
基于语音识别的课堂笔记系统设计与实现
2020-04-29 01:26薛辉
商洛学院学报 2020年2期
薛辉
(商洛学院教务处,陕西商洛 726000)
课堂笔记是学生学习过程中的重要资料,许多学生在上课时一边听讲一边记笔记。由于人写字的速度比说话的速度慢,所以学生记笔记的速度往往跟不上教师讲课的速度,造成笔记内容不完整,另外,一边听讲一边记笔记也影响学生对讲课内容的理解和吸收。如今语音识别技术已经比较成熟,已经有许多基于语音识别技术的软件被开发出来,但应用于课堂笔记的系统还很少,基于语音识别技术自动生成课堂笔记[1],可以把学生从记笔记中解放出来,使学生专注于课堂听讲,课后对自动生成的笔记稍加整理即可,能达到事半功倍的效果[2]。
1 语音识别技术
语音识别技术是人工智能的一个分支,经过多年的发展,如今已经比较成熟[3]。语音识别技术的原理如图1 所示。语音信号经过去噪音、端点检测等预处理之后,提取它的声学特征[4],经过训练生成模板库,识别的时候将需要识别的语音的特征与模板库进行匹配,分析出语音对应的文字,然后经过后处理,输出最终的识别结果[5]。

图1 语音识别技术的原理
2 语音识别关键技术
2.1 语音识别技术的选取
如今,谷歌、百度、讯飞等公司都研究了自己的语音识别技术,其中讯飞公司的语音识别技术在中文语音识别领域达到了世界领先的水平[6],因此本文应用讯飞的语音识别技术实现课堂笔记系统。
讯飞的语音识别技术分为语音听写、语音转写、语音唤醒和离线命令词识别等。语音听写是基于语言处理技术,将语音音频转换为文本的技术,适合于少量语句的识别。语音转写可以将连续的音频流识别出来,输出相应的文字,适合于连续语句的识别。语音唤醒是识别音频中特定的词语,唤醒程序或机器,执行下一步动作。离线命令词识别是根据语法规则,将符合语法的自然语言转换为文本输出。记笔记需要连续识别语音流,因此选择语音转写技术比较合适。讯飞的语音转写技术又分为非实时转写和实时转写,非实时转写是先录制音频,录完之后将音频上传到服务器转换为文字,而实时转写是一边录制一边转换,语音录制完之后文字也就输出了。为了方便用户使用,本系统采用实时语音转写技术。
2.2 实时语音转写的流程
讯飞的实时语音转写是基于深度卷积神经网络技术[7],通过WebSocket 协议建立客户端与服务器端的长连接,将连续的语音内容即时上传,服务器端实时进行语音识别,并返回对应的文字信息。
在实时语音转写中,用户的客户端与讯飞服务器端的交互可以分为握手阶段和实时通信阶段,如图2 所示,在握手阶段建立客户端与服务器端的长连接,在实时通信阶段将语音上传到服务器端进行识别。
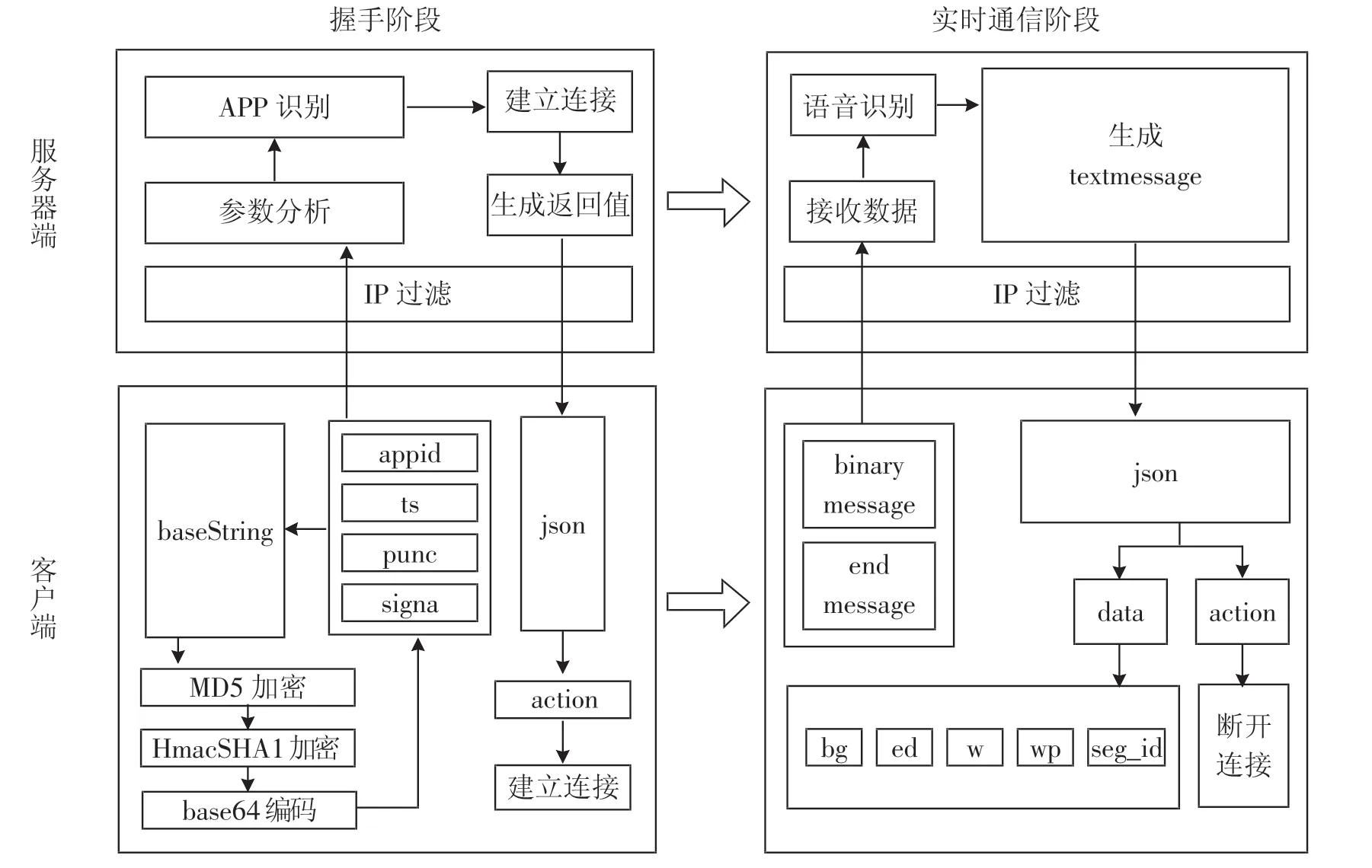
图2 实时语音转写的流程图
2.2.1 握手阶段
1)客户端用appid 和当前时间戳ts 组成base-String,其中appid 是讯飞开放平台的应用ID,在注册应用时由平台分配。
2)对组成的baseString 进行 MD5 加密。
3)以apiKey 为密钥,在MD5 加密的基础上再进行HmacSHA1 加密,其中apiKey 是接口密钥,在应用中添加实时语音转写服务时会自动生成。
4)对加密后的字符串进行base64 编码,形成signa,以方便网络传输。
5)将 appid、ts、signa 和 punc 作为参数传递给服务器端。
6)服务器端对客户端的IP 地址进行验证和过滤,只接收来自合法IP 地址的客户端传递的参数。
7)服务器端根据接收到的参数识别APP,建立与客户端的连接并生成json 格式的返回值。
8)客户端接收服务器端返回的json 格式字符串,从json 字符串中分离出action,action 的值为“started”说明握手成功,连接建立。
2.2.2 实时通信阶段
1)客户端录制pcm 格式的音频。
2)将音频数据以二进制的形式不断上传给服务器,每40 ms 发送1280 字节。
3)服务器端验证客户端的IP 地址,只接收合法客户端上传的数据。
4)服务器端对接收到的数据进行语音识别,并连续生成json 格式的text message。
5)客户端接收服务器端返回的json 格式字符串,从中分离出action。
6)如果 action 的值为“error”表示发生错误,需要按错误码排除错误。
7)如果 action 的值为“result”,则从 json 字符串中分离出data。
8)从data 中分离出识别结果,将结果按seg_id的顺序连成语句。
2.3 识别结果检测
服务器端将语音识别的结果以json 格式写在 text message 里,包含 5 个参数,action、code、desc、sid 和 data,其中 action 是结果标识,用来区分握手、结果和异常;code 是错误码,指出错误的类型以便于调试;desc 是对结果的文字描述;sid是会话ID,它可以在调试时帮忙追查错误;data是识别的结果字符,其中ws 表示词组,cw 表示中文分词,w 表示单词,通过循环连接可以把词组成短句,把短句连起来形成句子。提取data 中识别结果的关键代码如下:

3 语音识别的课堂笔记系统的设计
3.1 课堂笔记系统的设计
在课堂上听课时,可以使用手机作为语音识别的客户端,通过手机录音并上传到服务器端,把语音转换为文字并生成笔记,课后对生成的笔记稍加整理即可[8]。
系统的功能模块如图3 所示,主要分为采集模块、语音转换模块和编辑模块三部分。采集模块通过调用收音机录制教师讲课的声音,通过调用照相机拍摄教师讲课过程中的一些图片。语音转换模块包括语音上传、数据接收和结果转换三个功能,其中语音上传功能把录制的音频上传给服务器,服务器返回的信息通过数据接收功能来接收,然后通过结果转换功能把数据转换为文字。转换的结果可以在编辑模块适当排版、修改、插入图片等,最终完成笔记的记录[9]。
3.2 课堂笔记系统中关键技术的实现
本系统基于Andriod 平台开发,实现的关键是保障手机端与服务器端进行稳定的WebSocket 通信[10]。目前,已经有一些成熟的框架支持在Android 平台使用Websocket 协议,其中,Java-WebSocket 是一个优秀的开源框架,本文使用此框架来实现手机端与服务器端的WebSocket通信。
1)连接前准备:建立WebSocket 连接前应先判断当前是否可以连接,比如当前网络是否可用,用户是否登陆,当前是不是已经处于连接状态等,条件都满足了才可以发起连接。此外,还要准备好连接的地址。讯飞的语音实时转写的服务器地址是固定的,因此可以将该url 保存起来,APP 启动的时候连接该地址,并且在APP 内部保存一个WebSocket 状态,发送请求和需要重新连接的时候可以使用该状态。
2)建立连接:建立连接时先在项目的build.gradle 中加入Java-WebSocket,然后加上网络权限,再新建一个继承WebSocketClient 的客户端类,实现它的四个抽象方法和构造函数,用URI.create()方法给它传入讯飞服务器的地址和appid、ts、signa 和punc 四个参数,然后进行初始化,接下来就可以进行连接了。连接时可以使用connect()方法或connectBlocking()方法,这里选用connectBlocking()方法,因为 connectBlocking()方法比connect()方法多了一个等待,会先连接再发送。当看到客户端执行了onOpen()方法,就表示已经建立好了Websocket 连接。
3)发送消息:发送消息时,使用send()方法把音频文件用RandomAccessFile 类以二进制流的方式发送给服务器端,每隔40 ms 发送一次数据,每次发送1280 字节,不能发送过快,发送过快可能导致引擎出错。音频结束时给服务器端发送end 值为“true”的消息,表示上传结束。
4)接收消息:接收消息时,使用客户端类的onMessage()方法。为了使接收到的消息处理起来方便,可以在初始化时重写onMessage()方法。当连接成功建立时,在onMessage()方法中接收到的action 的值为“started”;当接收到语音转写的结果时,在onMessage()方法中接收到的action 的值为“result”,data 的值为转写结果的 json 字符串;如果在onMessage()方法中接收到的action 的值为“error”,说明发生异常,需要查看错误码查找问题并进行调试。
5)失败重连:建立连接有时会失败,如果接收到连接失败的消息,就需要重连;此外,如果网络状态改变,比如手机信号从wifi 改变为4G,连接会断开,也需要重连;当应用回到前台的时候,如果连接断开了,也需要重连;还有连续多次心跳检测失败的时候,也需要重连。为了取得较好的重连效果,可以定义一个重连间隔时间t,令t 等于最小重连时间间隔最小值(min),当重连次数n≤3 时,每隔 t 时间重连一次,当 n>3 时,令 t=min(n-2),当t 大于最大重连时间间隔最大值(max)时放弃重连。
4 系统测试
经测试,在网络稳定的情况下,该系统能够连续识别课堂语音,稳定输出教师讲解的文字。讯飞的语音识别准确率是极高的,在该应用中语音识别准确率高低一是取决于教室杂音的大小,二是取决于授课教师的普通话发音是否标准。当接收语音信号的手机附近比较嘈杂时,会降低识别的准确率,如果授课教师的普通话发音不太标准,也会影响识别的准确率。一般来说,在课堂里说话的学生是比较少的,即使说话也是小声说,绝大多数教师的普通话也比较标准,所以这两者的影响都比较小。本研究将本系统在安静的课堂(低噪音)与有学生小声说话的课堂(中等噪音)分别进行了测试,结果如表1 所示。从表1 可见,本系统识别的正确率是比较高的。文科课堂上讲解的几乎是纯语言,识别效果较好,对于理科课堂中讲解的公式、函数等本系统无法识别,可以拍成照片在课后整理笔记时插入。
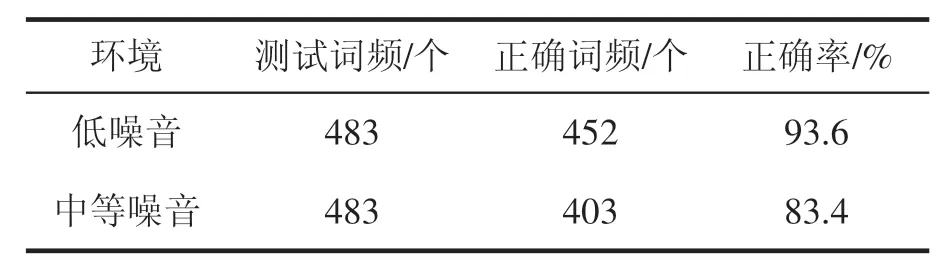
表1 语音识别正确率测试
5 结语
本文基于讯飞语音识别技术,设计并实现了一款课堂笔记系统,可以通过手机自动记录教师讲课的内容,能够把学生从繁琐的记录工作中解放出来,使学生专心进行课堂听讲,课后对自动生成的文字稍微加以整理和编辑即可形成课堂笔记,使用起来比较方便。与其他语音识别系统相比,本系统易于扩展和改进,加以修改也可用于会议记录、演讲记录等其他场合,给人们的学习和工作带来更多的便利。
猜你喜欢
数码世界(2020年11期)2020-11-23
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
电子制作(2017年9期)2017-04-17
小天使·一年级语数英综合(2017年2期)2017-02-16
小天使·一年级语数英综合(2017年2期)2017-02-16
网络空间安全(2016年11期)2017-02-13
软件导刊(2016年11期)2016-12-22
小天使·一年级语数英综合(2016年7期)2016-05-14
人间(2015年8期)2016-01-09
