
分布式混合推荐算法在新闻传播中的应用体现
2020-04-14 08:43
电子元器件与信息技术 2020年11期
(伦敦大学国王学院人文艺术学院,伦敦 SE18WA)
0 引言
在网络科技技术飞速发展中,以互联网平台为依据的信息传递方式越发完善,尤其是在经济全球化发展背景下,既丰富了网络信息储备数量又增加了技术创新难度,尤其是对不同类型的用户群体而言,无法更为准确和快速地获取所需信息。而引用推荐系统不仅能向用户群提供更多新闻讯息,而且可以解决信息过载的发展难题。简单来讲,推荐系统是指从用户的喜好、阅览行为及所在地区等信息为依据构建对应模型,而后为用户提供具有个性化特征的推荐工作。了解当前我国新闻传播发展情况可知,数字化发展对全世界文化产生了巨大影响,不管是当前发展还是未来方向都面临着极大挑战,此时只有更好掌握新闻传播的有效途径,提高新闻传播的效率和质量,才是确保新闻行业有序发展的重要举措。由于我国正处于创新发展的初级阶段,不管是城市改革还是与国际交流都在结合实践经验进行不断优化,因此正确认识新闻传播工作,为实践发展构建优质环境至关重要。这一环境既是我国对外交流和发展的基本“形象”,又是国内企业走向世界的影响因素[1]。美国作为全球新闻媒体传播发展较快的国家之一,不管是新闻产品还是舆论信息都在影响全世界其他国家,尤其是在新媒体时代下,美国媒体在快速整合数字化、互联网等内容的基础上,全面优化了新闻传播的速度和质量。这是我国在发展中需要借鉴和学习的地方,既能帮助我们更快认识现代先进技术理念和应用方向,又能根据我国基本国情对新闻传播工作进行革新。通过在国内外环境中寻找发展机遇,正确应对不断创新带来的挑战,有助于我国新闻传播工作逐渐突破传统模式的限制,充分利用现代化技术理念进行优化发展,这样不仅能传播弘扬我国优秀的民族文化,而且可以吸引更多世界先进文化成果,促使传媒市场在打破国家“围墙”的同时,逐步提高新闻传播的质量和效率,并提出与时代发展相符的传播途径。
1 基于新闻传播的准备工作
1.1 明确Spark的分布式计算平台
Spark作为现如今较为常见的并行计算框架,相比Hadoop MapReduce不管是迭代计算速度还是实际应用范围都有了明显提升,因此大部分数据公司都开始由此入手进行技术革新,见图1。由于Spark是取代MapReduce的有效方案,其中包含了Hive、HDFS等多个分布式储存层,不仅能与Hadoop生态系统融合运行,而且全面处理了以往应用系统存在的缺陷,因此在新时代新闻业技术创新发展中得到了重点关注。通过运用弹性分布式数据集RDD储备所需信息,既能准确记录每项数据又能作为分布式索引,同时结合事件驱动中的类库来进行具体任务,并依据线程池复用来降低实际开销[2]。
1.2 了解个性化推荐研究内容
在网络技术全方位推广的背景下,随着线上阅读人数和数量的增加,针对信息搜索和传播的推荐系统和舆情分析系统得到了“涌现”。对比两者分析,前者在市场中并不常见,尤其是现如今的网络市场环境不稳定,所以不管是发现新闻事件还是个性化推荐等相关系统设计依旧处于发展的初级阶段。以中文事件为例,Liu Shuwei等人在实践探究中研制出以TF密度为依据的话题识别和跟踪调查系统,而孙玲芳等人也在优化K-means聚类算法的过程中,控制了算法对孤立点的影响,有效提高了工作状态下的系统效率。
现阶段,最有应用价值的个性化推荐算法主要分为三种:第一,以内容为依据进行推荐。通过先对新闻实施建模,而后依据用户浏览新闻信息形成兴趣模型,最终将与用户感兴趣的相关内容推荐给该用户。在这一过程中,构建模型和计算相似度是做好内容推荐的重难点,也是当前科研人员关注的焦点。第二,协同过滤推荐。其是指结合用户之前提供的浏览记录实施推荐,通常来讲和内容没有关联。Badrul Sarwar等人以项目为依据设计了明确的协同过滤算法,有效解决了以往计算效率过低的难题,且保障了实际应用结构的准确率[3]。第三,混合推荐。由于两种算法都存在优缺点,因此有人结合实践应用情况提出了有效整合两种算法的推荐算法,不仅能降低训练集的数量,而且可以加快程序工作效率。
2 分析分布式混合推荐算法
了解当前基于新闻传播进行的推荐算法可知,其并没有整合研究事件相关性和用户兴趣等问题,所以本文主要从这一角度入手研究具有高效性和个性化的推荐算法。
2.1 发现新闻事件
通过运用整改后的层次聚类发现新闻事件,再计算每个事件的热度、簇内方差等信息,可以为后续建模提供有效依据。以往层次聚类算法一般都会存在较大的簇,其中包含非常多的数据信息,且随着计算速度的加快会持续合并周边的小簇,这种现象就是“大簇现象”。整合实践案例分析,出现这一现象的原因在于合并过程中出现重叠模糊问题,这是由于算法执行后期,簇与簇之间的距离越来越小,且大簇的权重分布非常均衡,所以大簇在“合并”时就会随着熵的增加而扩大范围,最终形成恶性循环。
为了有效处理这一问题,工作人员可以科学调节簇与簇之间的距离计算公式,具体公式如下所示:
公式当中的newsk和newsi分别代表不同簇中相对距离最远的新闻事件,而title和content分别表示新闻的标题与内容的特征向量,cluster代表其中某个新闻事件[4]。
在调整好公式之后,为其引入簇与簇之间最远的距离,在这个距离达到最大的情况下,不同簇间的新闻相同程度会降低,此时极容易受大簇所影响降低簇的中心距离,因此整合以往工作经验分析需要从中心距离和最远间距入手,加权求和就能有效控制上述现象的发生。本文设定权重α为3/7,在验证实验当中,选用人工标注的2000篇新闻对簇与簇之间的距离和紧密情况实施判断,其中有三种聚类算法效果如下表所示。
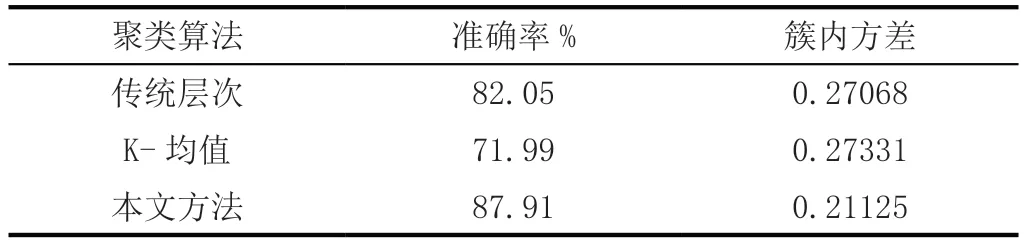
表1 三种聚类算法的结果对比
通过观察表格可以发现,改进之后的算法更加有效,不仅能提高实际工作的准确率,而且可以提升整体工作效率和质量。
2.2 个性化推荐算法
要想快速处理以往个性化推荐算法在工作中涌现出的问题,如冷启动、矩阵稀疏等,可以通过有效结合两种算法实施个性化推荐:第一,先做好数据集的预处理工作,根据收集与用户和事件相关信息实施建模;第二,每位用户寻找与模型相近的邻居集;第三,运用这一内容记录最近的新闻事件阅览情况,而后计算用户邻居同样喜欢但没有被用户阅览的内容,记录成推荐列表;第四,依据数量、阙值等对事件的推荐列表进行正确筛选[5]。
一方面,事件模型。通过运用向量空间模型实施建模工作,认真计算每个事件当中不同单词的权重,而后按照大小顺序来排列,并优选出权重超过阙值的单词,将其看作事件模型的空间向量模型vsm[6]。由于上述公式计算中的新闻数量比较大,所以每个单词都会在每个事件或只在某个事件中出现过,所以运用总数除以包含某词的事件数时,会降低IDF的数值,而运用总数除以包含单词t的新闻数时可以有效解决这一问题[7]。
另一方面,构建用户兴趣的模型。通过从时间衰减函数、事件的热度和关键词入手,这种算法是以用户兴趣及其阅览事件的行为为依据,为不同类型的用户构建相应的兴趣模型,整合实践应用情况分析,新算法的提出有效解决了以往用户和项目在描述文件中出现的数据过少等问题,不仅能全面掌握用户兴趣爱好,而且可以帮助某个用户对其所在群体的共同爱好进行判断。
3 如何实现Spark的推荐算法
基于Spark的推荐算法的整体生态系统都是以RDD为基础进行具体操作的,这一内容只用来读取数据块。RDD也叫做弹性分布式数据集,在计算时若是内部储存出现不够的问题,能和磁盘实现数据交换。一般来讲,Spark推荐算法中的RDD可以选择两种方式进行构建:一种从Hadoop入手,另一种依据Spark Context中的parallelize方法,并化处理Driver的数据集,最终得到分布式的RDD[8]。
本文所选方法为前者,具体步骤如下所示:第一,在HDFS中得到最初的数据集,并掌握初期的新闻RDD;第二,通过新闻聚类获取Cluster RDD;第三,根据Cluster RDD计算事件模型,并得到相应的RDD;第四,在HDFS中收集与用户阅览事件有关的数据信息,并找到用户——新闻RDD;第五,将Cluster RDD与用户——新闻RDD两者融合到一起,获取用户——事件RDD;第六,从事件模型和用户事件RDD入手研究用户兴趣的相关模型,并获取用户——兴趣RDD;第七,认真计算用户之间的距离,并由此获取用户——邻居RDD;第八,寻找用户和邻居之间的共同兴趣,并在有序过滤后将其排列成正规的推荐表格[9]。
4 结论
综上所述,从分布式混合推荐算法入手全面研究当前新闻事件传播的技术内容,向不同类型的用户提供有价值和所喜爱的新闻讯息,不仅能满足他们提出的个性需求,而且可以有助于他们更为便捷和快速的掌握新闻事件变化。与此同时,本文研究所实现的分布式算法能突破传统网络平台传播新闻受到的限制,既符合大数据时代发展特点,又能快速处理新闻数据集,促使未来新闻传播工作得到全方位发展。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
成都信息工程大学学报(2021年3期)2021-11-22
煤气与热力(2021年9期)2021-11-06
军民两用技术与产品(2021年5期)2021-07-28
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
文苑(2020年4期)2020-05-30
电子制作(2019年22期)2020-01-14
汽车与新动力(2016年6期)2017-01-04
互联网天地(2016年1期)2016-05-04
