
一种高效率的多天线信号检测方案的设计与实现
2020-04-18 13:15:00朱捷席兵刘勇
计算机应用与软件 2020年4期
朱 捷 席 兵 刘 勇
1(重庆邮电大学通信与信息工程学院 重庆 400065)2(重庆邮电大学通信网与测试技术重点实验室 重庆 400065)
0 引 言
现代无线通信系统中,良好的接收机设计对于系统性能的发挥起到重要保障作用。随着近两年TM9模式的逐步商用,针对多天线技术的增强特性逐步部署于现有的移动通信系统中,对于信号检测环节的设计及优化工作提出了新的挑战。当前市场上以Xilinx、Wasiela为代表的公司研发的主流产品IP集中在MMSE和k-best两种检测器上,高吞吐、低延时的检测模块设计仍然为研究热点。文献[1]提出了一种基于乒乓操作的多天线检测方案,其应用场景简单、数据量小,不能满足现有的吞吐和存储需求。文献[2]提出了一种基于MGS-QR分解的高效检测器结构,通过数据级并行、任务级并行等策略提高了计算效率,但该设计方案复杂度过高,硬件资源损耗过多。文献[3]的设计方案能很好地应用于无线空中接口系统,具有良好的EVM指标及吞吐性能,但该方案不支持多天线增强特性,如TM9下的信道估计是基于DMRS(DeModulation Reference Signal)的,模块需进一步优化以满足新的应用需求。
针对现有方案的不足,本文提出了一种高效率的多天线信号检测方案。针对高带宽、高吞吐的设计需求,将DDR3存储器整合至接收端信号检测环节,并采取基于AXI4-Stream接口封装的形式实现了高速的数据交互。通过功能划分及模块集成,接收端形成一种近似流水线的工作方式,并行处理各子帧数据。本文方案现已应用于一款空口监测仪表中,具备实用性。
1 多天线信号检测方案
1.1 DDR3读写模块设计
随着信号处理技术的发展,仅依靠片内的存储资源是远远不够的,本文采取了片外DDR3的方式实现各个模块的高速数据交互。
Xilinx公司为DDR3提供了MIG IP核作为控制器,并提供实例设计便于对用户接口进行封装,极大地便利了开发工作,但由于其读写指令通道复用需要实时关注两个ready信号,造成了时序操作上的不方便[4]。为了解决这一问题,可以采取将DDR3控制器封装为AXI总线接口的方式,充分利用其读写通道分离的特点实现双向的数据传输,同时又结合了SOC的架构优势,方便挂在总线上的PL端通过地址访问。AXI4总线包含三种类型的接口,即AXI4、AXI4-lite、AXI4-stream。考虑到项目中需处理的数据量较大,本文选取了最佳的AXI4-Stream[5]。
数据读写的整体设计如图1所示,由PL端发起读写操作命令,通过MIG控制片外DDR3。基于AXI4-Stream的流接口封装,收发双方可采取点对点的数据传输方式,故不需要总线地址,数据吞吐率较高,但开发人员需要自行封装控制地址的映射和读写仲裁等。本文在读写仲裁方面进行了简单的轮转FIFO设计,即数据的读写总线命令同时有效时,进行控制协调并分别例化一个FIFO用于缓存地址和数据。仲裁模块通过MIG侧的优先级轮换逻辑实现轮流读取,即每次选一个FIFO读取直至为空再重新选择。

图1 DDR3读写模块设计
1.2 信号检测方案整体设计
在此基础上,将DDR3模块整合至接收端物理层的信号检测。此时数据读写操作对象主要为频域数据和信道估计值,故与DDR3进行数据交互的模块为信道估计、同步时偏修正、MIMO检测模块。设计中为了达到低耦合的设计目标,将参考信号的提取集成到信道估计模块实现,同时由于多个物理信道在检测流程上相似,故将MIMO检测模块集成为下行接收端所有信道复用的一个模块。为了便于各子帧检测时数据同步,本文采取DDR3统一存储数据,资源解映射模块进行状态地址信息交互,然后再调度数据给MIMO检测模块的方式。此时下行接收端在进行信号检测时各模块间相互独立,整体形成一种近似流水线的工作方式,设计方案如图2所示。
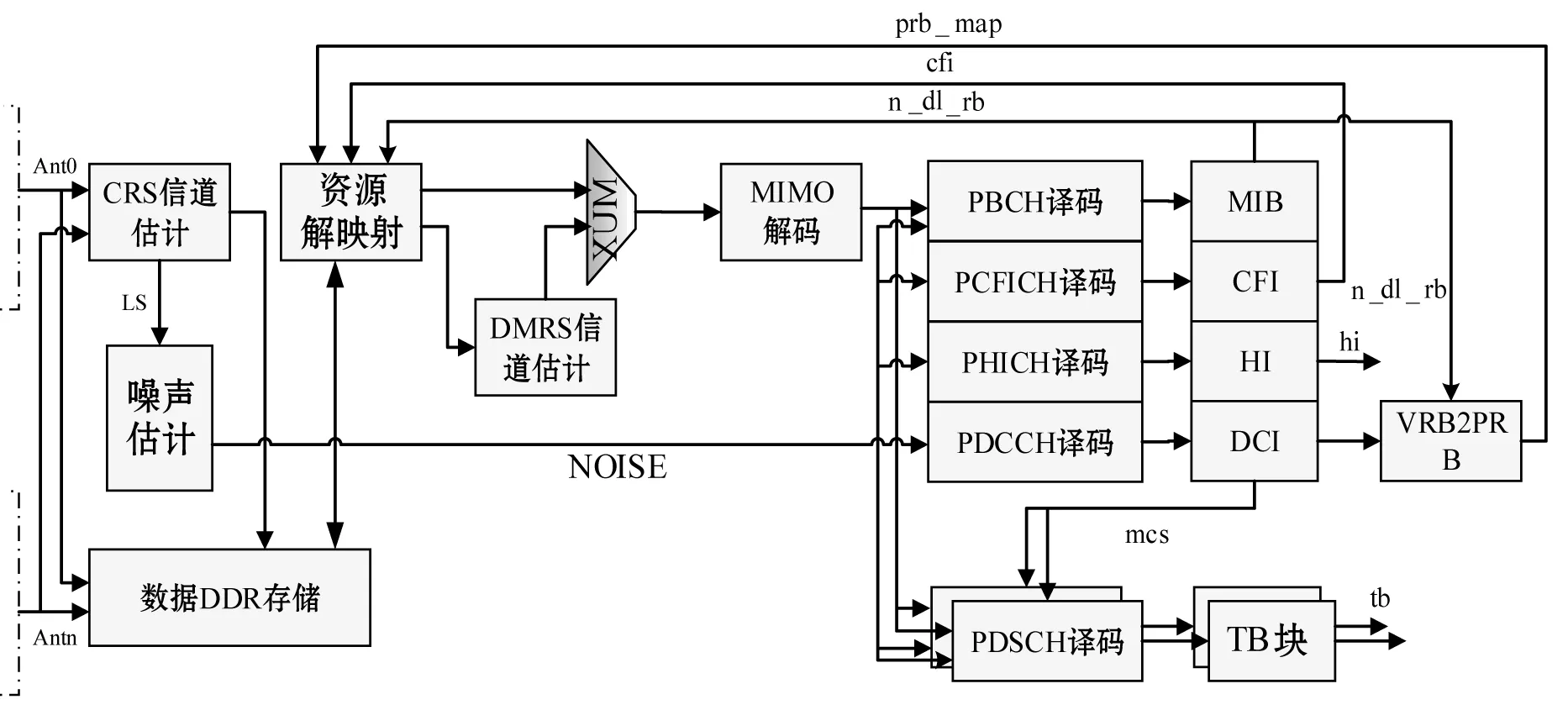
图2 信号检测整体设计
所有天线的多路IQ数据依次经过低电压差分信号(Low-Voltage Differential Signaling, LVDS)接口适配、去直流、频偏修正、帧同步、FFT和时偏修正等模块进入CRS(Cell-specific reference signal)信道估计和数据DDR3存储,然后进行多用户(UE)场景下的信号检测。具体流程如下:
(1) CRS信道估计模块将数据以频域帧结构的形式轮流存入DDR中,最多存储4份子帧数据。
(2) 一个子帧数据写入DDR完毕即可拉高对应标志端口电平,通知后级资源解映射模块提取数据。然后依次提取PBCH、PCFICH、PDCCH信道数据,送往后级译码模块进行信道译码。
(3) 考虑到多个UE的情况,PDCCH译码模块每译码出一个UE的DCI(Downlink Control Information),进而计算出UE的参数,如调制模式、RE数量、码块大小、码流数目等[6]。根据UE的参数,资源解映射模块计算出UE所占用的PDSCH位置,从DDR中读出UE的数据。
(4) 根据DCI提示的传输类型,如果是TM7-TM9,则将UE的数据送往DMRS信道估计模块,然后送往MIMO检测模块,否则直接送往MIMO检测模块。将该模块的数据送入PDSCH模块进行译码,从而得到一个UE的数据。
(5) 获取另一个UE的DCI信息,重复执行第(3)步至第(5)步,直至将一个子帧里面的所有UE数据处理完毕。考虑到如果出现异常中断情况,即在执行第(6)步的过程中DDR的提示状态发生了改变,那么FPGA执行完当前的UE操作后会立即跳转到第(2)步进行下一轮操作,同时保存上一个子帧的所有状态,在执行完PBCH、PCFICH和PDCCH译码后,FPGA再接着处理上一个子帧的UE数据。如果完全执行结束,那么FPGA从第(2)步开始一轮新的操作。最终,将PDSCH、PBCH、PCFICH输出的数据进行组装后输出。
在该设计模式下,接收端在遍历子帧时可以达到并行处理数据的特点,即前一子帧的数据存储和后一子帧的数据处理同步进行,整体上提高了数据的实时处理能力,为后续模块赢取时间。经过测试,在200 MHz差分时钟下以1个符号的12个子载波为基本单位,写入连续读出离散的情况下,DDR3的性能达到600 MB/s。
2 MIMO检测模块
2.1 流程设计
由上述分析可知,该方案中DDR3模块负责数据存储,资源解映射模块负责各阶段的资源位置提取,通过与DDR3进行地址信息交互调度数据给MIMO检测模块,核心计算部分为MIMO检测模块。本文选取主流的MMSE检测器,采取流水线结构,充分利用了FPGA并行处理数据的优势。
MIMO检测模块进行的是反向预编码、解层映射和复原调制符号最优估计的处理,该模式需满足不同的传输模式。针对当前的LTE-A系统,实现时采取了每个子帧完成14列OFDM符号的信道估计后统一进行MIMO检测的方案,在同一子帧内采取了遍历子载波的检测方式。检测流程设计如图3所示。

图3 MIMO检测流程设计
具体包括:
(1) 通过资源解映射模块添加子帧、OFDM符号列数、子载波号等地址信息向DDR3请求数据。
(2) DDR3通过AXI4-Stream接口返回地址及数据信息给MIMO检测模块。
(3) 通过拆分控制流信息读取传输模式,参数有误则Security验证失败。
(4) 由读取的频域数据rm(i)及信道估计数据Hm ,n(i)构造等效信道矩阵H和接收向量r。Hm ,n(i)表示接收天线m与发射天线n之间的第i个数据符号的信道估计值,rm(i)表示接收天线接收的第i个数据符号的数据。构造等效信道矩阵的过程即对应解预编码,不同的传输模式对应不同形式的等效信道矩阵[7-10]。
(5) 执行检测算法,即本文选择的MMSE算法:
(1)
(6) 解层映射及后续处理,主要针对发射分集模式,对结果中一个数据流求共轭。
2.2 关键子模块划分
按照自顶向下的设计原则,对检测模块进行了FPGA设计,顶层的设计框图如图4所示。

图4 MIMO检测模块顶层设计

控制模块主要包括时钟信号、复位信号、握手信号、参数控制流等。时钟管理方面,采取了全局时钟缓冲(BUFG)的方法,即一个高扇出缓冲器,它将信号连接到全局布线资源,实现了整个系统的同步。
矩阵求逆部分是限制吞吐性能的主要瓶颈。目前,LTE-A系统中基站端接收天线数至多为8,故运算中复矩阵B的形式为2×2、4×4、8×8,且均为Hermite正定矩阵。国内市场处于4×4MIMO初步商用的阶段,故本文设计主要支持中小规模MIMO,即4维以下的矩阵求逆。
2.3 基于Cholesky分解的矩阵求逆模块设计
基于Cholesky分解的矩阵求逆方案的基本思想是通过矩阵分解简化为下三角阵求逆的问题,可拆分为Cholesky分解、下三角矩阵求逆、矩阵乘法三个模块。
以4×4的矩阵规模为例,其Cholesky分解形式如下:
(2)
由数据依赖关系可以看出,Cholesky分解是基于开方运算来实现的,且每一列的数据运算均依赖于前几列的元素。故设计时,拆分为4个Col子模块,每个子模块完成一列元素的计算并缓存初始的输入数据。具体即Col1模块输入目标矩阵的下三角元素,计算出下三角矩阵L中的第一列元素并缓存剩余元素;Col2模块的输入数据为Col1模块的输出及缓存的原矩阵剩余元素。以此类推,分解为4级实现,各模块输出时将计算出的结果与寄存的非计算元素输出至下一模块即可。
为了提高运算效率,4个子模块计算时均通过数据依赖关系拆分组合逻辑于内部流水实现,每一列处理均优先计算出主对角线元素,然后依次参与非对角线元素的计算。如Col1模块的l21、l31、l41的计算均依赖于l11,先计算出l11并缓存,再并行处理l21、l31、l41的计算。Col2和Col3模块时序较为复杂,图5给出了第二列的流水线设计结构。Col4模块主要计算l44元素,累积误差已经较为明显,其取值依赖于l41、l42、l43,故在截位操作时需保障精度。子模块间通过valid、ready握手信号控制。

图5 Col2模块的流水线结构设计
由Cholesky分解得到下三角矩阵,求逆后进行矩阵乘法即可得到最终结果。基于数据依赖关系采取了流水+空间并行的方式,即脉动阵列求解。传统的设计均是针对上三角矩阵,由于上三角阵与下三角阵存在良好的转置对称关系,故二者的脉动阵列设计几乎完全相同,仅需调整进入PE单元的元素顺序即可。本文使用了传统的设计方案,即单元设计仍是基于乘加单元和除法单元。
2.4 2×2MIMO下的全流水设计结构
对于2×2MIMO系统,矩阵维度最小,设计中希望进一步提高模块的吞吐率。2×2场景下Cholesky分解模块与三角阵求逆模块间的数据依赖关系较为简单,为了减少缓存数据消耗的寄存器资源同时提高运算效率,本文又提出了一种无数据回流的全流水线设计结构。
设输入正定矩阵为A,元素用aij表示。
经过Cholesky分解后得到下三角矩阵L如下:
(3)
对于下三角矩阵的求逆即为:
(4)
在二维矩阵规模中,经过Cholesky分解后可以根据数据依赖关系由数据流直接构建出逆矩阵LINV的形式,无需再对中间过程三角阵的元素进行位置标识。对于求解LINV(2,1),数据依赖于l11、l22和l21,进一步拆分组合逻辑,设计为先求解对角线元素,再利用对角线元素的结果进行两次乘法运算避免了更为复杂的除法运算,达到快速求解的目的。整体上模块的输入端可以同时处理目标矩阵所有元素,内部转化为3路数据流并行处理的流水线结构,极大地提高了模块的吞吐率。模块内部涉及的乘法、除法、开方运算均通过Xilinx公司提供的成熟的IP核来实现,一定程度上保证了计算精度和性能发挥。2×2矩阵求逆整体设计结构如图6所示。

图6 求逆模块流水线结构设计
3 测试结果与分析
为了更好地评估设计方案,本节以ZYNQ系列的XC7Z100-2FFG900 FPGA芯片为硬件平台进行综合实现,并通过联合Vivado、Novas、Synopsys Vcs等软件进行了功能测试。
仿真选取在20MHz FDD系统下进行,天线配置为2×2,TM3传输场景。系统时钟最高可以支持187.5 MHz,完成一个RE的信号检测约耗时0.007 ms,仿真结果如图7所示。

图7 检测模块FPGA功能仿真图
图7中,valid、ready信号为AXI4-Stream使用的握手信号,valid为高电平时数据有效,ready阻塞信号为低电平时表示本模块当前暂停接收数据。输入的信道估计值及频域数据均为32位,高16位为虚部,低16位为实部。m_axis_datao数据为解层映射后输出的32位IQ数据流。
通常设计中信道估计及资源解映射环节会占用过多的块RAM资源,随着流水线级数和延时单元的增加,块RAM的使用量会进一步增多。为了节约资源,本设计主要使用分布式RAM即LUT资源。设计方案的资源消耗如表1所示。

表1 检测模块资源消耗
与文献[1]相比,本文在资源开销不大的情况下达到了较高的吞吐率。文献[1]中,部分资源消耗占比过高,如RAM资源占用达到33.74%,本文的设计方案中各项资源的占用率较为合理且有所降低,均为10%左右。吞吐性能方面,文献[1]采取了子帧内并行处理的方式,本文则是各子帧间并行处理数据,无明显差异。
如图8所示,将Vcs仿真导出的数据与MATLAB浮点数仿真的结果进行相对误差分析,通过大量的数据测试可以看出虽然存在一定的精度损失,但仅在10-4量级,即实现的精度在合理范围内。

图8 检测模块误差分析图
该方案现已应用于当前LTE-A系统下的空口监测产品中[11],实测环境下经CMW500仪表验证在双流传输场景下PDSCH检测吞吐可达140 Mbit/s,EVM指标接近5%,符合空中接口协议要求。
4 结 语
本文提出了一种高效率的多天线信号检测FPGA实现方案,该方案充分利用了DDR3高速读写数据的优势并采取了基于AXI4-Stream接口封装的技术极大地提高了数据处理效率。对于其核心模块MIMO检测,基于数据依赖关系,本文采取了流水线的设计结构,针对2×2MIMO场景又提出了一种新的低消耗、高吞吐的设计方案,通过全流水的方式将矩阵分解和三角阵求逆两个独立模块结合起来,节省了中间过程因控制和存储造成的资源消耗。本文方案能满足当前TM9模式的应用需求,也为无线通信系统基带核心处理部分提供了解决方案。
猜你喜欢
中国交通信息化(2017年10期)2017-06-06 07:13:20
电子制作(2016年1期)2016-11-07 08:42:54
学习月刊(2016年19期)2016-07-11 01:59:46
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:42
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:44
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
电子设计工程(2015年8期)2015-02-27 12:05:33
