
基于联合相似度的民航旅客不文明等级预测
2020-04-23 05:43:24丁建立王怀超
计算机工程与设计 2020年4期
丁建立,李 洋,王怀超
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
随着民航领域的快速发展,民航客流量的不断攀升,不文明旅客的数量也不断增加,不文明旅客数据库逐渐形成规模。如何对民航不文明旅客行为进行有效的监控与分析;如何建立一套可量化、可测量的指标体系;通过社会不文明人员与民航不文明旅客进行相似性分析,来预测从事民航活动的社会人员发生不文明行为的潜在程度,对不文明旅客进行有效的监控,便于辅助航空公司对旅客的管理决策和服务政策制定已经成为民航业亟待解决的问题。
目前国内外使用文本挖掘技术对于民航不文明旅客的研究较少,但在犯罪侦查项目中有所应用。亚利桑那州大学和警察机构建立的犯罪侦查项目Coplink和Recap,采用命名实体抽取方法对犯罪叙述报告的实体进行识别。此外运用文本挖掘工程结合犯罪规范词汇,从犯罪记录和目击者的叙述中提取相关实体,通过聚类方法和短文本相似性分析来匹配犯罪过程。目前对于犯罪或者不文明行为的分析主要是通过文本相似性度来进行研究。
为了达到对旅客有效监控的目的,实现对从事民航活动旅客发生不文明行为潜在程度的预测,本文采用相似度匹配算法对不文明人员的民航行为和社会行为进行度量,并将不文明旅客的处罚规则特征引入了计算模型,针对不同行为间的隐式关系进行了挖掘,刻画不文明人员特征,实现旅客潜在不文明水平的预测,维护航空安全。
1 相关工作
目前国内外对文本相似度的研究主要集中在对文本特征题提取和对比分析方面,通过统计文本中的TF-IDF(term frequency-inverse)值构成文本特征向量,并运用卷积神经网络,和深度学习等方法对文本进行训练,计算出文本的相似度值。
为了提高文本相似度计算的性能,Tian等[1]提出了具有多种文本特征的句子对匹模型,使用对齐特征(alignment feature)计算句子的语义相似性,但该方法仅考虑了两个句子间同词的共现,忽略了文本上下文的联系产生的影响。武永亮等[2]提出了文本关键词寻优算法,考虑了关键词比例增加的临界点问题,该算法通过更新类别关键词和控制相似度阈值降低了噪声文本加入的概率,但在使用TF-IDF值进行关键词提取时,对于非关键词语料的去除,忽略其潜在的语义联系。Tang 等[3]提出了在文本中加入同义词林的多粒度计算模型,将同义词林加入文本共同训练,但同义词林的加入会导致计算复杂度的提高,降低效率。Mikolov等[4]在Word2vec的启发下提出了Paragraph Vector,借助于词向量方法的成功,对于句子和段落的向量表示工作正尝试展开,从单词向量的简单附加组成到复杂的加权结构[5-10]。通过叠加词语的词向量来获得句子向量对整个句子的语义表达不够准确。Wieting等[11]用单词向量平均来学习句子向量,通过监督句子释义组来更新标准词向量用于句子训练,但需要重新训练大量有标记的数据集。Neculoiu 等[12]通过循环神经网络结合Siamese模型学习变长文本序列的相似性度量,但仍需大量标注数据。Mrabet 等[13]受DNA序列启发提出了考虑连续单词顺序性的独立相似性度量算法,但忽略了共现词带来的影响。Alnajran 等[14]提出了一种启发式驱动预处理方法来增强上下文相似性度量性能。Arora等[15]总结前人经验提出的一种简单有效的句子向量表示新方法SIF(smooth inverse frequency)该方法非常适合于域适应设置,即在各种语料库上训练的单词向量可用于计算不同测试平台中的句子向量。
上述算法的训练与测试往往是在同源数据中,但面对非同源数据的相似性匹配并不能起到很好的效果。本文对于民航不文明旅客行为分析和研究中需要面临来自于社会和民航两部分的非同源数据,两者数据在构词结构和语义表达上有一定的不同,并不能直接使用上述算法;其次,对于民航不文明旅客的分析和研究中不能只考虑行为信息。不文明旅客之间存在造成相同结果的显式关系和不同行为的隐式关系,且不同行为的隐式关系更具有挖掘价值,要考虑不文明旅客的处罚规则和结果在行为匹配中的相互影响,其行为严重程度取决于行为信息又受处罚结果的影响。
为了解决上述问题,本文在SIF算法的基础上提出了对行为特征和处罚特征融合度量的民航不文明旅客联合相似度匹配(incivilized passenger behavior similar-smooth inverse frequency,IPBS-SIF)算法,面对非同源数据,创新性的将不文明旅客的处罚规则特征引入了计算模型,为处罚规则制定统一量化标准,针对不同行为间的隐式关系进行了挖掘,实现不文明旅客的多粒度联合相似度分析,并对旅客在发生不文明行为之前的潜在程度进行合理预测。对比实验数据表明,改进的IPBS-SIF算法在面对非同源数据时有很好的效果,预测准确度有一定提升。实现航空公司对旅客发生不文明行为之前进行有效监控。
2 SIF算法
SIF算法是一种简单有效的句子向量表示的新方法:该方法引入了“平滑”概念来计算句子中单词向量的加权平均值,然后删除第一个主成分上的平均向量的投影(公共成分去除)。该方法在各种文本相似性任务上表现出比未加权平均值明显更好的性能,并且在大多数任务中甚至超过了一些经测试的监督方法,包括一些RNN和LSTM模型。该方法非常适合于域适应设置,即在各种语料库上训练的单词向量可用于计算不同测试平台中的句子向量。生成的句子向量还联系了语料库上下文语义,使句子表示更为准确。
核心算法如下
(1)
X←{vs∶s∈S}
(2)
vs←vs-uuTvs
(3)
式中:w代表一个词,V代表整个语料库生成的词的全集,vw代表词向量,即 {vw∶w∈V};s代表一个句子或段落,S代表数据中所有句子的全集,vs是句子向量,即 {vs∶s∈S}。 其中a为平滑反频率参数,p(w) 为单词在整个语料库中的频率。为了句子向量和语义空间上下文建立联系,将所有的句子向量组成矩阵X, 得到X的第一奇异向量u, 对式(1)中的vs进行更新。
SIF算法算法对于文本的向量的表示有着很好的效果,但对不文明旅客的分析研究中,面对非同源数据以及旅客造成相同处罚结果的显式关系和不同行为的隐式关系时并不能发挥很好的效果,对社会不文明人员和民航不文明旅客的相似度匹配时准确度不够;其次,不文明旅客行为记录和处罚结果的数据格式与结构不同,不能直接运用到不文明旅客的匹配与预测中去。因此本文做了如下改进。
3 IPBS-SIF算法设计
3.1 处罚特征的标准化度量
在民航不文明旅客的惩处规则中根据其情节严重程度分有不同类型的不文明水平,在不文明旅客的分布规律中,旅客数量所占比随着严重程度的提高而下降;在处罚结果中,也有拘留天数,罚款数额的区别,因此需要对处罚规则进行标准化度量。
(1)不同类型的不文明旅客所占比例不同,因此为保证度量的合理性,引入处罚规则概率P
(4)

(2)不同旅客的处罚结果不同,因此引入不文明旅客行为严重程度归标准化矩阵L
(5)
在不文明旅客的处罚结果中,也有拘留天数,罚款数额的区别,因此需要对处罚规则进行标准化度量。其中:Cij为第i种处罚类型j处罚结果,Max(Cij) 为i类型中j处罚结果中的最大值,Max(Cij)+1 保证了Lij的值域属于 (0,1)。
(3)引入不文明旅客处罚规则的标准化度量矩阵PL
(6)
其中,将处罚规则的概率模型与标准化模型结合起来,形成对不文明旅客处罚规则的标准化度量矩阵PL。PL矩阵的构建使得不同惩处类型与不同惩处结果的不文明旅客有了统一的度量标准,PL值代表着当前不文明行为在惩处规则库中的行为严重程度的衡量。
民航不文明旅客依据其情节严重程度划分共有4个类别:A、B、C、D这4类。旅客的不文明程度随类别梯度的上升(A→D)而上升。将不文明旅客的处罚数据带入到式(6)中运算,并得到每一类不文明旅客的平均PL值,结果见表1。
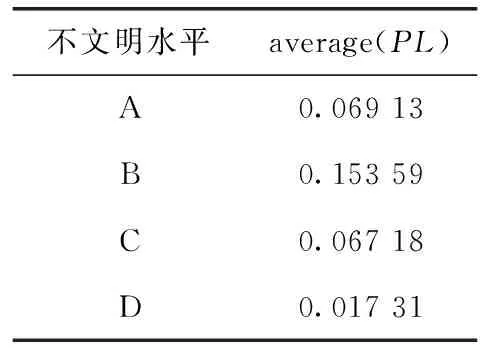
表1 不同不文明水平的平均PL值对比
不文明旅客的average(PL)值见表1,代表着对不同类型的不文明旅客处罚特征统一标准量化后的PL值对比情况,而对于不文明旅客的分布情况如图1所示,代表着不同类型之间所占比例。由两图对比可以看出由于所占比例的大小不同使得不文明旅客的PL值并未跟随处罚类型梯度上升(A→D)而增加,在实际应用中,为了达到理想预期效果,因此对PL的频率模型进行更细致的参数寻优。优化后的标准化度量矩阵如式(8)所示。

图1 不文明旅客类型分布
(4)引入概率模型寻优参数β
(7)
(8)
其中,λ为处罚规则的平滑反频率,β为反频率参数,β∈(10-4,100)。β的引入使得每一类的PL值随处罚梯度上升而增加。本文以ω=2e-5作为步长使β在 (10-4,100) 上寻优,并记录随β值的变化各类average(PL)值的变化情况,实验结果如图2所示。
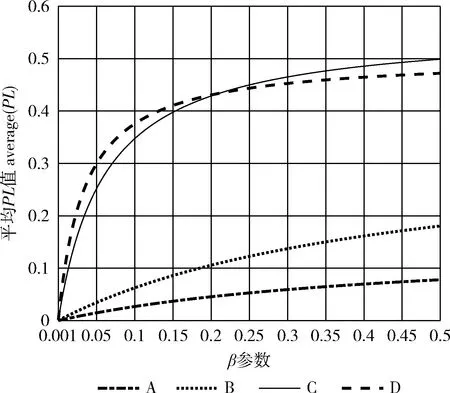
图2 β寻优分布
由图2可知各类值PL随着β的增加而上升,且β在(0.025,0.15)之间符合我们的标准,即各类PL值随处罚梯度的上升(A→D)而上升,本文取β=0.1, 做实验得到图3结果,可以看出优化前和优化后的各类PL值对比情况,优化后的PL值随处罚梯度的上升而增加。
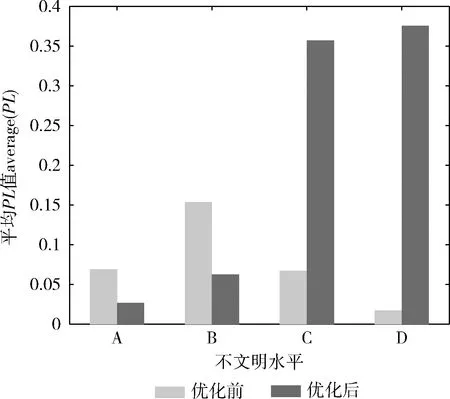
图3 优化前后平均PL值对比
3.2 多粒度度量算法
对于社会不文明人员和民航不文明旅客的行为记录是文本格式,为将不文明行为记录进行联合相似度匹配,本文使用word2vec对文本进行特征提取转化为文本词嵌入表示,再通过伴随平滑反频率词向量加权平均获得文本的句子级向量表示;其次,为减少不文明旅客之间存在造成相同结果的显式关系和不同行为的隐式关系对预测准确度的影响,本文将标准化度量的处罚特征融入进相似度计算。该多粒度度量算法融合了不文明人员的不文明行为特征和惩处结果的处罚特征,丰富不文明旅客与社会不文明人员的特征表示,使得对不文明人员的定量刻画更加充分。多粒度度量算法详细如下所示。
算法1: 多粒度度量算法
输入:
语料库词向量{vw∶w∈V}
不文明行为描述文本库S{s∈S}
行为处罚规则库{Ci,Cij∶i,j∈C}
输出:
行为描述文本向量vs
处罚规则归一化标准度量PLij
(1)for all s in S do
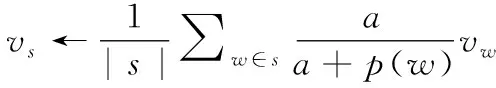
(3)end for
(4)Form matrixX←{vs∶s∈S},
(5)u=First_singular_vec(X)
(6)for all s in S do
(7)vs←uuTvs
(8)end for
(9)for all i,j in C do

(11)end for
具体步骤为:遍历不文明行为描述文本库,通过神经网络skip-gram模型将语料库进行特征提取训练获得词向量vw, 通过SIF算法对词向量加权求和生成句子向量vs, 将所有文本的向量表示组成矩阵X并计算其奇异向量u对vs进行更新;遍历行为处罚规则库将不文明人员的惩处结果通过算法生成惩处特征标准度量值PLij, 算法结束。
3.3 联合相似度匹配算法
面对非同源数据,我们以文本特征相似性为主,处罚特征相似性为辅,进行联合相似度匹配。使用余弦相似度来比较两个文本向量的相似性。使用改进的反正切函数来比较两个处罚特征统一度量值的相似性,并为联合相似度匹配算法设置加权参数α。 联合相似度算法如下所示
(9)
(10)
sims=α·cos(vi,vj)+(1-α)sim(PLi,PLj)
(11)
约束条件
α>(1-α),α∈(0,1)

联合相似度匹配算法详细如下所示。
算法2: 匹配预测算法
输入:
不文明社会人员信息库s_courps
不文明旅客信息库a_courps
输出:
不文社会人员预测结果
(1)for all s in s_courps do
(2) for all a in a_courps do
(3)sims_list=α·cos(vs,va)+(1-α)sim(PLs,PLa)
(4) end for
(5)sort_select(sims_list,top=1)
(6)end for
具体步骤:遍历民航数据列表,使得社会数据列表中的每一条数据通过sims()函数与之做联合相似度计算;通过sort_list()函数排序选择出最相似的一条,并归属到这一类中。该类的不文明等级即为社会不文明人员在民航中的潜在不文明等级。算法结束。
4 实验结果分析
4.1 实验数据
本文实验是采用中国航空运输协会公布的2016年-2018年16批民航不文明旅客行为记录数据;来自于信用中国的民航旅客特定失信人数据2330条;来自于中国裁判文书网、人民检察院信息公开网、法律图书馆、法律家的裁判文书数据:包括危害国家安全,危害公共安全,侵犯财产,妨害社会管理秩序4大类共12 043条数据。我们把所有数据的80%作为训练集,20%作为测试集。来源于社会的数据依据其相似性已人工做好标注。民航不文明旅客依据其情节严重程度划分共有4个类别:行政处罚、行政拘留、行政处罚+拘留、刑事拘留,本文将其定义为A、B、C、D这4类。旅客的不文明严重程度随类别梯度的上升 (A→D) 而上升。民航不文明旅客信息样例见表2,社会不文明人员信息样例见表3。行为记录数据多为30-60字符的短文本。

表2 民航不文明旅客行为信息样例

表3 社会不文明人员信息样例
正如表2和表3所示的数据样例,在社会和民航这两个非同源的领域,对于不文明人员和不文明旅客的行为记录中,存在着构词结构和语义上的差别,如民航记录中中出现的‘航空’、‘航班’、‘乘机’等词,社会记录中出现的‘民警’、‘消防’、‘机动车’等词。这会对两个非同源数据相似性匹配的准确率产生影响。
4.2 实验参数设置
本文采用Word2vec的深度神经网络模型Skip-gram生成词向量,维数为200,单词向量的维数较小不能完全表达单词的语义信息,维数过大导致计算复杂度越大,计算越慢。窗口大小为5,迭代次数选择50。在IPBS-SIF算法中参数a=10-3,β=0.1,α=0.8。
4.3 实验评价指标
为了对本文匹配算法进行衡量,通过计算查准率P、召回率R、F1值、准确率A对实验结果进行度量。在实际的匹配和预测行为中,查准率,召回率,F1值和准确率的定义如下

4.4 实验结果
实验过程中,使用社会不文明人员数据对民航不文明旅客相似度匹配,并预测其在民航发生不文明行为的潜在程度,通过本文改进的IPBS-SIF联合相似度匹配算法与Doc2vec算法、词向量平均算法AverVector、和SIF算法进行实验,分析算法效率。
4.4.1 算法的查准率、查全率和F1值比较
图4为4种算法的查准率比较图,图5为4种算法的查全率比较图,图6为4种算法的F1值比较图。
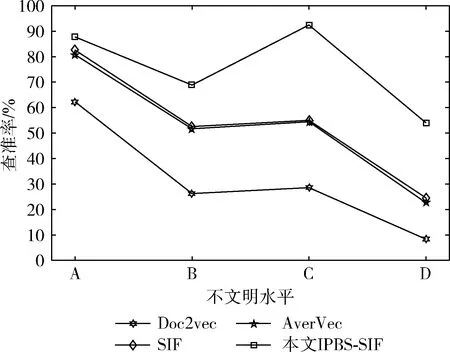
图4 不同算法的查准率比较
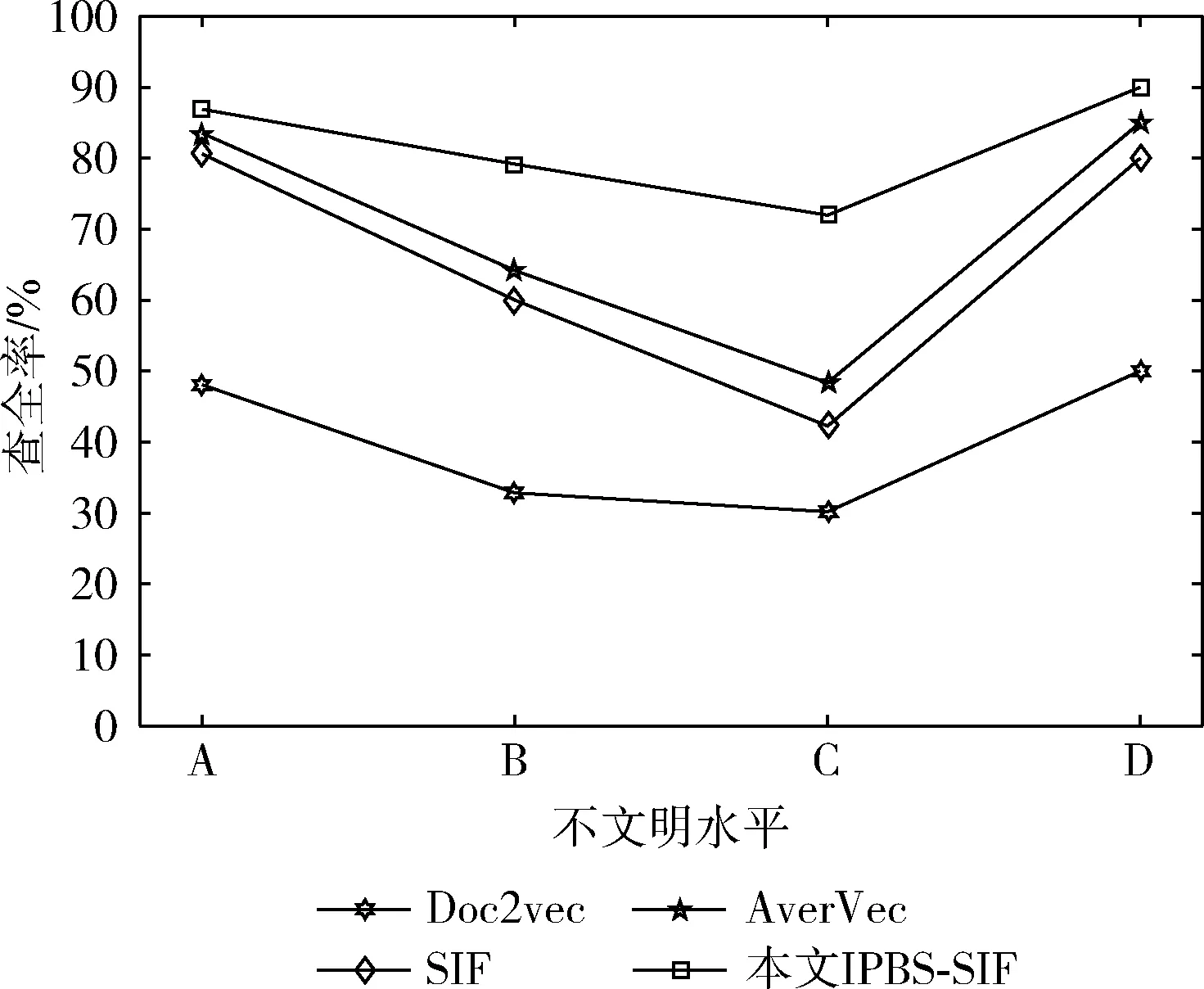
图5 不同算法的查全率比较
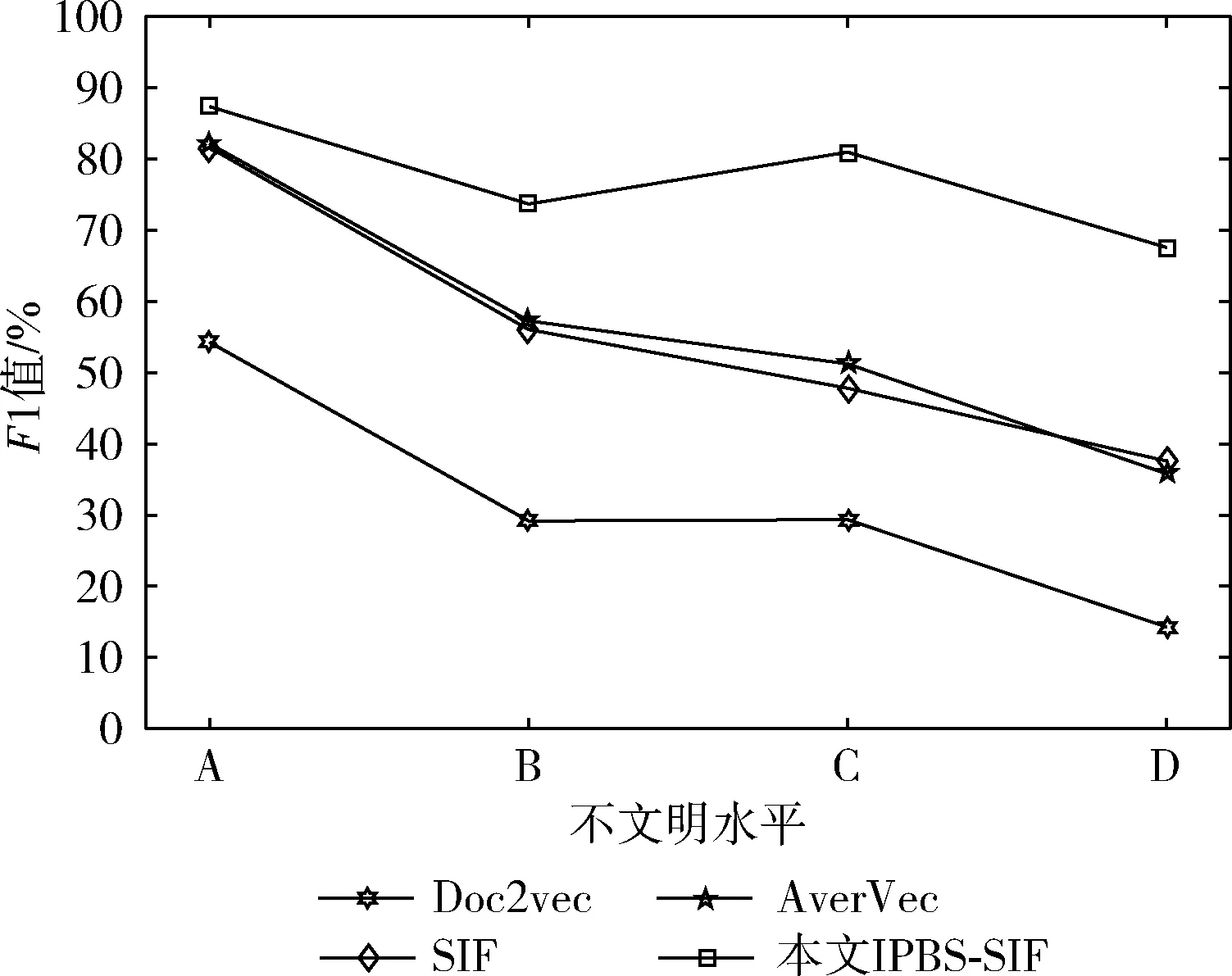
图6 不同算法的F1值比较
图4,图5可以看出不同算法之间在查准率和查全率之间的对比曲线。从图中可以看出无论是查准率还是查全率IPBS-SIF算法都要优于其它算法。在不文明水平A的实验结果上,Doc2vec算法面对短文本并未发挥出优势,AverVec、SIF、IPBS-SIF这3种算法的查准率查全率相差不大,查准率和查全率都保持在80%以上,但随着不文明水平梯度的上升,AverVec、SIF算法性能下降,本文改进的IPBS-SIF算法的效果高出其它算法10%-20%。面对语义差别较大的C类不文明水平的实验结果,所有算法性能都有下降,但本文设计的IPBS-SIF算法仍能保持查准率在70%以上,查全率在80%以上;综合两者的数据观察图6中F1值可以看出Doc2vec算法在面对非同源数据,语义相差较大的短文本时未能发挥其优势,SIF算法和AverVec水平相差不大,但面对非同源数据,效果有时并不理想,随着不文明水平梯度的上升性能有所下降,本文改进的IPBS-SIF算法将处罚特征纳入考虑,弥补了这一缺点,使整体的准确性表现良好,相比其它算法有一定提高。验证了改进后的算法是可以接受的。
4.4.2 算法准确率和耗时比较
在同一实验平台下对相同数据进行实验,各算法的平均准确率和耗时情况见表4(实验中采用的平台为python 3.5集成开发环境,CPU为i5-4200m,内存8 G)。
本文将(A→D)4类的准确率求取平均值来衡量算法的性能。由表4可以看出在4种匹配算法中,在平均准确率上,本文设计的IPBS-SIF算法在准确率上都要高于其它算法,IPBS-SIF算法相比改进之前的SIF算法平均准确率高出约0.136,相比AverVec算法平均准确率高出0.138;在时间性能比较上,Doc2Vec算法的耗时最小,AverVec算法和SIF算法的耗时相当相差不足1 s,IPBS-SIF算法的耗时处于平均水平,是可以被接受的。
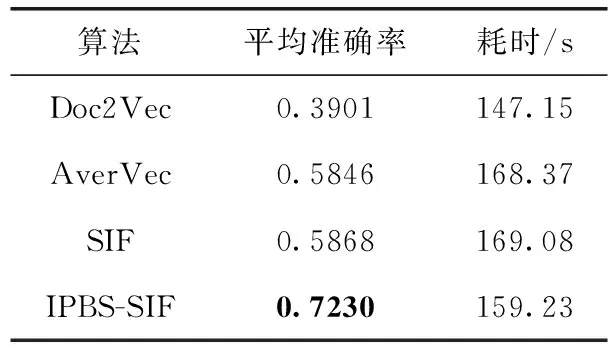
表4 不同算法的平均准确率和耗时比较
4.4.3 不同算法相似度匹配结果
在数据中抽取的实验数据样例见表5,各算法对社会人员在民航中发生不文明行为潜在程度预测结果见表6。

表5 社会与民航实验样例

表6 不同算法的相似度和预测结果比较
表5是在实验数据中抽取的社会与民航中的实验样例,表6为使用不同算法对表5中的数据进行相似度计算以及得到在民航中不文明等级的预测结果。由表5知,面对来自民航和社会的两非同源数据。具有相同的显式处罚结果拘留7天罚款1500元,但是对应其不同行为记录,因非同源数据造成的构词差别如:民航中的“候机区”、“航空运输”;社会中的“包房”、“公共安全”等造成不同行为之间的语义差别较大,影响预测准确度。本文设计的联合相似度匹配算法引入惩处特征弥补了行为记录语义差别的不足,使算法面对相同结果不同行为的显隐式关系时仍有良好效果。从表6可以看出IPBS-SIF算法的联合相似度比其它算法的语义相似度高出0.1-0.2,在预测结果中只有IPBS-SIF预测准确。本文设计的IPBS-SIF算法将处罚特征纳入考虑,挖掘了相同结果与不同行为间的隐式关系,弥补了非同源数据构词不同、语义差别的缺点,使整体的准确性表现良好。
5 结束语
本文通过研究民航不文明旅客的行为信息和惩处规则提出了IPBS-SIF匹配算法,针对不文明旅客之间存在造成相同结果的显式关系和不同行为的隐式关系,对不文明旅客行为特征分析的同时把处罚规则产生的影响纳入考虑。对不文明旅客进行多粒度融合度量。并对社会不文明人员和民航不文明旅客进行联合相似度匹配,预测其在从事民航活动中发生不文明行为的潜在程度。结果表明IPBS-SIF算法克服了因非同源数据构词结构不同、语义差别问题所带来的影响,提高了预测的准确度。为今后民航旅客不文明行为分析与监控提供了新的解决思路。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学物理学报(2022年5期)2022-10-09 08:56:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
小哥白尼(趣味科学)(2021年3期)2021-07-16 07:47:32
河北画报(2020年8期)2020-10-27 02:54:20
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
故事大王(2018年3期)2018-05-03 09:55:52
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
空中之家(2016年1期)2016-05-17 04:47:43
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
