱求得电影相似度后,可以生成1个电影相似性矩阵。如表1所示。
表1所示为电影内部的语义相似度矩阵,其中,aij为2部电影实体间的相似度。在推荐过程中不会向用户推荐已经选过的电影,因此对角线元素直接设置为0,从而避免向用户重复推荐已经观看过的电影。

Table 1 Movies similarity matrix表1 电影相似度矩阵
3.3 2种相似度的融合
基于用户评分矩阵计算出相似电影并且向用户推荐。但是,协同过滤算法在实际中存在的数据稀疏性问题会导致计算出的电影相似度很低。因此,本文结合知识图谱计算出的相似度与协同过滤算法计算出的相似度作为推荐依据。步骤如下所示:
(1)将电影领域本身的语义知识通过TransHR模型学习得到电影领域的实体表达,并计算相似度。
(2)通过用户评分矩阵计算2部电影的余弦相似度,值越大,相似度越高。
(3)将知识图谱计算出的相似度与协同过滤算法计算出的电影相似度进行匹配融合。
(4)通过最终预测的评分选出K个预测评分最高的结果。
根据式(3)与式(11)得TransHR-CF算法融合后的结果:
sim(Ii,Ij)=simc(Ii,Ij)+simg(Ii,Ij)=
(12)
其中,x<1,式中第1项为协同过滤算法计算得出的相似度,第2项为知识图谱计算得出的相似度。
3.4 预测用户评分
预测用户对电影的评分,根据预测评分可以形成推荐列表。通过引入知识图谱计算出的电影相似度可以更准确地估算出用户对未评分电影的评分。用Pui表示用户Uu对物品Ii的评分。Pui的计算公式如下所示:
(13)
其中,sim(Ii,Ij)是电影Ii与电影Ij的相似度,Su,j表示用户对电影Ij的评分,N(u) 表示用户Uu评分过的电影集合,S(i,k)表示前k个与Ii最相似的电影。用户对电影Ij的评分越高,同时电影Ii与Ij相似度越高,则Pui的值越大。通过计算每一位用户的未点击电影的Pui形成TOP-K推荐列表。
基于SVD分解的推荐算法在应用中通过降维预测用户评分,实现了高质量的推荐。然而该分解方法要求矩阵本身不能是稀疏的,否则需要对评分矩阵进行填充。传统的SVD分解是填充用户评分的均值,这种方法会使得预测结果产生偏差。尤其是当矩阵非常稀疏时,其预测结果是非常不准确的。结合知识图谱计算出电影间相似度,预测越相似的电影越容易获得相近的评分,从而对矩阵中用户未评分数据进行填充可以更准确地反映影片实际的得分值。通过填充矩阵计算出用户未观看电影的预测分值,向用户推荐预测分值最高的影片。
本文采用知识图谱辅助计算相似度从而预测用户评分的办法填充用户评分矩阵,结合矩阵分解为用户形成推荐列表。SVD分解如式(14)所示:
Mm×n=UΣVT
(14)
其中,Mm×n是用户评分矩阵;U是m×m阶酉矩阵;Σ是m×n阶对角阵,对角线的值为Mm×n的特征值;VT是n×n阶酉矩阵。通过SVD分解可以实现数据降维,缓解稀疏性问题。
4 实验分析
4.1 数据集
本节对提出的TransHR-CF算法进行实验验证,实验数据集采用MovieLens数据集的数据。其中用户记录有943个,电影数量有1 682部,平均每个用户评价了100多部电影,共有100 000多条评论数,评分在[1,5]。
引用TMDB数据集构建知识图谱数据集,TMDB作为一个影视数据社区有超过15万的使用者,TMDB的数据集可以免费爬取,方便实验验证。通过知识抽取最终得到了电影名、演员、电影种类等在内的11 619个实体,保留了导演关系、编剧关系等在内的25 232个关系。由于一部电影参演人数较多,本文将每部电影演员的实体数量控制为3个,目的是降低知识图谱的构建复杂度。通过影视数据集构建基于TransHR的知识图谱,构建过程如图4所示。

Figure 4 Construction process of knowledge graph图4 知识图谱构建过程
4.2 评价指标
推荐系统中常用的结果分析指标主要有3个:准确率、召回率、平均绝对误差(MAE)。参数含义如表2所示。

Table 2 Parameters表2 参数
召回率:
(15)
准确率:
(16)
召回率给出了推荐给用户的电影与用户所有喜欢的电影的比例。准确率反映了用户的喜好是否被正确预测,即正确向用户推荐喜欢的电影的比例。
平均绝对误差:
(17)
平均绝对误差反映实际预测误差的大小。其中|M|表示预测项目集合的大小,fi表示物品的真实评分值,yi表示填充的预测值。MAE越小说明推荐越准确。
4.3 融合因子的设定
为了取得最佳推荐效果,本文提出将基于物品评分的相似度与知识图谱相似度通过融合因子x融合,x取值从0到1递增,每次步长0.1,做11次实验,验证召回率和准确率。每次实验做10次并取平均值。结果如图5和图6所示。

Figure 5 Recall result图5 召回率结果

Figure 6 Precision result图6 准确率结果
从图5和图6可以看出,随着融合因子x的增大,召回率和准确率都有所改善,在0.6时性能最好。当x为0时,表示相似度完全由用户评分矩阵决定。
4.4 算法比较
与传统协同过滤算法和基于TransE翻译模型的协同过滤算法进行实验对比。此处选取使召回率和准确率最高的融合因子x=0.6,验证不同近邻数下的召回率和准确率。近邻数K分别选择50,70,100,120实验10次并取平均值。由图7和图8可以看出,本文算法在召回率和准确率指标上都有提升。说明利用了影视实体之间的关系计算影视相似度更加准确。

Figure 7 Recall under different neighbor numbers图7 不同近邻数下的召回率

Figure 8 Accuracy under different neighbor numbers图8 不同近邻数下的准确率
与基于传统知识图谱的协同过滤算法相比,当近邻数为100时,基于TransHR模型的协同过滤算法在召回率上提升了约5%,准确率提升了约10%,弥补了协同过滤算法的不足以及TransE嵌入过程中的精度不高问题。这说明本文算法的有效性。
为了进一步验证本文算法的准确度,结合矩阵分解比较了MAE值。将式(13)计算出的预测评分填充矩阵,与基于TransE的知识图谱计算出的用户评分和基于用户均值填充的矩阵,做SVD比较。根据式(13)选取知识图谱中K个与预测电影最相似的电影时,推荐性能会随着近邻数K的不同而不同。分别取近邻数K为10,15,20,30,验证MAE值,结果如图9所示。

Figure 9 MAE under different neighbor numbers图9 不同近邻数K的MAE值
传统SVD分解采用均值填充的办法,与知识图谱中的近邻数K值无关,因此不会随K值变化而变化。基于TransE与TransHR的矩阵分解的MAE值在近邻数取20时效果最好,其中基于TransHR相似度融合的SVD分解推荐优于传统SVD与基于TransE的推荐。这说明了本文利用TransHR进行相似度融合的优越性。
5 结束语
本文改进了基于知识图谱的协同过滤推荐算法中使用的表示学习算法,在影视推荐过程中更充分地考虑了影视作品间的多重关系属性。通过将电影间的多关系嵌入在一个单独的关系矩阵中,使得TransHR模型可以构建多关系模型,从而改进了电影间的语义相似度,优化了推荐结果。结合SVD分解的推荐结果也比传统的SVD分解推荐结果更好。本文采用的TransHR模型在推理和表示过程中只能表示出单步相邻的电影实体,不能推理出电影实体之间存在的多步关系。今后将尝试引入多步关系推理算法挖掘更多电影信息用于相似度计算。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少先队活动(2020年12期)2021-01-14 01:47:40
中国外汇(2019年18期)2019-11-25 01:41:54
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
哲学评论(2017年1期)2017-07-31 18:04:00
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
领导科学论坛(2016年9期)2016-06-05 14:59:58
