
气象数据融合性统计比较分析
2020-04-09 04:41费强许欢
无线互联科技 2020年2期
费强 许欢


摘 要:气象数据的记录早期都是人工进行观测并记录而获得的。随着计算机技术的发展、自动化水平的提高,部分气象观测站点的气象数据逐渐开始应用仪器自动记录气象观测数据,如何将双套站的两套数据融合成一套数据成为气象站业务投入前必须解决的问题。文章利用安徽气象局祁门站由A,B两套仪器测得的气温观测数据,在对数据进行有效的预处理之后,提出了3种融合数据算法:一是基于空间一致性的主备法;二是基于数据的滑动方差和标准差,对数据赋以不同权重的权重法;三是基于差值订正的合成法。将其进行分析和评估并比较融合效果,结果表明,3种算法都是合理的,融合值基本可以反映真实的情况。
关键词:气象;滑动方差;空间一致性;数据融合
1 我国自动气象站发展概述
我国是世界上气候变化较大的地区之一,为了对极端天气进行提前预防和抵御,中国气象局大力采取一系列措施,推动和促进大气监测自动化快速发展[1]。从1999年我国自行研发第一批自动气象站开始,到现在已有30 000多个自动气象站,在很大程度上增加了地面气象观测资料的时间密度并提高了观测数据的精确度[2]。随着气象科技的发展,双套自动气象站建成并已投入使用。双套自动站的建设工作是在原有自动气象站的基础上,再建设一套新型自动气象观测设备,从而取消人工对比观测,实现双套自动观测数据的对比观测,在一定程度上解放了观测员,推动了气象现代化的进程[3-4]。
在双套自动气象站出现的同时,问题也随之而来。双套站拥有A,B两套仪器,每套仪器各测出一套数据,许多服务只需要一套观测数据进行分析处理即可,因此,如何将A,B两套仪器的观测数据融合为一组数据成为自动气象站亟需解决的问题[5-6]。本研究利用安徽气象局祁门站由A,B两套仪器测得的气温观测数据,对原始数据进行有效处理后,利用基于空间一致性的主备法,基于数据的滑动方差和标准差,对数据赋以不同权重的权重法,基于差值订正的合成法气象数据进行融合。分别将3种方法的融合结果与安徽气象局祁门站观测数据进行比较,对其进行分析和评估[7-8],并比较3种方法的融合效果,得出结论。
2 算法简介
2.1 主备法
主备法的思想为当两套观测数据偏差在最大许可范围之内,将其中一套仪器作为主站,另一套作为备用站;当数据差值异常时,利用空间一致性判断,用对应的数据替换异常值。
3 算法结果与评估
本研究使用的数据是祁门双套站2016年1—5月的数据,涉及气温、地温、气压、蒸发量等多个要素,以及同时期周边4个台站(休宁站、黟县站、歙县站、屯溪站)的气象数据资料,和祁门站的人工检测气象数据,如表1所示。
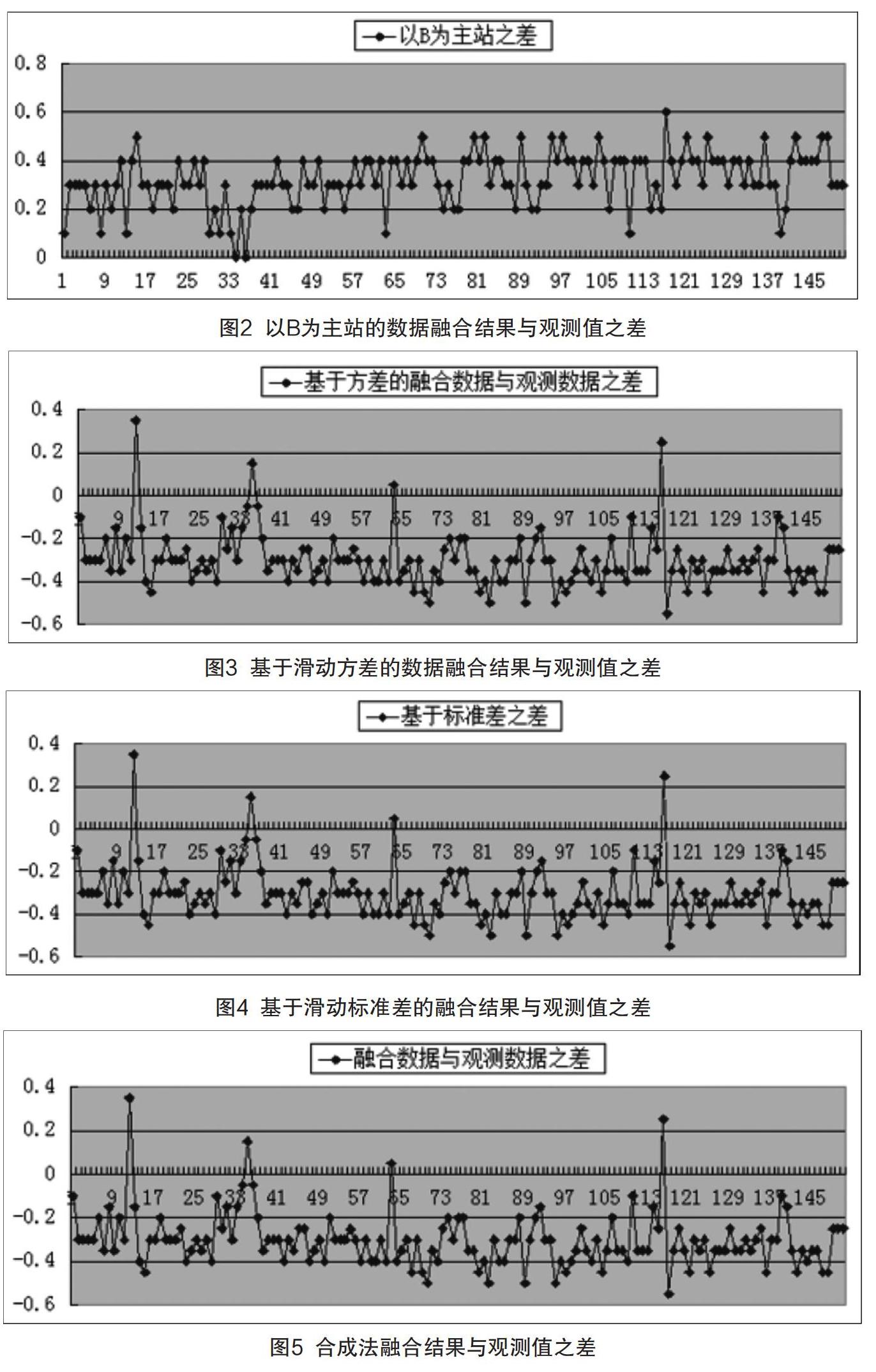
图1—5为3种算法5种方法,合成法的融合结果、以A为主站的融合结果、以B为主站的融合结果、基于滑动方差的融合结果、基于滑动标准差的融合结果与观测值的差值的比较。
由图1和图2可以直观地看出,主备法差值的波动程度最大,由算法公式可以看出,主备法的精确度为0.10,合成法的精确度为0.05,而权重法的精确度最高。所以并不能从超差率就断言哪个算法最好。主备法的超差率最小的原因在于A,B两站的观测数据相差较小,在±0.4内,A,B两站与本站观测数据相差较大,若A数据与观测值相差0.4,B数据与观测值相差0.6,从算法角度而言,以A为主站的主备法融合差值为0.4,权重法的融合差值在0.4~0.6,而合成法差值为0.5,导致了权重法及合成法的超差率较主备法大。但论精度权重法最好,合成法次之,主备法最差。因此,如果A,B站与观测值之间相差不大,权重法的融合效果最好。
由算法可知,主备法的优势在于利用了空间一致性。在发现原始数据出现较大异常的情况下,单单将缺测一方用另一方的数据来填补并不够,还必须对其进行数据是否差异过大进行判断[9]。当选出差异过大的数据后,则应找到一个标准来衡量是因为哪一方的数据异常,才导致了两组数据差值过大的情况发生[10-11]。此时,选择1~2个与自动站无关的数据作为标准,显然比直接选取A站或B站本身作为标准要合理。本研究选择了与自动站数据相独立的周边站台数据作为衡量的标准,摆脱了自動站数据本身的影响。利用空间的均匀性加权得到的与自动站所在位置的气象数据相接近。选择该数据作为处理异常数据的标准,可以合理地找到异常的一方,即与标准数据差异较大的一方。再将标准数据替换掉异常的数据,使得处理之后的数据与真实的数据值较为接近,且两组数据的差异较小,有助于融合出更贴近真实值的数据[12]。
权重法的优势在于不仅利用主备法中的空间一致性对数据进行了预处理,并且在数据融合的整个过程中,没有采取传统的对整个样本求方差、标准差的方法,而是采用了只选取该点数据附近一定数量的数据作为计算样本进行运算,将其称之为滑动方差、标准差。本文将滑动长度定为20,考虑到气象数据会随着时间的往后推移,呈现出较大的变化,或者出现周期性特征会对数据的方差、标准差产生影响,从而影响对于A,B自动站本身观测数据稳定性的判断,将方差的计算样本控制在20以内,可以有效消除这种影响。
合成法的优势在于当A,B站观测数据在0.4之内时,将普遍意义上更接近于真值的均值当作融合数据;当A,B站差值超出误差允许范围时,将此时数据与前面4个时次的差值相比较,得出跟接近于真值的融合数据。
4 结语
本研究利用安徽气象局祁门站的由A,B两套仪器测得的气温观测数据,对主备法、权重法和合成法进行分析和评估。结果表明,基于空间一致性的主备法,基于数据的滑动方差和标准差、对数据赋以不同的权重的权重法,基于差值订正的合成法这3种算法都是合理、可行的。三者的精确度不同,主备法的精确度为0.1,合成法的精确度为0.05,权重法的精确度最高。在不同的数据条件下三者的融合效果也不同,若在A,B站观测值相近但与本站观测数据相差较大的情况下,主备法的融合效果更佳;若在A,B站观测值相近且与本站观测值也相近的条件下,权重法的融合效果更好。
总的来说,双套站的自动观测方法可以在很大程度上解决单套运行的自动站由于设备故障、环境因素所造成的观测数据异常以及缺乏同时期、同要素数据的对比问题,大大提高了观测气象要素的准确度。
[参考文献]
[1]华连生,华洋,徐光清,等.“双套站”气温模拟评估[C].厦门:第28届中国气象学会年会,2011.
[2]温华洋,徐光清,华连生,等.“双套站”数据处理方法探索[C].厦门:第28届中国气象学会年会—S1第四届气象综合探测技术研讨会,2011.
[3]唐为安,吴必文,徐光清,等.安徽国家基准气候站自动与人工气温对比分析[C].杭州:第26届中国气象学会年会第三届气象综合探测技术研讨会分会场,2009.
[4]温华阳,徐光清,张虎,等.双套自动气象站数据评估及其优势探讨[J].应用气象学报,2012(6):748-754.
[5]李艳萍.地理信息系统与气象的融合应用[J].广西气象,2004(S1):72-74.
[6]汪冬华.多元统计分析与SPSS应用[M].上海:华东理工大学出版社,2010.
[7]盛骤,谢世千,潘乘毅.概率论与数理统计[M].北京:高等教育出版社,2008.
[8]郑明,陈子毅,汪嘉冈.数理统计讲义[M].上海:复旦大学出版社,2006.
[9]邱声春.数据挖掘和数据融合技术在天气预报和气象服务中的应用研究[J].山西气象,2007(2):34-36.
[10]楊华,林卉.数据融合的研究综述[J].矿山测量,2005(3):24-28.
[11]杨明,冯径.气象多数据源数据融合模型研究[J].计算机与现代化,2005(3):13-14.
[12]石阳,刘东华,邱宗旭,等.智能专业气象信息融合与服务系统初步探讨[J].广东气象,2012(6):51-54.
Abstract:The records of meteorological data were obtained by manual observation and recording in the early stage. With the improvement of computer technology and automation level, the meteorological data of some meteorological observation stations gradually began to use instruments to record meteorological observation data automatically. Based on the temperature observation data measured by A and B two sets of instruments in Qimen station of Anhui Meteorological Bureau, this paper proposes three fusion data algorithms after effective preprocessing of the data. One is the main-standby method based on spatial consistency, the other is the sliding variance and standard based on data difference, the weighting method with different weights on the data, and the third is the synthesis method based on the difference correction. The three algorithms are analyzed and evaluated and the fusion effect of the three methods is compared. The results show that the three algorithms are reasonable, and the fusion value can basically reflect the real situation.
Key words:meteorological; sliding variance; spatial consistency; data fusion
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18
内蒙古气象(2021年2期)2021-07-01
领导决策信息(2018年46期)2018-04-20
百科探秘·航空航天(2017年11期)2017-12-20
现代电子技术(2016年24期)2017-01-19
东方教育(2016年10期)2017-01-16
