
引入Self-Attention的电力作业违规穿戴智能检测技术研究
2020-04-02 09:53:32莫蓓蓓吴克河
计算机与现代化 2020年2期
莫蓓蓓,吴克河
(华北电力大学控制与计算机工程学院,北京 102206)
0 引 言
“安全第一,生产第二”一直是高危作业现场最常见的标语,强调了安全施工远比不顾安全的盲目生产更加重要。在电力系统中,进入现场作业必须正确佩戴安全帽及身着工作制服。电力作业现场存在大量大型危险设备,安全帽的佩戴对作业人员来说必不可少;工作制服是电力部门根据现场作业特点而专门设计的,具有耐磨、防静电、燃烧时防粘皮肤等特点。因此安全防护用品的正确穿戴能一定程度上避免事故的发生或者在事故发生时大大降低人员受伤害程度。但是,由于作业点大多处于户外,作业人员长期处于炎热、暴晒的环境中,导致一些诸如未佩戴安全帽、未扣紧帽带、敞开工作服等违反安全规则的行为时有发生,给作业人员带来了安全隐患。据权威统计数据显示,近年来在作业过程中因不正确佩戴安全防护用品而发生的伤亡事故占电力行业各类生产事故的50%以上[1],安全事故发生的类型以及安全防护用品使用情况的统计分析(抽样调查200个安全帽使用案例)如表1所示。
表1 安全防护用品佩戴情况统计

安全防护用品使用情况数量/件所占比例/%备注情况正确佩戴安全帽17085可发挥保护作用不正确佩戴安全帽2211有条件发挥作用未佩戴安全帽84防护完全失效
从表1可以看出,安全防护用品的佩戴与否以及佩戴方式决定了其能否有效发挥防护作用。
无规矩不成方圆,要保证生产的安全稳步开展,不仅需要加强安全文化建设、提高作业人员自身的安全意识,还要制定全面监管策略、采取有效监管措施对人员的行为加以约束[2-3]。其中,最直观有效的监管方式就是在作业现场设置专职巡管人员和摄像头对作业人员进行监督,及时发现违规行为并进行纠正。
为了提高监管水平,现在多采用自动化监管方法取代低效的人工巡检方式,近年来已有许多研究人员提出了对施工现场安全防护用品穿戴的实时监测技术[4-10]。目前主流技术是通过摄像头采集现场图像,然后采用深度学习算法对目标进行检测。基于深度学习的目标检测经历了从R-CNN到Faster R-CNN的不断改进[11-13]:张明媛等[7]基于TensorFlow框架搭建Faster R-CNN模型,识别未佩戴安全帽行为的mAP达到88.32%;徐守坤等[8]在原始Faster R-CNN上运用多尺度训练和增加锚点数量,引入在线困难样本挖掘策略,采用多部件结合方法剔除误检目标,mAP达到91.42%。尽管Faster R-CNN检测精度很高,但计算速度略慢,不能满足实时监测的需求。2016年,Redmon等[14]提出了YOLO模型,虽然精度达不到最优,但速度更快更适用于实时检测,刘君等[9]在YOLO模型上融合了RPN和R-FCN[15]的思想,mAP达到93.42%,fps达到20.659。之后,Redmon等基于YOLO又提出了性能更好的YOLOv2[16]、YOLOv3[17],施辉等[10]运用K-means算法对先验框参数聚类,然后对YOLOv3预测层进行了修改,将mAP提升到92.13%,fps达到62,取得了不错的效果,但是,该工作仅对是否佩戴安全帽进行判断,而未根据安全帽的颜色区分人员类别。此外,现有对于作业现场安全防护用品穿戴的研究大多集中于安全帽检测,缺少工作制服穿着情况检测技术的研究。
针对电力作业现场的特点和对于安全防护用品穿戴检测的细致要求,本文选取目前性能最优、速度最快的YOLOv3算法与自注意力机制相结合,提出一种针对电力作业违规穿戴的目标检测模型,在YOLOv3原有架构中结合DANet的思想,以学习网络空间和通道之间的相互关系(包括相对位置关系和图像特征关系),显著提高了目标检测效果。
1 安全防护用品穿戴检测模型设计
1.1 基础网络选取
YOLOv3是由Redmon等基于YOLO、YOLOv2提出的目标检测算法。YOLO(You Only Look Once)系列只需要一次端到端计算即可检测出目标,具有结构轻量、运算速度快的特点,适用于实时目标检测。下面对YOLOv3进行详细介绍。
1.1.1 特征提取网络Darknet-53
笔者借鉴残差网络(ResNet)[18]的思想设计了新的网络Darknet-53,作为YOLOv3的特征提取网络。相较于YOLOv2的Darknet-19,Darknet-53加深了网络,用卷积代替池化,可以提取更高级的图像特征。图1为Darknet-53的网络结构,虚线框表示模块内容,左边数字代表残差模块的重复次数。
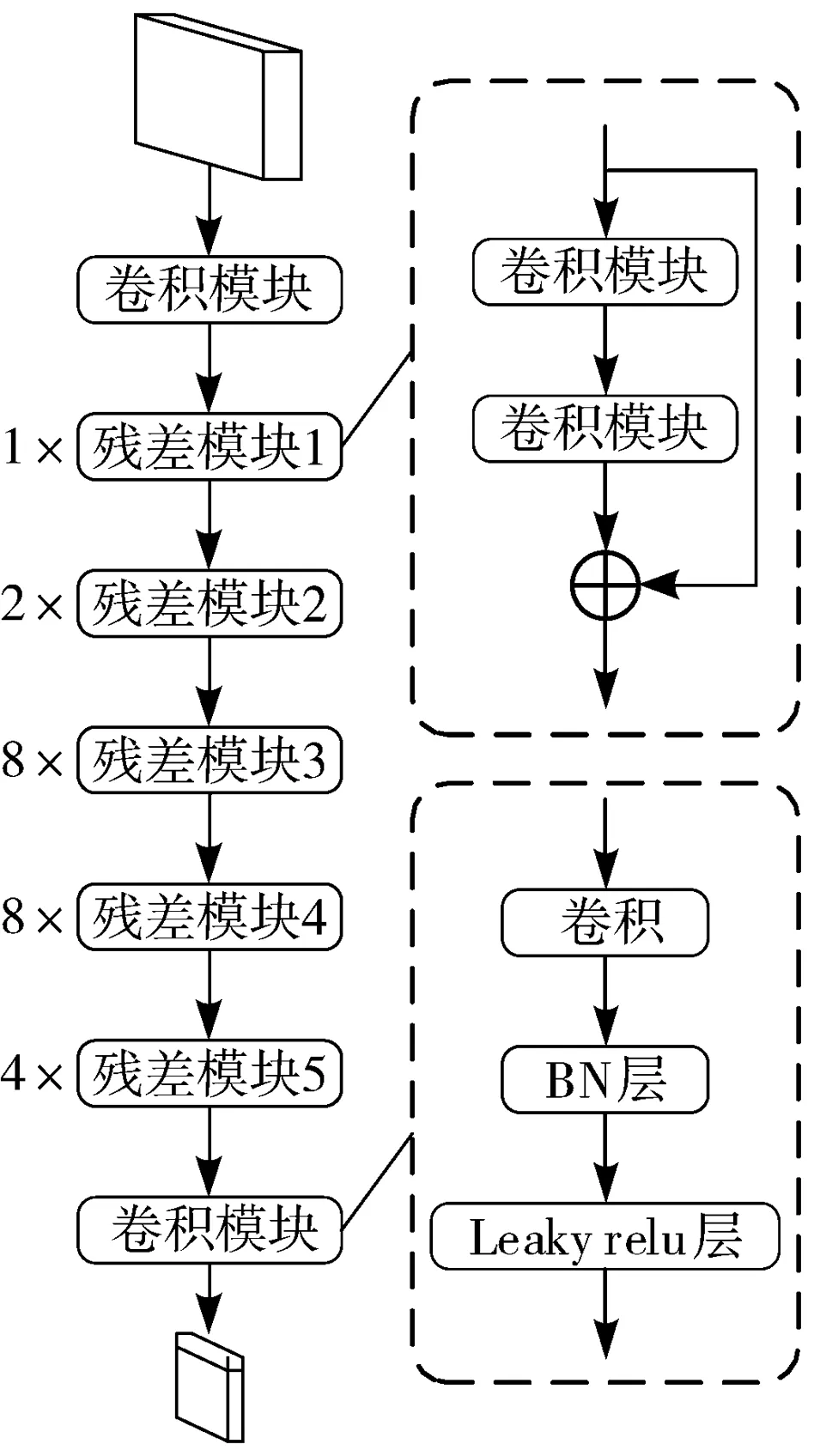
图1 Darknet-53网络结构
1.1.2 特征金字塔多尺度融合
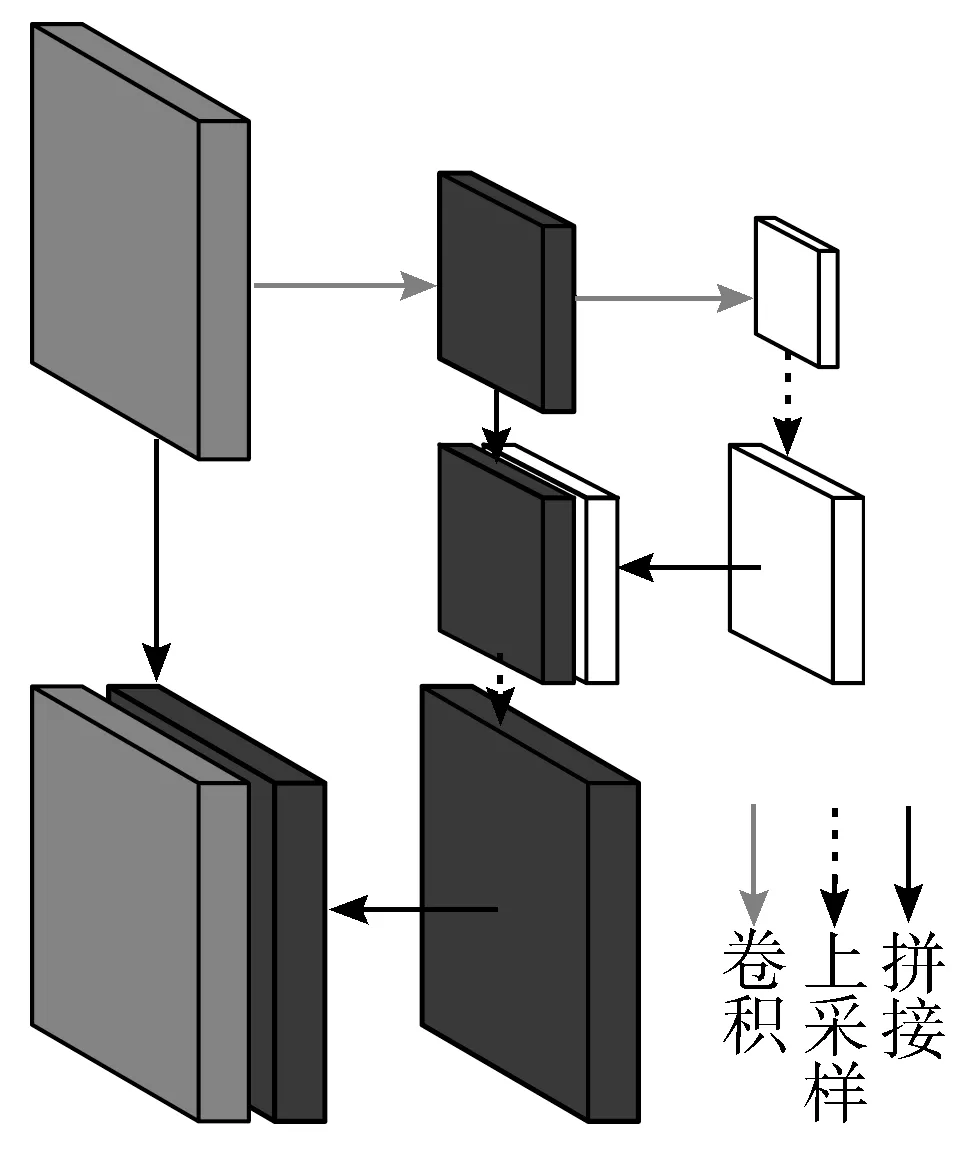
图2 多尺度特征融合
为了提高对多尺度目标的检测效果,YOLOv3借鉴了FPN[19]的思想,采用多尺度特征图进行检测。YOLOv3输出小、中、大3个尺寸的特征图,分别为13×13、26×26、52×52,对应的感受野为大、中、小,即在该尺寸特征图能检测到的目标大小,较低层次特征图尺寸较大,可以捕捉局部细节,适用于检测小目标;高层次特征图尺寸较小,聚合了全局信息,适用于检测大目标。融合过程如图2所示,将小尺寸的特征图上采样至中等尺寸,与中等尺寸特征图拼接,拼接特征图与原中等尺寸特征图相比,融合了更高层次的语义特征。同理,其它层次也依次进行操作。
1.1.3 边界框预测方法
不同于Faster R-CNN采用的RPN筛选候选框方式,YOLOv3直接将图片划分成N×N个网格,在每个网格上预测目标边界框的中心点坐标、长宽、目标类别,既显著提升了计算速度又保证了较好的预测效果。预测边界框的方式为:先采用K-means聚类,在需要预测的数据集上计算出现频率最高的k种边界框大小,由于大、中、小3个尺寸特征图的网格分别设置了3个先验框,所以k=3×3=9。网络的输出不直接输出预测框的坐标、大小,而是通过输出结果结合偏移量计算出最终结果,计算公式为:
(1)
式中,tx、ty、tw、th为每个网格一个预测框的输出结果,cx、cy表示该网格在所处特征图的坐标,pw、ph表示先验框的大小(事先聚类的参数),bx、by为预测框的中心坐标,bw、bh为预测框的长宽。
1.2 自注意力机制
注意力(Attention)机制由Mnih等[20]提出,最初应用于自然语言处理(NLP)领域[21],对语言序列进行加权变换,带来了巨大的提升。注意力机制模拟人类在实际处理信息时的注意力分配情况,可以强调关注的部分,忽略不重要的部分。该机制随后被引入视觉图像处理中。随后Vaswani等[22]提出了自注意力(Self-Attention)机制,并被各领域广泛应用[23-26],Wang等[23]提出Non-local神经网络,捕获全局像素之间的依赖关系,作为特征的加权,Woo等[25]提出CBAM模块,结合空间注意力和通道注意力,比仅使用其中一种注意力取得了更好的效果。
受Non-local和CBAM启发,Fu等[27]提出了双重注意力网络(DANet),首先考虑了特征图中所有位置的相互关系,其次考虑了空间信息和通道信息的共同贡献。此外,该模块不同于CBAM中用全局池化提取注意力权重的方法,而是利用每个位置的空间信息对通道信息建模。DANet的网络结构如图3所示。
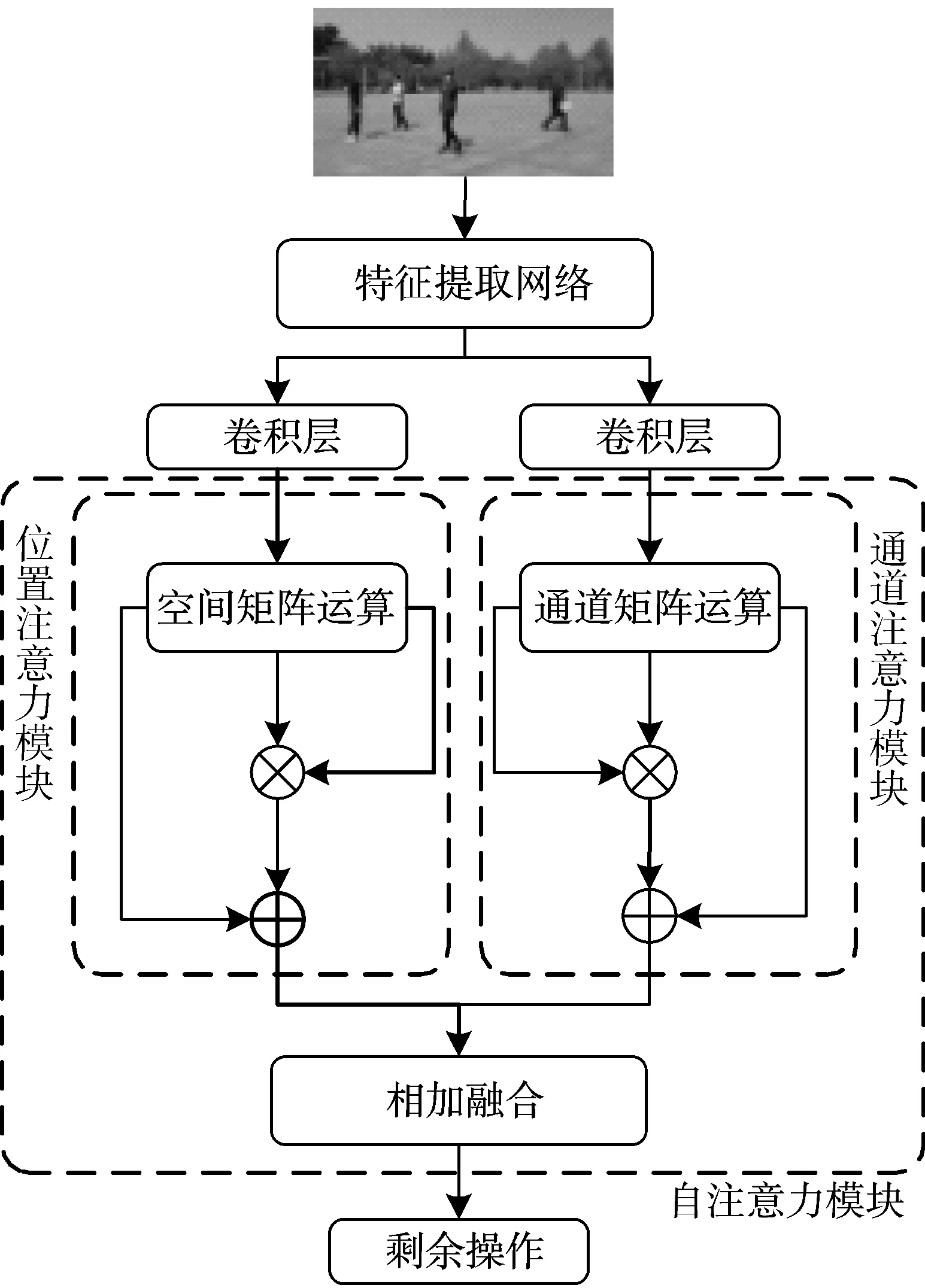
图3 DANet结构
首先,输入图像通过特征提取网络获取特征图,将特征图分别进行卷积操作后获取相同维度特征图,然后放入自注意力模块。自注意力模块分为位置注意力模块和通道注意力模块,分别用于获取特征图的各元素之间的关系特征和各通道之间的关系特征。进一步,借鉴Non-local方法,将关系特征与原有特征进行相加。最后将位置注意力模块和通道注意力模块的输出相加融合,此时输出的特征图挖掘了原本特征图中各位置和各通道之间隐藏的依赖关系,更有助于语义特征的表达。
1.2.1 位置注意力模块
位置注意力模块的架构如图4所示。
Step1将特征图ARC×H×W分别进行卷积得到同样维度的特征图B、C、D({B,C,D}RC×H×W),进一步将B、C、D进行reshape操作转化为维度RC×N(N=H×W,即A中像素的数量)。
Step2将reshape后的B的转置(RN×C)与reshape后的C进行矩阵相乘,并进行Softmax计算,得到空间注意力特征矩阵SRN×N,计算公式如下:
(2)
式中,sji代表着特征图A中第i个像素对第j个像素的影响,即在空间上特征图A任意2个位置之间的相互关系。
Step3将reshape后的矩阵D(RC×N)与矩阵S的转置相乘,将计算结果(RC×N)reshape回到特征图A原本的维度(RC×H×W)。
Step4将Step3的结果与一个尺度参数α相乘,并与特征图A进行逐位求和(element-wise sum)计算,获得结果ERC×H×W,计算公式如下:
(3)
式中α为学习权重,初始值为0,由模型学习获得。Ej为第j个位置的加权位置特征与原始特征之和,其结合了全局上下文的影响,又能通过学习权重和空间注意力特征有选择地聚合特征。

图4 位置注意力模块
1.2.2 通道注意力模块
在高层次特征中,特征的每个通道包含着一定的对应于某些类的信息,则可以将通道间的关系看做类间关系。通道注意力模块对通道关系建模挖掘类间依赖关系,并加强这种相互依赖关系的表达,以提高语义特征表示。
通道注意力模块的架构如图5所示,与位置注意力模块相似但稍有不同,第一步中特征图ARC×H×W直接进行reshape和转置,经过相似操作得到通道注意力特征矩阵XRC×C,计算公式如下:
(4)
式中,xji代表着特征图A中第i个通道对第j个通道的影响,即在特征图A中任意2个通道之间的相互关系。
通道注意力模块最终输出结果E∈RC×H×W,计算公式如下:
(5)
式中,β为学习权重,初始值为0,由模型学习获得。Ej为第j个通道的加权通道特征与原始特征之和,其汇聚了通道之间的依赖关系,并通过学习权重和通道注意力特征有选择地聚合特征。
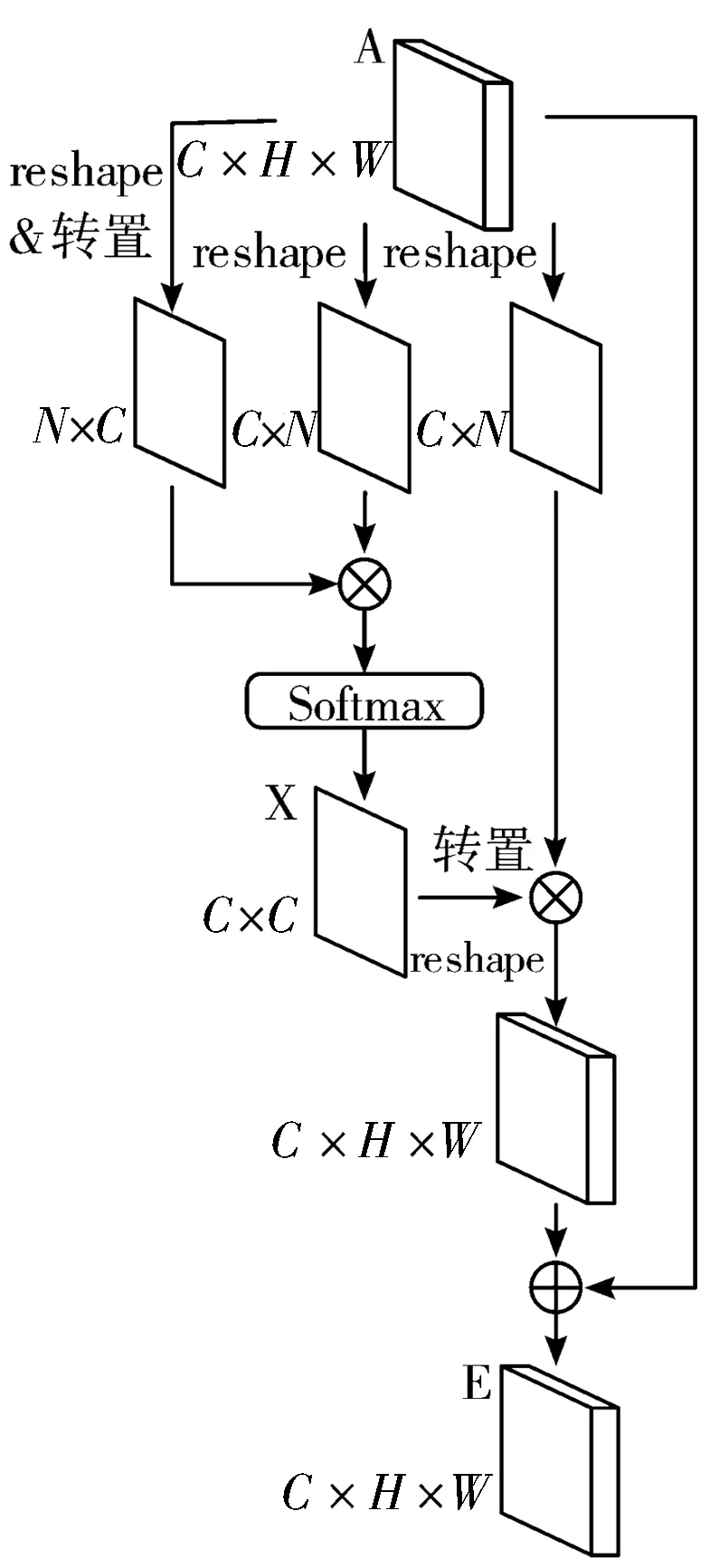
图5 通道注意力模块
1.3 引入自注意力机制的模型架构
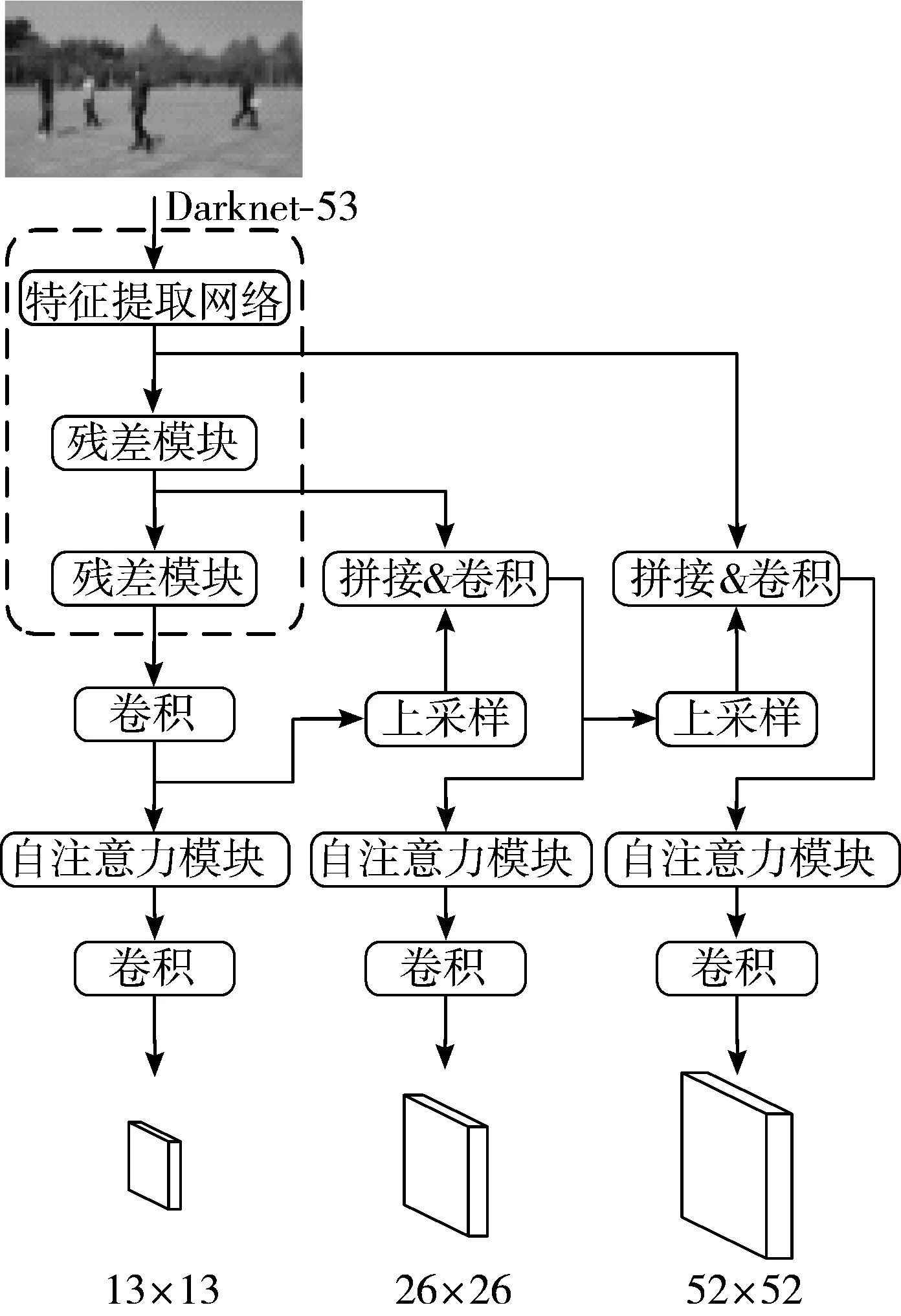
图6 引入自注意力机制的模型架构
YOLOv3模型中未对注意力机制加以研究,对所有位置和通道分配了同等的重要性,为了提高检测效果,本文在实时检测模型YOLOv3中引入注意力机制,在较高层次的特征层后嵌入DANet的自注意力模块。需要注意的是,使用自注意力模块没有增加太多的参数,但是有效地增强了特征的表达[27]。嵌入自注意力模块的YOLOv3架构如图6所示。首先,分别在DarkNet-53网络的倒数第二个残差模块之前、倒数第一个残差模块之后和最后的卷积操作之后保存该阶段输出的特征图。然后,把感受野最大即尺寸最小的特征图进行2倍上采样,与中等尺寸的特征图拼接;将拼接后的中等尺寸特征图卷积后进行2倍上采样,与大尺寸特征图拼接后再次卷积。本文在YOLOv3模型的3个尺度特征图进行最后的一系列卷积操作前,嵌入自注意力模块。由于该阶段的特征图已经具备了高级语义特征,并融合了来自更高层次上采样的语义信息,很适合作为自注意力模块的输入。为了对该选择进行验证,在实验中分别将自注意力模块嵌入上采样操作前、拼接操作前与当前方案进行对比,对比结果在2.2节中详述。最后,3个自注意力模块的输出再经过一系列卷积操作,分别输出大目标特征图(R13×13)、中等目标特征图(R26×26),小目标特征图(R52×52)。最终的特征图经过非极大值抑制(NMS)运算去除重复候选框,得到最终预测结果。
2 模型训练与结果分析
2.1 数据集准备
电力作业现场大多处于郊区户外,作业时间从清晨至夜间不固定,光线变化较大,加之现场存在许多大型电气设备,作业人员可能时而处于阳光曝晒处,时而处于背阴处,导致摄像头采集的图像明暗效果差异较大。人员佩戴的安全防护设备种类也有规定细则,依据国家电网、南方电网的作业标准[28-29],安全帽的分类如表2所示。
表2 电力作业现场安全帽分类

安全帽颜色类型红色生产管理部门黄色运行或巡检人员蓝色检修维护人员白色领导或外来参观人员
表3 标签类别
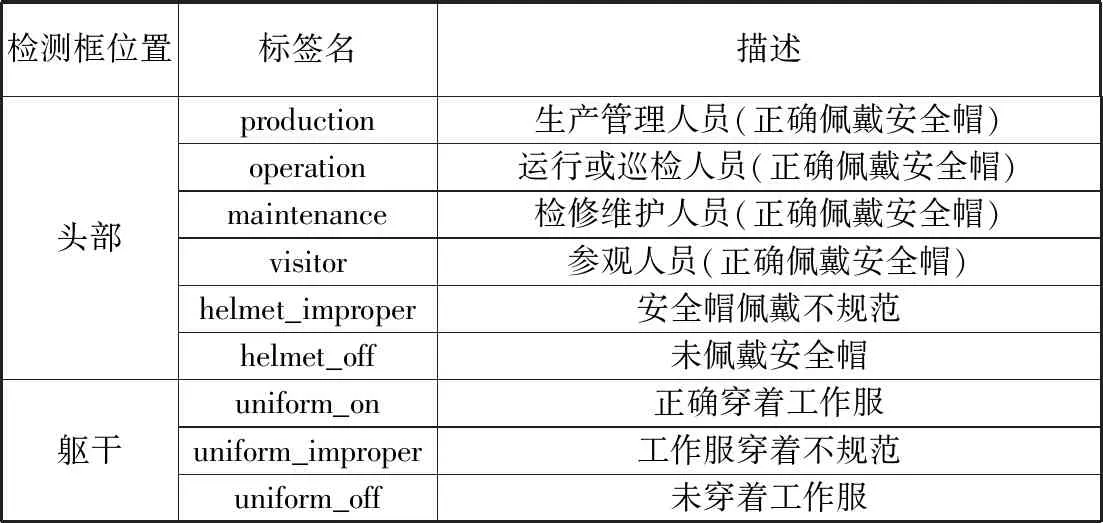
检测框位置标签名描述头部production生产管理人员(正确佩戴安全帽)operation运行或巡检人员(正确佩戴安全帽)maintenance检修维护人员(正确佩戴安全帽)visitor参观人员(正确佩戴安全帽)helmet_improper安全帽佩戴不规范helmet_off未佩戴安全帽躯干uniform_on正确穿着工作服uniform_improper工作服穿着不规范uniform_off未穿着工作服
并且,安全帽佩戴时的标准方式为:将帽带扣在颚下并系紧,可以有效防止安全帽滑落。此外,现场作业人员的工作制服分为着装整齐和着装违规(包括没有穿着制服和上身制服敞开等情况)。摄像头某个时刻拍摄到的作业人员也分为正面、侧面、背面等多个角度和站立、蹲下、行走等姿势。实验数据主要来自于某电力作业现场采集的图像,其中违规情况占比较小,为使实验结果更准确,笔者针对违规情况自主拍摄了一些图像以扩充数据集,保证每种互斥情况数量大致等比。使用VOC格式标注工具labelImg对筛选后的图像进行标注,给需要检测的位置加上检测框,并选择相应的类别标签(见表3)。最后将数据集按8:2比例划分为训练集和测试集,分别用于模型训练和性能验证。
2.2 实验环境与参数
本文实验硬件配置如表4所示,在此基础上安装操作系统Ubuntu 16.04,开发框架CUDA、OPENCV等。
表4 硬件配置
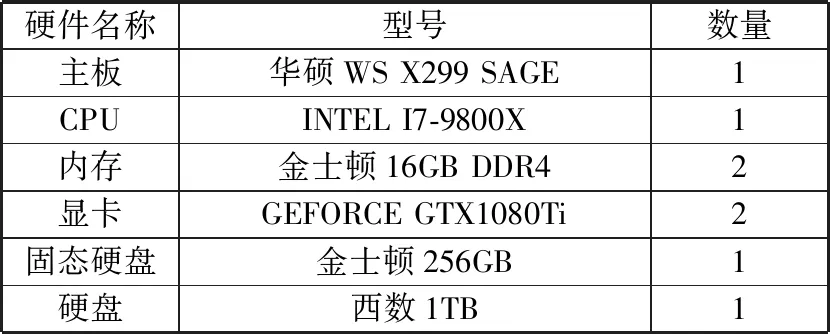
硬件名称型号数量主板华硕WS X299 SAGE1CPUINTEL I7-9800X1内存金士顿16GB DDR42显卡GEFORCE GTX1080Ti2固态硬盘金士顿256GB1硬盘西数1TB1
参考算法官方推荐参数取值并结合实际情况作出适当调整后,设置的实验参数如表5所示,其中卷积核数量为3×(标签类别数目+5)。
表5 实验参数
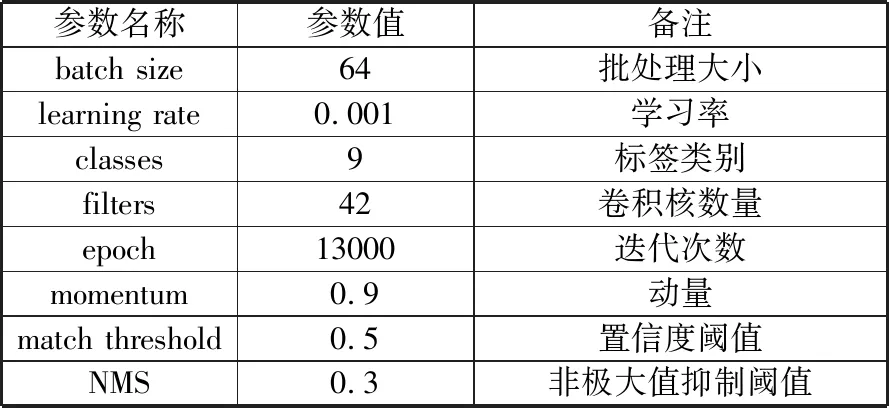
参数名称参数值备注batch size64批处理大小learning rate0.001学习率classes9标签类别filters42卷积核数量epoch13000迭代次数momentum0.9动量match threshold0.5置信度阈值NMS0.3非极大值抑制阈值
依照K-means方法,对标注完成的数据集进行聚类操作,参数k=9,为大、中、小3个尺度的特征图中每个网格设置3个先验框尺寸,作为预测框的计算基准。聚类结果如表6所示。
表6 先验框聚类结果
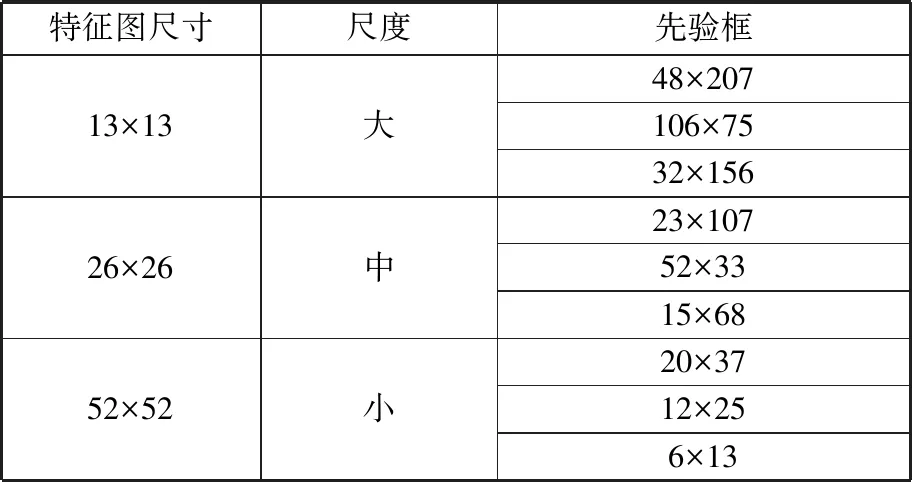
特征图尺寸尺度先验框13×13大48×207106×7532×15626×26中23×10752×3315×6852×52小20×3712×256×13
2.3 训练结果与对比
本文对自注意力模块嵌入YOLOv3中不同位置的模型架构进行了实验,并联合改进前的YOLOv3模型进行纵向比较。其中,把在上采样操作之前嵌入自注意力模块的架构称为Attention-YOLOv3-a(以下简称模型A),把在拼接操作之前嵌入自注意力模块的架构称为Attention-YOLOv3-b(以下简称模型B),把在最后一系列卷积操作之前嵌入自注意力模块的架构称为Attention-YOLOv3-c(以下简称模型C)。各模型使用上文准备的训练集训练5000代后逐渐收敛,使用测试集验证,精度对比如表7所示(正确佩戴安全帽在实际训练中分为4种标签,在这里取平均值作为AP),查全率(Recall)和fps对比如表8所示。
表7 精度对比

模型mAP/%AP/%未佩戴安全帽安全帽佩戴不规范正确佩戴安全帽未穿着工作服工作服穿着不规范正确穿着工作服YOLOv381.9290.5670.5672.7796.2971.5289.82Attention-YOLOv3-a88.6192.6184.2680.9596.3386.4291.09Attention-YOLOv3-b90.8993.1789.9587.5496.3686.9491.35Attention-YOLOv3-c94.5897.4393.6495.1398.8689.6292.81
表8 查全率和fps对比
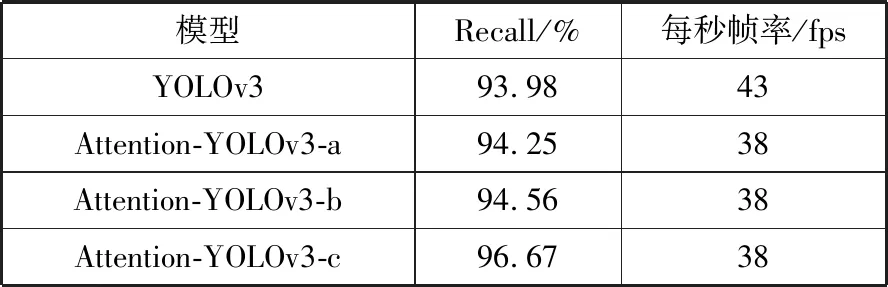
模型Recall/%每秒帧率/fpsYOLOv393.9843Attention-YOLOv3-a94.2538Attention-YOLOv3-b94.5638Attention-YOLOv3-c96.6738
从表8看出,由于引入了自注意力模块,模型A、B、C的平均精度均值(mAP)和Recall相对改进前的YOLOv3模型均有不同程度的提升。其中模型A、模型B的mAP和Recall相差不大,模型C相对于改进前的YOLOv3模型提高了12.66%的mAP和2.69%的Recall,相对于模型A、B提高了5%左右的mAP和1.6%的Recall,获得了最优结果。并且,引入自注意力模块增加了模型复杂度,模型A、B、C的fps指数均比改进前下降至每秒38帧,但是依然满足实时检测的标准(36 fps)。可以分析得出,由于模型C嵌入自注意力模块的位置处于网络的较高层次且作为输入的特征图融合了上采样的高层特征,此时自注意力模块的输入聚合了较具体的语义和空间信息,更有利于自注意力模块挖掘位置和通道间的依赖关系,使输出特征更为有意义。
本研究的主要任务是识别出未佩戴安全帽、安全帽佩戴不规范、未穿着工作服、工作服穿着不规范4类情况,通过观察模型改进前后这4类的P-R曲线(图7),可以看出:未佩戴安全帽(图7(a))、未穿着工作服(图7(c))在原来的基础上进一步提升了检测效果;安全帽佩戴不规范(图7(b))、工作服穿着不规范(图7(d))原本的曲线呈现快速下降趋势,效果不理想,改进后,查准率(Precision)在查全率(Recall)较高时才出现明显的下降趋势并保持在一定区间内。
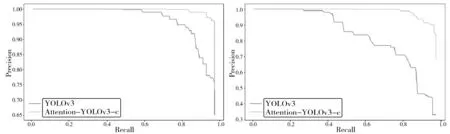
(a) 未佩戴安全帽 (b) 安全帽佩戴不规范
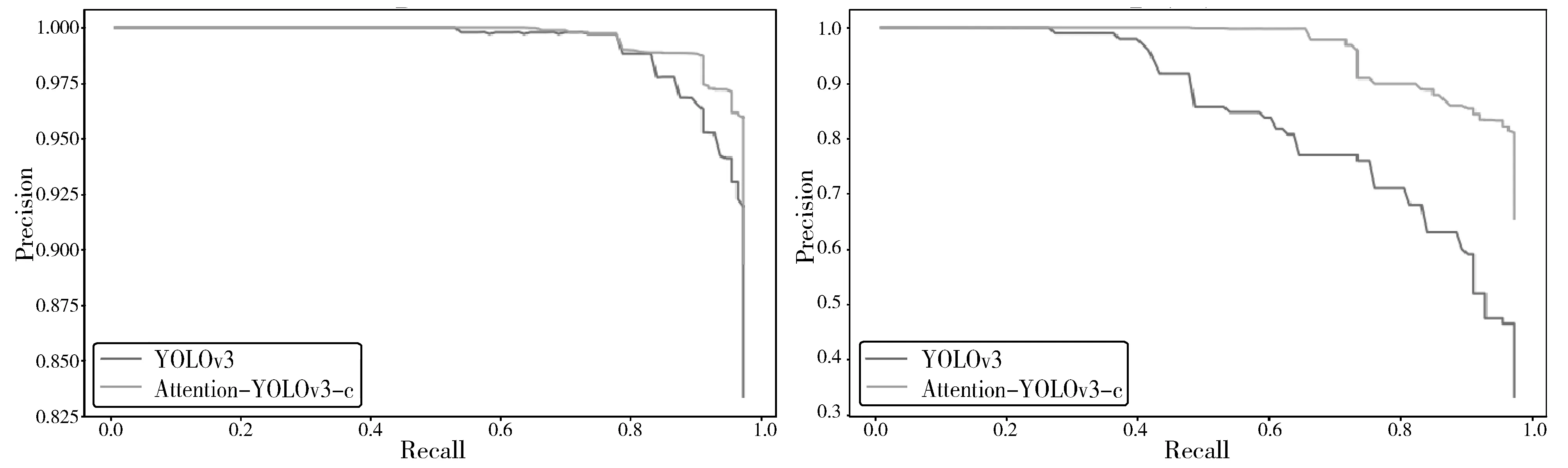
(c) 未穿着工作服 (d) 工作服穿着不规范
并且,由于安全帽佩戴不规范和正确佩戴安全帽、工作服穿着不规范和正确穿着工作服之间存在外观上的相似,在YOLOv3上这4类的AP都不高。引入自注意力模块后,这4类的AP大幅提升,可以推断,自注意力模块有效地强调了类内一致和类间不一致。网络改进前后检测结果对比如图8所示,图8(a)为待预测原图,图8(b)为YOLOv3原始网络预测结果。可以看到,图8(b)第一张示例中,右二人员正确佩戴安全帽,工作服穿着不规范,却因帽带被手部分遮挡,被判定为安全帽佩戴不规范,工作服穿着情况也被误判为没有穿着工作服;右一人员并未身着工作服,由于衣着整体色调与工作制服色调相似且包含较大白色区域,被误判为着装不规范。图8(c)为引入自注意力机制的YOLOv3网络预测结果,将图8(b)中误判的类别正确地预测了出来,预测框对目标的定位和覆盖精准度也有明显提升。

(a)原图

(b) YOLOv3原始网络预测结果

(c) 引入自注意力机制的YOLOv3网络预测结果
3 结束语
为了保证电力作业的安全稳定运行,电力系统要求现场人员必须正确穿戴防护用品,以保证其人身安全。但是因为种种原因,经常出现一些违规穿戴的情况,为此本文提出了一种人工智能监测现场人员违规穿戴的方法。该方法结合了实时深度检测网络YOLOv3和Self-Attention机制,Self-Attention借鉴了DANet的位置注意力和通道注意力,能够更好地挖掘目标隐含特征,学习类间和类内依赖关系,区分相似类型目标,同时,该注意力模块增加的参数量较少,与YOLOv3算法相比,该方法在检测速度基本持平的情况下大幅改善了任务性能,具有较好的查准率和查全率,不仅可以满足违规穿戴检测任务要求,而且为电力作业安全稳定进行提供了保障,具有较好的应用前景。在之后的研究中,将进一步研究模型精度和速度的提升,同时探寻变电站、输电线路等其他电力场景的目标检测应用方向。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
机电安全(2018年3期)2019-01-29 05:22:44
消防界(电子版)(2018年6期)2018-02-18 17:31:57
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
环球市场(2016年35期)2016-03-16 03:31:32
化工管理(2014年12期)2014-08-15 00:51:32
华东理工大学学报(自然科学版)(2014年3期)2014-02-27 13:49:03
