
基于聚类分析与说话人识别的语音跟踪
2020-04-23 11:18王俊影
计算机与现代化 2020年4期
郝 敏,刘 航,李 扬,简 单,王俊影
(广东工业大学机电工程学院,广东 广州 510006)
0 引 言
现阶段,语音交互技术例如语音合成、自动语音识别等在现实生活中得到了广泛的应用,但在真实环境下会伴随着如背景噪声、多个说话人声及混响等相关干扰因素,降低了说话人语音的听感和可懂度,从而影响语音交互的实际效果。而语音跟踪技术,可解决从多个说话人干扰或者其他背景噪声中获得高保真、高纯净的目标说话人语音信号的问题[1]。
在公安刑侦监听领域,经常需要将多个说话人的语音进行分离。由于刑侦监听的特殊性,多个说话人的语音信号将由同一拾音器收录,因此无法通过多个不同方向的麦克风进行语音分离。另外,在刑侦监听过程中,输入音频中同一时间点说话的人数具有不确定性。
到目前为止已出现许多有价值的语音分离方法,大体可以分为3类:信号处理的方法[2]、基于计算听觉场景分析的方法[3]和统计建模方法。其中统计建模类方法根据模型的深浅,可分为浅层模型和深层模型,值得关注的是,这3类语音分离方法仅依据领域与定义进行划分,并不进行严格区分,许多高质量的语音分离方法往往对这3类方法均有涉及。
2018年电子科技大学王义圆等人[4]采用麦克风阵列技术,通过多个麦克风阵列组合对多个目标说话人的位置信息进行对准与捕捉。但是,多麦克风系统会衍生出更多潜在的问题,如多麦克风的非线性组合以及配置平稳性问题。
2018年台湾信息技术创新研究中心以视觉信息作为辅助信息[5]来增强语音分离与跟踪系统的性能,然而这种方法同时需要语音和视觉信息,且实际应用中语音和图像可能存在延时问题导致无法适配。
2018年日本NTT信息实验室通过采用有效位编码向量[6-7]或者目标说话人语音信息作为语音分离系统的额外输入,此类方法不仅不是严格意义上的语音跟踪,且无法实现端到端的语音跟踪,与单独的语音跟踪算法相比,由于引入了目标说话人身份信息作为输入,导致训练以及测试的时间复杂度过高。
针对现有技术存在的问题,本文提出一种语音跟踪方法[1,8-9]。这种方法以单声道语音输入为主,面向说话人无关的语音分离问题,提供基于深度聚类(Deep Clustering)的语音分离方法,并对Deep Clustering的实时性以及损失函数进行优化。另外,本文在语音分离的基础上,提供基于说话人识别(GMM-UBM)的语音跟踪方法。
1 整体框架
基于聚类分析与说话人识别的语音跟踪方法,按照流程顺序包含5个处理步骤:语音预处理、端点检测、说话人语音分离、特征提取和说话人语音跟踪模型匹配,具体流程如图1所示。
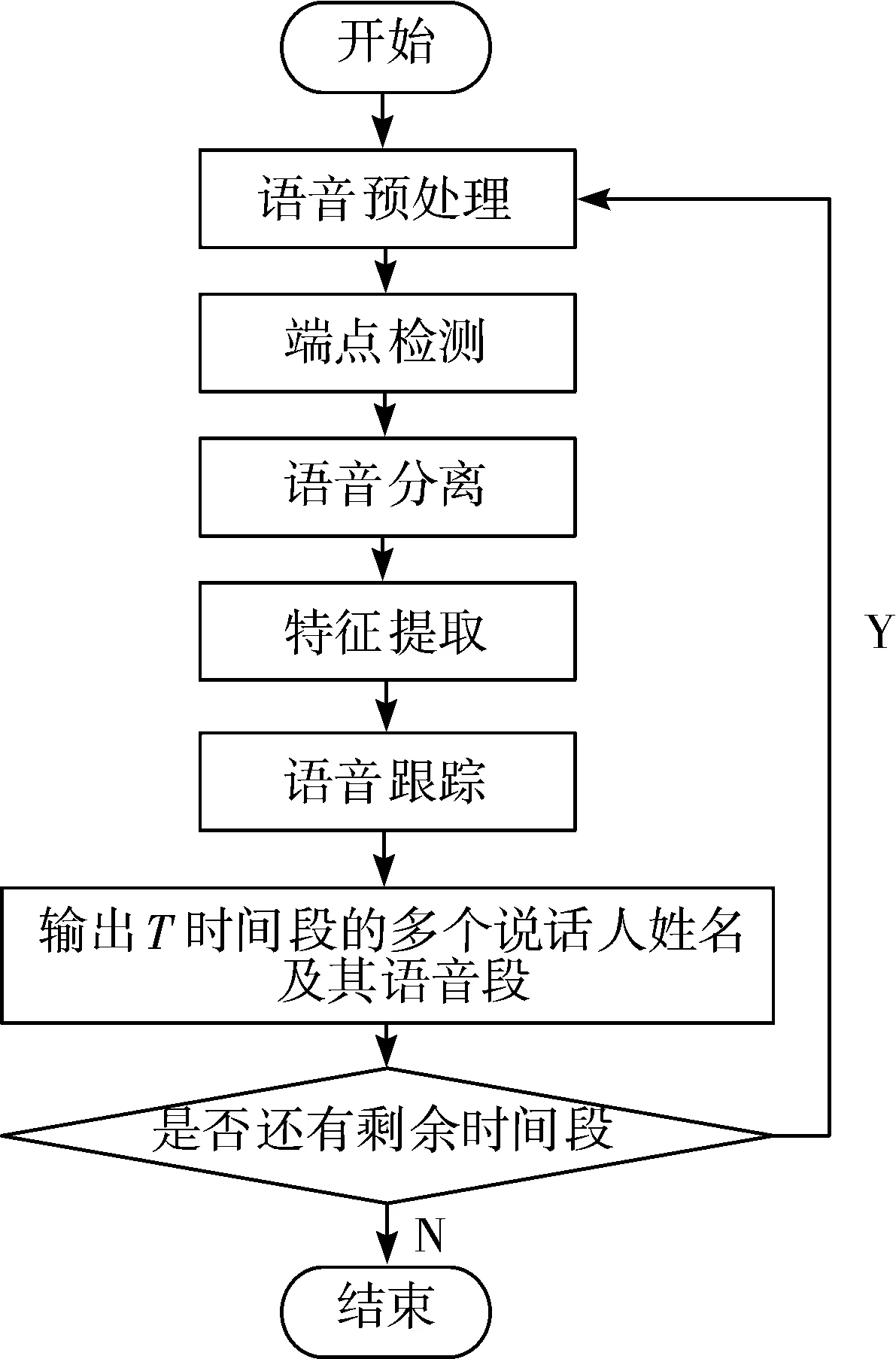
图1 本文算法流程
1.1 语音预处理
语音预处理包含音频采样、量化、预加重、分帧加窗和短时傅里叶变换,文献[5-6]对其进行了详细的说明。
1.2 端点检测
端点检测[10-12]的目的是为了确定语音片段中说话人语音的开始与结束的时刻点,测试表明,人在正常谈话时,有50%左右的语音片段是空语音段,因此去除空语音段可以使有效的语音信号和无用的空语音段得以分离,减少算法后续运算量,可以极大地提高语音应用的实时性,同时增强语音分离的效果。
1.3 语音分离与跟踪的效果评价
根据BSS-EVAL客观评价准则[13],本文测量3个定量值:信伪比(Signal to Artifact Ratio, SAR)、信干比(Signal to Interference Ratio, SIR)、信失比(Signal to Distortion Ratio, SDR)。三者的数值越大,语音的综合分离效果越好。
2 多个说话人语音分离
多个说话人语音分离是鸡尾酒会问题中比较难的分支,特指所有信号由同一麦克风收录,因此无法通过多个不同方向的麦克风解决鸡尾酒会问题。多个说话人语音分离的设定也有很多种,简而言之,就是从多个说话人同时发声的一段音频中,将不同的说话人区分开,以便对其中的某个语音内容进行识别。
2.1 基于LSTM与聚类分析的说话人语音分离
采用时频掩蔽的深度学习方法对于有监督学习分离质量通常较好,但在说话人未知的情况下,分离质量会比较差。
本文采用了说话人无关的深度聚类[14]方法将说话人进行分离,将输入中每个时频单元采用长短期记忆网络(LSTM)映射到K维嵌入向量的特征空间(embedding space),使属于同一说话人或说话声音相似的人的时频单元距离减小从而可聚集一起,即可训练出一个有区分度的K维embedding space,具体算法流程如图2所示。
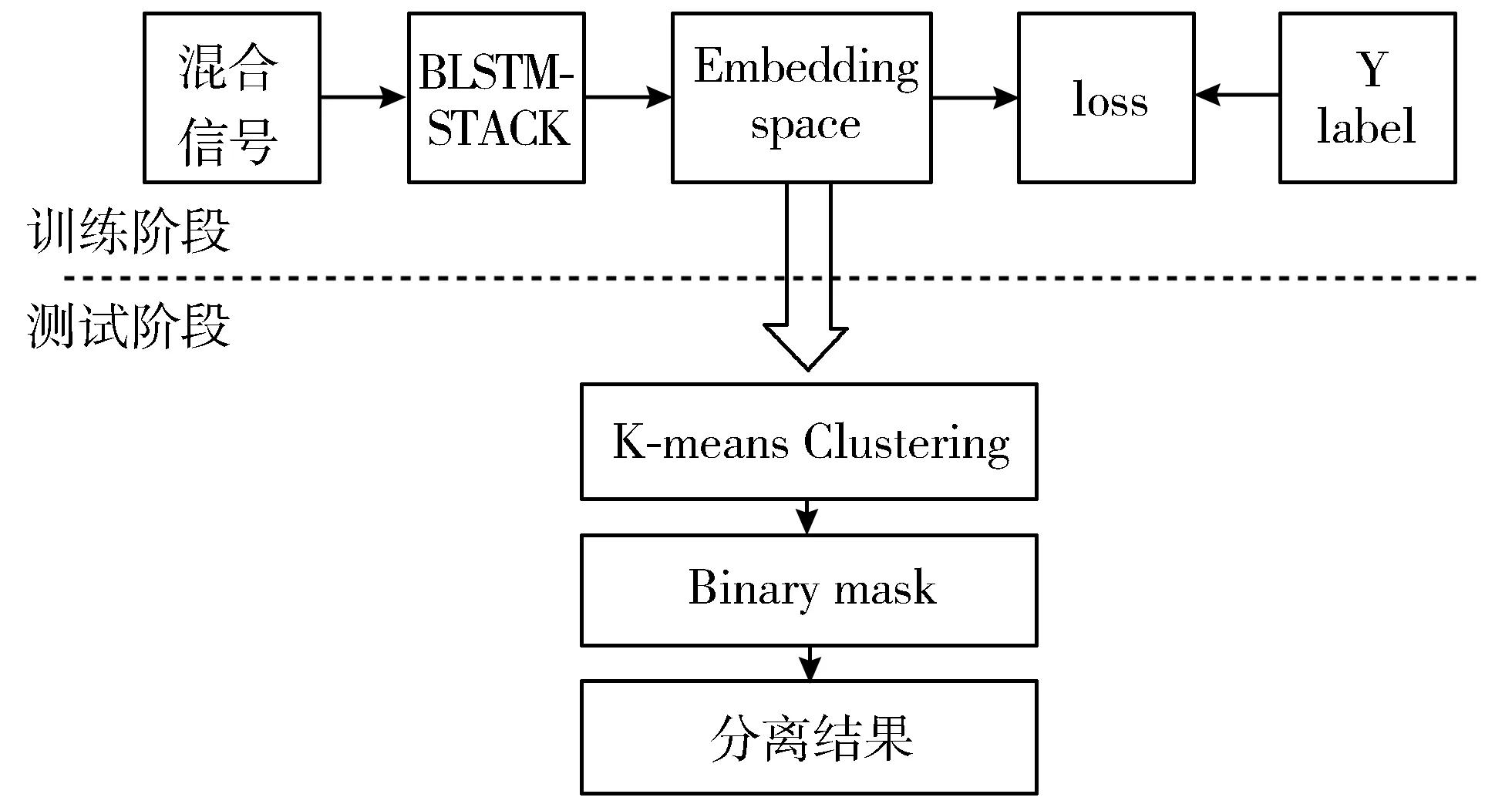
图2 深度聚类算法流程
2.1.1 训练阶段
首先在训练阶段,采用双向长短期记忆网络(Bi-directional LSTM, BLSTM)结构。
设X∈F×T为C个说话人Sc∈F×T混合的幅度谱,c=1,…,C,T和F分别表示信号的帧和频率,BLSTM结构通过函数表示为式(1):

(1)


(2)
其中,di=YYT,N表示常量。在训练的时候为了去除噪声段和静默区,需要采用端点检测方法,小于设置的端点检测阈值时频带在训练阶段被剔除。公式(2)可保证从一个训练样本到下一个训练样本中类别标签的数量和排列保持不变,且使得同一说话人占主导地位的时频单元之间距离最小,而不同的说话人时频单元的距离最大,即可实现说话人分离。
2.1.2 测试阶段
在测试阶段采用K-means算法将经过时频转换的时频点映射到K维的embedding space聚类,聚类属于无监督学习,聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本与x放在一起。K-means设计目的是使各个样本与所在簇的质心的均值的误差平方和(Sum of the Squared Error, SSE)达到最小,即是评价K-means算法最后聚类效果的标准,计算公式如下:
(3)
其中,K-means将SSE作为算法优化的目标,具体过程可概括为如下5个步骤:
1)创建k个点作为k个簇的起始质心,本文根据测试环境实际说话人数来选取。
2)分别计算剩下的元素到k个簇中心的相异度(距离),将这些元素分别规划到相异度最低的簇,在语音中具体对应功率谱的时频单元。
3)根据聚类结果,重新计算k个簇心各自的中心,计算方法即取簇中所有元素各自维度的算术平均值。
4)将元素重新按照新的质心重新聚类。
5)重复步骤3和步骤4,直到结果收敛并输出聚类结果集。
2.2 多个说话人语音分离模型改进
2.2.1 低延迟
当多个说话人语音分离的模型嵌入到助听器或者人工耳蜗植入等应用设备时,降低延迟处理对于用户体验来说极为重要,据Agnew等人[15]的研究表明,当延迟在3~5 ms时用户是可以感知到的,当超过10 ms时体验感就变差。因此,在上述的深度聚类模型中主要考虑3个问题:
1)基于前后时序依赖的BLSTM等深层神经网络结构的时间复杂度过高,无法适用于低延迟应用。
2)基于快速傅里叶变换的信号处理系统,一大部分时间用于语音信号的时频分解,因此窗函数的帧长取值(一般为20~40 ms)需要根据延迟占比做调整。
3)采用聚类K-means算法在确定质心过程中时间过长,考虑固定一个时间段T确定质心,缓存质心的坐标,剩余的时频点根据缓存的质心计算2点之间的距离,从而确定类别,使K-means算法时长缩短。参数比较如表1所示。

表1 深度聚类传统版与低延迟版模型参数
2.2.2 损失函数优化
基于深度聚类的语音分离方法分离质量很大一部分在于经深度神经网络映射的高维特征空间能否具有很好的区分性,以分辨不同的说话人语音特征点。若存在一种较优的距离度量方法便能使混合语音的频谱更容易在映射的高维特征空间分类,引入正则项则是较优的方法。正则化是对学习算法的修改,旨在减少泛化误差而不是训练误差,可通过式(4)表示:
(4)
其中,V和I分别表示特征空间矩阵和单位矩阵,‖·‖F表示矩阵的范数,VVT∈K×K,将特征空间矩阵的对角线元素强制为1,而非对角元素强制为0,使特征空间矩阵正交化,将式(4)进行化简可得式(5):
(5)
因此结合深度聚类的损失函数的总损失函数可用如下公式表示:
(6)
基于特征空间惩罚系数的正则化经过训练后可以得到一种泛化能力更强的特征空间。
3 GMM-UBM说话人识别模型
基于GMM-UBM的语音跟踪模型具体的处理流程如下:
1)在声纹识别注册阶段,对预分离的语音片段中包含的说话人进行语音录制并导入语音库中,打上姓名标签,扩大训练数据量[16]。
2)对语音库中每个姓名标签下的语音记录进行信号预处理,操作包括预加重、分帧加窗以及端点检测。
3)提取说话人的美尔频率倒谱系数(MFCC)参数以及MFCC的一阶偏导、二阶偏导,并将这3个特征按比例进行组合,组成GMM-UBM模型的输入[17]。
4)对每个说话人模型的潜在变量进行估计,采用EM算法,构建声纹识别模型。
5)对预分离的语音片段也按步骤2处理,再转化为功率谱,作为说话人语音分离模型的输入。
6)经过说话人语音分离模型得到多个说话人的语音的时频掩蔽,并通过混合信号与时频掩蔽做内积运算得到多个说话人语音功率谱。
7)对多个说话人语音波形进行预处理,再按步骤3处理,得到GMM-UBM模型的测试输入。
8)将步骤7中的结果输入到构建的声纹识别模型中进行打分决策。
9)按照系统的输入,经处理后输出分离的说话人语音。
3.1 构建GMM-UBM说话人模型
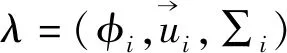
(7)
然后考虑求模型参数λ的极大似然估计,经过log函数转化为式(8):
(8)
一般用期望最大化算法(Expectation Maximization, EM)对GMM模型参数进行估计。
3.2 基于EM算法的参数估计
EM算法是由文献[19-20]提出的可迭代收敛算法,其思想是利用杰森不等式找到当前λ的L(λ|X)的最新下界,然后更新模型参数λ使L(λ|X)不断逼近极大值的过程。为此引入辅助函数Q,Q函数定义如下:
Q(λ,λj)=Ei[logP(X,Zij|λ)|X,λj]
(9)
其中,Q函数与L(λ|X)具有相同的增减性,为使L(λ|X)尽可能增大,可化简λ的表达式如下:
(10)
式(10)即为EM算法的原型。
3.3 说话人自适应MAP
在采用EM算法训练获取到一个稳定的说话人无关UBM模型后,接着采用最大后验准则(Maximum A Posteriori, MAP)[21]将UBM与目标说话人语音特征混合计算,生成关于目标说话人的GMM。假设给定目标的语音特征向量X=(x1,x2,…,xT),说话人自适应具体步骤如下:
1)计算目标语音特征向量中的每个向量在第i个高斯分布条件下的概率,可得:
(11)
2)首先根据步骤1的处理结果,求得说话人目标的权重系数、均值以及方差:
(12)
(13)
(14)
然后根据上述的说话人目标的权重系数、均值以及方差更新说话人的GMM模型:
(15)
(16)
(17)

(18)
其中,τ为一个经验值,表示UBM模型与说话人GMM模型的关联程度,本文取值为16。
3.4 目标说话人辨认
在说话人确认阶段,根据上述的说话人特征自适应获取到目标说话人的GMM,采用最大后验概率对目标说话人进行辨认,其公式如下:
(19)
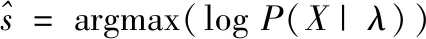
(20)

4 实验设计与结果分析
本实验的操作系统环境为Ubuntu14.04,使用Python2.7以及Tensorflow1.1-gpu进行编程,实验部分采用TIMIT语料库作为实验数据集,TIMIT包含男声与女声在内的630个英文wav录音文件,其中每个人说10个给定的句子,说话时长平均为3~4 s,即短时语音。语音的采样率为16 kHz,而低延迟版的语音采样率为提升实时性,舍弃了部分采样的信息,降低采样率为8 kHz,窗函数为汉明窗,采样点数(FFT)为256,有效采样点数为129,每个点对应不同的频率值。
4.1 深度聚类多说话人语音分离实验
在深度聚类的多个说话人语音分离实验中,训练数据集随机地由363个不同的说话人中抽取2个说话人进行组合。验证数据集由不同于训练集的77个不同的说话人随机混合组成,测试环境的说话人与训练环境的说话人完全不同。为了防止过拟合,通过监控验证集,当在验证集进行训练的损失值不再下降时,便停止训练。语谱图上的端点检测(VAD)阈值设置为40 dB,排除额外的噪声和空语音时频点,减少深度聚类模型训练中不必要的计算量。
为了检验本文提出的基于深度聚类对多个说话人语音分离的效果,本节实验部分在神经网络结构以及不同的损失函数下,比较了多个说话人语音分离模型的分离性能,所有的神经网络层数均为3层,600个隐藏神经单元与上述的采用深度聚类的方法保持一致,且输入的数据均为同一训练集。主要对比分析前馈神经网络、LSTM以及不同的损失函数下的双说话人语音分离。
图3和图4为采用前馈神经网络训练,并以理想时频掩蔽做为计算目标,预训练100次的语谱图对比。

图3 说话人语谱图1

图4 FNN分离的说话人语谱图
图3表示未分离的语谱图,图4表示使用前馈神经网络(FNN)分离出来的语谱图。2幅图形状存在相似性,均无法有效地形成说话人频带,存在很多的噪点。
图5和图6为采用LSTM进行训练,并以理想时频掩蔽作为计算目标,预训练100次语谱图对比。
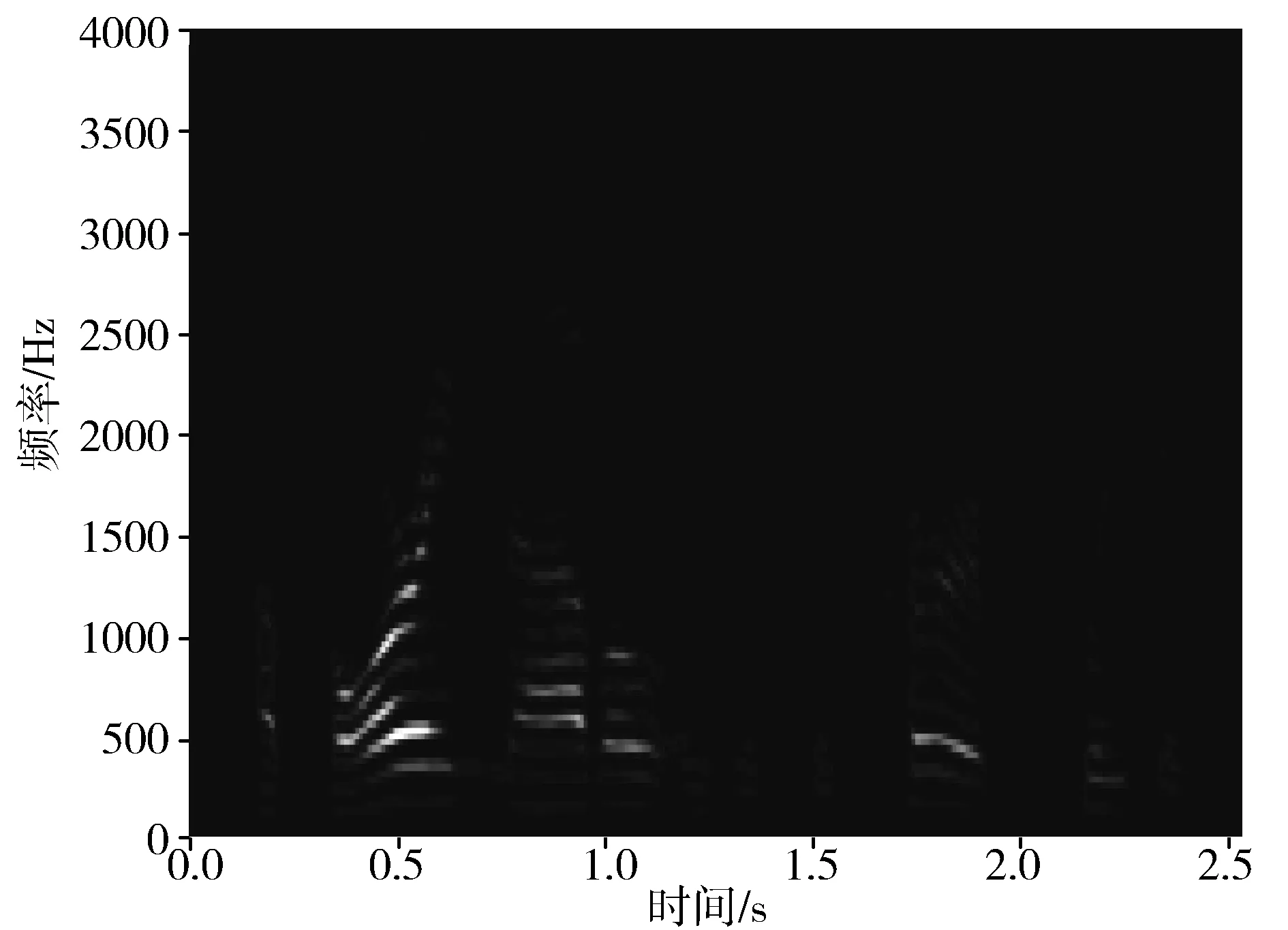
图5 说话人语谱图2

图6 LSTM分离的说话人语谱图
图6为采用LSTM得到的语谱图,相比于使用前馈神经网络,图片中的黑白间隔更大、噪点更少,有效地形成了说话人频带,其分离的语音质量比采用前馈神经网络的效果更好。
4.2 深度聚类低延迟与损失函数优化
在低延迟的深度聚类实验仿真中,按2.2.1节参数进行调参修改,包括降低语音信息采样率为8 kHz、采用固定一个时间段T确定质心、缓存质心的坐标以缩短K-means聚类时间等。值得注意的是,在确定质心的过程中应该随机抽取,尽量均匀类别并随机抽取不同说话人的语音数据为先,因为初始数据分布越均匀,质心坐标则描述越精确。最后得到低延迟深度聚类模型,如图7所示,图中表示在K-means聚类中缓存不同时间步长的质心,在SDR、SIR以及SAR上评估低延迟深度聚类的语音分离性能。其中,最低的缓存时间为100 ms,且缓存时长为300 ms时可达到5.2 dB,当缓存时长超过300 ms并不会有显著的语音分离质量提升。
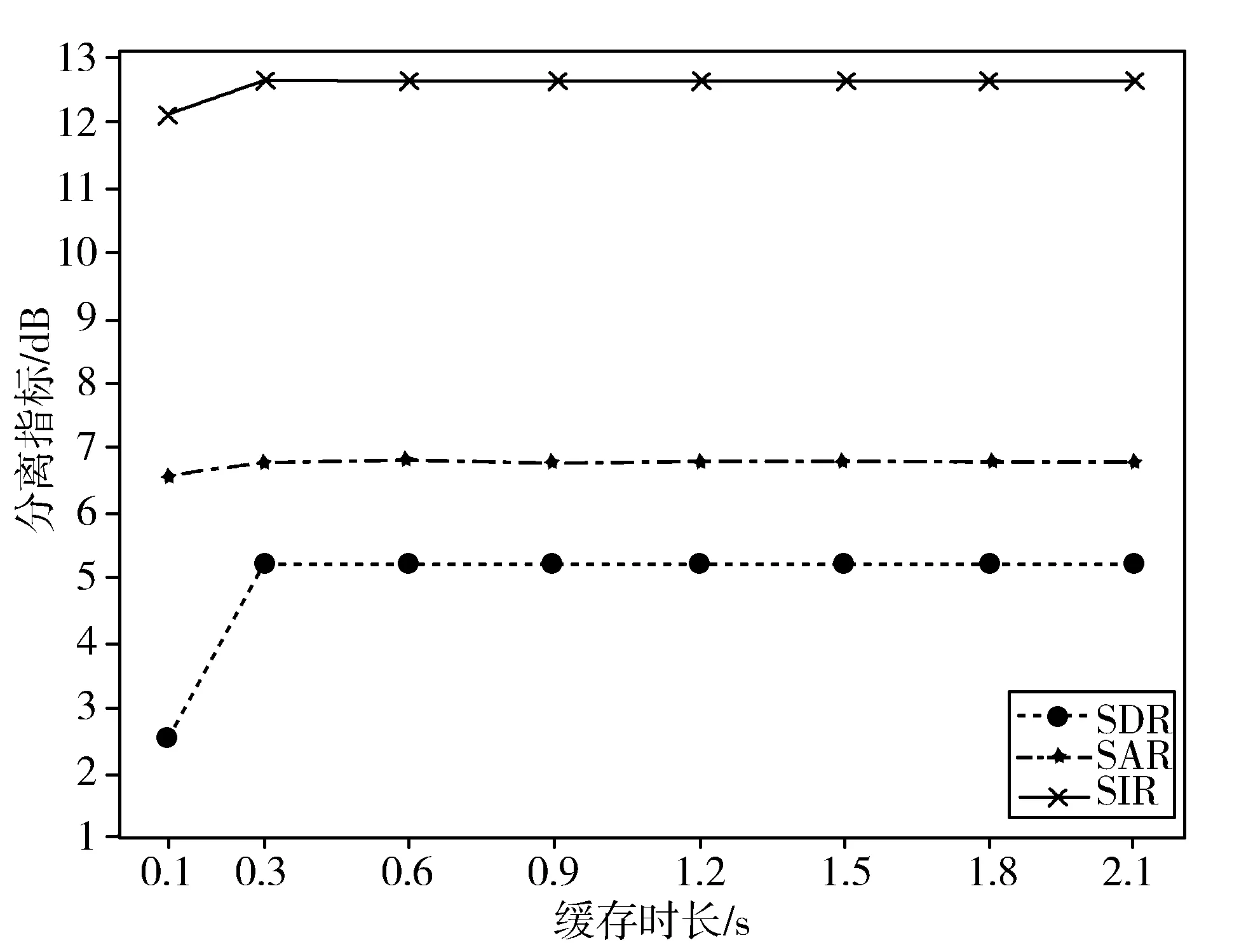
图7 深度聚类模型的分离指标估计
BLSTM相比于LSTM,embedding维度K=40,在其他参数保持不变的情况下,训练的时间复杂度更高,所以低延迟版本中将采用LSTM网络结构,如表2所示,采用BLSTM的语音分离质量明显高于窗长为8 ms与32 ms的LSTM,因为BLSTM更能挖掘语音上下文的相关性,提高语音的分离质量,而采用1.5 s的缓存时长的低延迟版本中,在降低采样率的同时,SDR仅下降2.3 dB。

表2 深度聚类分离指标估计
为分析引入正则项以及不同性别组合下的语音分离质量,将原语音数据集按等比例数据构造3份混合语音数据集,具体采用男声与女声、男声与男声、女声与女声3种规则混合原语音数据,并经过特征提取序列化为.pkl文件。除深度聚类中embedding空间维度K外,其他参数保持不变,计算SDR语音的评价指标,结果如表3所示。

表3 深度聚类引入正则项语音分离SDR评估
从表3可知,男声和女声的混合语音分离质量要明显高于其他语音混合的效果,因为男性与女性语音特征相对更容易区分,具有不同的发音时长以及频率分布。而加入对embedding特征空间的正则项后,可提升语音的分离质量,特别是在男声与女声的语音分离上,但正则项对相同性别的混合语音分离并不明显,甚至略微有降低,在embedding的特征空间维度K=20时,引入正则项并不能提升语音的分离质量。
4.3 GMM-UBM说话人识别实验
在GMM-UBM的说话人辨认仿真实验中,从TIMIT库中抽取100个说话人的全部语音(1000个语音段)用于UBM预训练,在多目标说话人模型的训练中,使用不同于UBM预训练的部分语音段用于训练各自的说话人模型,其中提取的MFCC的特征维度为13,分别取每人各5、7、9段语音用于训练。实验结果如图8所示。

图8 不同高斯混合模型阶数下的识别率
根据模型复杂度与UBM模型性能的相关性可知,当UBM中单个高斯分布数量越多,即UBM模型的阶数越多,UBM模型在充分训练的情况下,就能覆盖目标说话人所有的音域特征,通过MAP自适应调整为目标说话人模型的识别性能更好。但当阶数达到一定量级后,性能提升愈不明显,如图8所示,分别用1、2、4、8、16、32、64个高斯分布密度个数用于测试。从实验结果可知,在高斯混合模型阶数较低的时候,随着阶数的增加,GMM-UBM模型识别率越高,但当达到32阶后,识别率趋于平稳且训练时长显著增大,因为更高阶数的模型需要时序更长的语音数据才能精确刻画目标说话人的语音特征,阶数更高的GMM中的单个高斯分布在同等数据的情况下反而由于训练不够充分,导致GMM-UBM模型精确度不够、鲁棒性不足。值得注意的是,GMM-UBM在短时语音(约3 s测试语音)的识别率仍能达到84%的识别率,且与复杂的深层模型相比,计算量低,实时性比较好。
同时在本次实验中,为分析使用聚类分析方法分离语音后进行识别的准确率,设计了比对试验。即测试语音为3 s,比对的训练目标说话人数为37,说话人模型阶数均为32,训练语音分别约为3 s、6 s、12 s、16 s的情况下的实验效果,如表4所示。

表4 GMM-UBM识别率
从表4可知,在GMM-UBM模型其他参数均保持一致的前提下,随着训练语音数据的增加,识别率显著提高,因为训练语音数据越长,涵盖的说话人的音域特征越广,说话人辨认系统匹配目标说话人的效率越高。另外,语音分离后再进行识别,识别率明显提高,因为语音分离后,语音的信伪比、信干比以及信失比均有所提高,从而导致语音中的特征参数更突出,识别效果更显著。
5 结束语
本文提出了基于聚类分析与说话人识别的语音跟踪算法。算法首先使用改进的聚类分析方法进行语音分离,具体包括在K-means聚类中对质心进行缓存并降低采样率以及在embedding特征空间引入正则项。其次,算法采用GMM-UBM说话人模型进行语音跟踪。
本文实验部分首先对说话人语音分离部分进行仿真,包括混合语音数据的构造,如男声与女声混合语音的分离效果对比等。实验结果表明改进的聚类分析方法可以有效提高算法的实时性及语音分离质量。然后对说话人识别进行仿真,仿真结果显示使用GMM-UBM模型在3 s语音的测试中具有84%的识别率。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
北京航空航天大学学报(2021年4期)2021-11-24
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
宇航计测技术(2018年3期)2018-09-08
应用科技(2015年5期)2015-12-09
舰船科学技术(2015年8期)2015-02-27
航天器工程(2014年5期)2014-03-11
