
网页搜索排序模型研究
2020-04-29 11:02:08李明琦
智能计算机与应用 2020年2期
李明琦
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
0 引 言
随着互联网的发展以及相关技术的不断提升与完善,人们获取信息的主要途径从查阅书籍、报纸等纸质材料转向了搜索引擎。然而,用户往往需要耗费大量时间从纷繁复杂的网页中去甄别有用信息。因此,高效地进行信息检索的主要挑战是优化网页搜索的排序以检索出与用户查询相关的文档。时下,许多搜索引擎仍在进一步研究新的排序算法,来提升用户的满意度。
目前,第二代搜索引擎还有一些不足之处。其一是相关性问题,即用户使用的检索词与文档的相关程度。通常使用的语言是复杂的,难以通过表面的文档特征来判断该文档是否与检索词相关。一方面,这种判断会使搜索引擎返回大量网页,且容易发生排序作弊现象,另一方面,这种判断无法返回不包含检索词、但相关性高的文档。其二,大多搜索引擎是根据关键词匹配,经常给出许多混合结果,不能有效解决问题。虽然搜索引擎展示的结果与用户检索的关键词相关,但是这并不能满足用户对信息的需求与期待。
改善这些问题的一种方法是更好地理解用户行为,在不断地检索过程中,搜索引擎收集到了大量的用户行为数据,通过分析和利用这些数据,可以有效提升排序效果。同时,如果能在文档特征中加深语义理解,就能使检索词与文档的相关程度分析得更为精准,从而能够提高用户的满意度。
近期的研究者已经转而关注起新的研究任务,并不是因为网页搜索排序问题已经完全解决了,而是因为这个任务到达了一个平台期。网页搜索排序问题仍然有着实际重要性,因此还需展开深入系统研究,推动该领域的发展与进步。
1 相关工作
网页搜索排序,即给定一个查询Q和一个网页文档集合D,基于文档和查询的相关性得分,给出最相关k个文档的顺序。迄今为止,许多学者尝试了各种方法来解决这个问题,而且取得了较为可观的成果。
搜索引擎在早期时,主要用到的网页排序思想是根据关键词在文档中出现的位置和频率进行排序。基本原理是,关键词在文档中的词频越高,出现的位置越重要,则被认为和检索词的相关性越好。OkapiBM25[1]是一个流行的基于tf/idf的排序函数。
然后,出现了链接分析排序技术,其思想源于文献引文索引机制,若网页被其他网页引用的次数越多,或者被越有价值的网页所引用,该网页的价值就越大。
斯坦福大学Page等人[2]提出了PageRank算法,基本思想是,以PageRank值来判断网页的重要程度,PageRank值取决于2个特征,其一是引用该网页的网页个数,其二是引用该网页的网页重要程度。但PageRank算法会严重排斥新加入的网页,并且没有将网页的主题相关性考虑到排序中。
斯坦福大学的HaveliWala[3]提出了主题敏感的PageRank算法,解决了主题漂流问题,然而这个算法没有用主题的相关性来提高链接得分的准确性。
Google的工程师Bharat等人[4]获得了HillTop算法的专利,解决了PageRank算法的查询无关性的问题,文档链接如果与查询主题相同会认定为更具可靠性,并只考虑专家页面,由专家页面对用户查询进行链接。这就有效处理了一些想通过增加循环链接数量提升PageRank值来作弊排序的网页。然而,专家页面在查询过程中权重非常大,这忽略了许多非专家页面的影响。
Kleinberg[5]提出的HITS算法是另一个基于超链接分析的著名排序算法,但仍然无法解决主题漂流的问题,并且可能产生主题泛化等问题。
在网络搜索领域,机器学习算法自动训练排序模型越来越流行,因为网页搜索中,有很多信息可以用来确定query-doc对相关性,并且可以利用大量的搜索日志。
Cao等人[6]将Ranking SVM应用于文档检索,并对高排名的文档加强训练提出了用新的损失函数解决排序问题,应用了梯度下降和二次规划来优化损失函数。
Burges等人[7]提出一种基于PairWise的RankNet方法,使用神经网络来训练模型,训练的损失函数为交叉熵,使用梯度下降来优化损失函数,时间复杂度优于Ranking SVM。RankNet优化的是pairwise错误的数量,但这与检索特征并不匹配。而其后提出的LambdaRank模型[8],其设计思想是直接求梯度,而不是利用代价。LambdaMART模型[9]则是结合了MART和LambdaRank,也是基于RankNet的算法。
对于网页搜索的点击模型最初是考虑点击偏置来估计相关性。Richardson等人[10]提出了位置模型,用户点击取决于文档位置和query-doc对相关性。Craswell等人[11]提出了瀑布模型,研究中假设一个用户从头开始逐个地浏览文档,并且在遇到不相关文档后继续浏览,但在遇到相关文档后停止。许多复杂的点击模型都是基于这两个模型,如UBM[12]、DBN[13]、CCM[14]。Chapelle等人提出了DBN,该模型假设了一次点击当且只当用户检测并且认为网页是可能相关的。
本文采用基于统计的排序学习方法,用不同的方法对文档进行表示,输入到排序模型中,进行对比实验,期望在小数据集上得到较好的排序效果。
2 文档表示方法和排序模型
本节拟探讨实验中采取的文档表示方法和排序模型。这里,排序任务是机器学习问题,需要抽取不同的特征来代表query-doc对,以输入到排序模型中进行训练。对此可做分析论述如下。
2.1 query-doc对表示方法
首先,采用手工抽取特征的方式对query-doc对进行表示,每个query-doc对都由多维向量表示,每个维度都是一个特征。本任务抽取了文本特征、相似度特征、匹配特征、点击特征等14个特征,见表1。

表1 特征类型
文本特征考虑到了查询和文档,是非常传统的用于排序学习任务的特征,长度是基于中文分词后的结果进行统计。相似度特征是基于查询和文档关系的特征,由3种模型得到不同的文档向量表示,然后计算得到查询和文档的余弦相似度。匹配特征是指关键词在文档标题或内容的出现情况,完美匹配即关键词以连续顺序出现于文档标题或内容,非完美匹配即关键词以不连续顺序出现于文档标题或内容。点击特征是由4种流行的点击模型(DBN, TCM[15], PSCM[16], UBM)训练得到的点击概率值,搜索引擎收集的各种用户行为信息揭示了查询和点击文档的相关信息,因此这些点击模型可以根据用户行为建立起来并且可以预测下次用户点击的位置,这些点击概率给研究者提供了极具价值的查询和文档相关程度信息。
这种用特征表示文档的方法是人们凭经验提取组合的,可能并没有足够好的表达query-doc对,并且人工抽取特征也较为耗费时间和人力。所以,研究尝试使用不同的深度学习方法对query-doc对进行表示,以期能够表示query-doc对的深度语义信息,再将这些特征向量作为排序模型的输入,可能提高整体模型的表现效果。
Word2Vec方法可以将单词映射到向量空间,不仅考虑到了词与词之间的语义信息,而且还能将词语映射到低维度的向量,解决了one-hot向量稀疏的问题,常见的用词向量表示文档的方式有:对词向量的每一个维度取平均值,最大、最小值等。通常,直接拼接组合词向量是简单有效的方法,通过实验证明该方法能够在不同的NLP任务中取得较好的效果。
基于Word2Vec的文档表示方法,考虑到了词与词之间的语义信息,并且能够降低向量的维度,然而,研究时将文档中的所有词取平均值或最大、最小值会忽略词与词之间的顺序,同时对文本表示信息有一定影响。基于Doc2Vec的文档表示方法是对Word2Vec的扩展和改进,其段落向量保留了段落的主题信息,对段落进行记忆。Doc2Vec模型可以将文档映射到固定维度的向量,既可以学习到词与词之间的语义信息,又可以保存词与词之间的顺序信息,用Doc2Vec对文档进行表示,可以很容易得进行文档相似度等计算,对于许多含有长文本的任务都有所帮助。
2.2 排序模型
排序学习是一个有监督的机器学习过程,通过对每一对给定的query-doc对,抽取查询文档的特征表示,然后通过训练排序模型,使得输出与实际数据相似。常用的排序学习分为3种类型:PointWise, PairWise和ListWise。其中,PointWise方法只处理单独的文档,将文档转换为特征向量,根据训练数据得到的模型对其进行打分,再将所有文档按照得分结果进行排序。PairWise方法将相关性得分转换为文档对关系,例如A的相关性得分为3,B为2,C为1,则可得到A>B,B>C,A>C等关系。这样就把排序问题转化成了二分类问题,利用训练模型,对所有文档进行分类得到偏序关系,从而构造全集的排序关系。ListWise方法的输入为一个文档序列,通过构造合适的度量函数来优化排序,得到排序模型。
本课题通过调研选取3种稳定的排序模型进行实验,分别为:Ranking SVM、 RankNet和LambdaMART。其中,Ranking SVM和RankNet是基于PairWise方法的,LambdaMART是基于ListWise方法的。
过程中,分别用前文所述方法对query-doc对进行表示,再与不同的排序模型进行组合,这里以使用Word2Vec取平均表示query-doc对,排序模型采取RankNet为例,设计模型如图1所示。

图1 基于Word2Vec取平均的文档表示输入RankNet模型
3 实验
3.1 实验数据集
本课题用到的数据集来自NTCIR-14的WWW2任务,包含2万个query-doc对,含有相关性标签,其中15 000对作为训练集,5 000对作为测试集。对于每对query-doc对,提供4种弱相关标签,由4种流行的点击模型得到,分别为:UBM, DBN, TCM, PSCM。这些点击标签利用了大量用户行为,如点击、跳过、停留时间。
3.2 数据预处理
原始数据为xml格式,包含查询内容、查询频率、查询id、文档url、文档id、文档标题、文档内容、html、文档频率、文档点击标签等内容。
首先,需要对这些数据进行预处理。本课题只提取了查询内容、文档标题、文档内容、点击标签等信息。然后过滤掉内容、标题等数据中的非中文、空格、停用词、空数据等信息。最后,将数据进行繁简转换、分词等操作。
3.3 评价指标
针对回归、分类、排序等不同类型的问题,研究时用到的评价指标也不相同。网页搜索排序返回的结果通常是有序的,所以需要考虑其位置信息,本课题采用信息检索的常用评价指标如NDCG、nERR、Q-measure,来度量排序结果的优劣。
3.4 实验结果
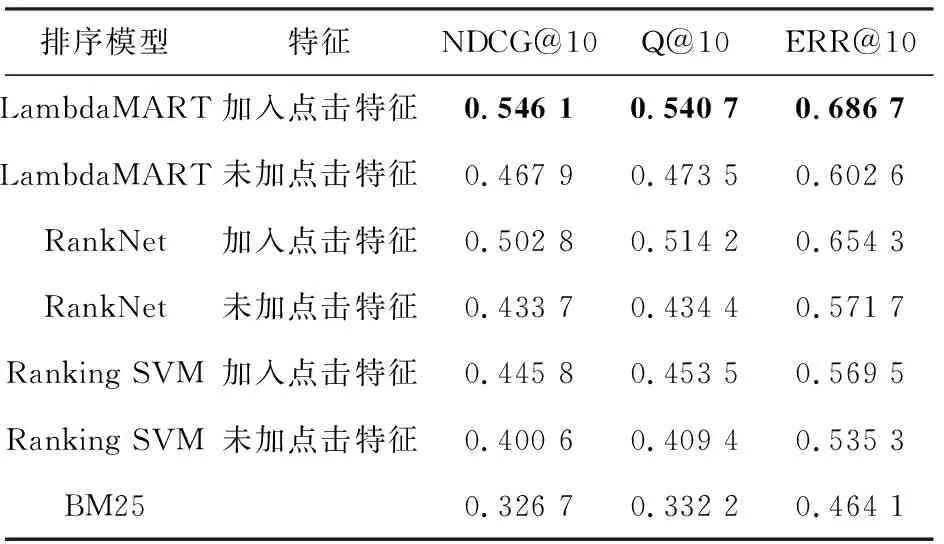
本节将BM25算法作为本课题研究的基线,该算法是文档检索的常用算法,思路非常简单。这里对比了加入点击特征对query-doc对进行表示的情况下,Ranking SVM、 RankNet 和LambdaMART模型的表现,具体实验结果见表2。
表2 排序模型在不同特征组合下的实验结果
Tab. 2 The results of ranking model under different combination of features
排序模型特征NDCG@10Q@10ERR@10LambdaMART加入点击特征0.546 10.540 70.686 7LambdaMART未加点击特征0.467 90.473 50.602 6RankNet加入点击特征0.502 80.514 20.654 3RankNet未加点击特征0.433 70.434 40.571 7Ranking SVM加入点击特征0.445 80.453 50.569 5Ranking SVM未加点击特征0.400 60.409 40.535 3BM250.326 70.332 20.464 1
由此可以看出,LambdaMart模型表现效果最好,并且点击特征对排序结果非常有帮助。
采用Word2Vec,Doc2Vec等模型对文档进行表示,在排序模型上选择稳定性较好的Ranking SVM、 RankNet和LambdaMART进行实验,继而比较3种评价指标的好坏,实验结果见表3。
由此可以看出,基于深度学习的表示方法整体优于不加入点击特征时的手工提取特征的方法,Doc2Vec模型表现最优。
4 结束语
如今,人们在日常生活中广泛使用互联网,对信息的获取主要求助于搜索引擎,因此对网页搜索排序结果进行优化是有着重要研究价值的,好的排序结果可以节省用户浏览大量低相关度网页的时间,并且返回用户满意的结果,从而解决人们生活中的实际问题。
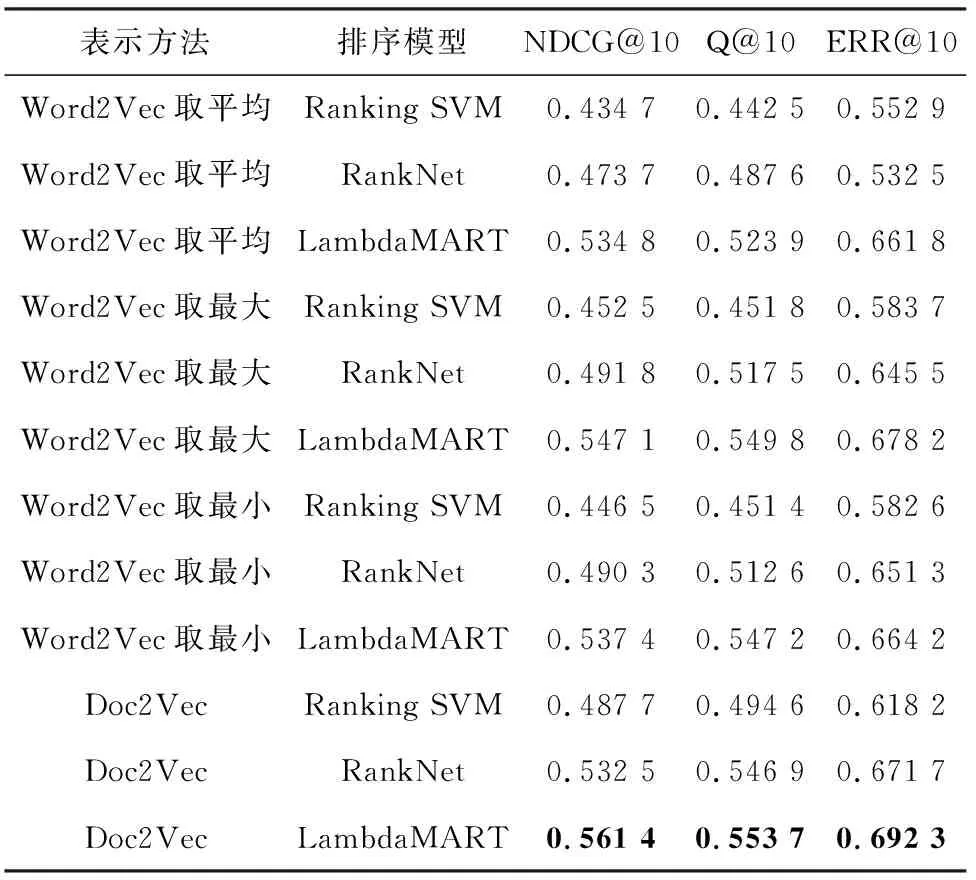
表3 基于不同文档表示方法的实验结果
本文在少量标注样本数据集上,采用不同的query-doc对表示方法,对不同的排序模型如Ranking SVM、RankNet、LambdaMART进行对比实验。实验结果表明,点击特征对于提升排序效果非常重要,并且LambdaMART模型在本实验中的排序效果最好,稳定性较高。本文探索了多种基于深度学习的文档表示方法,如Word2Vec分别取平均值、最大值、最小值,Doc2Vec模型,将以上模型生成的文档表示向量输入到排序模型中进行了对比试验。实验结果表明,用Doc2Vec模型来表示query-doc对,最终得到的排序结果是最好的,可以很好地捕捉到文档的语义信息。本文在网页搜索排序问题上取得了一定的研究成果,但是仍然存在一些不足。一方面,排序模型的实验以及基于深度学习方法表示文档的实验对比并不充足,未能尝试基于pointwise方法的排序模型,而且也没有用更多的深度学习方法(如GRU模型)对文档进行表示,这样会使实验结果不全面,不足以进行有效的论证。另一方面,数据样本较小,且数据存在不平衡性,这对提升排序效果的表现产生一定影响。
后续的研究工作可以从半监督学习方面开展,排序模型效果的表现与训练数据的多少相关,由前文可看出,即使研究尝试了多种文档表示方法、排序方法,排序结果的评价指标仍然没达到最理想的状态。因为研究中很容易地获取到大量的无标注网页,其中蕴含的信息对于训练排序模型也是很有价值的,因此可以利用半监督学习方法,自动标注一部分数据,这样就可以扩充训练集,同时也能尽量保证标签的准确性。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
中国新闻周刊(2021年26期)2021-07-27 04:02:12
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
电子制作(2018年10期)2018-08-04 03:24:38
儿童绘本(2018年5期)2018-04-12 16:45:32
电子制作(2017年2期)2017-05-17 03:54:56
信息安全研究(2016年4期)2016-12-01 06:06:54
电子测试(2015年18期)2016-01-14 01:22:58
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
