
基于深度神经网络和投影树的高效率动作识别算法
2020-04-18 13:15郭洪涛龙娟娟
计算机应用与软件 2020年4期
郭洪涛 龙娟娟
1(洛阳师范学院信息技术学院 河南 洛阳 471934)2(江南大学数字媒体学院 江苏 无锡 214122)
0 引 言
动作识别和行为理解是目前计算机视觉领域的研究热点[1],其难点在于需要从背景中检测出目标和动作,同时需要准确识别动作的多样化[2]。在传统动作识别方法中,基于动作特征和轨迹特征的识别效果较好[3],但视频中存在遮挡或者同一动作在不同环境下的差异导致传统动作识别方法的准确率难以得到提高。传统方法对某些动作具有较强的识别能力,但对动作多样化的识别能力存在明显的不足[4]。
随着近期深度学习技术在模式识别领域的广泛应用,日益增多的研究人员将深度学习技术应用到视频识别的领域中[5],包括:基于深度学习的时空双流视频动作识别[6]、基于训练图卷积神经网络的动作识别[7]、基于光流约束自编码器的动作识别[8]等。这类动作特征学习方法的识别准确率在大型动作数据集上较传统动作识别方法获得了显著的提升。
另外一些研究人员提出了基于无监督学习的视频动作识别方法[9]。这类动作特征学习算法将视频块像素作为输入信号,通过统计视频块中的像素分布信息学习动作特征。此类方法未考虑像素在时空域的特征,因此仅能描述视频像素块的外观信息,忽略了动作的运动信息[10]。
本文利用深度学习的泛化能力和视频的时空信息,提出了一种基于四元组Siamese网络[11]的动作识别算法。为了提高动作识别的泛化效果,增强对动作多样性的区分能力,提出了一种增强Siamese神经网络的完全无监督学习算法提取视频的动作特征。为了提高动作识别的效率,做了两点设计:(1) 通过三维Harris角点检测时空域中发生显著变化的局部结构,对这些兴趣点进行无监督学习,由此提高学习的速度;(2) 为兴趣点的特征索引构建投影树,由此提高模式匹配的搜索速度。
1 基于Siamese网络的无监督学习

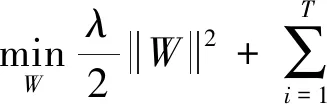
(1)

1.1 Siamese网络结构
文献[12]的慢特征分析(Slow Feature Analysis,SFA)框架能够从向量形式的输入信号学习缓慢变化的特征,视频序列恰好是该模型的理想输入信号,将连续视频帧间的时间一致性作为监督结构。SFA具有以下属性:在时域上接近的视频帧在特征空间内的距离也接近,设一个学习的描述符为ψ,两个连续视频帧为Vi,t和Vi,t+1,可得ψ(W,Vi,t)≈ψ(W,Vi,t+1)。下文将ψ(W,Vi,t)简写为ψ(Vi,t),假设学习的特征描述符是一个关于网络参数W的函数。
第1个Siamese模型的关键思想为:学习程序的目标是保证查询帧和相邻视频帧在特征空间ψ中接近,而查询帧和其他视频的帧间距离大于某个阈值δ。图1是本文的Siamese网络结构,网络由两个基础网络组成,基础网络之间共享参数。模型的输入是一对视频帧:(Vi,t,Vi,t+1)或者(Vi,t,Vj,t′),以及相关的标记Y(两个帧属于相同的视频,Y=1;否则Y=0)。基础网络的输出均为4 096维的特征空间ψ(·),在训练之前无需初始化基础网络和相关的权重参数,直接将网络的参数设为随机值,因此本模型为完全无监督模型。

图1 第1个Siamese网络的结构
假设查询视频为Vi,两个连续帧Vi,t和Vi,t+1之间特征描述符的距离应当小于查询帧Vi和其他任意随机帧Vj的距离。
如果Vx=Vi,t,并且Vy=Vi,t+1
如果Vx=Vi,t,并且Vy=Vi,t′,那么:
max(0,δ-ψ(Vx),ψ(Vy))
(2)
式中:d为欧氏距离,式(2)(对比损失函数)惩罚连续帧之间的距离,奖赏不同视频帧之间的距离。
在模型的训练程序中未考虑视频的标记,所以本模型支持任意的视频,是一种完全无监督的学习方法。
1.2 四元组Siamese网络
第1个Siamese网络仅仅学习了连续的视频帧,第2个Siamese网络为四元组Siamese网络,负责提取视觉内容的细节特征。文献[13]提出归一化SFA模型,该模型在学习视频描述符的过程中能够产生一个二阶时间导数,将三个时间紧密帧组成三元组(Vi,a,Vi,b,Vi,c),该模型使得紧密帧之间的特征变化也保持相似,即d(ψ(Vi,b),ψ(Vi,a))≈d(ψ(Vi,c),ψ(Vi,b))。该模型的目标函数结合了监督损失函数和无监督的正则化项,而本模型则是完全无监督的学习模型。
深度学习特征的核心思想是保证连续帧特征描述符之间的时间一致性,所以长度n的时间窗口内帧间距离应当小于不同视频的帧间距离。图2是本文设计的四元组Siamese网络,该模型捕获视频的局部微小变化,并保持全局的判别力。

图2 第2个Siamese网络的结构(四元组Siamese网络)
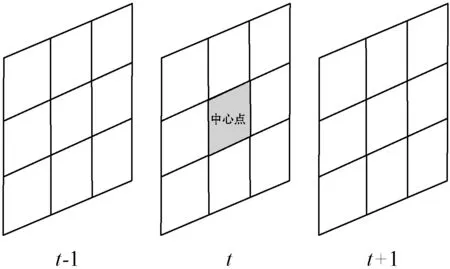
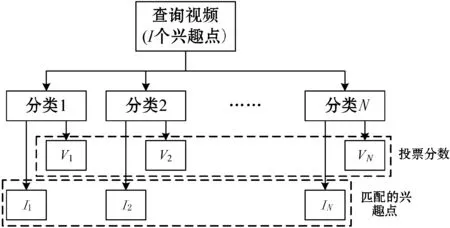
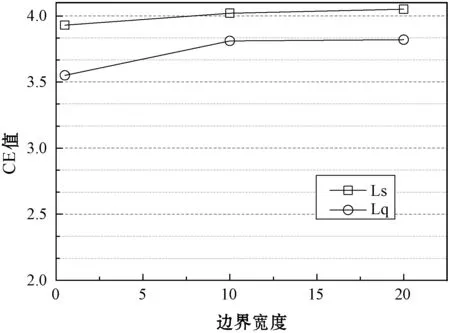
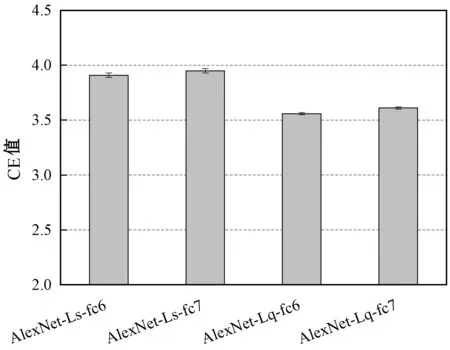
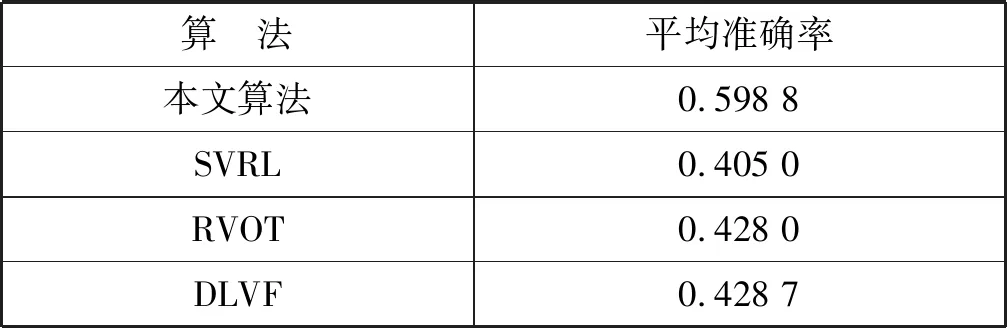
模型共有4个基础网络组成,网络之间共享相同的参数。模型的输入为四个视频帧的元组(Vi,t,Vi,t+1,Vi,t+n,Vj,t′),每个基础网络的输出为1024-D的特征空间。选择4个视频帧的原因在于:查询帧Vi,t和相邻视频的帧Vi,t+1在学习的特征空间中极为靠近(ψ(Vi,t)≈ψ(Vi,t+1)),查询帧Vi,t和相同视频的帧Vi,t+n在特征空间中也较为接近,而查询帧Vi,t和其他视频的帧Vj,t′在特征空间则较为疏远,即d(ψ(Vi,t),ψ(Vi,t+n)) 四元组Siamese网络的损失函数定义为: d(ψ(Vi,t),ψ(Vi,t+1))+max{0,d(ψ(Vi,t), ψ(Vi,t+n))-d(ψ(Vi,t),ψ(Vi,t′))+α} (3) 式中:α表示全局的margin。 动作识别程序需要消耗大量的内存空间和计算时间,而且Siamese网络的学习成本也较高,为了提高动作识别的效率和速度,提出一种基于局部最大差异图像的兴趣点检测技术,将视频分割为动作主要区域和动作次要区域,Siamese网络仅学习主要区域的特征。在兴趣点的检测程序中,使用相邻帧差分技术获得差分图像。 图3是动作识别算法的流程框图。算法主要由三个模块组成:① 兴趣点检测模块,检测身体的移动部分,其优点在于提取运动行程较大的身体区域,这些区域对于动作区分具有较高的判别力。② 建立投影树的过程中,设计了重叠区域分割机制,降低边界点分类的错误率。③ 采用霍夫投票机制统计测试视频和各个训练分类的相似性,结合投票得分和投票数量的结果识别出目标动作。 图3 动作识别算法的流程框图 视频的兴趣点一般为边缘和角点等,三维角点是一种效果较好的人体动作描述符,采用三维Harris角点检测兴趣点。将Harris角点检测技术从空间域扩展到时间域和空间域,提取时空域中发生显著变化的局部结构。三维Harris角点检测一般通过Harris角点移动检测三维角点的变化,但在一些视频中发生三维角点变化的部分并非主要区域,因此无法检测出关键的移动区域。所以设计了差分视频帧的局部最大化机制,提高动作识别的精度。 算法1是兴趣点检测算法的伪代码。假设查询视频V共有Nf个帧,计算连续帧之间的差分图像Di。应用中值滤波器处理差分图像,抑制多余的毛刺,计算三维局部最大值。计算目标像素的26个相邻像素(3×3×3的三维立方体),分别和目标像素比较来判断目标像素是否为局部最大值。图4是判断局部最大像素的实例,将图中26个像素的强度值与中心像素比较,如果均小于中心像素,那么该中心像素为一个兴趣点。 图4 判断局部最大像素的实例 最终计算所有兴趣点之间的欧氏距离,如果两个点的距离小于阈值θ,那么删除其中一个兴趣点,本文将θ设为20个像素对应的欧氏距离。 算法1检测兴趣点的算法 输入:查询视频V,视频帧数量Nf 输出:兴趣点IP,迭代次数i 1.whilei 2.D(i)=median_filter(V(i+1)-V(i)); /*中值滤波*/ 3.i++; 4.} /*计算目标像素的26个相邻像素,判断是否为局部最大*/ 5. foreachpixelinDdo { 6.center_pixel=pixel; 7.nei_pixel=pixel的26个邻居像素 8. foreachlfrom 1 to 26 do { 9. ifnei_pixel[i]>center_pixelthen 10.pixel不是兴趣点; 11. break; 12. endif 13. endfor 14.IP=center_pixel; //该中心点为兴趣点 15.endfor /*删除接近的冗余兴趣点*/ 16.foreachiinIPdo { 17.dis=ED(IP(i),IP(i-1)); /*计算欧式距离*/ 18. ifdis<θthen 19. 删除该冗余点; 20. endif 21.endfor 图5是兴趣点检测的实例图。(a)是一个拳击动作的视频帧;(b)是两个连续帧的差分图像;(c)是轮廓检测的局部最大兴趣点,删除了近距离的兴趣点和低强度的兴趣点。 (a)(b) (c)图5 检测兴趣点的实例图 采用第1节无监督学习的神经网络学习视频帧兴趣点的特征,特征集总体的维度为162。 采用投影树构建特征空间的索引,提高兴趣点的搜索速度。随机投影树(Random Projection tree,RP-tree)对于低维流形学习的效果好于近邻树,所以本文采用RP-tree建立特征空间的索引,RP-tree为训练数据集建立索引,在测试过程中快速搜索查询兴趣点的匹配数据。但是RP-tree存在一个问题:如果不同分区的兴趣点相似,则会导致RP-tree出现较高的失败率。 将重叠区域分割能够有效地降低失败率,图6是分割重叠区域的示意图,将区域Χ沿随机方向U分割,控制变量α,将区域分割为(1/2-α)和(1/2+α)。 图6 重叠区域分割的示意图 算法2是建立RP-tree的算法,将视频提取的兴趣点集表示为P={pi;i=1,2,…,NP},其中pi=[fi,li],fi和li分别为兴趣点pi的描述符和时空位置,NP为兴趣点的总数量,设参数td是tree的最大深度。mk_RPtree是建立RP-tree的程序,div_data(P)是分割重叠区域的函数(见算法3)。 算法2mk_RPtree函数 输入:特征集P,深度depth。 输出:投影树tree 1.初始化:最大树深度td,叶节点中兴趣点的最少数量msz。 2.ifdepth 3. if |P| 4. returnleaf; 5. } else { 6. rule=div_data(P); 7.left_tree=mk_RPtree({x∈P:rule(x)=true}∪ {x∈P:x∈Pcommon}); 8.right_tree=mk_RPtree({x∈P:rule(x)=false}∪ {x∈P:x∈Pcommon}); 9. } 10.} 算法3分割重叠区域的函数div_data(P) 输入:特征集P 输出:数据分割规则rule 1.产生一个随机方向v; /* 产生的列表为p1≤p2≤…≤pn。*/ 2.将投影值排序p(x)=v.x, ∀x∈P; 3.for (i=1,…,n-1) { 7. 搜索ci的最小值, 8.θ=(pi+pi+1)/2; 9.rule(x)=v.x≤θ; 10.} 上节为兴趣点构建了RP-tree,训练数据为R={dr=[fr,lr];r=1,2,…,NR},fr和lr分别为兴趣点dr的描述符和时空位置,NR为兴趣点的总数量,V(x,t,ρ)表示时间中心为t、空间中心为x的测试视频,ρ为测试视频的缩放尺度。从V提取的兴趣点表示为P,V和R之间的相似性匹配分数计算为: S(V(x,t,ρ),R)∝ (4) 如果fi,fr属于树Tj的同一个叶节点,那么Ij(fi,fr)=1,否则为0。lv=[xv,tv]为投票位置,xv和tv分别为: (5) 图7是投票程序的详细流程。 图7 投票程序的详细流程 相似性匹配度表示为[xv,tv],xv为查询点和动作中心间的欧氏距离,tv为训练兴趣点和动作中心间的欧氏距离,[xv,tv]表示xv和tv之间的差值。如果不同分类的训练视频之间兴趣点数量不相等,那么在tree某些深度的叶节点具有不等的兴趣点数量,该情况导致误检率升高,容易将查询视频误分类为假正类。为了避免该问题,对于投票技术进行修改,保持兴趣点数量相等。 计算匹配点到查询点间欧氏距离的差值之和,其结果用于计算相似性匹配度。此外,记录每个分类的兴趣点数量,综合上述两个结果,识别出查询视频。 图8 查询视频的投票分数和兴趣点匹配示意图 算法4是改进投票算法的伪代码,通过投票的分数初始化类Vi,统计和查询兴趣点匹配的兴趣点数量,分别做如下不同处理:(1) 如果当前类匹配的兴趣点数量最多,那么该查询视频增加该类的类标签。(2) 匹配兴趣点的数量和初始识别的类做比较,投票总分数更高的类作为识别的分类。 算法4改进的投票算法 输入:匹配的兴趣点数量Ij,分类数量N,投票分数Vi 1.ifi==j{ 2. 类标签=i; 3.} else { 4.Ii=Vi; //匹配的兴趣点数量 5. 搜索Ik>Ii的类标签; 7. 类标签=k; 8.} (1) 实验方法。基于MATLAB(9.0.0.341360 release 2016a)实现实验中的各个算法。实验环境为PC机,CPU为Intel Core i5,主频为3.2 GHz,内存为8 GB,操作系统为Window 10。 UCF101数据集是从YouTube网站采集的实际动作视频,共包含12 000个视频,101个动作类型。数据集分为3个子部分,本实验采用其中第1个部分,该部分共有9 537个训练视频和3 783个测试视频。上述数据集的视频均包含标注信息,但是本文在学习视频特征的过程中忽略了这些标注信息,而是从视频集中提取一部分的子集作为训练集。 J-HMDB数据集是一个单人交互的动作视频数据集,该数据集能够清晰地观察动作识别算法的处理过程。该数据集共包含21个动作类型,每个动作类型有36~55个视频。实验从每个类型中随机选出6个视频作为训练集,随机选出30个视频作为测试集。 实验方法有以下几个步骤:(1) 采用训练视频集以无监督的方式学习本文的神经网络结构。(2) 计算测试视频的特征。(3) 检测视频动作的类型。每组实验独立重复10次,统计每组实验的平均值和标准偏差作为最终的实验结果。 (2) 性能评价指标。采用条件熵(Conditional Entropy,CE)评估检测的性能。CE定义为: (6) 式中:X为正定标签;Y为算法检测的标签;变量(x,y)是从有限离散相交空间X×Y获得的采样。 图9 CE与边界宽度的关系 分别测试神经网络fc6层和fc7层学习特征的效果,结果如图10所示。综合4个参数组合的结果,fc6层的性能优于fc7层。 图10 fc6层和fc7层学习特征的结果 采用3个动作识别算法与本文算法做比较,分别为SVRL[16]、RVOT[11]、DLVF[3]。SVRL是一种无监督学习视频特征的方法,该方法的分类准确率较高。RVOT是一种基于卷积神经网络的视频特征选择算法,该算法设计了多尺度完全全局Siamese网络,与本算法同属于Siamese网络的改进算法。DLVF也是一种使用神经网络的人体动作识别算法,该算法是一种分布式动作识别算法。使用K-means聚类算法[15]和谱聚类(Spectral clustering,SC)分别测试特征子集的性能,基于高斯核距离的全连接方式生成SC的相似矩阵。 图11是4个动作检测算法的CE结果。观察图中的结果,本文算法均实现了最低的CE值,SVRL是一种提取视频时空特征的算法,其特征的效果明显低于其他三个深度学习的特征。在三个基于神经网络的检测算法中,本文算法实现了最低的CE值,并且虽然RVOT和DLVF的CE值与本文算法较为接近,但这两个算法均为有监督特征学习方法,需要预知系统的参数和应用场景的先验知识。本文算法则是完全无监督学习方法,无需任何的先验知识。 图11 4个动作检测算法与不同分类器组合的CE结果 通过J-HMDB数据集能够观察动作检测算法的细节信息,为J-HMDB数据集的动作类型编号:(1) Brush hair,(2) Catch,(3) Clap,(4) Climb stairs,(5) Golf,(6) Jump,(7) Kick ball,(8) Pull up,(9) Push,(10) Run,(11) Shoot ball,(12) Shoot bow,(13) Swing baseball,(14) Throw,(15) Walk,(16) Wave。采用3个指标评估本算法的总体性能[17],分别为灵敏度、准确度、特异度,敏感度高说明漏检率低,特异度高说明误检率低。图12是本文算法对于J-HMDB数据集的动作识别结果,(a)中15个数据集的灵敏度均达到了0.4以上,Push数据集的敏感度较低,漏检率较高,主要原因是Push动作的幅度较小,提取的特征判别能力弱于其他类型的动作;(b)中Pull up动作和Push动作的准确率较低,其他14个动作的准确率也均高于0.4;(c)中所有动作的特异度均达到0.9以上,说明算法的误检率较低。 (a) 灵敏度 (b) 准确度 (c) 特异度图12 J-HMDB数据集的动作识别结果 表1是4个动作识别算法对于H-HMDB数据集的平均准确率结果。本文算法的平均准确率接近0.6,明显高于其他3个动作识别算法,表明本文算法具有较好的识别准确率性能。表2是4个动作识别算法对于H-HMDB数据集的平均时间结果,4个算法在时间效率上均具有良好的性能,均可在10秒以内成功完成检测,而本文算法则具有最快的速度。 表1 4个动作识别算法的平均准确率 表2 4个动作识别算法的平均时间 本文设计了新的动作识别算法,主要包括三点创 新:(1) 设计了兴趣点检测模块,检测身体的移动部分,其优点在于提取运动行程较大的身体区域,这些区域对于动作区分具有较高的判别力。(2) 建立投影树的过程中,设计了重叠区域分割机制,降低边界点分类的错误率。(3) 采用霍夫投票机制统计测试视频和各个训练分类的相似性,结合投票得分和投票数量的结果识别出目标动作。最终通过实验验证了本文算法的有效性,在检测准确率和时间效率上均具有明显的优势。未来将利用分布式计算和并行计算实现本算法,将算法的识别速度加快到1秒以内,进一步提高算法的实用性。1.3 Siamese网络的实现细节
2 动作识别的算法设计

2.1 检测兴趣点

2.2 特征提取
2.3 重叠区域分割的随机投影树

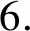
2.4 投票模型
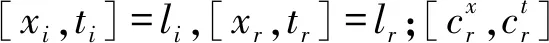

2.5 改进投票算法
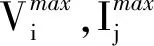
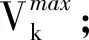
3 仿真实验和结果分析
3.1 实验环境和方法
3.2 神经网络参数的效果
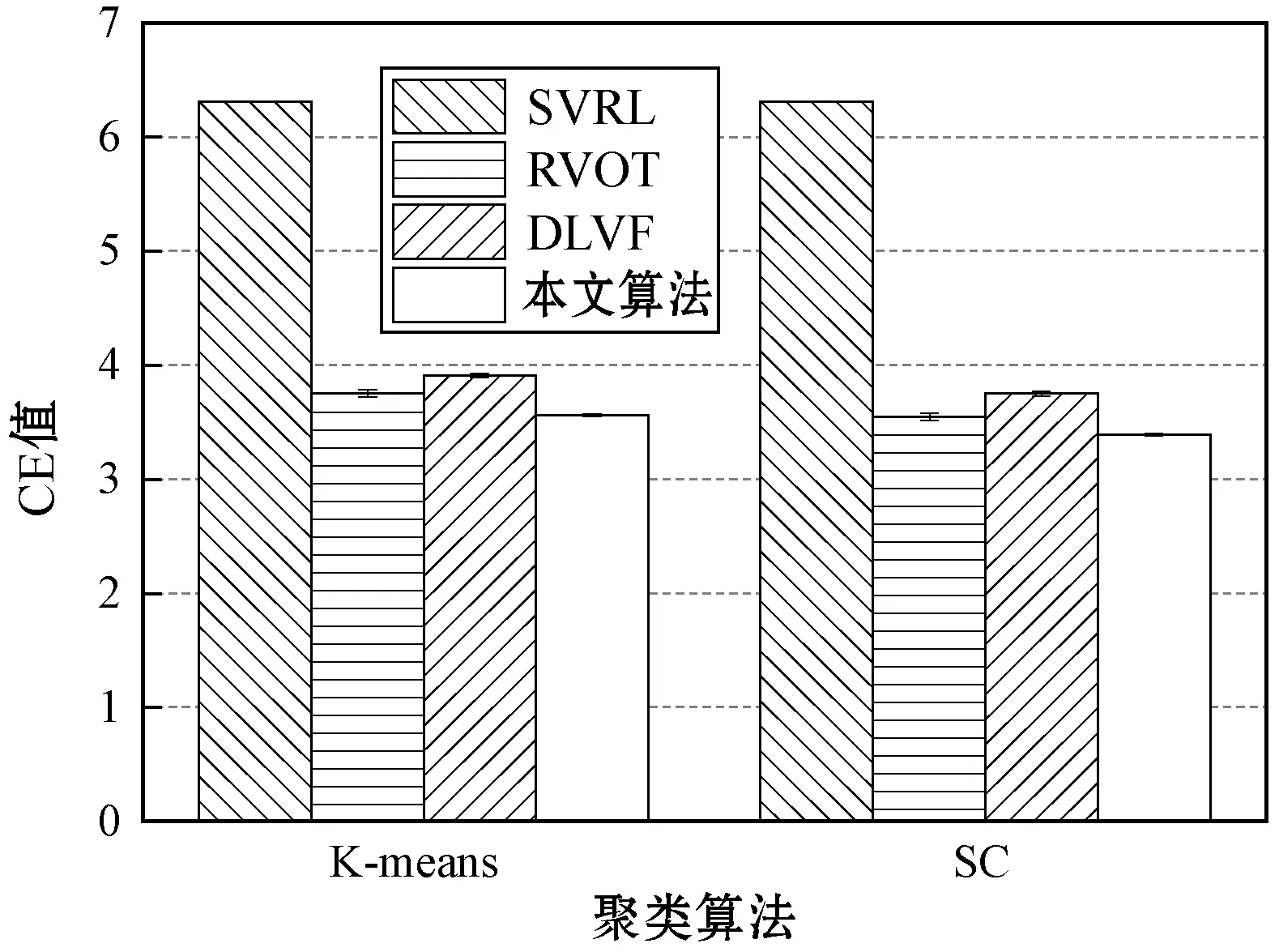
3.3 UCF101数据集实验
3.4 J-HMDB数据集实验
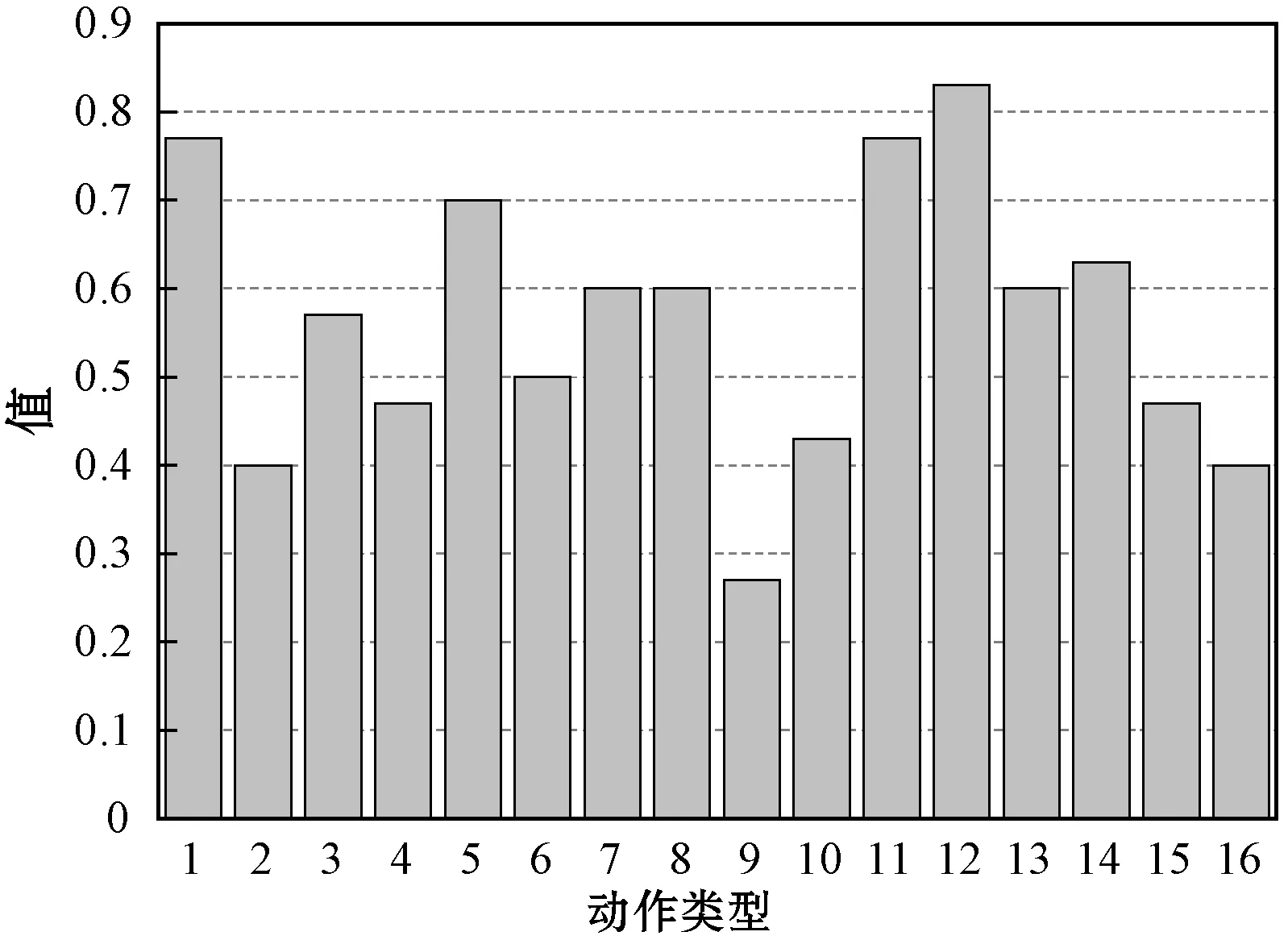

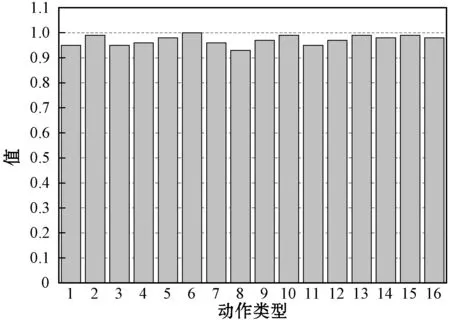

4 结 语
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25中学生数理化(高中版.高考数学)(2022年3期)2022-04-26小学生学习指导(低年级)(2021年12期)2021-12-31红领巾·萌芽(2019年8期)2019-08-27阅读与作文(英语初中版)(2019年8期)2019-08-27初中生世界·七年级(2019年5期)2019-06-22当代陕西(2019年10期)2019-06-03中学生数理化·高一版(2017年1期)2017-04-25中学生数理化·高一版(2017年1期)2017-04-25CHIP新电脑(2016年3期)2016-03-10
