
面向文章流量预测的特征筛选与分析*
2020-04-25 13:37胡宝灵李志涛
通信技术 2020年4期
胡宝灵,李志涛,周 燕
(华南农业大学,广东 广州 510642)
0 引 言
随着互联网自媒体的兴盛和人们上网偏好的改变,微信公众号逐渐成为重要的媒体平台之一。公众号若能够抓住关注者的阅读偏好,并生产阅读偏好下用户最可能喜闻乐见的内容,将对其阅读量的提升存在一定作用。因此,本文在文本数据挖掘的基础上,分析可能影响文章阅读量的特征,并对这些特征进行筛选,旨在确认影响媒体阅读量的因素,实现文本数据挖掘技术的延伸、传播学自媒体研究的拓展。
1 文献综述
自媒体阅读量受多种因素影响。在自媒体阅读量的研究中,研究者们采用多种方法确认阅读量的影响因素,如金星[1]通过分析案例阐述阅读量对文章特征的影响;陈星蓉、龙兴宇[2]结合人群喜好提取吸引读者的文章特征,但它们缺乏数据支持。还有通过描述性数据分析来估计阅读量影响因素的研究,如郭炉、刘春云[3]将公众号文章的多种特征可视化,判断是否影响阅读量,但这种方法仍旧缺乏有效的有效性检验。钟若曦、马晓燕等[4]采用多因素Logistics 回归分析阅读量和点赞量的影响因素和程度,但数据因人为主观因素而存在误差。
2 研究方法
本研究以一个微信公众号为研究主体,通过爬虫技术获取该公众号下的所有文章为研究样本,然后估计阅读量发展至稳定所需的时间,裁去部分阅读量仍未达到稳定的样本,随后数据清洗,去除特殊文章和异常文章,并将文章的标题和文章转换词向量,再进行特征工程。通过最大概率法、主题概率模型以及相关数据操作技术,对数据进行分词处理,提取文章特征,并检验所提取特征与阅读量之间的关系。
3 数据处理
本文爬取微信公众号“情感说说”2018 年11月14 日至2019 年5 月11 日的数据,剔除流量一周增长率大于1%(文章发布两周时的阅读量文章发布一周时的阅读量)、阅读量在3 倍标准差范围外的文章。经过数据清洗后,选用226篇文章的标题、发布时间、内容和阅读量4 个变量作为研究数据。
4 特征工程
4.1 文章标题的特征
陈星蓉、龙兴宇[2]认为,文章标题对文章流量有着至关重要的影响,新颖的标题往往使文章具有较高的阅读量。文章标题的特征很可能包涵对文章流量预测的重要信息,故本研究首先提取文章标题的特征。
4.1.1 标题汉字的个数
本文将文章标题的汉字个数与文章阅读量通过散点图的形式可视化,并生成通过最小二乘法拟合得到曲线及95%的预测区间,如图1 所示。可以看见,数据点主要集中在左侧且偏上的位置,拟合曲线明显向下倾斜。

图1 汉字个数与文章阅读量的散点图及拟合曲线(95%)
通过R 软件计算得到的一元线性回归系数表(表1)可以发现,标题的汉字个数在回归模型中的t 检验显著性水平小于0.05,说明汉字个数在流量预测模型中存在足够的信息价值。

表1 汉字个数与文章阅读量的回归系数表
4.1.2 标题符号的个数
王干丽[5]在研究公众号文章标题时发现,标点符号可以增强文章的感染力。本研究将标点符号这一特征进行多种方式分类,发现将没有标点符号以及有标点符号的标题划为一类,剩余有两个及以上标点符号的标题划为一类,这种情况经过方差分析F 检验后的显著性水平最低。以符号情况为名建立新变量,并将第一类划为0,第二类划为1,共得到201 个0 和25 个1。
4.1.3 标题的词频
文章标题是读者了解文章最快速的渠道,标题中的每一个词都可能意味着是文章所涉及的主题或讨论的话题,而读者也往往可能因为文章的某一个词而选择阅读文章。
本研究将以文章标题中出现的词建立多个变量。在建立词变量前,首先需要对文章的所有标题进行分词处理。
经过R 软件jiebaR 中segment 函数的处理,文章标题将分为一个个词。以标题“希望,对余生的希望”为例,经过分词处理后的输出结果为“希望”“对”“余生”“的”“希望”。对226 个标题进行分词处理,共收集到533 个词,其中370 个词仅出现1 词,81 个词出现2 词,而出现次数最多的词为“的”字出现77 次。本研究保留名词、动词、形容词等实词,副词、介词、连词等虚词删去,获得114 个词,并以这114 个特征作为分类变量。
4.1.4 标题的情感
本文利用处理多分类问题的两种拆分策略在鸢尾花数据集上进行对比研究,比较两种拆分策略的优劣性,为后续多分类问题的研究起到一定的指引作用。
由于研究对象属于一个情感类公众号,因此研究将标题的情感作为特征之一。
研究根据情感态度将标题分为积极、消极和中性3 类。运用专家打分法,同时建立特征标题情感,将积极、消极和中性分别赋值为1、-1 和0。经过处理后共得到54 个积极标题、131 个消极标题和41 个中性标题。部分标题的划分如表2 所示。
4.2 文章正文的特征
当读者通过文章的各种特征判断其为一篇“好文章”时,可能会分享它,利于文章传播提高阅读量。下面将应用多种统计方法提取文章正文的特征,尽可能从数据中获取有价值的信息。
4.2.1 正文主题
本文提取文章的字符数和发布时间。通过提取统计文章中所有词的词频,可以自动查找主题。运用主题数K=3 的LDA 主题概率模型,将文本视作词频向量。从单词的概率分析得知主题,而文本又是多个主题构成的一个概率分布,从而得知正文的主题特征。
4.2.2 正文长度
文章长度可能隐含能影响阅读量的有价值信息,故计算正文的字符数表示文章长度。正文长度的样本均值为568.58,样本标准差为107.01。将正文长度的密度分布函数可视化后发现,整体近似正态分布,密度分布函数图在正文长度800 左右小范围起伏。
4.2.3 发布时间
研究的226 篇文章中,只有1 篇在19:30 发布,其余225 篇在21:04 至23:58 之间发布。以21:00 起的每分钟为发布时间,则21:04分发布的文章为4分,23:58 发布则为178 分,19:30 发布的那篇文章直接作为21:00 处理,然后将整理后的时间可视化,发现阅读量在10 000 以下的数据散点有轻微的波动起伏情况,说明夜间阅读存在高峰与低谷。
类似的,微信用户也可能因为工作等关系,在工作日与休息日上有不同的阅读频率。因此,将文章发布日期转换为周一至周日,并对阅读量在7 个水平上进行方差分析,得出方差分析表如表3 所示,箱型图如图2 所示。

表3 阅读量的方差分析表

图2 文章阅读量以星期未分割的箱型
可以明显看出,在周一发布的文章阅读量集中且低于其他天,而周日发布的文章阅读量相对分散。同时,在方差分析表中,经过F 检验的p 值为0.584,在0.1 的显著性水平下,可以认为阅读量在不同的星期发布是有差异的。
在微信公众号的订阅号页面,一些订阅号群发的文章有分头条与次条,如图3 所示。

图3 订阅号群发预览
通过浏览数据对比公众号的群发内容发现,收集到的数据中,当天的第一条为头条,其余为次条。以头条为1、次条为0,经过提取后得到125 篇头条和101 篇次条。
4.3 有效性检验
经过上述过程的特征提取,原始数据变成226行125 列的数据框。除去文章阅读量,125 个特征分别是标题的汉字个数(连续变量)、标题的符号个数(二分类变量)、标题的情感(多分类变量)、正文的长度(连续变量)、文章发布时间(连续变量)、文章发布星期(有序变量或多分类变量)、头条次条情况(二分类变量)、114 个标题的词频(二分类变量)、3 个正文的主题概率值(连续变量)和正文的主题类型。总的来说,可以分为连续变量、二分类变量和多分类变量3 种类型。
对3 种变量类型的特征进行有效性检验,对连续或有序变量特征与文章阅读量进行相关性检验,确认特征是否对文章阅读量有线性影响。检验结果(表4)显示,标题的汉字个数对阅读量有明显线性相关性,且当发布星期作为有序变量时,可以看成其对阅读量存在有线影响。
二分类变量特征将文章阅读量在特征水平上分为两组,若特征对阅读量有影响,则应当反映两组间均值是有差异的,因此通过T 检验确认特征的有效性。
由于本文特征工程中创建的特征超百个,故仅抽取0.05 显著性水平下表现显著的特征作为结果展示(表5)。这些标题词频特征表示,文章的标题是否出现这些词汇会显著影响其阅读量。

表4 相关性检验结果

表5 显著特征的T 检验结果
而对于多分类变量,两组各进行一次则流程繁琐,且无法反映整体情况,因此采用方差分析的方差检验组间均值是否有差异。需要进行方差分析检验的特征分别是发布星期、标题的情感和主题类型,3 次方差结果如表6 所示。
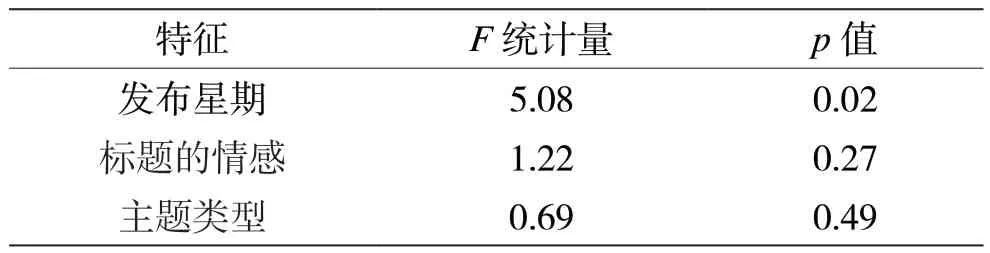
表6 方差分析检验结果
5 结 语
研究发现,影响文章阅读量的因素有标题的汉字个数、标题的情感、正文的长度、正文所涉及的主题类型、发布的时间点和星期、是否头条以及标题中是否会出现某些词等。以上特征对该公众号的创作指导显然具有重要意义。
猜你喜欢
科学养鱼(2021年6期)2021-11-30
中国现代医药杂志(2021年10期)2021-11-11
小学生学习指导(低年级)(2021年9期)2021-10-14
中学生数理化·中考版(2021年8期)2021-07-31
小学生学习指导(高年级)(2021年4期)2021-04-29
小学生学习指导(低年级)(2019年9期)2019-09-25
学生导报·东方少年(2019年27期)2019-01-14
小学生学习指导(低年级)(2018年9期)2018-09-26
爆笑show(2015年5期)2015-07-09
新高考·高二数学(2014年7期)2014-09-18
