
基于奇异值分解的新闻标题聚类研究
2020-04-15 02:58文晓艺郝程程
计算机技术与发展 2020年2期
文晓艺,郝程程
(上海对外经贸大学 统计与信息学院,上海 201600)
0 引 言
文本聚类技术作为文本挖掘技术的重要分支之一,有着非常广泛的应用。文本聚类的一个难点在于文本特征词提取,对此Dumais(1998)提出了隐含语义索引LSI来构造向量空间模型,通过对原文本词条矩阵进行奇异值分解来进行降维,提高聚类的效率[1]。在国内的文本挖掘相关领域中,姜宁和史忠植(2002)在对聚类分析模型进行比较的基础上,提出了贝叶斯后验模型选择方法,给出了一个用于文本聚类分析的概率模型[2];徐建锁等(2004)应用动态自组织映射神经网络来实现文本聚类,这种方法不必预先给定聚类个数,使得聚类过程更加灵活[3-4];姚清耘等(2008)探讨了基于向量空间模型的文本聚类方法,并提出了一种文本聚类的改进方法——LP算法[5];宋涛等(2010)根据潜在语义分析模型,提出了截断奇异值分解中K值的选取方法来降低文本空间的维度[6]。
文中主要研究对新闻标题这种汉语短文本的聚类问题。短文本与长文本不同,因为每条文本包含的信息较少,基于现有的以词条矩阵为基础的文本聚类,点与点之间的距离更近,研究表明现有聚类技术的效果并不明显。针对汉语简短文本,介绍了目前主要的自动分词、特征词提取以及k-均值聚类方法,并通过利用一组新闻标题数据,对主流汉语简短文本的聚类方法进行了评估。
1 汉语短文本的自动分词与特征选择
与一般文本相比,文中研究的新闻标题文本有两个突出特点:一是文本长度短,主要指新闻标题的一般不超过30个汉字;二是未登录词多,由于新闻类文本的即时性与专业性,其普通新词、专有名词与专业术语的出现频率远高于语料库一般文本。因此,文中在进行自动分词与特征提取时,重点关注这两个问题。
1.1 汉语新闻标题自动分词算法
自动分词问题是聚类孤立语与黏着语(如汉语、日语等)文本时的首要基础性工作。文本分词,即将整段文本切割为词,是获取特征词的频率及其文档频率,从而将文本数字化不可缺少的环节。然而,与西方屈折语文本不同的是,孤立语与黏着语缺乏显示标志指示词与词的分隔,因此需要计算机系统进行自动分词。汉语文本分词的主要难点是分词歧义[7]。但是,对于新闻标题类文本,未登录词对于分词精度的影响远高于歧义切分。
国内外众多学者在孤立语与黏着语自动分词领域已进行了大量研究[8]。诸多国内学者(如文献[9])将现有研究分为两大类:基于词表的分词方法和基于统计模型的分词方法。前者包括正向最大匹配法、双向扫描法、组词遍历法等,后者可分为基于词的生成式模型(word-based generative model)与基于字的区分式模型(character-based discriminative model)两大类。文中选用了三种基于统计模型的分词方法。
1.1.1 基于词的二元语法模型
基于词的n元文法模型属于生成式分词方法,是目前主流的统计分词方法之一。基于词的二元语法模型的最大概率法表述如下:
假设S为一个汉字序列,W=w1w2…wN是S可能切分出的词序列,N为词序列长度。最大概率分词过程实际上即求解使概率P(W|S)最大的切分词序列W*。根据贝叶斯公式,即:
(1)
其中,P(S|W)为生成模型,P(W)为语言模型,若P(W)采用二元语法,可以表示为:
1.1.2 基于字的一阶隐马尔可夫模型
另一种统计分词方法是基于字构词的区分式分词方法。基于字构词的一阶隐马尔可夫模型法表述如下:
对于W=w1w2…wN,采用文献[7]的做法,把字序列S=s1s2…sn转换成可能的词位序列T=t1t2…tn,其中规定每个字只有4个词位:词首(B)、词中(M)、词尾(E)和单独成词(S)。则最大概率分词过程即求解:
(2)
若采用二元语法,且假设生成模型满足一阶隐马尔可夫模型,则
其中,式(2)中的未知参数利用训练语料库进行最大似然估计,词位状态T*利用Viterbi动态规划算法求解。
1.1.3 混合模型
一般而言,模型(1)对于词典词的处理可以获得较好的表现,而对于未登陆词的分词效果欠佳。对于新闻类文本该缺点尤其重要。模型(2)恰好相反,对于词典词不能很好地识别。为了加强对未登录词的识别,在最终分词时,利用了结合最大概率法和隐马尔可夫模型的混合分词方法。
1.2 汉语新闻标题特征选择方法
文本特征选择是文本聚类的重要准备,不仅可以降低计算维度,提高计算效率,而且可能由于去除了数据噪声而提高分类的准确率。考察了基于TF-IDF(term frequency-inverse document frequency)的特征选择方法,以及基于SVD(singular value decomposition)近似的特征选择方法。
1.2.1 基于TF-IDF的特征选择方法
TF-IDF是一种用于信息搜索和信息挖掘的常用加权技术,由Salton(1988)提出,在搜索、文献分类和其他相关领域都有广泛应用。其中词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的次数,计算公式为[10]:
(3)
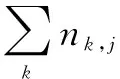
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF计算公式如下:
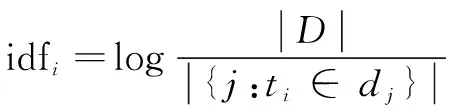
(4)
其中,|D|表示语料库中的文件总数,|{j:ti∈dj}|表示包含词语的文件数目,ti表示第i个特征词,dj表示第j条文本。如果该词语不在语料库中,就会导致式(4)分母为零。因此一般情况下,使用1+|{j:ti∈dj}|作为分母。最终,TF-IDF权重的计算公式为:
wi,j=tfi,j×idfi
(5)
其中,wi,j表示第i个特征词在第j条文本中的TF-IDF权重。
TF-IDF计算简单、易行,然而很多情况下,TF-IDF矩阵大部分元素都为0,过于稀疏。为了保证聚类效果,对TF-IDF矩阵进行奇异值分解,对求得的主成分得分矩阵进行聚类分析。
1.2.2 基于TF-IDF的SVD改进
对特征词-文档矩阵进行矩阵降维是潜在语义分析(latent semantic analysis,LSA)的基本思想,即对于传统向量空间模型的特征词-文档矩阵,应将其从稀疏的高维特征空间映射到低维潜在语义的空间,从而可能去除原始向量空间中的噪音,部分提高文本聚类精确度[11]。文中采用TF-IDF矩阵的奇异值分解,对潜在语义空间进行求解。
假设有一个M×N的特征词-文档矩阵A,其中M为特征词的数量,N为文档数目,记矩阵A的SVD分解为[12]:
A=UΣVT
(6)
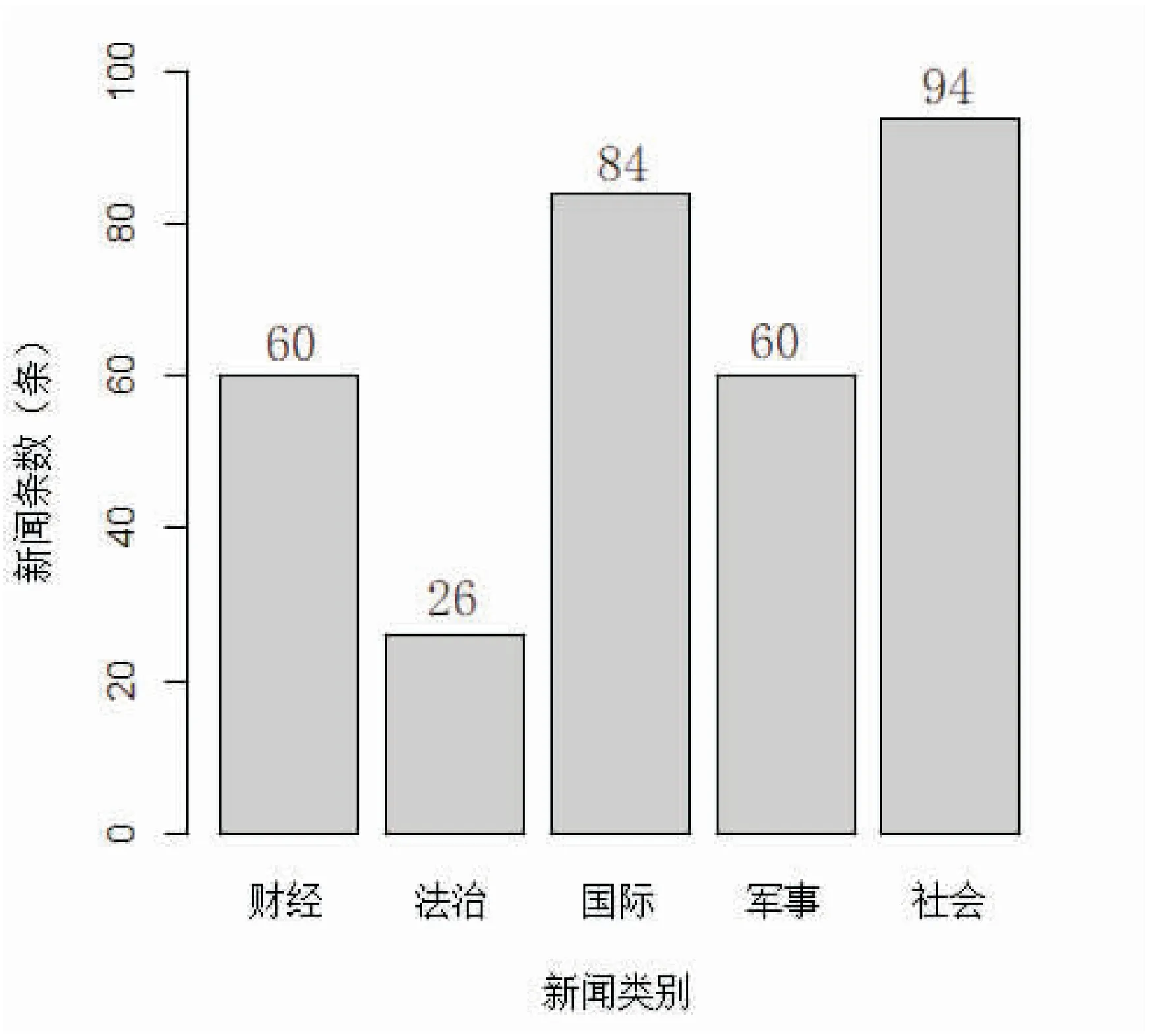
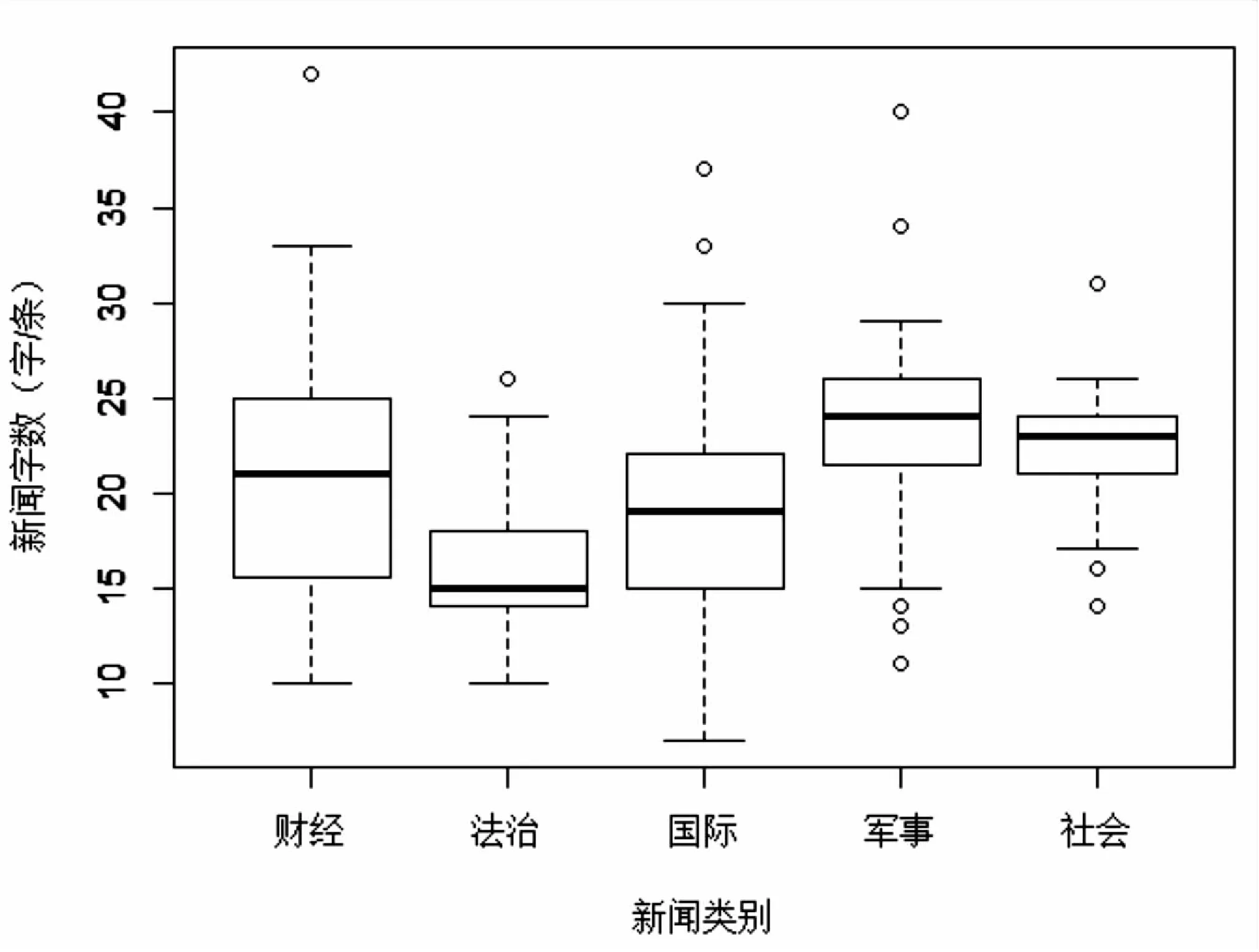
其中,U∶M×R和V∶R×N是正交矩阵,Σ∶R×R是奇异值的对角阵,R≤min{M,N}是A的秩。对Σ的对角线上的值从大到小排列,取前K (7) 其中矩阵Ak的秩为K。 SVD可以写为如下主成分分析形式: (8) 其中,vi被称为A的成分载荷,A在vi方向上的单位线性组合Z1=Av1=σ1u1在所有A的单位线性组合中样本方差最大,zi=σiui被称为第i主成分得分[13]。所以,将TF-IDF矩阵进行奇异值分解后,再用u矩阵和d矩阵组成的对角矩阵相乘,就能得到主成分得分矩阵。在实际计算中,对式(8)截取前k个主成分进行分析,这与计算式(7)数学上等价。 文中使用K-均值算法进行聚类分析。K-均值算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-均值算法以欧氏距离作为相似度测度,它是求对应某一初始聚类中心向量V的最优分类,使得评价指标J最小。算法采用误差平方和准则函数作为聚类准则函数,即各类的聚类平方和最小[14]: (9) 算法过程如下: (1)选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心,可以选择前s个主成分做聚类,假设它们在s维的坐标为αi=(αi1,αi2,…,αis)。 (2)对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类。若选取的数据点坐标为(x1,x2,…,xs),其与第i个初始中心点的欧氏距离的计算公式为: (10) (3)更新聚类中心:将每个类别中所有对象对应的均值作为该类别的聚类中心,计算目标函数的值。 (4)迭代步骤2~步骤3,直至新的质心与原质心相等或小于指定阈值,算法结束[15]。 文中从新浪新闻网爬取了财经、法治、国际、军事和社会共五类255条新闻标题,并进行了人为分类标识。这五类新闻数量不等,每类新闻的条数和平均字数如图1和图2所示。 图1 五类新闻条数 图2 五类新闻标题字数 图2是五类新闻标题字数的箱型图。可以发现,这五类新闻中,法治类新闻的平均字数最少,军事类的平均字数最多,但总的来说差异不大,都在15到20字之间,符合对汉语新闻短文本研究的目标。财经类和国际类新闻字数的变化区间较大,与它们的新闻类型有关;社会类新闻的字数变化最小。对五种新闻标题做分词处理,画出词频在前10的直方图,如图3所示。 图3 词频直方图 聚类处理过程中,为了能够更加有效地节省存储的空间及提高检索的效率,文中使用哈工大停用词表删去常用停词。鉴于分析对象的是新闻标题,没有强烈的情感倾向,未特殊保留情绪功能词。根据1.1.3节对文本进行自动分词并去停词后,得到了1 510个词条,即TF-IDF矩阵A的维度为:251×1 510。现利用式(6)对矩阵A进行SVD分解,并进行主成分分析。 选取式(8)的前三个主成分,通过观察数据发现第二主成分的数值大部分趋于0,只有1条标题的第二主成分值为-15,2条在-5左右,而这3条异常值都属于军事新闻,内容如下:“薛晓峰出席第十四届澳门青年学生军事夏令营暨第二届澳门大学生军事生活体验营开营典礼”、“特朗普回国后翻脸不认人 俄军用两大军事动作回应”、“百余名学子走进酒泉卫星发射基地体验航天梦”。可以看出这三条新闻的字数、特征词都有较大差异,共同点仅仅是它们同属于军事新闻,所以无法判断抛开极端值后,第二主成分主要包含的是文本的哪些信息。而第一主成分在前四类新闻中都不存在较大差异,可能是点过于密集的原因,但却把第五类社会类新闻与前四类区分开了,说明第一主成分主要包含的是文本的语义信息。图4和图5分别是去掉三个离群值后第一主成分和第二主成分的关系以及前三个主成分的三维图: 图4 五类新闻标题前两个主成分关系 图5 五类新闻标题前三个主成分的关系 选定前15个主成分,并将k均值聚类中的K值设为5进行聚类,可以把聚类后每一类的词云图与原始分类下的词云图进行比较,看它们在主要内容上有没有发生变化。以社会类新闻为例,对比结果见图6。 (a)聚类后的社会类新闻标题 通过计算聚类的平均准确率,可以对聚类效果有一个大致的认识,聚类的平均准确率采用文献[2]的定义,具体计算公式如下: 平均准确率: 积极准确率: 消极准确率: 其中,a、b、c、d的取值如表1所示。 表1 准确率的评价指标 可以列出取15个主成分时的每种新闻聚类准确率,如表2所示。 表2 不同主成分选取个数的聚类准确率 % 在聚类的主成分个数为15的情况下,k均值聚类的平均准确率为85.5%,其中积极准确率的均值为79.4%,消极准确率均值约为91.6%,显著高于积极准确率。 文中旨在通过对词条矩阵进行奇异值分解来降低矩阵的维度,达到更精确的分类目的。通过对新闻标题的聚类可以发现,聚类的结果并不是非常理想,认为可能有如下几个原因:由于新闻的时效性和多样性,不能从标题中提取出极具代表性的特征词;样本量较少,每条标题的字数过少;聚类方法不够好,可以尝试采用基于语义而非特征词的聚类方法。 在对文本聚类的研究过程中也进行了难点总结:首先,在将文本转换为词条矩阵时,若是保留去掉停词之后的所有词频大于等于1的词语,会使最后进行计算的矩阵过大,导致分类效率过低,而如果只提取词频较大的词语,则会损失一些信息,也会导致分类结果变差;其次,在生成词条矩阵时,已有的算法包默认只保留大于等于三个字的字符,这对处理英文文本比较实用,但处理汉语文本时会损失文本信息。2 K-均值聚类算法
3 数据介绍
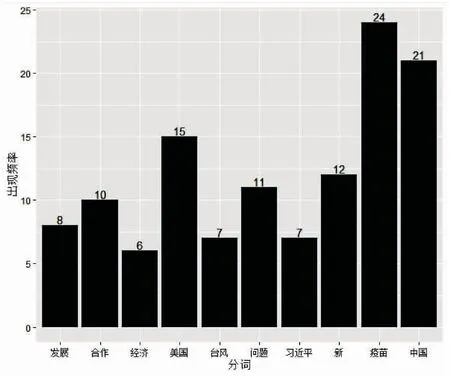
4 聚类结果
4.1 特征选择结果
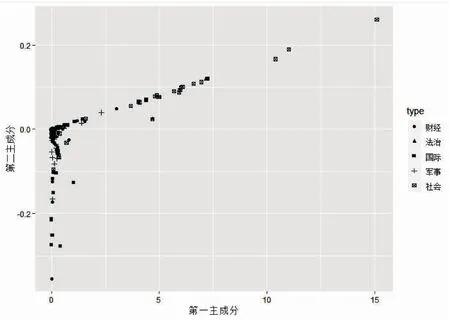

4.2 聚类结果

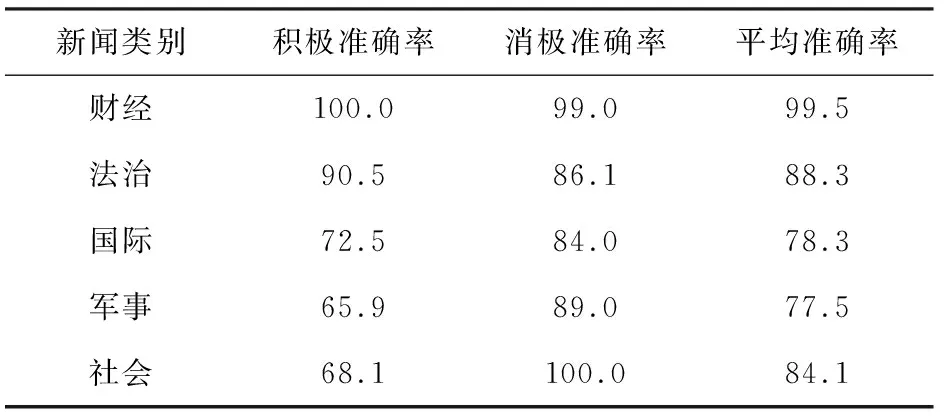
4.3 对聚类效果的评价

5 结束语
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
校园英语·月末(2021年13期)2021-03-15
健康体检与管理(2021年10期)2021-01-03
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
学校教育研究(2018年9期)2018-05-14
喜剧世界(2016年9期)2016-08-24
记者摇篮(2014年9期)2014-08-19
