
城市公共交通发展热点议题分析
2020-04-20 09:15赵己周
交通科技与经济 2020年3期
赵己周,杨 颖
(1.天津市市政工程设计研究院,天津 300051; 2.同济大学,上海 201804)
近年来,世界各大城市都面临着常规公交客流持续下降的困境,造成这一现象的外因主要有轨道交通、私家车以及出租车(含网约车)的分流作用,内因则是常规公交系统自身的服务水平较低,吸引力不足,无法适配居民日益多元的出行需求[1-2]。以天津市常规公交系统为例,由于城市人口规模趋于稳定造成的居民出行总规模基本稳定,加之轨道交通网络不断织密,对主要通道上客流的吸引作用日益增强,导致天津市常规公交客流量自2015年以来逐年下滑(见图 1),加之运营公交所需的人工成本居高不下,造成公交系统的发展陷于停滞,企业经营面临困境。
在上述背景下,各地均对未来城市公共交通系统的发展进行了布局规划,并在规划的过程中注重广泛吸收公众意见,常规的公众意见征集形式主要有意见簿、调查问卷、群众座谈等,这些方式往往耗时较长且覆盖的公众范围有限。社交媒体作为伴随着互联网发展而迅速成长的新型信息交互媒介,吸引了大量用户在其中发表观点、交流看法,也为规划设计人员提供了大量免费的一手信息。相较于传统分析方法,基于网络文本的分析方法具有时效性强、覆盖面广、调研成本低等优势,此外,利用网络文本开展定量分析可有效避免主观判断、个人喜好等主观性因素的干扰,有利于提高分析结果的客观性和准确性。近些年在国内外均有一些学者在不同领域开展基于社交网络信息的分析研究,Fraedrich和Lenz通过搜集各大传媒网站中的用户评论,分析了公众对于自动驾驶技术的看法及接受度[3]。Donchenko等人通过分析当地社交媒体中关于各类社会问题的贴文信息,尝试研究社会发展过程中的隐藏规律以及决定不同社会群体情绪变化的因素[4]。黄思维抽取社交网络中与交通拥堵相关的信息,对交通拥堵信息在社交网络中的传播机理及影响进行分析[5]。潘美瑜等人以微博社交平台为主要数据来源,利用网络爬虫技术实时获取与城市交通系统相关的一系列文本数据,实现对城市交通问题的事件特征提取与致因挖掘,同时研究文本背后的情感特征[6]。李丹妮和梁嘉依托新浪微博博文,对“上海垃圾分类”的相关讨论开展舆情分析[7]。

图1 天津市常住人口、常规公交年客运量、轨道交通年客运量变化图(2006—2018年)
可见基于网络传媒的文本分析研究已在各个领域得到了应用,本文尝试以城市常规公交作为研究对象,提出一套完整的网络文本分析方法,识别网民对于该话题的讨论热点以及情感取向,并以天津市为实例开展分析,尝试对网民讨论中提到的突出问题给出相应改善策略。
1 文本分析方法
在介绍具体的文本分析方法之前,首先定义以下术语:语料,即语言材料,在本文中特指单条的网民评论内容;语料库,指由一组语料构成的语料集合。
1.1 讨论热点分析
准确识别公共交通领域中的社会讨论热点可为规划设计人员开展工作提供借鉴参考。讨论热点分析流程可以概括为语料分词、单个语料关键词提取以及语料库关键词提取。
1.1.1 语料分词
语料分词是将连续的字序列按照一定的规范重新组合成词序列的过程,由于西文的行文规则规定单词间以空格作为自然分隔符,因此在西文语料的处理过程中较少涉及分词问题;但在处理中文语料时此问题无法回避,目前中文分词方法主要有基于词典的分词方法、基于统计的分词方法和基于构词的分词方法[8]。本文采用基于词典的分词工具包——结巴分词完成语料的分词工作,其工作过程如下例:
“故宫的著名景点包括乾清宫、太和殿和午门等。其中乾清宫非常精美,午门是紫禁城的正门。”
经分词后的结果为:
“故宫/的/著名景点/包括/乾/清宫/、/太和殿/和/午门/等/。/其中/乾/清宫/非常/精美/,/午门/是/紫禁城/的/正门/。”
可以看出,“乾清宫”一词未能被工具成功识别,此外,为便利后续操作,形如“的”、“是”、“和”以及标点符号等不表达实际含义的字符(亦被称为停用词)宜从分词结果中移除。因此,在对大规模语料进行分词操作前,建议首先构建自定义词典以及停用词表,以保证较高的分词准确率。
经重新优化后的分词结果为:
“故宫/著名景点/包括/乾清宫/太和殿/午门/乾清宫/精美/午门/紫禁城/正门”
1.1.2 单个语料关键词提取
通常来说,如果某个词在一条语料中出现的频率较高,并且在整体语料库中很少出现,则认为该词具有很好的将该条语料与其它语料区分开的能力,适宜作为关键词。TF-IDF算法正是以此思想为指导,通过计算词频TF(Term Frequency)以及逆文档频率IDF(Inverse Document Frequency)实现语料关键词的识别。
词频TF的计算方法如下:
(1)
由式(1)可知,若某个词在单个语料中出现的次数越多,则该词的词频值越大。
逆文档频率IDF的计算方法如下:
(2)
其中,lg代表求以10为底数的对数,由式(2)可见,若语料库中包含该词的语料数越少,则该词的逆文档频率值越大。
因此,词i在语料j中TF-IDF值的计算方法由式(3)给出:
TF-IDFi,j-TFi,j×IDFi,
(3)
词语在某一语料中的TF-IDF值越大,则说明这个词越适宜作为该语料的关键词。下面通过一个例子演示TF-IDF算法的实现过程(演示未包含对停用词的处理),假设语料库中共包含4条语料:
this is the first document
this is the second second document
and the third one
is this the first document
首先统计每个词在各语料中的词频TF,得到词频矩阵(见表 1)。

表1 示例语料词频矩阵
之后计算每个词的逆文档频率IDF(见表 2)。
最后将上述两表中相对应的元素相乘得到TF-IDF矩阵(见表 3)。

表3 示例语料TF-IDF矩阵
根据单个语料中各词TF-IDF值的大小确定该语料的关键词,如语料1的关键词按照排序结果可取first,this,is,document以及the。
TF-IDF算法易于实现且执行效率较高,但缺陷在于其对出现在文章不同位置的词语均一视同仁,无法体现词语出现位置对重要性的影响。
1.1.3 语料库关键词提取
对单个语料关键词的提取结果进行统计分析,得到能够代表全体语料的关键词。具体地,提取每个语料中按TF-IDF值降序排序后的前k个关键词(若关键词个数不足k个,则按照实际个数提取),并对所有提取出的关键词进行频次统计。
承接上例的结果,取k=2,得到全体语料关键词频次统计表(见表 4)。
1.2 情感取向分析
网络上纷繁的评论信息表达了人们的各种情感色彩和情感倾向,如喜、怒、哀、乐、批评、赞扬等。基于此,研究人员可以利用这些带有主观色彩的评论了解大众舆论对于某一事物的看法。
文本情感取向分析方法主要可分为基于情感词典的情感分析方法和基于机器学习的情感分析方法[9]。基于情感词典的方法是从待测文本中提取特征词后,在情感词典中查找该特征词的情感值,根据累加的情感值进行情感分类。基于机器学习的方法则先基于文本集训练得到分类器,再基于分类器实现对新文本的分类。

表4 示例语料关键词频次统计表
本文采用基于机器学习方法的情感分析工具包——SnowNLP进行语义的情感取向分析,SnowNLP的结果取值介于0和1之间,表达文本代表正面情感的概率,即结果约接近于1表示情感表现越积极,反之则越消极。此工具包已由软件开发者基于网购商品的评论数据进行了训练,但为了适应特定的文本环境,建议对模型进行二次训练。
2 案例分析
笔者首先在新浪微博中,以“天津”和“公交”为检索条件筛选出两个星期之内有价值的微博语料共52条。在构建了自定义词典及停用词表后,取得了较好的分词效果,如下例:
原始语料:早上看到感人一幕,大赞我天津公交676司机,帮助老人下公交车
分词结果:早上/感人/大赞/司机/老人
对完成分词后的单个语料进行关键词提取,并提取每条语料中的前10个关键词,得到所有有效微博语料的关键词频次统计表(见表 5,其中频次为1的关键词已略去)。

表5 微博天津公交话题高频词表
云词图可以更加形象的展示频次统计表所包含的信息(见图 2),图中字号大小基于词语的出现频次。
可以看到,网络上关于天津公交的讨论主要集中在“老人”、“司机”以及“时间”等话题。根据关键词追溯原博文发现关于以上关键词的讨论主要有:

图2 微博天津公交话题云词图
早上看到感人一幕,大赞我天津公交676司机,帮助老人下公交车。
这是一个非常放松的城市,今天路上人很少,公交车上老人很多,我很怀疑年轻人都去哪里啦,太美好啦!
我好像终于知道为什么天津公交车大多数时候车上有至少70%的老人了——因为他们乘公交不用花钱!
今天698公交车让我感觉要飞起来了,天津的司机师傅太生猛了……,还怕不能放下手机享受生活?来天津做公交车吧!
初次来天津,今天印象最深的居然是652路公交车,虽然只坐了七八站,那感觉真的是:司机开车真的猛,柴油发动机马力强劲,下意识地下车前提前站到后门,都有点站不稳!哈哈知乎上看到这是津南三霸?
两辆车前后脚发车,再后面一辆等20分钟,能不能规范一下发车时间?始发站都如此混乱!
835路公交车,在王顶堤商贸城公交站,在有车的情况下,拖延发车时间,请有关部门重视一下。我和母亲在这边等车等了超过四十分钟,从12点55分左右一直等到发博。
可以看出,以上讨论主要集中于老年人免费乘公交车,公交车司机驾驶行为以及公交车运营混乱等话题。
此外,对微博语料进行情感分析的结果总体上较好地反映了语料的情感倾向。例如:“不过,作为城市的窗口,天津的大部分出租车和部分公交车司机,素质真的有待提高”的情感评分为0.045 0;
“现在的京津冀一体化带来的交通便捷,真的是很好的体验。最近跑了天津河北,交通上无缝连接,都与北京地铁无缝连接,公交地铁都可以用北京的交通卡刷卡支付,随便哪个车,跳上去,刷个手机就可以了”的情感评分为0.836 1。
然而,由于网络语言具有表达形式自由以及语言不规范等特征,对于部分语料的情感分析结果不够理想,如:“天津的公交车,还能再人性化一点吗?这腿是真的放不下啊”!一句本是表达对公交车座位间隔的不满,但由于语言表达形式的原因其情感评分结果为0.701 4。
通过所有微博语料情感评分结果的分布情况(见图 3),可以看出公众对天津市公交系统的评价总体上呈“两极化”态势,情感倾向表现为积极与消极的语料数量基本相同,说明天津市公交系统发展取得了一些成绩,但仍在部分领域存在较大的改善空间。
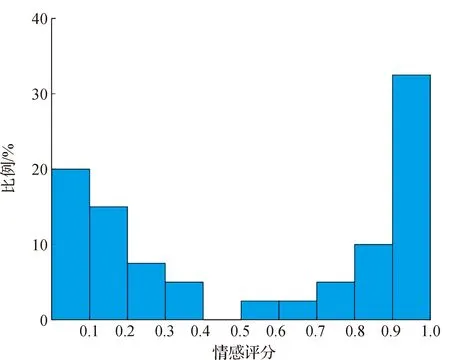
图3 微博天津公交话题情感倾向分布
综合以上分析结果,笔者就公众关注热点对天津市常规公交系统的发展提出如下建议:
1)改革老年人乘车优待制度。自2010年天津市实行65岁以上本地户籍老年人免费乘坐公交车政策以来,虽体现了社会对老年人的关爱,但政策设计的精细化程度不高,无形中正向刺激了老年人的乘车需求,由此派生出相当比例的非刚性出行,增加了高峰时期的车内拥挤度,增加了公交企业承担的风险和压力,形成对社会公共资源的挤占。此外,不常乘坐公交车的老年人无法享受这项政策带来的实惠,也引发对于这项政策公平性的质疑。建议天津可仿效上海的做法,上海市在2016年由老年人综合津贴制度替代了之前的免费乘车制度[10],采取每个月无差别地为所有老人发放一定数额津贴的方式,抑制了部分非刚性出行,体现了老年人福利政策的均等化,取得良好效果。
2)加强对驾驶员及车辆运营的管理。2019年9月,《天津市公共汽车运营成本规制办法(试行)》及其三个配套办法正式实行,办法中设定了运营服务质量考核办法,考核结果与财政补贴直接挂钩,由此激励公交运营企业不断提高经营效率和服务水平,提升群众满意度。办法实施以来取得了一定效果,但仍与公众期待存在差距,建议今后针对群众反映的热点内容继续修订完善考核办法。
3 结 论
城市公共交通系统是实现城市交通可持续发展的重要组成部分,在其发展过程中需要广泛吸收公众的意见建议。为此,本文提出了一套完整的基于社交媒体信息的文本分析方法,并以天津市为实例开展分析,识别网民对于天津市公交系统的讨论热点以及情感取向,最后针对网民讨论较为集中的问题给出相应改善策略。本文提出的文本分析方法简便高效,可快速抽取大量文本中的关键信息,辅助相关工作开展;但社交媒体信息通常单体篇幅较短且表达形式较为随意多样,可能会对识别精度产生影响,因此在开展实际业务时,需首先对所采用的工具进行有针对性的优化训练。
猜你喜欢
通信技术(2021年12期)2022-01-25
今日农业(2021年8期)2021-07-28
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
儿童故事画报·智力大王(2018年1期)2018-10-30
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
中学生英语·外语教学与研究(2008年4期)2008-03-18
