
结合动态概率定位模型的道路目标检测
2020-04-29 05:30:32左治江郑文远梅天灿
江汉大学学报(自然科学版) 2020年2期
左治江,胡 军,郑文远,梅天灿*
(1.江汉大学 机电与建筑工程学院,湖北 武汉 430056;2.武汉大学 电子信息学院,湖北 武汉 430072)
传统的车辆检测框架主要采用显式模型[1-3]或隐式模型[4-7],其特征表达均属于基于人工设计的特征表达,很难保证车辆检测的鲁棒性和稳定性,而基于神经网络的特征表达则是基于学习的特征表达,在影像分类和检测中表现出了优异的性能[8-10]。针对现有R- CNN 系列[11-13]模型和概率定位模型LocNet[14]的局限,本文提出一种端到端卷积神经网络车辆检测模型HyperLocNet,通过对候选框生成网络RPN[14],改进概率定位模型以及目标识别网络进行联合训练,从而使得各个子任务之间相互协同,提高目标定位和检测的精度,有效解决了目标检测任务中定位信息少、模型不稳定和对小目标检测效果不理想等问题。
1 HyperLocNet车辆检测网络
目标检测包含目标定位和目标识别两个关键问题。针对现有回归定位和概率定位两种定位方法的局限,HyperLocNet 将定位和识别网络融合在同一个网络中共享信息,实现多任务的端到端学习,其模型结构如图1 所示。待检测图像经过基础卷积网络之后得到激活特征图,激活特征图首先进入RPN 网络产生候选框。RPN 网络与后续检测网络共享基础卷积层的权重,包括候选框坐标回归及前景与背景预分类两个分支。根据每个候选框分类得分进行非极大值抑制操作,训练阶段选择前2 000 个候选框对后续的检测网络进行训练,测试阶段选择前300 或者100 个候选框进入检测网络。经过NMS 筛选得到的候选框被映射至激活特征图,经过ROI 池化层输出固定尺寸的特征向量,再进入检测网络进行精细定位并分类。
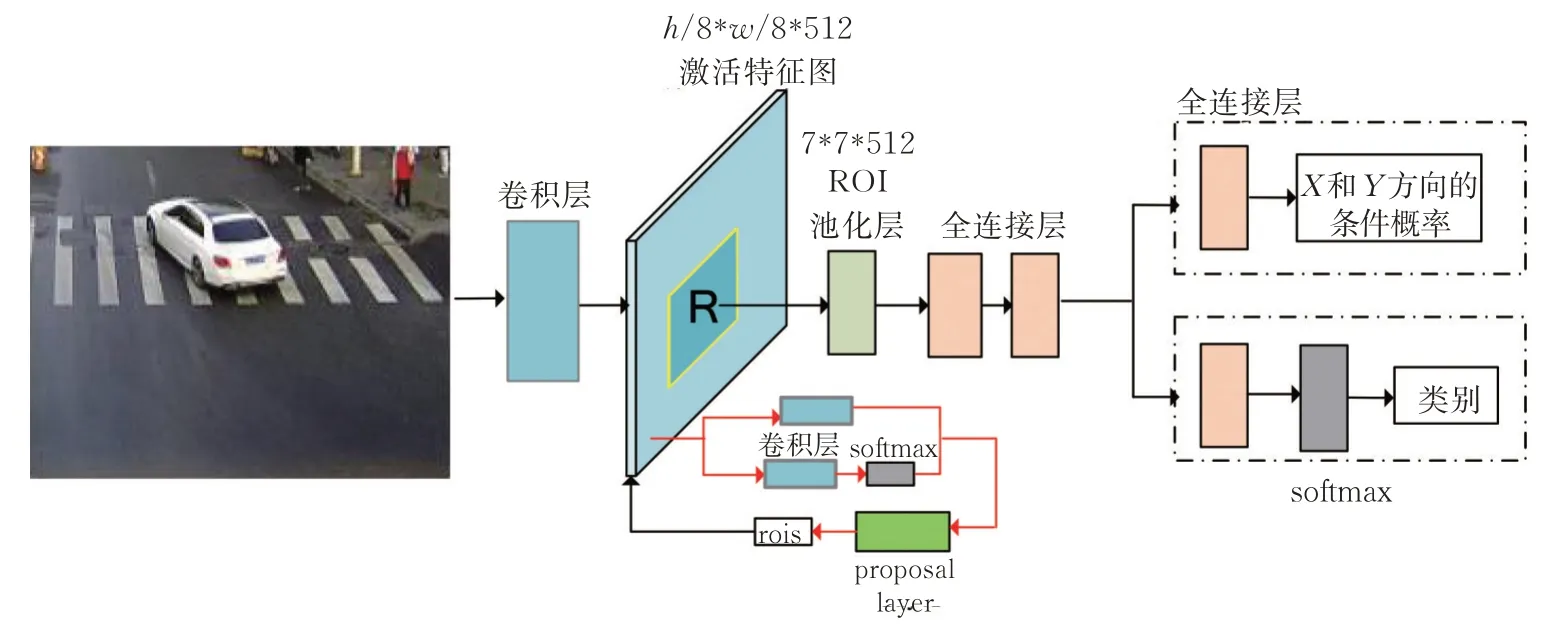
图1 HyperLocNet 检测模型图Fig.1 HyperLocNet detection model
不同于Faster R- CNN 的检测网络和RPN 采用回归模型进行定位,HyperLocNet 采用的定位模块提供了关于目标位置的条件概率,使得模型的稳定性更好,可以处理多个目标彼此接近的情形。对于小目标的检测需要更多的细节语义信息,而深层卷积网络由于池化层的原因,特征图尺寸不断减小,对细节语义信息响应不明显,HyperLocNet 改变VGG16 的pool/4 池化层的参数,使得conv4_3 经过池化层后尺寸不变,即将步长(stride)由16 变为8,特征图尺寸缩小为检测图像的1/8,以适应小目标的检测。
HyperLocNet 在目标定位模块中将X和Y两个分支的任务融合到一个分支中,舍弃了原来模型目标定位模块中的多个卷积层和池化层。通常在卷积网络架构中的连续卷积层之间插入池化层,池化层使用Max Pooling 操作,在保证深度维度不变的前提下,减小了网络特征向量的尺寸,从而保证了特征的尺度和旋转不变性。但是目标定位任务对尺度和旋转非常敏感,尤其是检测小目标时,几个像素的移动就会导致最终的定位结果偏差很大。LocNet 模型中ROI 层之后的池化层可能会丢弃用于精确定位的关键信息,故HyperLocNet 在ROI 层之后直接通过全连接层提取位置信息,即X 和Y 方向的条件概率,从而保证从激活特征图传递出来的信息的完整性。而基础卷积层中的池化层已经可以保证特征的尺度和旋转不变性,使得检测模型的识别模块具有较强的泛化性和稳定性。
在对目标进行精确定位时,LocNet 要求初始候选框包含目标框,当该条件不满足时,其定位误差比回归模型大。图2 是概率定位模型与回归定位模型的比较,其中黑色框为概率模型搜索区域,黄色框为初始候选框,红色框为回归模型定位结果,蓝色框为概率模型定位结果,黄色箭头表示回归模型将候选框逼近目标框的过程。如图2(a)所示,当目标在初始候选框之外时概率模型不能准确定位,而回归定位模型无论初始候选框是否包含目标框,都可以使候选框逼近目标框。如图2(b)所示,当目标处在搜索区域中时,概率模型可以更加精确地定位。针对两种定位模型的特点,HyperLocNet 中RPN 采用回归模型定位生成距离目标比较近的候选框,后续检测网络采用概率模型对RPN 候选框进行精细定位提高定位精度。边界概率和边界内外概率的基本形式为表述为在区域R 内,任意行或者列是第c类的边界的概率(或者在第c类的边界内的概率),图3 是两种概率定位示意图,其中青色框为原始候选框,黄色框为将原始候选框放大一定范围得到的搜索区域,蓝色框为目标实际边界框。图3(a)表示边界内外概率,即搜索区域内的行列在目标边界内的条件概率;图3(b)表示边界概率,即搜索区域内的行列为目标边界的概率。通过试验发现由于本文检测目标为小目标,检测难度大,单独采用边界概率定位效果不佳,而采用组合概率时间开销比较大,定位结果改善不明显,因此本文仅考虑边界内外概率的作用。

图2 概率定位模型与回归定位模型的比较Fig.2 Comparison between probabilistic location model and regression location model
2 HyperLocNet网络损失函数
本文提出的检测网络以VGG16 为基础,以ImageNet 上训练的图像分类模型为初始权重。在概率定位模型中,对于N个候选框训练样本定位损失为
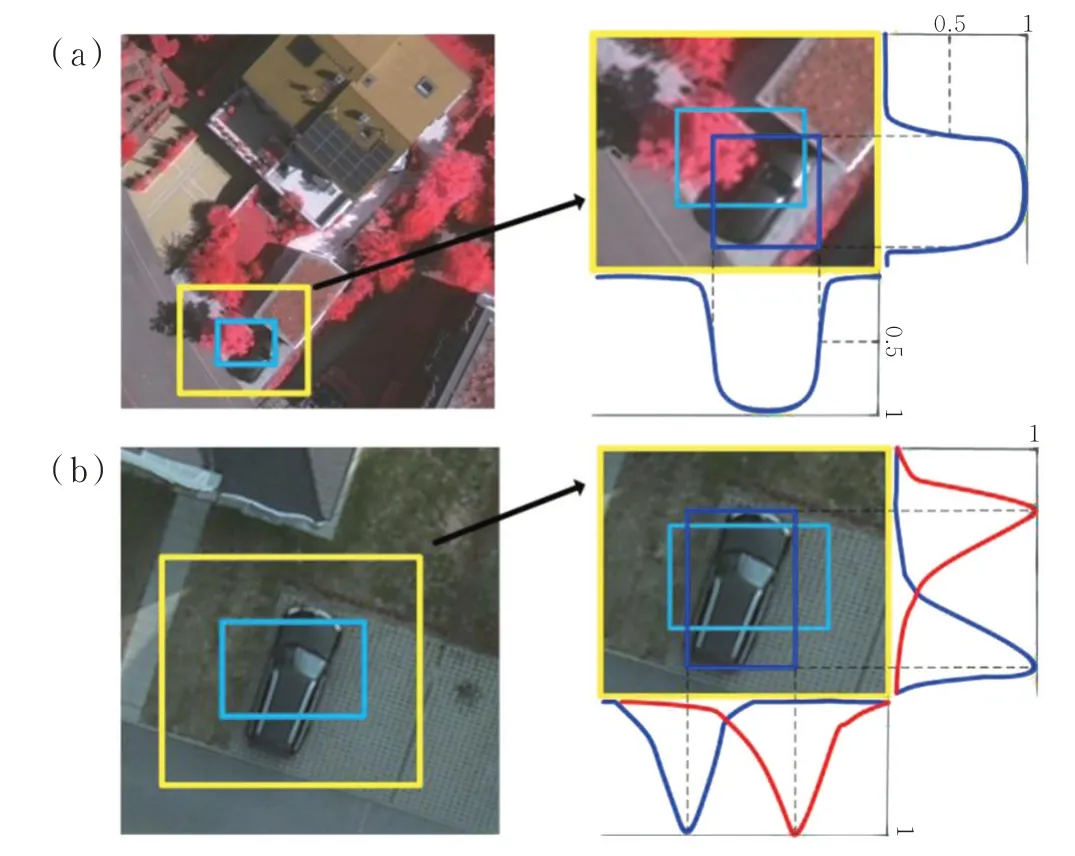
图3 概率定位模型示意图Fig.3 Schematic diagram of probabilistic location model
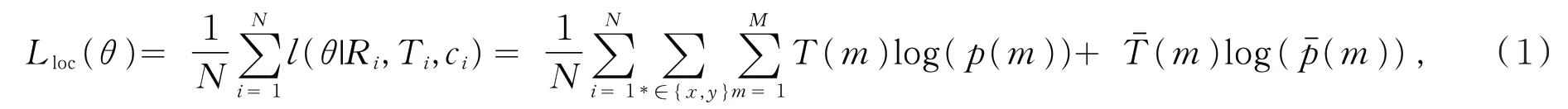
HyperLocNet 模型后续检测网络的多任务损失函数为

式(2)中Lcls(θ)表示所有类别的分类损失,Lloc(θ)为式(1)表示的定位损失。只有前景才产生定位损失,其中λ设为 1。
HyperLocNet 中的RPN 的多任务损失为

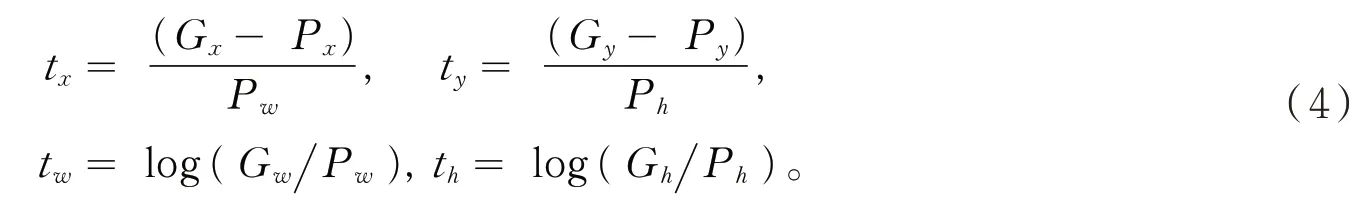
P= (Px,Py,Pw,Ph) 表示初始候选框在检测图像的中心坐标位置和长、宽。G=(Gx,Gy,Gw,Gh)代表原标记框(ground- truth box)在检测图像的中心坐标位置和长、宽。训练RPN 时,式(3)的λ设置为 3。
综合式(3)和式(4),HyperLocNet 训练过程中总的损失为

3 试验与分析
3.1 试验数据与训练参数设置
为了验证本文提出的HyperLocNet 检测模型的效果,制作了自定义的道路车辆目标数据集TVOWHU 进行检测试验,并将文献[14- 20]中的几种方法应用在该数据集上,与HyperLocNet检测结果相比较。
TVOWHU 数据集由分布在车流量较大的十字路口处的监控相机采集的视频流中随机采样得到的826 幅平均大小为601× 395 的图像组成,仿照Pascal VOC 的形式,以JPEG 格式呈现。其中707 个样本作为训练数据,其余119 个样本作为测试数据。训练HyperLocNet 时,RPN 中检测框与ground- truth 的交叠率大于0.4 的为正样本,小于0.3 的为负样本,后续检测网络中,交叠率大于0.4 的为正样本,在0.1 ~ 0.4 之间的为负样本。表1 展示了LocNet 和HyperLocNet 检测模型的训练参数设置。LocNet 检测模型分别训练了识别网络和定位网络,识别网络为去掉定位部分的Fast R- CNN 网络。

表1 训练参数设置Tab.1 Training parameters setting
3.2 检测结果比较与分析
图4 为不同检测模型在TVOWHU 数据集上的Recall- IoU 曲线,可以看出HyperLocNet 的检测效果始终优于Faster R- CNN。当IoU > 0.5,候选框数量为300 时,HyperLocNet 的召回率为 71.5% ,Faster R- CNN 的召回率为 62.5% 。与 YOLO- v2 相比,IoU 较低时,HyperLocNet 的检测效果更好,当 RPN 产生 300 个候选框时,HyperLocNet 在 IoU > 0.5 和 IoU > 0.65 时召回率比YOLO- v2 分别高出15 个和5 个百分点。
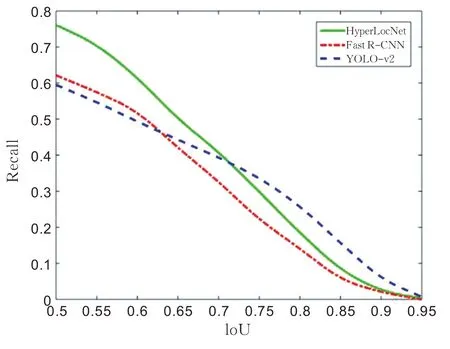
图4 不同检测模型在TVOWHU 数据集上的Recall-IoU 曲线(Proposals = 300)Fig.4 Recall-IoU curves of different detection models on TVOWHU data (Proposals = 300)
表2 为TVOWHU 数据集的整体检测结果,表中AP 表示平均检测精度(average precision)。LocNet 在PASCAL 数据集上试验时,采用多次迭代的方法提高检测效果,最终确定迭代次数为4 次。在试验中发现,对TVOWHU 数据集,最多迭代2 ~3 次就可以达到最好的检测效果。对于Selective Search 产生的质量较高的候选框,当数量较多,为1 k 时,只需迭代1 次即可,数量较少,为300 时,需迭代2 次;对于Sliding- window 产生的质量较低的候选框,当数量较多,为1 k时,需迭代2 次,当数量较少,为300 时,需迭代3 次。但即使由Selective Search 产生1 k 候选框,LocNet 的 AP 与 HyperLocNet 相比仍然有较大差距。比如 RPN 产生 50 个候选框,IoU > 0.5 时,HyperLocNet 的 AP 为 57.7% ,而 LocNet 的 AP 仅为 49.5% 。文献[16,20]采用手工设计特征识别车辆,只考虑了IoU > 0.5 的情况,与之相比HyperLocNet 的AP 整体高出10% ,由此可以看出卷积神经网络的特征表达能力更强。与LocNet 相比,HyperLocNet 检测效果更好,说明网络联合训练、共享权重可以使得识别和定位两个任务相互促进。与R- CNN 系列模型相比,HyperLocNet的优势很明显,说明概率定位模型应用在目标检测框架中可以提高检测性能。虽然IoU > 0.5 时,HyperLocNet 的 AP 略低于 YOLO- v2[9],但值得说明的是,当 0.5 < IoU < 0.7时,HyperLocNet 的AP 始终在 30% ~ 60% 之间,而 YOLO- v2 在 IoU > 0.7 时 AP 已经为 23.6% 。这一结果表明在IoU 较低时HyperLocNet模型更为稳定,在这种条件下,随着在IoU 增大时,检测效果没有急剧下降。
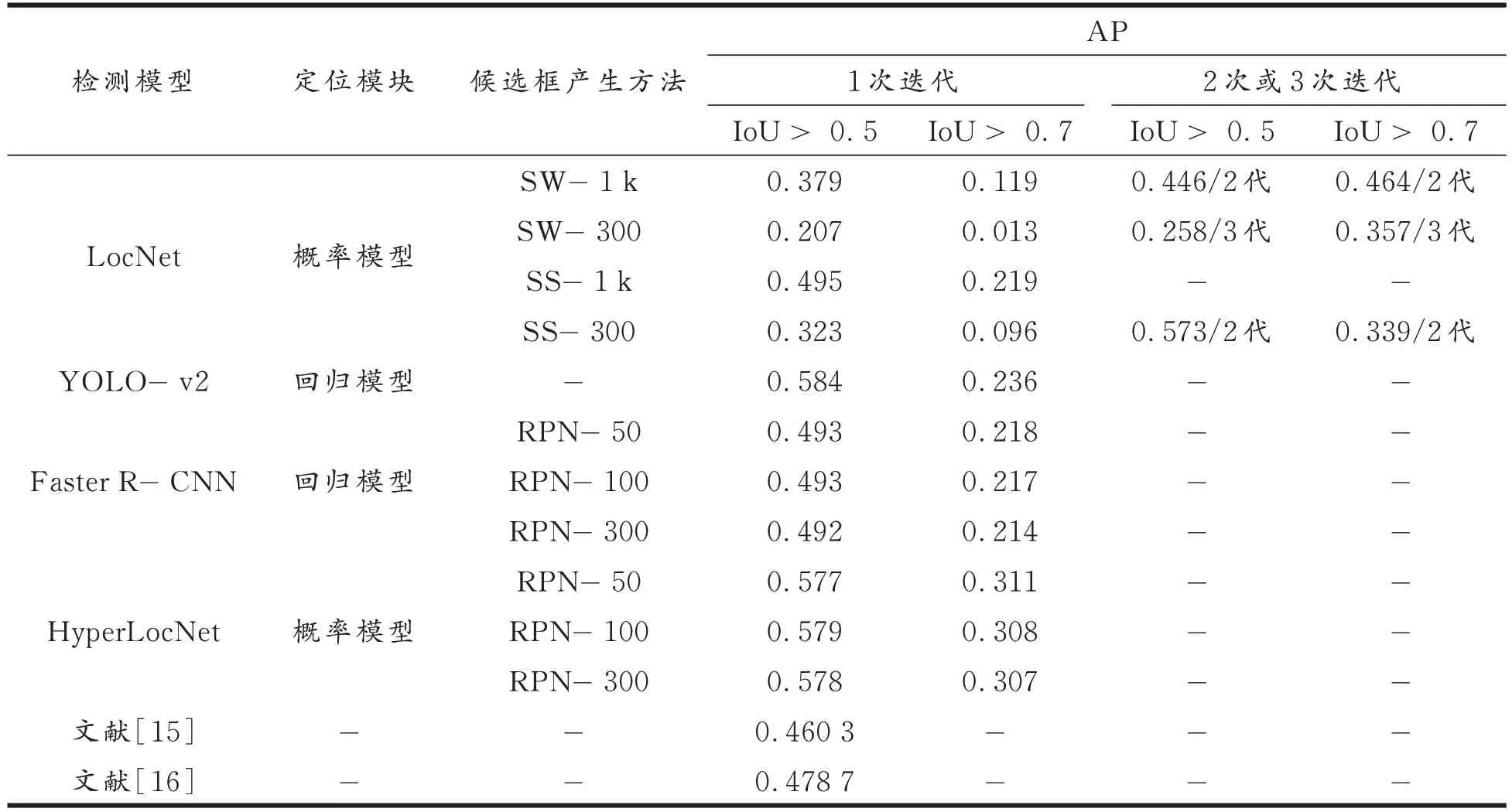
表2 TVOWHU 测试结果Tab.2 TVOWHU test results
表3 为各检测模型处理一张图片所用的时间,括号内为每秒处理的图片容量。这里所示的均为所有检测情况下检测效果最好结果的运行时间,比如LocNet 模型由Sliding- window 提供1 k个候选框时,迭代2 次效果最好。由表3 可以看出端到端模型的检测时间最短,HyperLocNet 可以达到13 帧/s,完全具有实时处理的潜质,今后我们也将继续探索,在保证检测效果的前提下,提高检测效率。除文献[15- 16]的检测模型外,HyperLocNet、LocNet、Fast R- CNN 模型均基于caffe 深度学习框架,YOLO- v2 基于DarkNet 深度学习框架,在GeForce GTX 1080Ti 上运行。
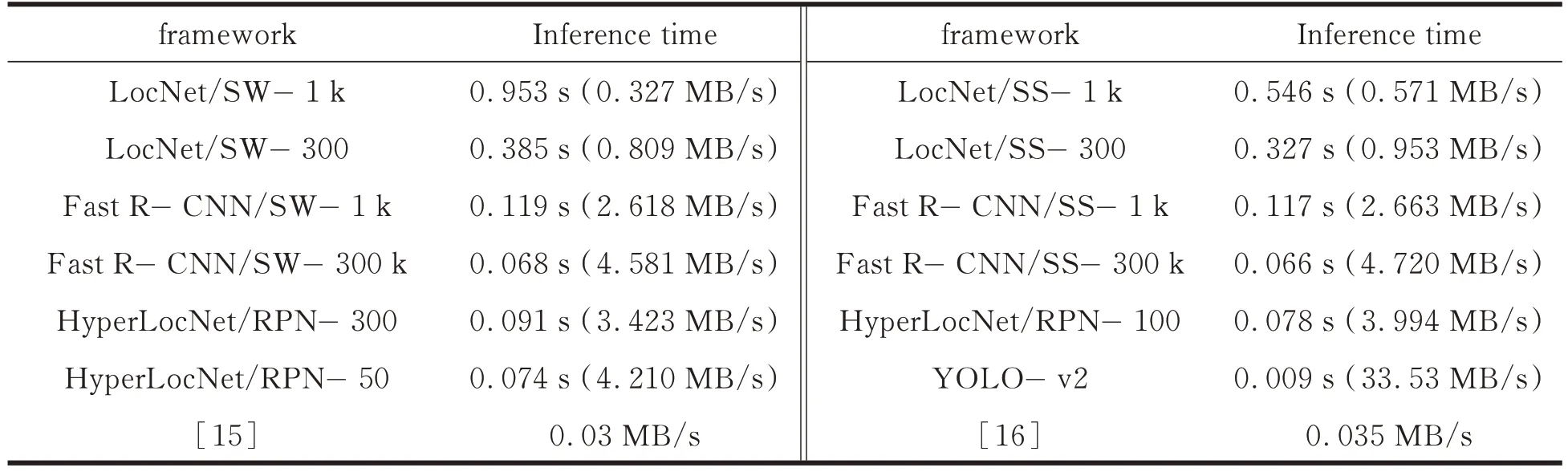
表3 TVOWHU 测试时间Tab.3 TVOWHU test time
3.3 检测结果可视化
图5 展示了HyperLocNet 和其他几种检测模型在TVOWHU 数据集上的检测结果,其中绿色箭头所指为漏检或者定位框误差较大的情况。即使在车辆分布密集,车身目标小,车辆目标相互之间有重叠的情况下,HyperLocNet 的检测结果依然比较好。其他几种检测模型有不同程度的漏检,或者有定位框位置不准确等问题。在车辆分布较密集的区域,HyperLocNet 只有一处出现一个漏检,其他检测框架出现漏检的情况较多,而且Fast R- CNN 的多个定位框的位置误差较大。

图5 检测结果Fig.5 Test results
从TVOWHU 数据集检测结果来看,本文提出的HyperLocNet 检测模型对于小目标的检测效果比R- CNN 系列模型和YOLO- v2 的检测效果好。造成这种差距的原因,第一是因为概率定位模型在稳定性方面发挥了优势,对于大目标和小目标,训练阶段和测试阶段输出的条件概率都在0 ~1 之间,保证了模型的稳定性,使得对大目标和小目标的检测效果都很好;第二是因为在HyperLocNet 检测网络中,定位和识别都采用了概率模型,这更有利于多任务学习中两个任务相互促进、相互制约,提高整个模型的稳定性和泛化性能;第三是因为在概率定位模型中,搜索区域R 是以候选框为中心并将其放大的特定区域,放大候选框,将目标周围的背景信息融入其中,也是一种特征融合的过程,有利于改善模型性能。
4 结语
本文提出一种新的基于视频流影响的道路车辆目标检测框架HyperLocNet,实现端到端检测,并达到13 帧/s 的处理速度。为解决基于CNN 的目标检测框架中使用回归模型定位输出信息较少,定位精度受限的问题,利用改进概率定位模型输出条件概率,提供更多有用的关于目标位置的信息,使检测模型更加稳定。进一步,本文将目标识别和目标定位融合在一个深度学习网络中,使得识别和定位任务共享卷积层和两个完全连接层的计算,降低了计算成本。在这个多任务模型中,识别和定位任务相互促进,使得检测性能比LocNet 大大提高。在自定义的TVOWHU道路目标数据集中,本文提出的模型检测效果比广泛使用的Faster R- CNN 和YOLO- v2 等方法有了明显提高。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
计算机工程与应用(2022年1期)2022-01-22 07:46:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
科技创新与应用(2021年23期)2021-08-30 11:46:16
计算机工程与科学(2021年4期)2021-05-11 01:59:36
无线互联科技(2020年15期)2020-11-10 06:00:58
科技传播(2020年6期)2020-05-25 11:07:46
电子制作(2019年11期)2019-07-04 00:34:38
雷达科学与技术(2018年3期)2018-07-18 00:59:32
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
