
基于二级网格和卷积神经网络的流体模拟方法
2020-04-18 13:15段景耀
计算机应用与软件 2020年4期
段 景 耀
(上海交通大学电子信息与电气工程学院 上海 200240)
0 引 言
流体模拟是计算机图形学的重要分支之一,被广泛应用在电影、游戏、动画、虚拟现实场景以及科学工程等诸多领域。基于物理的流体模拟过程中需要求解纳维尔-斯托克斯(Navier-Stokes,NS)方程,在计算机领域NS方程的求解方式一般分为两种:欧拉法和拉格朗日法。相比于拉格朗日法,欧拉法在高精度的模拟中具有求解更为稳定、表面重构和渲染更为简便等优点,因而被广泛使用。
在流体模拟的规模增大时,欧拉法模拟所需的计算量也迅速增加。因此,大场景中的流体模拟需要良好的加速算法来保证效率。在模拟中,泊松方程的求解是欧拉法的关键步骤,同时也是计算开销最大的步骤。为了提高流体模拟的运行速度,许多研究都致力于优化泊松方程的求解乃至整个欧拉法的求解中。
最为直接的优化效率方法是优化泊松方程的求解过程。例如,Bridson等[1]提出的预处理共扼梯度法,通过减少求解大型稀疏线性方程组的迭代次数,来达到加速计算的目的。McAdams等[2]在共扼梯度法的预处理过程中使用了多重网格来进行加速,在模拟较大规模的场景时具有非常良好的性能提升。
另外一种优化效率的方法是对模拟的空间进行区域划分,优化计算资源的分配,在更加关键的区域中增加计算资源和精度。例如文献[3-4]提出通过八叉树数据结构对空间进行划分。文献[5]的方法在液体表面采用精细的立方体网格,而在液体内部使用长方体网格。文献[6]的方法在流体的来源位置应用精细的网格,在其他区域则使用较为粗粒度的网格。文献[7]将整个空间进行粗粒度划分,并将每个区域进行抽象,在宏观和局部分别求解,最后再合成流体的运动状态,通过减小计算规模的方法减小计算量。这些方法都是在精度和性能之间进行平衡,提升性能的同时不可避免地会引入误差。
机器学习(Machine Learning,ML)作为一个新兴的学科,被广泛应用于多个计算机领域,能够实现自动化地在数据中提取特征进行分类或拟合的操作,具有速度快、非线性等诸多优点。卷积神经网络(Convolutional Neural Network,CNN)作为机器学习的重要分支之一,同样被应用在流体模拟中。例如,文献[8-9]利用CNN通过数据训练来求解NS方程,来达到加速的目的。文献[10]等人通过CNN来对流体的局部特征进行学习,再通过合成得到整个场景的流体运动状态,也达到了良好的模拟效果。
本文提出一种基于二级网格和CNN的流体模拟方法,首先通过二级网格进行局部和宏观的流体状态的模拟,再通过训练好的CNN将局部细节状态和宏观运动趋势进行整合,得到最终的流体模拟结果。
相比于其他方法,本文的方法具有以下的优点。首先,基于流体的连续性和受局部状态影响较大的特性,可以将流体进行二级网格的划分。这样的划分能够有效减少计算规模,并允许同级网格之间进行并行计算。其次,CNN的引入能够有效地对高低精度网格之间的非线性关系进行拟合,从而通过数据驱动的方式,减少由于二级网格分割计算带来的误差,在加速流体模拟的同时,仍然保持较好的数据精确性。
1 算法描述
本文的算法主要分为两个部分,分别是二级网格的流体模拟,CNN的学习和应用。二级网格的模块主要实现了分块的流体模拟算法,在此阶段同时生成二级网格流体的状态数据,作为CNN学习的训练数据。在CNN部分中,对上述数据进行学习,并将得到的训练好的模型应用在二级网格的模拟中,得到最终的流体模拟结果。算法流程如图1所示。
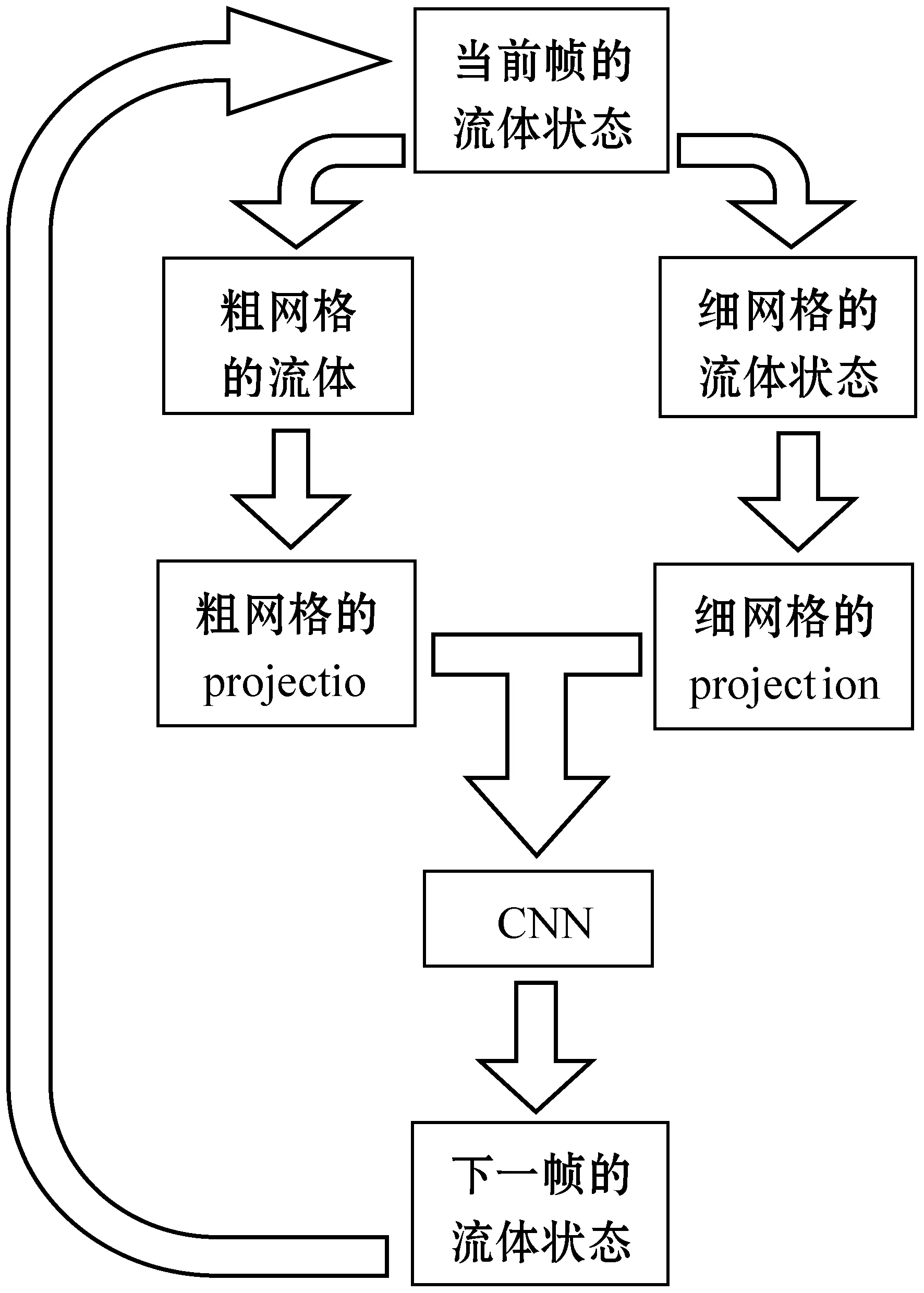
图1 包含二级网格与CNN的流体模拟算法流程图
1.1 Navier-Stokes方程
在欧拉方法中,流体被视为不可压缩的。流体所在的空间被均匀分割成大小相同的网格。记流体的速度场为a,流体的密度为ρ,流体的压强为p,f为所有的外力的合力(重力、浮力等),则Navier-Stokes方程以如下的方式给出:
(1)
▽·u=0
(2)
式中:▽为梯度算符。若已知第n帧的速度场un,为求解最终的速度un+1,首先求解中间速度u*,满足:
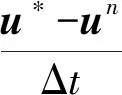
(3)
进一步,求解第n+1帧速度:
(4)
压强p通过下列方程给出:
(5)
通过上述5个方程,便可以根据当前帧的流体状态,求得下一帧中流体的状态。
1.2 二级网格下的流体模拟
首先,我们将网格均匀分割为粗网格,再将每个粗网格均匀分割成为若干细网格。如图2所示,若流体空间为正方体形状,记每一边上的粗网格数目为rc,每个粗网格中每一边上细网格的数目为rf,空间中的精细网格的总数为(rc×rf)3。若此时每个精细网格的速度记为u,则我们最终要求解的是下一帧中的每个精细网格中的速度u′。
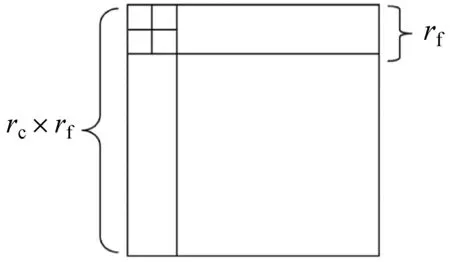
图2 二级网格的空间划分

(6)
平均值反映了此区域中整体的流动情况。由于流体中的速度是连续的,在较小的局部区域内流体的速度差异并不明显,因此我们可以选取平均值作为粗网格中的速度代表值。
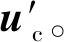
(7)
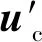
(8)
我们使用CNN通过大量数据的训练来得到较为理想的函数f。
(3) 计算复杂度。在计算压强时需要求解方程组:
(9)
式(9)可以等价为AP=b的形式,其中:A为系数矩阵,P为待求解的压强构成的向量,b为常数矩阵。由于压强p的长度为n3,可知矩阵A的大小为n3×n3,在实际计算中A较为稀疏,但求解A的逆矩阵A-1的复杂度必定大于O(n3)。由经验得出,此步骤中的实际复杂度约为O(n4)。
在我们的问题中,若直接应用NS计算求解,所需时间为:
T=k·(rc·rf)4
(10)
式中:k为复杂度系数。
若进行二级网格的划分,则在局部精细网格和全局粗网格上,NS方程求解所花费的时间总共为:
(11)
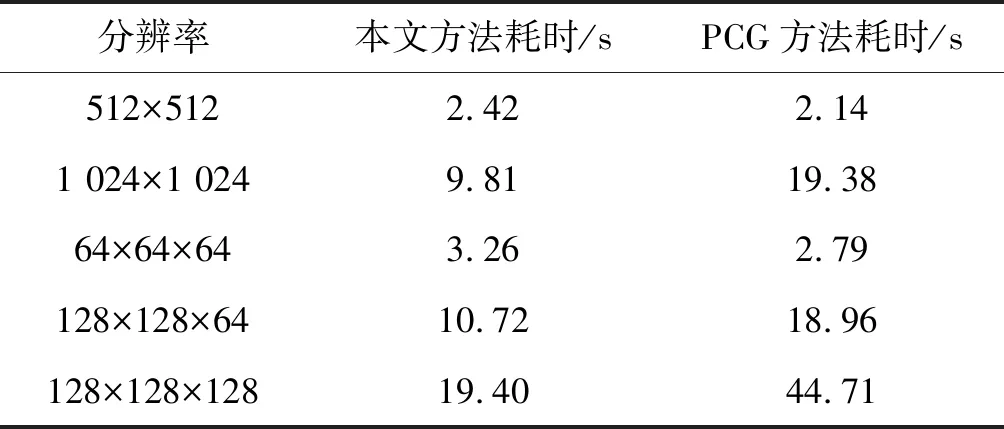
式中:t为整合粗细网格所需的时间,与rc和rf的三次方成正比。可以看出分割方法的时间复杂度要小于直接求解NS方程的时间复杂度,即T′ 综上所述,二级网格划分本身能够降低计算量,又由于各个粗网格区域内的计算相互独立,因此可以进行多线程或者分布式计算进行进一步加速。如将空间分割为16个粗网格,则在求解速度,可以同时计算16个网格中的速度,使此步骤的性能至少提升16倍。 由于二级网格的区域分割的计算,将完整的流体分割成为了相互独立的精细网格区域,这样在提高效率的同时也不可避免地引入了误差。卷积神经网络(CNN)能够较好地处理平滑曲线的拟合问题,而流体恰好具有良好的连续和平滑的特性。鉴于粗网格、细网格分别代表了局部运动和宏观运动,但二者的对应关系未知,我们采用CNN来通过数据来拟合二者的关系。 (1) 数据生成和预处理。在二级网格的模拟过程中,我们将每一帧的粗网格和细网格中的速度数据进行记录,作为训练数据。同时在同样的场景不使用二级网格,而是直接求解NS方程得到下一帧的网格中的速度,作为对照参考的真实数据。而我们的预测数据就是下一帧中细网格中的速度数据,目的是让预测数据尽可能接近真实数据。 对于粗网格的数据,其网格大小与全局网格大小不一致,其分辨率为rc。我们采用扩充的方法,将数据集大小扩充为全局数据网格大小rc×rf,记录每个精细网格所对应的粗网格的数据,以便于在CNN中对数据进行卷积处理。 由于流体的连续性,当时间步长较小时,相邻两帧之间的速度等各项流体状态数据差异较小,因此我们在时间上进行抽样,每N帧之中选择1帧数据进行记录,从而在数据集大小不变的情况下,增加了数据集的多样性。同时,我们针对多个不同的场景进行模拟,进一步提升数据集的多样性。 (2) CNN结构。卷积神经网络具有这样的特性,每个神经元都会考虑其附近区域的数据状态,符合流体的局部区域影响的特点,与我们二级网格划分的思想高度相似。鉴于我们的输入数据(当前帧的粗网格和细网格的速度场)和输出数据(下一帧的细网格的速度场)的形状相同,我们采用两层带有边界补齐padding的卷积层对数据进行学习。 图3 卷积神经网络结构 在此神经网络结构中,要训练的对象是每一层中的卷积核conv。例如在我们的实际应用中,每个卷积核宽度为7,深度为6,即每一个卷积层中卷积核中的数据个数为7×7×6=294。总共需训练的卷积核变量的数目为588个。通过对大量训练数据进行学习,使预测的误差不断减小,从而找到预期的卷积核的值。 (3) Loss函数。Loss函数作为衡量预测结果的标准,直接影响到模型的准确性。Loss函数的选取应该具有以下几点特点:(1) 模型预测越准确,Loss函数的返回值越小,反之,Loss函数的返回值越大;(2) Loss函数的选取应尽量简洁,使其自身的求解和梯度下降法反向传播梯度的时候,不会带来过大的运算量,保证机器学习的效率。 基于这两点要求,我们采用每个维度上,预测数据与真实数据的L1距离差异比例作为模型的Loss,即: (11) 在实际操作中,由于我们的模型是递归进行的,即上一帧的输出作为下一帧的输入,倘若在神经网络的计算过程中,流体速度的比例产生缩放,即计算得到的u′与真实的utruth的关系为u=αutruth,则随着模拟的进行,u′与真实的utruth之间的差异将会呈指数级增长。如果α小于1,u′将会迅速趋近于0;如果α小于1,u′将会迅速增大,以至于模拟场景“爆炸”。因此我们增加一项Loss,来衡量u′与真实的utruth的比例关系,即: Lossscale=w∑(convweight-1) (13) 式中:convweight为卷积核的权重之和,w为Lossscale所占总的Loss的权重。我们将此项与式(12)中的Loss相加,得到最终模型的Loss函数。 首先在数据上,我们通过Loss函数对我们方法进行评估。为了避免过拟合,我们对数据集训练的Epoch数目为2 000。通过训练,我们的方法训练的最终Loss值约为0.34(见图4)。此数值在具体流体场景中的意义为:在对速度场求解结果的逐网格的比较中,我们的方法与PCG相比的逐网格的差异平均为34%左右。作为对比,在未使用CNN而采用线性插值时,根据场景的不同,此数值在0.6~2.1之间变动,即在最坏的情况下相对于PCG误差达到了209%左右。 图4 CNN训练EPOCH与Loss的关系 如图5、图6所示,在视觉效果上,我们的模型在保持流体宏观走势的同时仍然可以展示流体的微观细节。 (a) 本文方法(b) 直接求解NS方程图5 模拟结果 (a) 本文方法 (b) 直接求解NS方程图6 模拟结果 我们使用的机器的处理器为Intel i7-3770@CPU 3.40 GHz×8,内存为15.6 GB,显卡为NVIDIA GTX 970。 在实际操作中,取N=5即每5帧取一帧数据,粗网格和细网格的分辨率均为16,即场景中的分辨率为256,同时在450个不同的场景中进行模拟,每个场景模拟100帧。在模拟过程中,总计耗时约为1.3 h,我们总共得到了450×100/5=9 000组数据,数据总大小约为1.8 GB。 训练过程中,我们对每个训练集训练的Epoch数目为3 000,批处理的大小为10组数据,训练时间长为3.1 h。在保持流体形态的同时,我们的方法能在分辨率较高时够大幅缩减模拟的时间,提高帧率。每帧所需的时间与分辨率的关系如表1所示。在网格规模为1 024×1 024时,我们的方法的运算效率仅为PCG方法的一半左右。 表1 两种方法每帧耗时和分辨率的关系 本文提出了一种基于二级网格和机器学习的流体模拟方法,通过二级网格的区域划分来加速流体状态的求解,并通过卷积神经网络对划分的区域进行整合,同时通过数据驱动的方法来消除误差,从而在加速流体计算的同时基本上保持原本的流体形态特征,达到了良好的模拟效果。 二级网格的使用建立在流体连续性较好,流体的运动状态受局部影响较大的前提下。但当每个粗网格包含的细网格数目(rf)较大时,二级网格的区域划分将会对空间造成较大的离散程度,由此产生较大的误差。 二级网格划分减少了计算量,因而减少了整个流体场景中所包含的信息量,我们的做法本质上是利用CNN,通过数据驱动的方法外推因计算量减小而丢失的信息,但当场景本身网格数量太少时,其包含的信息量便不足以支持外推,此时本方法将会失效。此外在网格分辨率较小时,PCG方法本身的耗时较小,但本文方法由于需要处理粗细网格间的调度,同时还需调用CNN进行预测,因此造成在低分辨率下运算效率低于PCG方法。因此本文方法更适用于大规模的流体场景。 此外,由于使用了数据驱动的方法,本文算法结果依赖于大量的真实实验数据。数据的数量不足或者多样性不足,会使得此方法在特殊边界条件或一些未训练过的场景中失效。由于我们的训练模型依赖于流体模型,当流体模型发生改变时(如流体的空间结构、大小和划分方式等),训练结果仍然会失效,因此我们模型运行的前提条件是流体模型的一致性。 本文的工作提供了很多可扩展性。首先,每个划分的区域都可以进行并行或分布式计算。其次,可以进行多于二级的网格划分,并使用同样的方法进行训练,进一步优化运算性能并保持流体的形态。除此之外,可以在CNN模型中增加对其他流体变量的分析学习,如对流体压强和密度的分析,从而进一步增加整合后流体的精确程度。1.3 卷积神经网络
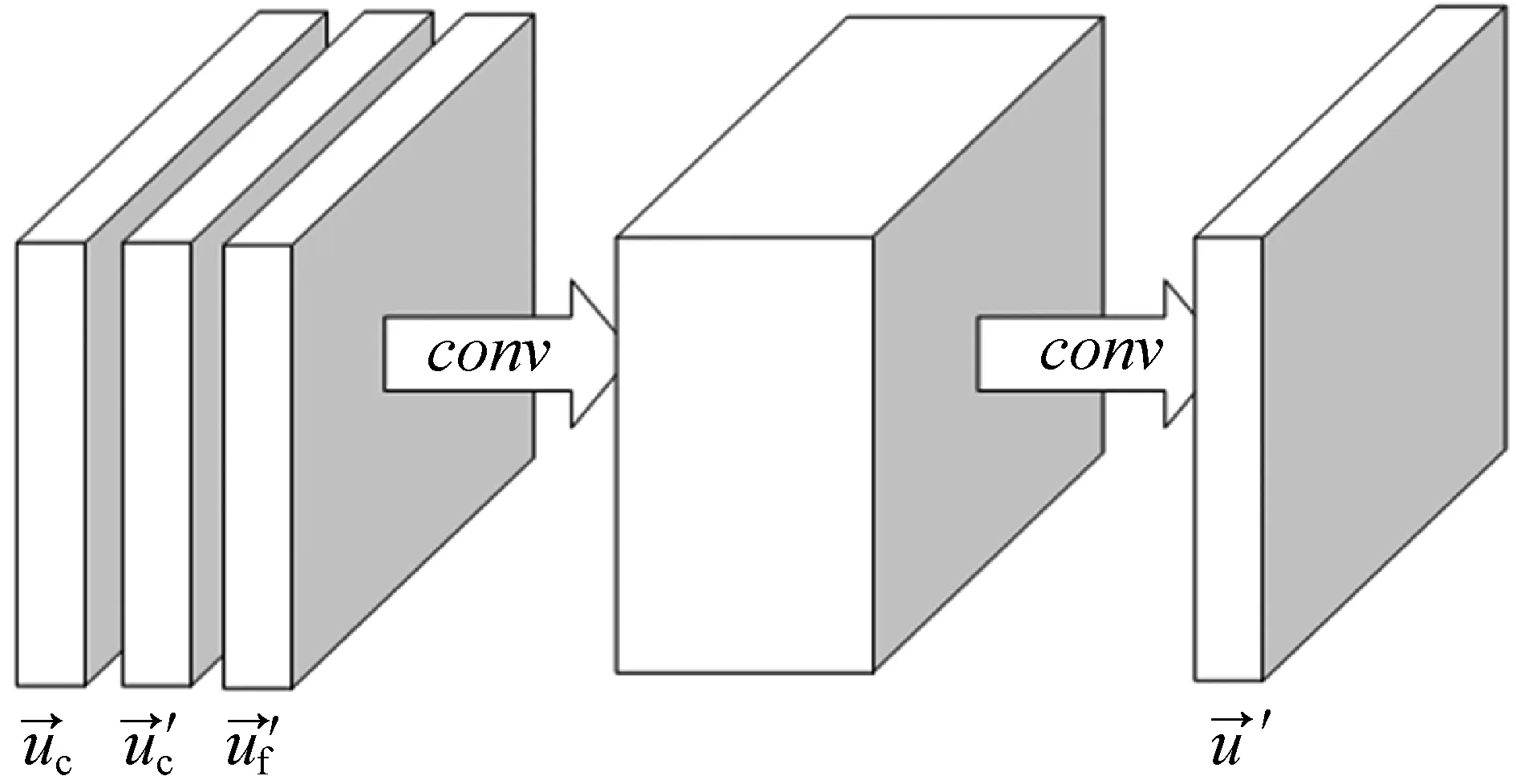
2 实验结果
2.1 实验效果分析
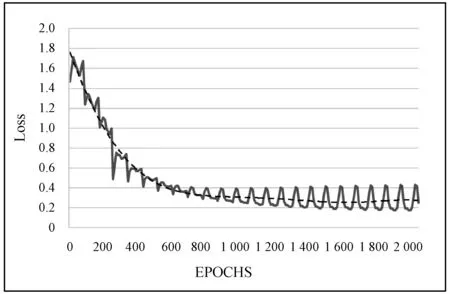
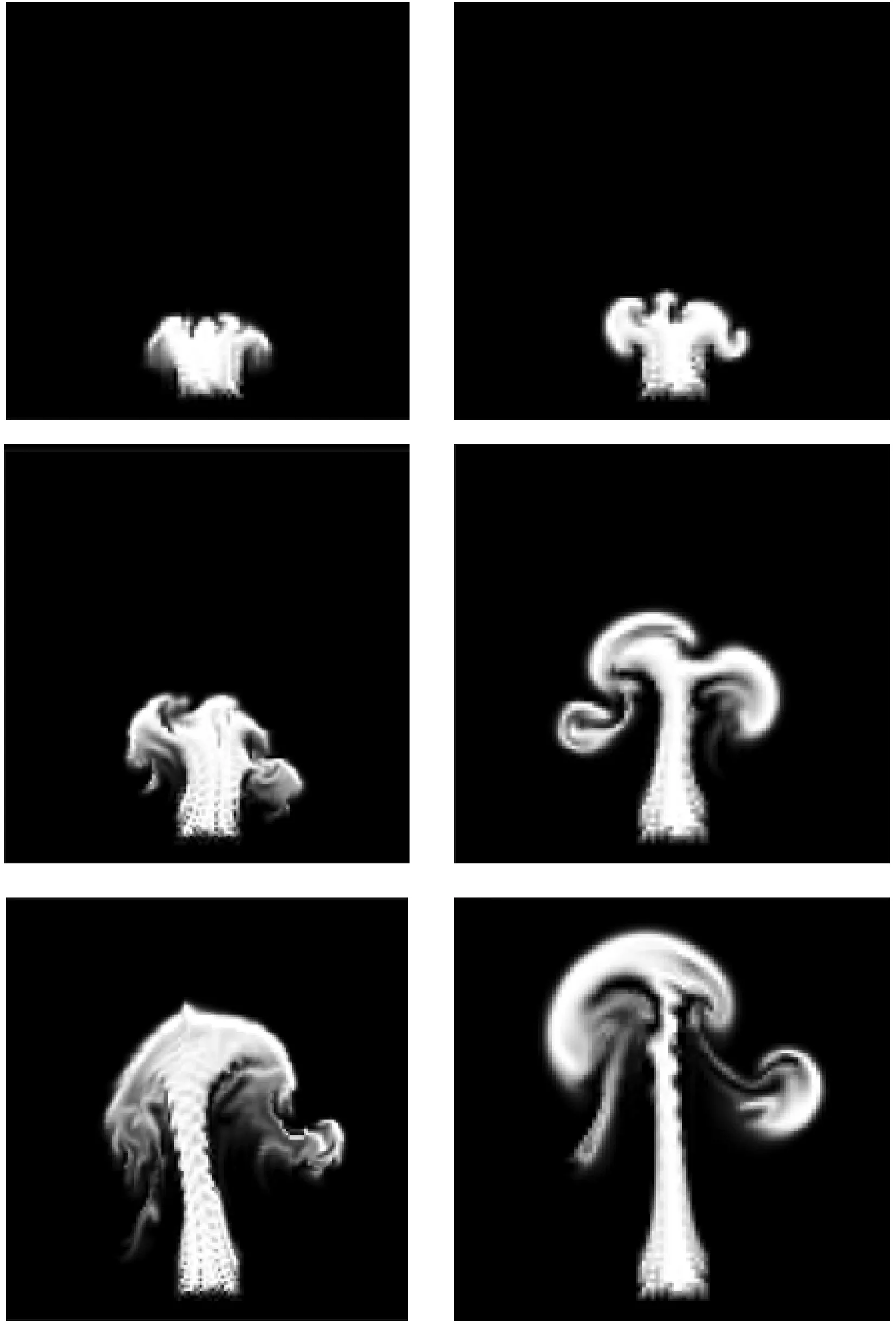
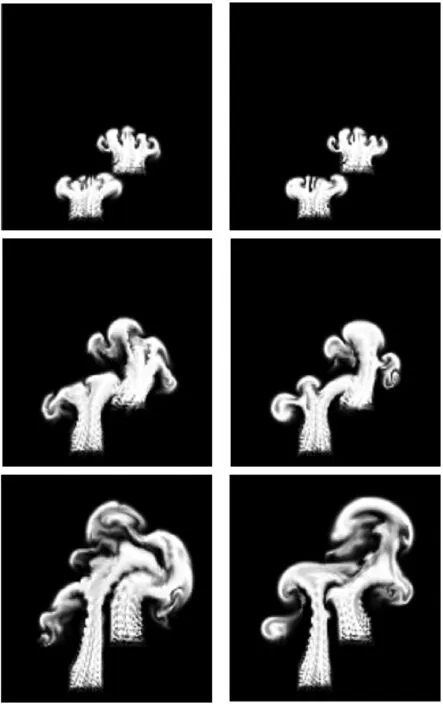
2.2 性能分析
3 结 语
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
华人时刊(2021年23期)2021-03-08
大众科学(2020年7期)2020-10-26
雨露风(2020年11期)2020-04-26
散文诗世界(2019年6期)2019-09-10
作文新天地(初中版)(2019年6期)2019-08-15
