
多标签分类的传统民族服饰纹样图像语义理解
2020-04-11 02:08:08赵海英侯小刚齐光磊
光学精密工程 2020年3期
赵海英,周 伟,侯小刚,齐光磊
(1.北京邮电大学 计算机学院,北京 100876;2.北京邮电大学 数字媒体与设计艺术学院,北京 100876;3.北京邮电大学 网络技术研究院,北京100876;4.北京邮电大学 世纪学院,北京 102101)
1 引 言
传统民族服饰纹样记载着一个民族从建立到发展过程的历史文化演变,在对服饰纹样进行解读时,不仅需要明确纹样的类别(本体),更需要诠释各纹样所具有的深层文化语义信息(隐义)。例如,传统民族服饰中纹样本体“龙”是古代皇帝的象征,隐义是“权势、高贵”;纹样本体“牡丹”被誉为花王,隐义是“富贵、美满”;纹样本体“桃”具有图腾、生殖崇拜的原始信仰,隐义是“长寿、健康”。因此,在对传统民族服饰纹样进行多标签分类时,从“本体”和“隐义”两个层面分类,可以更全面地阐述传统民族服饰纹样所蕴含的文化语义信息。
近年来,基于深度学习的方法在图像分割[1]、识别[2]和检索[3]等一系列计算机视觉任务中取得了巨大的成功。与此同时,基于深度学习的图像多标签分类方法越来越受欢迎。一方面,由于卷积神经网络(Convolutional Neural Networks,CNN)在单标签分类任务的成功,很多研究者直接将CNN应用到多标签分类任务上[4-8]。例如WEI等[4]以任意数量的对象片段假设作为输入,将共享的CNN与每个假设相连,最后将不同假设的CNN输出结果用最大池化进行聚合,得到最终的多标签预测。Yu等[6]将图像的全局先验信息和局部实例信息相结合构建了一个新的双流网络,可以自动定位触发标签的关键图像模式。另一方面,由于循环神经网络(Recurrent Neural Network,RNN)在机器翻译、图像描述以及视觉问题回答等任务的成功应用,一些学者将图像多分类看作是序列生成问题,同时利用RNN建立标签之间的依赖关系[9-12]。例如,JIN等[9]将图像标注任务作为一个序列生成问题,提出RIA模型能够根据图像内容对标签的长度进行原生预测,并考虑训练标注序列输入到LSTM顺序的影响。WANG等[10]构建一个端到端的CNN-RNN框架,学习图像标签嵌入的方法来表征隐义标签依赖关系和图像标签相关性。
然而,上述方法只能对图像中多个物体类别(本体)进行分类,而不能对同一张图像中各类别所蕴含的深层次语义信息(隐义)进行分类。为解决上述问题,本文提出了一个“本体-隐义”融合学习的图像多标签分类模型,该模型首先利用CNN中间层学习图像的本体信息,利用CNN较高层学习图像的隐义信息,然后利用本体信息和隐义信息之间的依赖关系设计融合学习模型,实现对图像中多类别以及各类别蕴含的深层语义信息分类。此外,在传统民族服饰纹样图像数据集和Scene数据集上进行对比实验,实验结果证明了本文方法在图像多标签分类任务上的有效性和优越性。
2 “本体-隐义”融合学习的多标签分类模型
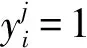
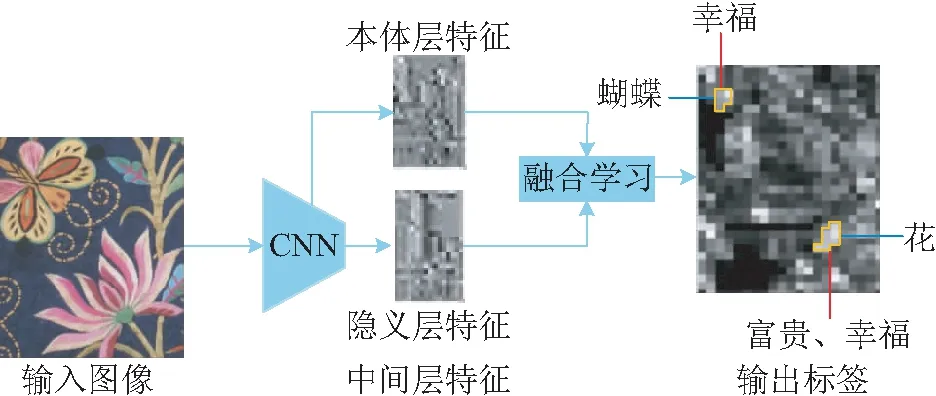
图1 构建模型纵览图Fig.1 Overview of the present model
从“本体”和“隐义”两个层面对传统民族服饰纹样进行分类,如表1所示,可以更全面地阐述传统民族服饰纹样所蕴含的文化语义信息。
2.1 模型结构
CNNs可以学习丰富的图像层次特征,例如AlexNet模型前两层学习的是颜色、边缘等低层特征,第3层学习的是较复杂的纹理特征,第4层学习的是特定类别的局部特征,第5层学习的是具有辨别性的完整特征[13],即网络的低层特征包含更多的图像结构信息,中间层因卷积核感受野小且个数多,更容易学习图像的区域或局部特征,而高层特征更关注图像的语义信息。

表1 图像的本体标签和隐义标签多分类
在本文中,本体信息描述图像中存在的物体类别,而隐义信息诠释图像所蕴含的深层次文化语义,与本体信息相比较,隐义信息需要考虑图像中存在的物体类别、组合规则等信息,从而需要更高层的特征进行表征。因此,在同一个网络中,可以利用网络的中间层学习图像的本体信息,高层学习图像的隐义信息。然后,将本体信息和隐义信息分别利用损失函数进行训练后,采用融合学习的方式更新网络参数,可以捕获图像的本体信息与隐义信息之间的关联性,从而实现了对同一张图像的本体标签分类和隐义标签分类。本文选取Inception-V3[14]作为基准模型,构建了一种“本体-隐义”融合学习的图像多标签分类模型,如图2所示(彩图见期刊电子版)。为简单直观地表述,图中红色虚线模块为重复模块,“x3”表示此模块按先后顺序重复3次,“x4”同理。(注:为便于下文表述,图中红色箭头为对应节点名称,其中mixed_2和mixed_7分别是最后一个重复模块的节点名称)

图2 “本体-隐义”融合学习的多标签分类模型Fig.2 Multi-label classification model based on “ontology-implicit” fusion learning
由于Inception-V3模型网络层次较深,通常需要在非常大的数据集上经过数百万次训练才能达到较好的效果。因此,本文利用ImageNet上预训练的Inception-V3在多标签分类任务上微调。本文采用的多标签损失函数为交叉熵损失。其中,采用Sigmoid作为激活函数得到输出hθ(x):
(1)
预测值和真实值概率之间的交叉熵如下:

(2)
其中yi∈{0,1}。记本体标签的损失函数为Jy(θ),隐义标签的损失函数为Js(θ),将两者加权求和进行融合学习,得到模型总损失函数为Jsum(θ),最后进行反向传播降低误差,以获得更好的分类效果:
Jsum(θ)=λJy(θ)+Js(θ),
(3)
其中λ为本体标签的损失函数Jy(θ)的权重。
2.2 模型不同中间层特征影响研究
Inception-V3网络模型深度较深,模型中包含许多卷积操作和池化操作。为了研究Inception-V3模型不同位置获取的中间层图像特征对本体标签多分类结果的影响,如图3所示,本文对Inception-V3模型的3个不同位置做出以下探讨。

图3 卷积和池化操作Fig.3 Convolution and pooling operations
在图3(a)中,获取Inception-V3网络模型的非Inception Module的第2个池化层(即Pool_1)输出特征,在其后面接1个平均池化层和3个卷积层,然后再接全连接层。在图3(b)中,在Inception-V3模型中的第1个Inception模块组的输出(即Mixed_2)后面,连接1个平均池化层和3个卷积层,然后再接全连接层。章节2.1中间层如图3(c)所示,即在Inception-V3模型中的第2个Inception模块组的输出(即Mixed_7)后面,连接一个平均池化层和两个卷积层,然后再接全连接层。下文将对不同中间层特征进行实验,对比效果差异。
3 模型不同结构对比研究
在2.1节中介绍的“本体-隐义”融合学习的图像多标签分类CNN模型基础上,对模型结构进行修改,提出另外3种“本体-隐义”图像多标签分类模型,下面对3个对比模型进行详细阐述。
3.1 单流网络
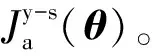

图4 单流网络Fig.4 Single stream network
3.2 分流网络
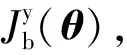
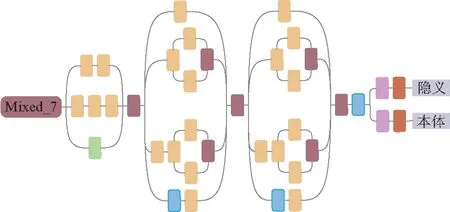
图5 分流网络Fig.5 Shunt network
3.3 中间层分流网络

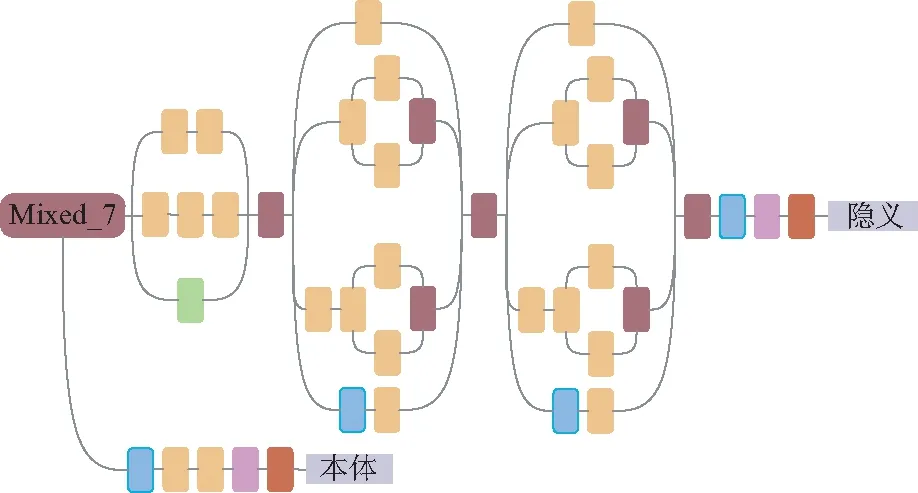
图6 中间层分流网络Fig.6 Intermediate shunt network
4 实验结果与分析
4.1 实验数据与评价指标
本文在传统民族服饰纹样图像数据集和Scene数据集上进行多标签分类的对比实验。传统民族服饰纹样图像数据集由本实验室构建,共有3 000张图像,每张图像均含有本体和隐义两层标签。本体标签包含8个不同类别,即花、桃、鸟、龙、蝴蝶、蝙蝠、祥云以及人物;隐义标签包含有7个不同类别,即富贵、喜庆、权势、幸福、典故、吉祥以及长寿。另外,Scene数据集[15]共有2 000张图像,包含沙漠、山脉、海洋、日落和树木类等5类自然场景。另外,将两个数据集分别按6∶2∶2的比例划分为训练集、验证集和测试集。两个数据集的统计信息如表2所示,其中“>1 标签”表示同时含有多个标签的图像在数据集中所占比例大小。

表2 数据集统计信息
在传统民族服饰纹样图像数据集上,使用和文献[9]同样的评价指标,利用公式(4)计算总体的精确率、召回率和F1值(O-P、O-R、O-F1),以及每个类别的精确率、召回率和F1值(C-P、C-R、C-F1)。同时参考文献[5],本文对每个类别也采用平均精度(Average Precision,AP),对于总体也采用平均精度均值(mAP)。
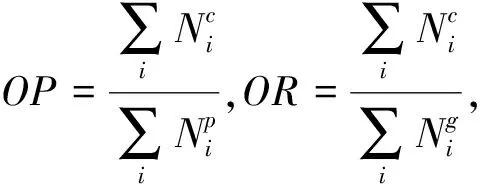
(4)
在实验中,本文使用TensorFlow深度学习框架,利用在ImageNet2012分类挑战数据集上预训练的Inception-v3作为基础模型。模型训练的初始学习率为0.001,共训练15 000步,在第10 000步时学习率降低为之前的1/10,动量率为0.9,权重衰减率为0.000 5,使用随机梯度下降法(Stochastic Gradient Descent,SGD)进行优化,batch_size设置为100,同时将原始图像大小调整为299×299作为模型的输入。
为标记简洁,将单流网络、分流网络、中间层分流网络以及2.1章节中提出的模型依次记为M1,M2,M3以及M4,同时考虑Inception-v3中间层的影响,将Pool_1,Mixed_2和Mixed_7输出依次记为A,B和C,并将Pool_3的输出记为D。在Scene数据集上进行对比实验时,遵循NGRM-1方法实验设置,即使用标准5-折交叉验证进行评估,报告5次实验的平均性能,此外对比方法还有MLR[16],MIMLfast[17],KISAR[18]和MIMLcaus[19]。
4.2 实验结果
4.2.1 模型不同中间层特征对比结果
通过对“本体-隐义”融合学习的图像多标签分类模型(M4)的不同中间层特征进行研究,在传统民族服饰纹样图像数据集上的实验结果如表3所示,同时M4-A、M4-B和M4-C的参数量(单位:×105)分别是26.32,26.68和28.15。从表中可以看出,在AP的大多数指标上,M4-C的结果优于M4-A和M4-B,并且在mAP指标上获得了最好的结果,尽管M4-C模型参数量相较于M4-A和M4-B有所增加,但性能的提升是可观的。因此,在本文的后续实验中,将采用Mixed_7作为中间层输出。

表3 模型M4不同中间层特征的AP和mAP对比结果
注:黑色加粗为单列指标最好结果。
4.2.2 模型融合学习参数选择
由公式(3)可知,λ为模型M4中本体标签损失函数的权重值。将模型M4在传统民族服饰纹样图像数据集进行实验,并且λ在[0.4,1.6]内取值,实验结果如图7所示(彩图见期刊电子版)。从图中可以看出,在λ的取值范围内本体标签分类的mAP值(红线)显著高于隐义标签分类的mAP值(绿线),另外当λ取0.8或1.2时,本体和隐义的mAP值之和取得最大值(蓝线)。考虑到隐义标签分类的mAP值较小,在误差反向传播时应赋予较大的权重,因此λ取值为0.8。

图7 不同λ对应的本体标签和隐义标签分类的mAPFig.7 mAP of ontology label and implicit label classification corresponding to different λ
4.2.3 模型不同结构对比结果
本文比较了提出的4种模型结构,在传统民族服饰纹样图像数据集上的实验结果如表4所示(由于M1是将本体标签和隐义标签看作一个整体进行训练,得到的是整体C-P,C-R,C-F1,O-P,O-R,O-F1以及mAP值,为方便直观与其它网络结果进行比较,将其看作是本体标签分类和隐义标签分类的结果)。从表中可以看出,无论是本体标签分类结果还是隐义标签分类结果,M4在大多数指标上获得了最好的结果,并且在mAP指标上明显优于其它方法。另外,比较4个模型的参数量(单位:×105),模型M4的参数量相较于模型M1和模型M2有所增加,但模型性能的提高是巨大的,如在本体标签分类的指标mAP上分别提高10%和5%,同时比较模型M4和M3的参数量,可以发现参数量几乎相等(数据只保留两位小数),但采用融合学习使得在隐义标签分类的指标mAP上提高1%。因此,将本体信息和隐义信息进行融合学习,可以很好地捕获两种之间的关联性,更好地提高模型分类的性能。

表4 4种模型结构对比结果
注:黑色加粗为单列指标最好结果。
4.2.4 Scene数据集实验对比结果
为验证本文提出模型的图像多标签分类效果,在公开的Scene数据集上与其他方法进行性能比较。实验对比结果如表5所示,其中“↓”表示“越小越好”,“↑”表示“越大越好”。可以看出,本文方法M4-D在Hamming loss、One-error和Average precision指标上分别优于其他最好方法0.103,0.096和0.083。在Coverage和Rank loss指标上与NGRM-1(SVM)方法性能接近,可以表明本文方法的优越性。同时,本文M4-C方法在Hamming loss和Average precision指标上优于NGRM-1(3NN)方法,验证了CNN中间层的有效性,即CNN中间层能够有效学习图像特征。

表5 图像多标签分类方法的性能比(mean±std)
注:黑色加粗为单列指标最好结果。
5 结 论
本文提出了“本体-隐义”融合学习的图像多标签分类模型。该模型能够模仿人类的方式观察图像,既能对图像中物体类别信息(本体)进行分类,又能识别各个物体类别所蕴含的深层次语义信息(隐义)。该模型首先利用CNN中间层和较高层分别学习图像的本体信息和隐义信息,然后利用本体信息与隐义信息之间的依赖关系设计融合学习模型,从而实现对图像中多类别以及各类别蕴含的深层语义信息分类。在传统民族服饰纹样图像数据集进行实验,结果表明模型的中间层特征能够有效表示图像的本体信息,利用融合学习可进一步提高分类的准确性;在Scene数据集上进行实验,结果表明本文方法在指标Hamming loss、One-error和Average precision上大幅度优于其他方法。在后续的工作中,将尝试利用两个CNN网络分别学习本体信息和隐义信息再进行融合学习。
猜你喜欢
艺术设计研究(2020年2期)2020-05-09 01:13:20
流行色(2019年7期)2019-09-27 09:33:20
流行色(2019年7期)2019-09-27 09:33:08
艺术设计研究(2019年1期)2019-04-23 03:10:32
西藏艺术研究(2018年1期)2018-07-10 08:33:54
艺术设计研究(2018年1期)2018-05-19 02:00:35
湖南包装(2016年2期)2016-03-11 15:53:17
焊接(2016年8期)2016-02-27 13:05:10
焊接(2016年6期)2016-02-27 13:04:55
Coco薇(2015年10期)2015-10-19 15:03:24
