
基于多元数据融合的课堂表现智能检测系统设计
2020-04-30 06:49李雨峤
无线互联科技 2020年6期
关键词:人脸检测
李雨峤

摘 要:为了评估学生的上课行为,文章采用最新的头部姿态估计技术。此项技术能够捕捉当前人头部所做的各种动作与角度,例如低头、转头、仰头等。低头是大多数学生课堂上使用手机的惯用姿势,可以利用此项技术来监测其头部姿态从而进行评估。考虑到人脸检测的定位准确度问题,以及学生低头的动作不一定是使用手机,文章同时引入了无线信号侦测技术,捕获并检测当前教室里由于学生使用手机造成信号频繁收发的终端位置,与人脸检测的定位相结合,交叉定位,从而获得更精准的定位效果。
关键词:人脸检测;头部姿态估计;无线信号侦测
本项目考虑到课堂使用情景,因此拟将使用便捷、功能齐全的Jetson TX2开发板作为主要开发平台。人脸检测方面,为了提高识别效率与准确率,使用Dlib库的机器学习算法与库,实现基于深度学习的人脸检测功能。采样方面,文章使用了ZED双目摄像头,其视角较广、分辨率高,同时有着景深探测的功能。无线信号侦测方面,使用无线网卡与天线结合来实现信号数据抓包,并通过tcpdump和wireshark进行解析[1]。
1 基于深度学习和 CNN 算法的人脸检测
关于人脸检测,目前有许多经典算法,其中比较传统的例如特征脸法,其原理是先将图像灰度化,然后将图像每行首尾相接拉成列向量。为了降低运算量,需要使用PCA降维,并使用分类器进行分类,可以使用 KNN,SVM、神经网络等。其中卷积神经网络(Convolutional Neural Networks,CNN)是近几年兴起的神经网络,可以实现图片的特征提取和降维,并且由于使用到了GPU进行辅助计算,效果比传统的检测算法要好得多[2]。
1.1 训练模型
卷积神经网络的训练过程分为两个阶段。第一个阶段是数据由低层次向高层次传播的阶段,即前向传播阶段。另一个阶段是,当前向传播得出的结果与预期不相符时,将误差从高层次向底层次进行传播训练的阶段,即反向传播阶段。训练过程为:
(1)网络进行权值的初始化。
(2)输入数据经过卷积层、下采样层、全连接层的前向传播得到输出值。
(3)求出网络的输出值与目标值之间的误差。
(4)当误差大于期望值时,将误差传回网络中,依次求得全连接层、下采样层、卷积层的误差。各层的误差可以理解为对于网络的总误差,网络应承担多少;当误差等于或小于期望值时,结束训练。
(5)根据求得误差进行权值更新,然后进入第二步。
1.2 检测人脸
得到训练后的人脸模型后,使用分类器将图片或者视频流输入并得到识别后的输出。文章采用了Dlib库的框架和算法进行检测,首先,将摄像头捕获的图片流进行预处理,例如裁剪、灰度化;其次,使用dlib.cnn_face_detection_model方法进行识别处理。一旦图片中包含条件足够识别出的人脸,该方法会返回人脸矩形框架的坐标矩阵,分别对应人脸框架的左上角、右下角,并在图片中将人脸框出[3]。
一开始采用的并非CNN算法,而是使用的传统特征提取,虽然也能做到检测人脸,但是当达到一定距离,人脸较小,或者光线不够充足时,检测效果便会大打折扣。而使用了CNN算法之后,即使是较为黑暗的光线环境或者较远的距离,依然能够做到准确识别[4]。
2 头部姿态估计
头部姿态估计(Head pose Estimation,HPE)是通过一幅面部图像来获得头部姿态角的算法,跟飞机飞行的原理类似,即计算pitch,yaw和roll这3个欧拉角,学名分别为俯仰角、偏航角和滚转角,其算法步骤一般为:
(1)2D 人脸关键点检测。
(2)3D 人脸模型匹配。
(3)求解 3D 点和对应 2D 点的转换关系。
(4)根据旋转矩阵求解欧拉角。
2.1 2D人脸关键点检测
根據前一项人脸检测的结果,在获得了人脸的矩形区域后,便对其内的人脸进行关键点检测。检测过程同样采用了Dlib库的分类算法,引入了经典的人脸68特征点模型("shape_predictor_68_face_landmarks.dat")进行匹配。为了简化算法并节约资源,本文只取以下几个特征点:鼻尖、双颊、左眼角、右眼角、左嘴角、右嘴角,便足以表示一个脸的特征。
2.2 3D人脸模型匹配
Dlib算法中内置了一个3D人脸模型,把关键点的空间位置全部标记出来,充当真实脸的空间位置。
然而,一个3D模型不能表示所有的人脸,即对所有人采用同一个3D人脸模型并不精确,因此,引入三维形变模型(3D Morphable Model,3DMM),对不同人可以拟出相应的3D脸模型,可以使得关键空间点的位置更加精确,但代价是计算量变大。
2.3 关系转化与求解欧拉角
一个物体对于相机的姿态可以用两个矩阵表示:平移矩阵和旋转矩阵。其中平移矩阵是指物体相对于相机的空间位置关系矩阵,用T表示;旋转矩阵指物体相对于相机的空间姿态关系矩阵,用 R 表示。
为了使现实空间的坐标能够和图片中像素的坐标形成映射,需要引入世界坐标系(UVW)、相机坐标系(XYZ)、图像中心坐标系(uv)和像素坐标系(xy),转换关系如下。
世界坐标系到相机坐标系:
相机坐标系到像素坐标系:
因此,像素坐标系和世界坐标系的关系如下:
如此,得到世界坐标系中点的位置、像素坐标位置和相机参数便可以知道旋转和平移矩阵。
求解欧拉角:
这3个角是文章提到的俯仰角、偏航角和滚转角了,用 y,x,z 来表示。只要取其中的y,即俯仰角,便可判断学生的抬头低头姿态。
3 基于双目摄像头的空间测距
要获取目标学生的位置,需要得到该对象相对于摄像头的角度和距离。在距离方面,普通的摄像头无法获取二維图像中对象的景深距离,因此使用了ZED双目景深摄像头来完成这一功能。双目摄像头的原理与人眼相似,通过对两幅图像视差的计算,直接对前方景物(图像所拍摄到的范围)进行距离测量,而无需判断前方出现的是什么类型的障碍物。
ZED双目摄像头的强大之处在于可以自己计算拍摄得到景物的景深3D点云图,便可以凭借景深图获取到图像中任意一点的深度Z。
对于空间中的任意一点,要想知道其相对于原点,也就是相机的距离,需要得知其3个维度x,y和z的值。在人脸检测中已经获得了人脸矩形框的坐标值,因此将矩形框的中点坐标x和y带入并赋值到3D点云图中,通过公式sqrt(x2+y2+z2)便能求出空间点,也就是某学生的距离相机的距离。
4 无线信号侦测
无线信号侦测与网络定位模块主要使用了接收信号强度(Received Signal Strength Indicator,RSSI)信号定位技术,通过采集空间中的电子足迹,给出移动设备的方位角,从而实现视觉—电子信号双重定位,提高无线定位的准确性。
电子足迹即移动设备的介质访问控制(Media Access Control,MAC)地址、IP等,采集空间中的电子足迹,主要通过网卡抓包解析报文内容,处理电子信号,获得报文中的信号强度,从而定位可能的移动设备相对于天线的角度,将该结果返回给系统,系统将该结果与视觉信号定位结果做一个匹配,检查该方向上是否有低头状态的学生,与头部姿态估计模块的结果相结合,得出最终分析结论。
为了多方位获取不同方向的电子信号,文章将天线装在了一个水平270°旋转的简易3D云台上,让其以匀速周期性摆动,实现多方位信号的捕获。
RSSI是无线发送层的可选部分,用来判定链接质量,以及是否增大广播发送强度。定向天线在不同方向上检测到某个IP信号的RSSI强度是不同的,当天线未对准IP所在位置的时候,天线所检测到的信号强度是微弱的,可是当天线对准IP所在位置时,所检测到的RSSI强度会有一个大幅提升,可以通过接收到的信号强弱测定信号点与接收点的相对角度,进而根据相应数据进行定位计算。
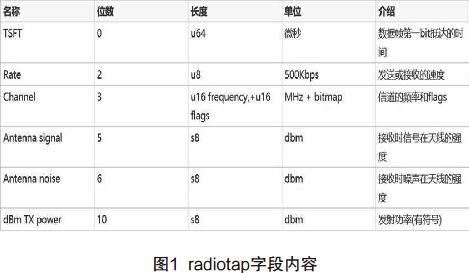
RSSI信息储存在数据帧前面一个叫radiotap的部分,包含了如信号强度、频率等信息,是ieee802.11 的标准。内容如图1所示。
其中,Antenna signal是所需要使用的字段。通过使用定向天线对不同方向抓包,考虑到所测试空间之外的电子信号的影响,会过滤掉信号极其微弱的数据包,然后对比相同MAC地址报文的信号强度,就可以找到信号强度最大的报文,从而依据抓包的时间得到天线抓到信号强度最大包的角度。说明这个角度方向上有一个移动设备正在频繁使用网络,达到文章的目的。具体的流程如下。
首先,将无线网卡设置成monitor模式,使用iwconfig命令:
# iw wlan0 interface add mon0 type monitor
添加一个别名mon0,设置为monitor模式,并用# ifconfig mon0 up 启用mon0进行网络监听。
其次,启动旋转云台使得定向天线开始旋转,记录启动时间,同时开始使用tcpdump工具进行抓包,并保存到一个CAP文件中。在存储的文件中包含了抓到的每一个包的时间、信号强度、MAC地址等信息。之后使用Python的scapy库读取文件进行数据包的解析,将需要的数据提取出来并且进行筛选分析,最后得出有频繁报文交换的角度,和头部姿态估计模块进行整合。
5 系统构成以及初步效果
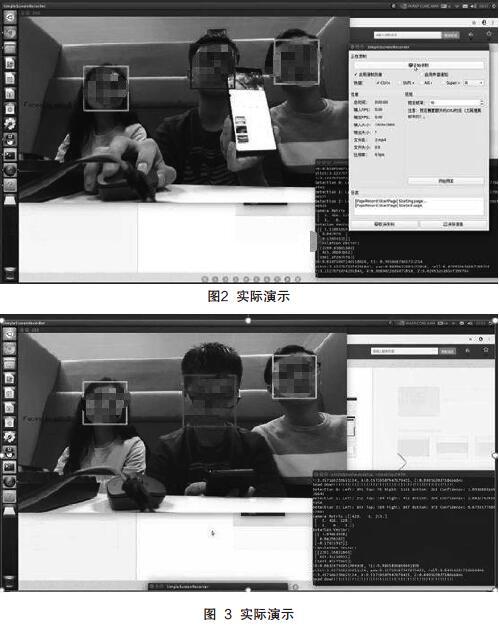
系统的实现分为以下几个步骤:(1)云台带动定向天线做180°周期性转动。(2)天线和无线网卡检测方向上信号强度高的报文并捕获。(3)统返回信号较强的方向角度。(4)摄像头捕获当前课堂视频并进行人脸检测。(5)对每一个人脸求出其中心点的距离。(6)求出离 S3 返回方向最近的目标人脸。(7)对该目标人脸进行头部姿态估计,如果检测到低头则判断为使用电子设备。初步实现效果如图2所示。
对于每一位学生,系统对其划分以下状态:
(1)正常抬头,身边没有移动终端收发信号(标绿)。
(2)低头,身边没有移动终端收发信号(标蓝)。
(3)正常抬头,身边有移动终端收发信号(标蓝)。
(4)低头,身边有移动终端收发信号(标红)。
假设图2中3人处于一个课堂,系统捕捉到了3人的人脸以及距离摄像头的位置信息。而只有中间的人手持电子设备并且在使用移动设备收发信号,但是没有低头,因此系统将此人标蓝。再如图3所示,中间人低头并且被系统检测到之后,符合使用“移动终端+低头”这一条件组合,因此,判定其为在课堂上使用手机终端信息的行为,将其标红。
6 结语
本系统能够基本实现对学生在小型课堂上是否使用智能终端设备状态的判断,但是受限于设备性能,最多只能容纳10~20人,识别的最远距离为7~10 m,且准确率受环境光照影响较大。此外,即使判断出学生在课堂上低头使用移动终端,也不能立刻判断其行为属于开小差,也有可能是查询资料等,更加细致的判断则需要进一步的研究。
[参考文献]
[1]PATACCHIOLA M,CANGELOSI A.Head pose estimation in the wild using convolutional neural networks and adaptive gradient methods[J].Pattern Recognition,2017(33):71.
[2]劉翠玲,王美琴,高振明.基于Linux的无线网络监听方法与实现[J].山东大学学报(理学版),2004(5):90-94.
[3]WANG J,CHEN Y,FU X,et al.3DLoc:Three dimensional wireless localization toolkit[C].Chengdu:IEEE International Conference on Distributed Computing Systems,2010.
[4]ZHANG B,TENG J,ZHU J,et al.EV-Loc:Integrating electronic and visual signals for accurate localization[C].South Carolina:Acm Mobihoc.IEEE Press,2012.
Designed on intelligent detection system for classroom
perfprmance based on multivariate data fusion
Li Yuqiao
(Southeast University, Nanjing 211189, China )
Abstract:In order to assess students'behavior in class, this paper used the latest head posture estimation techniques. This technology can capture the current persons head to do a variety of movements and angles, such as bow, turn, head, etc. Since lowering the head is the dominant posture of most students in class, can use this technology to monitor their head posture for evaluation. Considering the positioning accuracy of face detection problem, as well as the students action is not necessarily the bowed their heads and the use of mobile phones, this paper also introduced the wireless signal detection technology, capture and detection current caused by students use mobile phones in the classroom signal frequency transceiver terminal location, combined with the positioning of the face detection, cross positioning, in order to gain more accurate positioning results.
Key words:face-detection; head pose estimation; wireless signal detection
