
低延时期货交易系统的优化与测试
2020-04-25 07:53:06雷达沈益明
现代计算机 2020年9期
雷达,沈益明
(1.东华大学计算机科学与技术学院,上海200051;2.建信期货有限责任公司,上海200122)
0 引言
我国期货市场自创立以来,一直采用电子化交易方式,交易系统一直是期货公司的核心技术系统。目前客户普遍使用的期货交易系统在设计时,核心考虑的是系统的并发性、可用性、系统容量等,低延时并不是最优先考虑的。但近年来,国内期货市场发展迅速,期货新品种源源不断上线,期权、以人民币计价的原油期货等新业务也陆续推出,期货市场的交易方式和市场功能不断丰富,各类投资者尤其是机构投资者参与各类投资产品、参与多市场多品种间的套利热情日益高涨。这些投资者造成了资金流动性和交易量的急剧增加,因此对期货交易系统提出了更为明确的要求,主要体现在提高交易速度和提供程序化交易支持等功能。为了在竞争激烈的行业中脱颖而出,期货公司迫切需要低延时系统的优化解决方案,从而为速度敏感的客户提供更为优质的服务。
交易系统的低延时意味着投资者做出投资决策到委托获得执行和确认的时间间隔必须尽可能短。对于某些交易,如高频交易,交易速度是影响投资效果的最重要因素之一。此时,衡量交易系统绩效最重要的指标之一就是系统延时。一些高频投资策略可以在系统延时较低的情况下获得可观的正收益。
1 期货交易系统延时框架
如图1 所示,期货交易是一个双向往返的过程。广义上的交易延时是指由委托等交易指令从市场参与者系统发出,到交易系统接受、处理,并返回处理结果的时间开销。而狭义上的交易延时是指交易指令从进入交易系统接入点之后到处理结果返回接入点之间的时间开销[1]。对于期货公司这种集中式的交易系统来说,客户系统和交易所撮合等外部延时因素不可控,因此低延时期货交易系统的构建主要基于后者进行讨论。
对于期货交易系统,根据经过的处理环节,交易延时可细分为以下几类:
消息处理延时:消息传输过程中消息格式转换的应用,以及消息可用性机制相关的时间开销;通信处理延时:主机协议栈处理开销;调度延时:主机请求到处理开始的时间开销;发送/接收延时:主机向网络发送或接收协议包的开销;传播时延:传播介质上传输的时间开销,主要与传输距离和传输介质有关[2]。影响延时的因素分布在硬件、网络、操作系统、中间件和应用程序等不同层次上。其中,根据文献[3],对于高性能、低延时期货交易环境的系统来说,这些因素相互作用,在构建低延时期货交易系统的时候,尤其需要对这些延时影响因素进行分析,尽量避免或降低延时影响因素,从而降低交易延时。
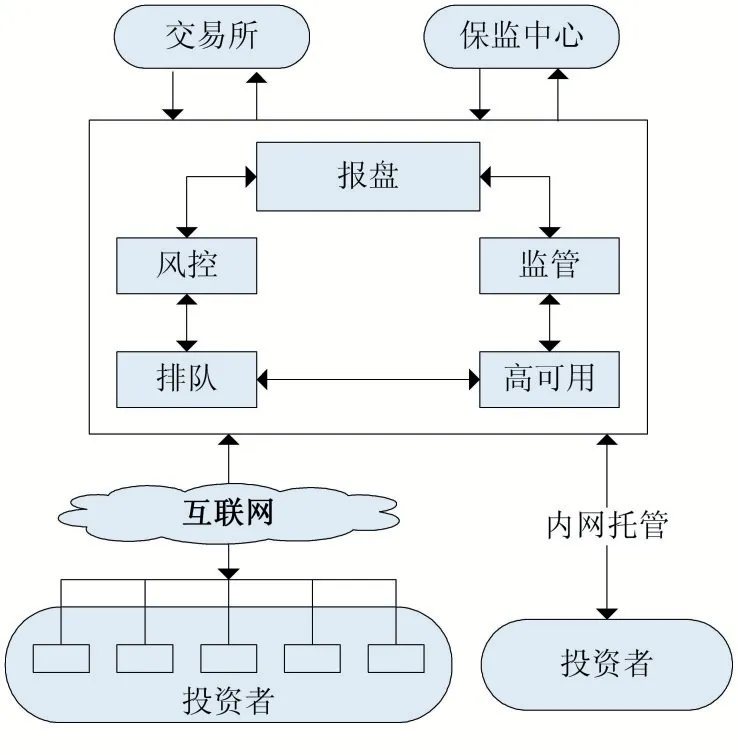
图1 期货交易系统结构
2 低延时期货交易系统的优化
2.1 优化步骤
在系统优化之前,需要收集延时参数和数据作为基线,知道“正常”的系统延时数据。然后查找潜在的性能问题并进行参数调优来修复。观察这些调整对系统的影响并决定是否确认保持这种调整或者恢复到调整前的状态。系统需要定期检阅,以发现系统异常变化引起的延时抖动。
优化的步骤如下:
(1)收集数据,建立基线。
(2)对系统进行选择合理的参数。
(3)观察统计数据,确认所做的调整是否正确,提交更改或回滚恢复。
(4)确定潜在的性能问题。
(5)调整优化参数。
(6)重复步骤(3)。
2.2 优化内容
(1)服务器优化
低延时期货交易系统选配的服务器尽量高主频、大内存,以HP DL380 服务器为例,在优化前记录系统参数配置,以便在调优过程中跟踪变化。根据HP 推荐,在BIOS 调优前需先升级至相应BIOS 和Firmware固件版本,有助于提升系统延时性能。
服务器出厂时硬件参数默认设置为通用节能模式,调整BIOS 参数,降低主机延时,使主机发挥最大性能,从而达到降级延时中的关键一环。BIOS 参数超频,虚拟化,超线程均会产生潜在延时抖动风险,需要关闭这些功能,关键优化参数描述如表1。
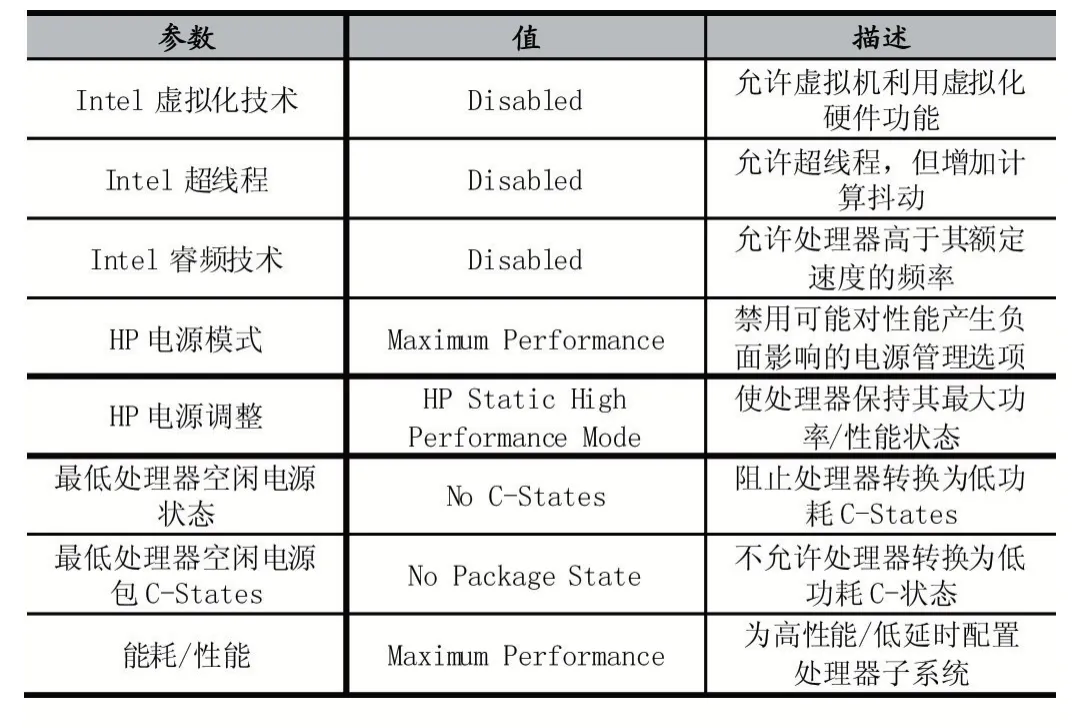
表1 BIOS 优化参数表
(2)Linux 系统优化
调整/boot/grub/grub.conf 参数,增加“idle=poll nosoftlockup mce=ignore_ce intel_idle.max_cstate=0 "参数到kernel。
idle=poll 参数与“intel_idle.max_cstate=0”一起使用时,“idle=poll”使处理核心保持在C0 状态;nosoftlockup参数使高优先级线程在内核上连续执行超过软锁定阈值时,防止内核记录事件;intel_idle.max_cstate=0 防止内核重写BIOS C-state 设置;mce=ignore_ce 防止Linux在机器检查库中每五分钟启动一次轮询,检查是否存在可纠正的错误。这些参数调整有助于降低通信处理延时、调度延时和发送接收延时。
(3)网络优化
在低延时系统中我们配置Sloarflare 的低延时网卡,停止中断分配服务,将网卡口的中断手工配置至网卡PCI 插槽对应的NUMA 所属的CPU 核。运行如下指令并将命令添加至rc.local,设置为开机启动加载,有助于降低传播延时。
网卡中断亲和性优化:
/usr/sbin/sfcaffinity_config-c 1,2,6,7 auto ethX
网卡吞吐量优化:
/usr/sbin/ethtool-G ethX rx 4096 tx 2048
/usr/sbin/ethtool-X ethX equal 2
/usr/sbin/ifconfig ethX mtu 9000 txqueuelen 10000
(4)交易线程绑核
期货交易系统的交易核心是多线程,操作系统调度算法使线程均匀的分布在CPU 核心上,线程之间需要进行通信、共享资源,所以这些资源必须从CPU 的一个核心被复制到另外一个核心,这会造成额外的开销。
为了让程序拥有更好的性能和更低的延时,将交易核心线程绑定到特定的CPU,这样可以减少调度的开销和保护关键线程。绑定后交易核心线程就会一直在绑定的核上运行,不会再被操作系统调度到其他核上,但绑定的核上还是可能会被调度运行其他应用程序的。因此,需要隔离被交易核心绑定的核。绑核代码如下:
bind_ttrade_cpu()
{
ttrade_threads=`ps-eLF|grep ttrade|grep-v grep|awk'{print
$4}'`
cpucore=(6 7 8 9 10 11)
index=0
for i in$ttrade_threads;do
if![[-z$i]];then
taskset-pc${cpucore[$index]}$i
fi
index=`expr$index+1`
done
}
bind_ttrade_cpu
3 低延时期货交易系统的测试
(1)测试准备
试验环境为万兆以太网,交换机Arista 7140,两台HP DL380 G9 服务器(12 核3.40GHz,64G 内存),配置2 块Solarflare 8522 万兆网卡和光纤模块。
(2)RTT 延时测试:
此外,卷积神经网络还涉及到多层次的输出类别以及输入图像类别。针对不同种类的输出与输入图像而言,通常都需将其分成相应的隐含层,然后将其连接于整个卷积网络。在这其中,图像隐含层能够容纳某些中间信息,且可以用来显示图片中的边缘点以及特征点。由此可见,卷积神经网络具备的核心价值就在于开展全方位的逻辑判断,其在本质上很近似人脑固有的性能,同时也涉及到多层次的技术细节。
两台服务器使用光纤back-to-back 直连,避免交换机产生的延时影响,RTT 测试结果如下:
优化前:
rtt min/avg/max/mdev=0.036/0.084/0.109/0.014 ms
服务器优化:
rtt min/avg/max/mdev=0.035/0.041/0.056/0.011 ms
Linux 系统优化:
rtt min/avg/max/mdev=0.027/0.031/0.049/0.007 ms
网络优化:
rtt min/avg/max/mdev=0.006/0.008/0.017/0.002 ms
从结果看出前述调优方法效果非常明显,但要注意的时,RTT 不可能无限降低,当降到某个稳定值时,我们认为此时调整的参数有效,如果无限制的追求最低,那延时抖动所带来的风险对期货交易来说是致命的。
(3)Onload 加速中间件测试
测试主要使用了sfnettest 开源工具来对比使用Onload 和Kernel 的差别。pingpong 测试1/2RTT 平均延时数据(单位:微秒)如图2。
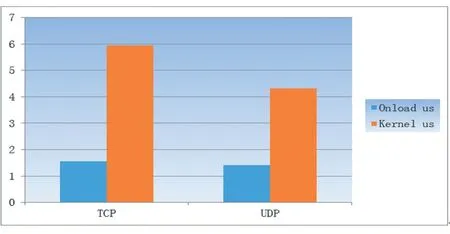
图2 1/2RTT 平均延时
从图2 中可以看出Onload 中间件的加速功能比Kernel 低2/3,对延时的提升是巨大的,当一个应用程序调用操作系统内核来发送和接收数据,从应用程序到内核是一项开销很大的操作,当应用程序使用Onload 中间件发送或接收数据,它利用了kernel bypass 技术,中间件直接访问网卡上的一个虚拟区来达到与网卡的直接通讯。因此系统的开销越小,延时就越低。
(4)期货交易实盘测试
期货公司更多关注的是交易系统自身内部延时,对系统设置4 个采样点T1,T2,T3,T4[4]。其中T1 为报单录入应答,当客户端发出报单录入请求指令后,交易系统返回响应时;T2 为交易系统接受到报单录入请求后向交易所前置发送报单录入请求;T3 为交易系统接受到请求后发给交易所,交易所收到后返回的请求;T4为返回给终端交易所报单状态。
图3 中可知,交易系统内部延时为Inner=(T2-T1)+(T4-T3)。
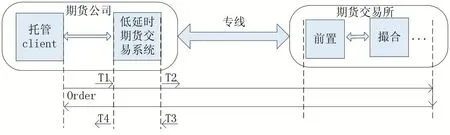
图3 延时指标定义
使用API 在内网用接近市价报单并迅速撤单,下单频率为50 笔/秒,内部处理时间(包含上行和下行的总处理时间)平均为27us,99%的报单延时在35us 以下。报单延时分布如图4。
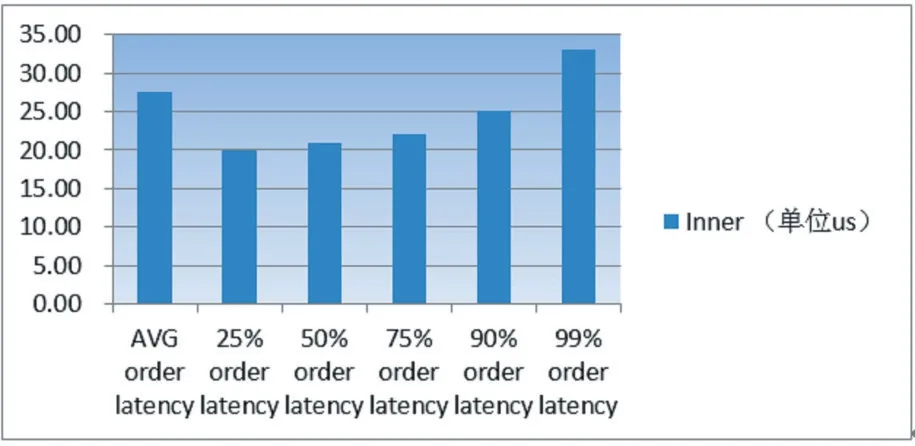
图4 交易系统报单延时
从图4 看出系统的内部延时较为稳定,系统内部平均延时27us,那么每秒能处理的订单量约为1000000/27=37037。如果以用户量来说明的话,能处理3 万7 千笔的报单相当于能接受375 个用户每秒按100 笔(上期所流控)来报单而不会出现积压。
4 结语
在系统上减少或消除抖动是获得最佳性能的关键,然而抖动的原因从而导致低劣的性能很难定义和很难补救,特别是在当前交易环境中,期货公司更多关注于自身环境的内部延时,从交易所线路接入到期货公司机房,从服务器、网卡到操作系统等,要设计好每一个环节。
期货交易系统是个多因素相互作用的复杂系统,仅改进系统的一部分并不一定会带来总体性能的提高和延时的下降。因此,构建低延时交易系统必须把握均衡原则,在把握关键因素的同时,必须从系统整体作考虑,认真分析各因素之间的相互作用和与周边系统的相互联系,并根据实际情况不断调整和优化。
猜你喜欢
科技与创新(2023年17期)2023-09-17 12:26:12
中国交通信息化(2022年7期)2022-10-27 06:35:38
中国交通信息化(2022年7期)2022-10-27 06:35:24
犯罪研究(2019年3期)2019-11-27 19:28:54
网络安全和信息化(2019年1期)2019-02-15 02:45:42
时代金融(2019年34期)2019-01-11 17:43:48
中国化肥信息(2018年12期)2018-03-01 03:12:58
科技经济市场(2017年9期)2017-11-28 01:14:56
湖南城市学院学报(自然科学版)(2016年4期)2016-02-27 14:02:42
电脑爱好者(2015年15期)2015-09-10 07:22:44
