
基于噪声点云的三维场景重建方法
2020-04-23 05:42:16李新乐赵晓燕
计算机工程与设计 2020年4期
张 健,李新乐,宋 莹,王 仁,朱 凡,赵晓燕
(1.中国航天科工集团第二研究院 706所,北京 100854;2.华中科技大学 计算机科学与技术学院,湖北 武汉 430074)
0 引 言
基于深度相机的三维重建技术在纹理特征较少的情景下仍能保持较高的重建精度,具有较好的建模效果,因此得到成为众多学者的热门研究方向[1,2]。许多学者基于深度相机图像提出多种模型重建、优化方法。
目前基于深度相机的三维重建方法多采用TSDF表达模型[3],聚合速度快,对于模型空洞等情况具有较好的鲁棒性。但深度相机返回图像数据所包含的大量噪声数据信息会导致重建模型细节失真乃至重建失败[4]。同时传统TSDF模型存储空间过大,在大场景重建时急剧消耗存储空间,缺失灵活性[5]。
同时在闭环检测处理方面,当前的研究方法多基于点云特征或彩色(RGB)特征实现闭环检测[6],这种算法计算量过大,并且使用场景受限,在处理器性能有限的情况下无法保证实时性,因此一般只能用于离线重建,其实用性则大大降低。
为了解决上述问题,本文使用统一的基于概率点云的方法,从点云模型位姿估计与聚合、子图构建和闭环检测3个方面解决基于深度相机的三维重建问题,从而提高建模的实时性,增强模型质量,以增强实用性。
1 基于概率点云模型的位姿估计与聚合
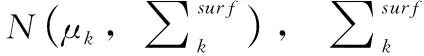
(1)
三维点通过相机投影得到深度图,相机的内参矩阵如式(2)所示
(2)
设相机坐标系内点的坐标为:pk=(x,y,z)T, 根据射影关系,得到深度图内的点到三维点的变换关系,结果如式(3)所示
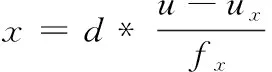
(3)
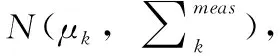
(4)
(5)
综合以上结果,测量点pk同时受表面采样噪声和测量点噪声影响,使用混合高斯分布描述,如式(6)所示
(6)
在基于深度相机的三维重建中,通常使用ICP算法,将位姿估计转化为非线性优化问题,通过迭代的方法求得位姿。当存在大量误匹配的情况时,可以采用随机抽样一致算法RANSAC(random sample consensus)[8],在每次迭代的过程中随机抽取3对点计算位姿,计算内点数目,使用内点数目最多的位姿作为最终结果。这种做法在位姿估计的过程中没有充分考虑数据噪声的影响,导致精确度不足。采用SLAM算法中图优化的思想,充分考虑点云的噪声,通过最小化马氏距离的方法进行位姿求解。
输入连续的两帧深度图,记对应的点云为Vs和Vt, 计算两者中点的对应关系。对于Vs中的点ps,Vt中离ps最近的点pt为相应的对应点,使用近似最近邻算法得到。优化算法中使用的能量函数为对应点之间的欧式距离,设Vs到Vt的变换矩阵为T,其中旋转部分为R,平移部分为t,则对应点之间的误差如式(7)所示
Δp=Rps+t-pt
(7)

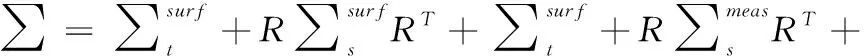
(8)
求出误差式和协方差矩阵后,使用协方差矩阵的逆作为权重,得到马氏距离[7],结果如式(9)所示
E=(Δp)T∑-1(Δp)
(9)
使用高斯牛顿法或者LM法最小化马氏距离求得变换矩阵。由于旋转矩阵R属于特殊正交群,不构成子空间,优化算法中增加步长的步骤会导致求得的R不满足旋转矩阵的条件,使用指数映射的方法,引入3维向量φ, 令
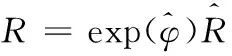
(10)
Δp=e(x)+JΔx
(11)
其中,J为雅各比矩阵。将e(x)简记为e,把式(11)带入式(9),得
Ek=ck+2bkΔx+ΔxTHkΔx
(12)
其中,ck=eT∑-1e,bk=eT∑-1J,Hk=JT∑-1J。
以上是对一对对应点之间的马氏距离的推导以及相应的线性化,实际优化的目标为所有对应点之间的马氏距离
E=∑Ek=∑ck+2∑bkΔx+ΔxT∑HkΔx
(13)
令c=∑ck,b=∑bk, 其中b为1×3维矩阵,H为3×3维矩阵。由于式(13)求和过程中的耦合度较低,直接用CUDA加速的算法进行矩阵的求和。求解方程HΔx=-bT得到本次迭代的步长Δx,使用步长更新x。
为了提高GPU的利用率,使用一种全局的注册方法,将所有帧的位姿同时优化,增加GPU数据的吞吐量,提高硬件的使用效率。设需要对N帧的位姿进行估计,第i帧记为Di, 求出第i帧和i-1帧之间点的对应关系,使用Di到Di-1的位姿关系Ti,i-1作为约束。则优化目标函数为所有对应点之间的马氏距离之和,使用高斯牛顿法对能量函数进行优化,得到帧与帧之间的位姿关系,进而通过累乘得到帧与模型之间的位姿关系。这种全局的注册方法使用累乘计算位姿,但是帧与帧之间的位姿变化通过全局优化得到,不存在累积误差的问题。
通过位姿估计算法得到每一帧的位姿,将点云变换到世界坐标系中。为了减少点云的冗余度,使用聚合算法将多个注册后的点云融合成全局、统一的点云。聚合算法中关键步骤是根据在位姿估计算法中得到的当前帧和上一帧之间点的对应关系,求得当前帧和当前模型的对应关系,使用哈希表记录帧坐标和模型中点索引的对应关系。哈希表键的类型是二元组 (u,v), 表示深度图中像素的坐标,值的类型是整型,表示对应点在点云模型中的索引,用F表示哈希函数。哈希表有以下操作:
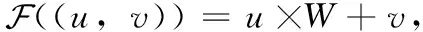


2 基于场景特征的子图构建
为了处理深度相机扫描过程中误差累积的问题,将输入帧根据一定规则划分为片段,每个片段称之为子图[9],子图内部使用第二节叙述的基于点云的位姿估计和聚合算法重建得到模型,整个场景的模型由若干模型片段组成,子图之间采用一定的关系进行约束。引入姿态图来表达子图之间复杂的约束关系。姿态图包括以下部分:稀疏点云和关键帧以及两者之间的约束关系。稀疏点云由关键帧上提取的特征点通过运算得到。姿态图中的约束关系包括以下两种:
(1)点和关键帧之间的约束关系。如果关键帧可以看到稀疏点云中的某个点,则两者之间存在约束关系。对于每一张关键帧,和多个点存在约束关系,对于稀疏点云中的每个点,和多张关键帧存在约束关系。
(2)关键帧和关键帧之间的约束关系。关键帧和关键帧之间的约束关系又称为共视关系。当两张关键帧之间可以看到的共同点的数目超过一定的阈值时,则称这两张关键帧之间拥有共视关系。
基于场景特征进行子图的划分,主要目标是尽量减少冗余子图。当冗余子图过多时,增加了存储空间以及优化算法的时间复杂度,同时对闭环检测造成了干扰。划分的核心思想如下:当相机在扫描过程中走出当前稀疏点云的范围时,当前关键帧对位姿的约束力会变弱,导致累积误差变大,此时应插入关键帧,同时生成新的稀疏,扩大稀疏点云的范围。输入深度图,位姿估计算法只在子图内部进行,累积误差只在子图之间存在。通过对姿态图的优化,调整子图之间的相对位姿关系,消除累积误差。对于每一张关键帧,有位姿T,表示关键帧的点云到稀疏点云之间的变换关系。优化的思想是最小化关键帧到稀疏点云对应点之间的欧式距离,设稀疏点云的集合为 {pi}, 关键帧的集合为 {Ki,Ti}, 其中Ti为关键帧到稀疏点云的位姿变换,通过最小化稀疏点云到对应点的欧式距离之和进行位姿优化。设pi在关键帧中对应点的集合为 (mij,Tij), 则能量函数为
(14)
在稀疏点云中存在杂点,为了消除杂点的影响,每次优化后使用以下条件进行杂点过滤:
(1)能够看到当前点的关键帧数目小于3。说明该点只在两张关键帧中被看到,那么有很大的可能该点是由于误匹配所产生的杂点。
(2)当前点到到关键帧中对应点的平均欧式距离大于阈值。说明该点与各个关键帧中对应点的匹配度较差,如果不去除会导致整体误差较大,对其它点的优化造成影响。
使用两段式的方法与稀疏点云进行匹配,对以下条件进行判断:
(1)与上一张关键帧之间的距离超过20帧。一般在输入深度图的数量超过30帧后累积误差的影响开始变大,如果在20帧以内插入关键帧说明是误判,过多的关键帧会导致算法的时间复杂度变高。
(2)匹配配上的点的数目小于50。说明此时相机已经走出了稀疏点云的范围,稀疏点云对位姿的约束变弱。
(3)匹配上的点的数目比当前关键帧匹配点的数目少90%。说明当前关键帧对输入帧的约束变弱,应当插入新的关键帧,否则当相机继续采集深度图时,会导致匹配不到点,跟踪失败。
3 GPU加速的FPFH算法
FPFH是一种基于直方图的算法[10],通过对点周围的集合特征进行描述,构造描述子。一共有4个步骤:法线估计、构造Darboux frame、计算SPF描述子、计算FPFH描述子。
为了提高FPFH算法的实时性,使用CUDA进行加速。FPFH中有两个关键算法:①邻域搜索算法[11]。邻域搜索算法指求以给定点为中心,半径为r的球形区域内的点,用于法线估计等过程。②k近邻算法[12]。k近邻算法指给定描述子,根据其它描述子到该描述子的距离从小到大进行排序,求出前k个描述子。用于特征点的匹配。在基于中央处理器(central processing unit,CPU)的算法中,这两者均用kd树实现。GPU使用流式计算单元对数据进行处理,同时并行处理的线程可以达到上百个。流式计算单元具有单指令集多数据流的特点,在某一时刻,并行线程处理同样的指令。kd树算法分支太过复杂,具有大量的判断结构存在。故当其中一个线程处理某个分支时,其它线程会陷入等待,导致算法的时间复杂度变高,并且kd树的训练过程中数据之间的耦合度较高,无法取得较大的并行度。故kd树这种数据结构并不适合GPU,需要设计新的数据结构。在GPU算法的设计中,遵循的原则是尽量使用逻辑简单的算法,在访存上做优化。因为GPU总体频率高,每秒钟处理的指令数目多,同时处理的数据量太大,使得流式计算单元和线程之间的带宽不够。
对于GPU加速的邻域搜索算法,核心思想是将点云划分为小方格,通过在小方格内并行搜索提高算法的性能。将点云划分为边长为m的小方格,称为体素(voxels)。为了将点云表示为网格形式,需要计算每个网格内有哪些点。引入新型数据结构,称之为网格点云,如图1所示。

图1 网格点云
得到网格点云的数据结构后,使用数据结构进行范围搜索。设点云中有n个点,对每个点进行范围搜索,搜索半径为r(单位为网格)。对于每个点,需要在 (2r+1)3个网格中进行搜索,则一共需要在n×(2r+1)3个网格中进行搜索。对每个网格使用一个线程进行搜索,将结果存储到对应的数组中。

d=NQ+NR-2QTR
(15)
d的大小为3n×m, 第i行第j列元素表示Q中第i个数据到R中第j个数据的值。对于k近邻算法,需要对d的第i行进行排序,取前k个值即为离对应点最近的k个点。
4 实验结果与分析
使用基于点云的三维重建系统对在真实环境中采集的数据和公开数据集TUM-RGBD数据集进行三维重建,效果图如图2所示。

图2 建模效果
建模算法完全基于深度信息构建,仅使用深度图作为数据的输入,故重建得到的模型没有纹理信息。图2中右下角为TUM-RGBD数据集中桌面数据重建结果,其它图片为在各种施工环境下采集的数据的重建结果。
点云位姿估计算法体现的是局部性,使用TUM RGB-D 数据集,数据集提供深度图以及对应位姿的ground truth。从数据集中截取3段,每段的长度为10帧,分别使用ICP、点到平面的ICP算法以及我们的算法进行位姿估计,使用ground truth位姿以及估计位姿分别对深度图进行变换,然后求得对应点之间的平均欧式距离(RMSE),用于衡量算法的质量,结果见表1。从实验结果中可以看出,点到平面的ICP算法比起点到点的ICP算法具有更好的鲁棒性。同时,由于两种ICP算法均未对数据中的噪声进行合适的建模,在有噪声的情况下性能均弱于我们提出的方法。

表1 RMSE实验结果
子图构建算法表现的是算法的全局性,当扫描轨迹过长时,若不引入子图进行约束,会导致累积误差越来越大。使用TUM-RGB数据集中的desk数据,分别用不带子图构建的算法(即整个跟踪过程中单纯的使用基于点云的位姿估计算法,不进行子图划分)和带子图构建的算法对数据进行处理,绘制出相机运行的轨迹,如图3所示,图3左侧为不带子图构建的相机轨迹,图3右侧为带子图构建相机轨迹。当不使用子图时,位姿的误差会逐渐累积,最终导致相机跟丢,使得重建失败。

图3 相机运行轨迹
对于FPFH算法,可以直接用于点云注册也可以用于闭环检测,从这两个方面进行实验。
对于点云注册,使用GPU加速的FPFH算法对不同的物体进行注册,将不同部分用颜色标出,结果如图4所示。从图中可以看出,GPU加速的FPFH算法对于各种形状的物体都能得到正确的注册结果。

图4 点云注册效果
目前常用的点云注册算法有FPFH(pcl库中的CPU实现版)以及基于神经网络的3DMatch算法。在实际工程中发现,对于点云的注册问题,这几种算法的准确度相差不大,对于特征丰富的点云都可以取得不错的结果,对于特征缺失的点云则会注册失败。从时间复杂度对这3种算法进行分析,对图4中最右边的水管模型进行注册,两个点云中点的数目分别为5.6万和6.3万,时间见表2。

表2 注册算法耗时
从表2中可以看出,对比CPU实现的FPFH算法,GPU加速的FPFH算法具有显著的加速比,3DMatch算法最慢。
对于GPU加速的FPFH算法在闭环检测中的性能,使用Choi的数据集进行定量分析。Choi从不同得三维场景的数据集中采集片段构造数据集,通过召回率和精度两个指标来衡量不同匹配算法的性能。对pcl中的FPFH算法、GPU加速的FPFH算法和3DMatch算法进行测量,见表3。
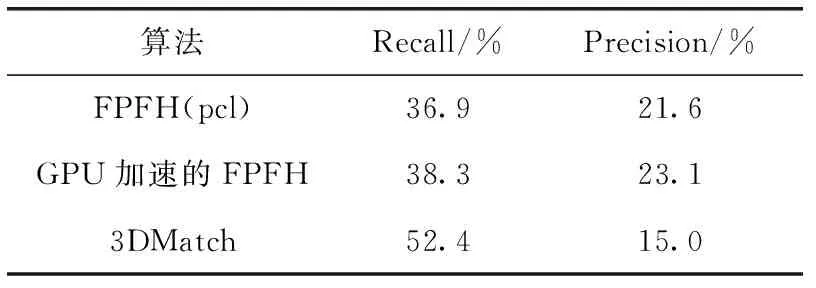
表3 召回度和精确度测量结果
从结果中可以看出,虽然理论上GPU加速的FPFH算法和pcl中的FPFH算法准确度应该是一样的,但是实际上GPU加速的FPFH算法性能稍好一点,这是数据误差造成的。3DMatch算法对比我们的算法优势不明显,但是3DMatch算法时间复杂度太高,且无法用GPU加速(因为基于神经网络的算法原本使用GPU实现),同时3DMatch的处理对象是TSDF模型,空间复杂度较高,故GPU加速的FPFH算法在实用性方面更胜一筹。
5 结束语
基于RGB-D的三维重建算法具有精确度高、视觉效果强等优点。目前,虽然基于RGB-D的三维重建技术已经取得了不错的发展,但是还存在一些不足之处。本文设计了基于点云的三维重建算法,使用概率点云表示模型,充分考虑噪声影响,优化了全局点云注册算法;通过优化子图构建和闭环检测算法,提高了模型建模质量,具有更好的鲁棒性;通过设计基于GPU加速的FPFH算法,保证了建模的实时性要求。后续在GPU显存调度方面仍具有一定的优化空间。
猜你喜欢
数理化解题研究(2022年5期)2022-03-12 09:49:58
初中生学习指导·中考版(2022年1期)2022-02-09 11:46:09
初中生学习指导·中考版(2020年2期)2020-09-10 07:22:44
计算机应用(2019年3期)2019-07-31 12:14:01
大连理工大学学报(2017年4期)2017-08-07 07:03:20
中学生数理化·七年级数学人教版(2016年8期)2016-12-07 07:21:54
软件导刊(2016年9期)2016-11-07 22:22:57
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25 00:37:00
科技视界(2016年2期)2016-03-30 11:17:03
西北工业大学学报(2015年3期)2015-12-14 13:08:46
