
应用于并行绘制系统负载均衡的改进随机森林算法
2020-04-22 23:38李君怡郭赛赛
现代计算机 2020年8期
李君怡,郭赛赛
(四川大学计算机学院,成都610065)
0 引言
近年来,随着图形软硬件的发展和互联网的广泛应用,实时交互娱乐系统伴随着日益强烈的需求得到了快速的发展。人们追求更真实更流畅的交互体验,这对图形绘制技术在输出分辨率和输出帧率等方面提出了更高的要求。单GPU 难以满足如此巨大的计算需求,并行绘制[1]作为解决这个问题的有效途径,通过将大型绘制应用场景中的绘制任务划分成若干绘制子任务,合理地分配给多个绘制节点,当所有节点绘制完成后,将其绘制结果进行拼接形成最终绘制结果,以此达到提高整体绘制效率的目的。
本文采用的基于sort-first 的并行绘制系统,由一个控制节点,若干绘制节点以及显示节点组成。控制节点将屏幕划分为若干个子屏,每个子屏对应一个绘制节点负责执行子屏的绘制任务,各个子屏绘制结束后,由控制节点完成子屏画面拼接工作,最终将完整的画面输出显示。在这个过程中,控制节点如何将绘制任务均衡地分配给各个绘制节点,以此减少用于同步各绘制节点的绘制结果花费的额外等待时间,成为了关键点。如果每个绘制节点在开始绘制一帧画面之前,获取到绘制负载均衡时的屏幕划分,就能实时地调度绘制节点以负载均衡的状态执行绘制任务,避免负载失衡所带来的额外时间花销。借助机器学习中的随机森林模型来预测各个子屏的绘制时间[2],控制节点再根据预测结果不断调整屏幕划分,直至各子屏绘制时间相当,就能实现负载均衡。在并行绘制系统达到负载均衡的过程中,随机森林的预测准确度越高,绘制节点所需调整次数越少,就能在更短的时间内达到负载均衡状态。因此,可以通过改进随机森林提升模型预测准确度,来提高并行绘制系统的帧率。
1 相关研究
原始随机森林在处理分类任务时,各个决策树对预测样本的类别进行投票,最终选择投票最多的类作为最终预测结果;而回归任务则通过对所有决策树的预测值求均值,作为最终预测结果。这两种方法简单且易于实现,但并不区分决策树预测性能的优劣,所有决策树对最终结果的贡献度一样,这显然不合理。在提升随机森林预测准确性的研究中,研究者提出了不同的加权随机森林算法。Hongbo Li 等人提出的TWRT(Trees Weighting Random Forest)[3],利用每棵决策树各自的OOB(Out Of Bag)[4]数据作集为验证集,以OOB 数据预测正确率为决策树赋权重。在预测阶段,所有决策树加权投票,选择投票最高的类作为预测类。Xiang Gao 等人利用OOB 数据测试决策树[5],根据决策树的测试结果中真阳性率(True Positive Rate,TPR)与阳性预测值(Positive Predict Value,PPV),为决策树赋予权重,并将其应用员工离职预测,获得了比原始RF 更高的预测性能。Pham 等人则将Cesaro 平均法应用于随机森林预测[6],使用测试数据对决策树的预测性能进行排序后,提出了一种只与决策树排列序号有关的权重来提高预测准确性。Shiyang Xuan 提出的RWRT[7]根据所有测试数据在决策树上累计的正确率和错误率之间的概率差来计算决策树权重,这在预测不平衡以及非高维特征数据时,具有较好的预测性能。
众多加权随机森林的算法中,都着重为决策树赋予权重,权重都是固定的,且都针对分类问题,这些方法并不适用于并行系统的负载预测。因此,本文提出一种改进随机森林,为每个叶子节点设置一个动态更新的置信度,使得预测性能好的叶子节点不断积累更高的权重,对最终的预测结果产生更大的影响,同时不断弱化预测性能差的叶子节点,由此来提高随机森林预测准确性。
2 算法实现
2.1 问题分析
为决策树赋予权重能在一定程度上提升随机森林的预测准确度,但对于一棵决策树来说,实际每次预测都是由待预测样本落入的叶子节点给出具体预测值。而为树赋予权重,就是将该树的所有叶子节点的权重设置为相同的值,并不对各叶子节点的预测性能优劣做区分。现实情况中,叶子节点的预测性能优劣,与该叶子中所包含训练样本的纯度或方差,以及其分布有关。一方面,决策树的构造过程中使用到的属性划分函数,如基尼指数[8]、信息增益,决定了决策树是朝着节点纯度更高的叶子节点方向生长的,因此叶子节点纯度越高,则其决策更具有确定性;另一方面,若待预测的数据落入到一个叶子节点后,与该节点中的训练样本“距离”较远,则不能得到较好的预测结果。根据分析,同一棵决策树叶子节点之间也存在预测性能差异,因此,不能以决策树的权重来表示所有叶子节点的权重,应从决策树级别上,为每个叶子节点赋予与其预测性能相关的权重。
2.2 改进随机森林算法概述
结合并行绘制的应用背景,本文提出了叶子节点权重更新算法。叶子节点权重更新是指对于已构建完成的随机森林,在预测前为决策树每个叶子节点设定一个初始权重。在预测阶段,对于第一次用于预测的叶子节点,其权重即为初始权重;随着待预测的样本逐一落入决策树的叶子节点中,对于多次落入样本的叶子节点,其权重是根据已落入的样本的预测准确率来计算的。每个样本的最终预测结果,由落入的所有叶子节点加权得出。如图1 所示,在一个包含了m 棵决策树的随机森林T 中,假设决策树t1 的初始叶子节点权重为wt1。当第一个待预测样本sample 根据决策树t1 的划分规则落入叶子节点leaft1,将叶子节点leaft1的权重wt1以及其所代表的决策值vleaf1_t1代入公式(1)计算最终预测值:

获取样本预测值以及真实值后,计算预测准确度,结合预测准确度来更新leaft1的权重,更新后的新权重wt1*将作为下一个落入leaft1的待测试样本在leaft1上的权重。决策树每个被用于预测的叶子节点,按照这种动态权重计算方式不断更新权重。
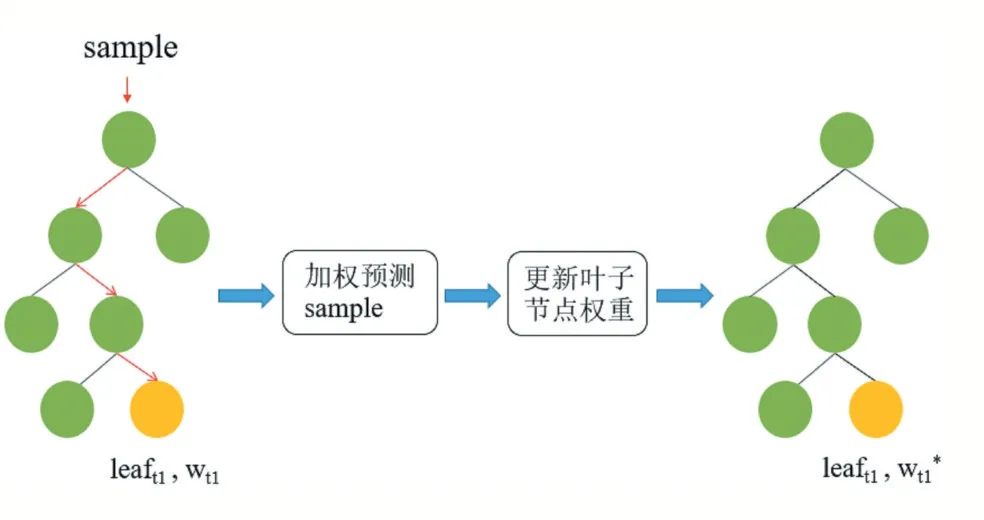
图1 叶子节点权重“预测+更新”过程
一般为决策树赋予权重的算法都采用静态权重,权重一旦确定后,在预测阶段就不能更改。当预测数据与训练数据分布不同时,往往得不到好的预测结果。而这种动态的叶子节点权重更新方法,借助于并行绘制系统在绘制完一帧画面后,能立即获得该帧的实际绘制时间,来计算预测准确率,反映叶子节点对当前数据的预测性能。随着待预测样本数量的增加,该叶子节点通过这种“预测+更新”的方式不断累积历史预测准确来更新自身权重,获得更真实的预测可信度。
2.3 权重更新方法
叶子节点权重更新过程中,关键是如何根据预测准确度调整权重。假设存在一个预测准确度阈值σ,当样本预测准确度高于σ,则认为样本所落入的叶子节点预测准确率相对较好,应适当提升其权重;当样本预测准确度低于σ,则适当降低叶子节点的权重。通过与预测准确度阈值对比,来判断预测性能的优劣,从而调整叶子节点的权重。为了能客观地反映叶子节点的预测性能优劣,本文选择将历史样本预测准确度平均值作为阈值σ。对于第n 个待预测样本xn,在获取了xn的预测值以及真实值后,按照公式(2)来计算随机森林对xn的预测准确度,并按照公式(3)来计算预测当前准确度阈值σn:
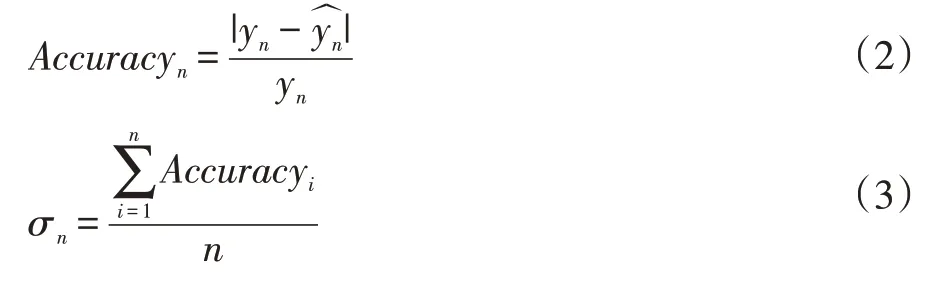

其中,wcurrent表示叶子节点leaft更新前的权重,也是本次预测所使用的权重,当叶子节点leaft第一次落入样本被用于预测时,初始权重设置为1。Accuracyleaf_t表示叶子节点leaft对样本xn的预测准确度,Accuracyleaf_t与sigmoid 函数分别表示为公式(5)与公式(6):

公式(6)中,k 作为sigmoid 函数的平滑参数,为一个固定值。本次更新的叶子节点leaft的权重wupdate将作为下一个落入leaft的样本的预测权重。
3 实验结果与分析
本文研究的目的在于提升随机森林对绘制帧负载的预测准确率。因此,实验部分将计算原始随机森林与改进随机森林对相同绘制帧的负载预测结果的MSE(Mean Squared Error)[9]与R2Score(Coefficient of Determination)[10],来对比两种方法的预测效果。MSE 用于反映预测值与真值之间差异程度,MSE 值越低,代表模型的预测准确性越高;R2Score 用于反映线性或非线性拟合程度好坏,其值介于0 到1 之间,越接近1 表示模型拟合程度越高。表1 表示了原始RF 与改进RF 预测性能对比情况:
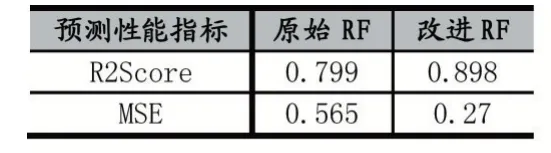
表1 原始RF 与改进RF 预测性能对比
从表1 可以看出,改进RF 相对于原始RF,R2Score 更接近1,MSE 值也越低,说明改进后的随机森林在对真值的拟合程度更好,预测值与真值之间的差异也更小。
4 结语
本文为了提升随机森林对并行绘制系统中各个子屏负载的预测准确度,提出了一种改进随机森林算法。利用并行绘制系统能在绘制过程中及时反馈每一帧的真实绘制时间,实时计算随机森林预测准确度,来为决策树的叶子节点赋予与其真实预测性能相符的权重,以此提升了模型的预测准确度,并通过实验证明了改进随机森林的有效性。
猜你喜欢
心理学报(2022年5期)2022-05-16
科海故事博览·下旬刊(2022年4期)2022-05-07
当代陕西(2020年17期)2020-10-28
科学与信息化(2019年28期)2019-10-21
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
科学与财富(2016年32期)2017-03-04
价值工程(2016年32期)2016-12-20
考试周刊(2016年34期)2016-05-28
中小企业管理与科技·中旬刊(2014年10期)2015-02-03
