
基于多层次动态门控推理网络的文本蕴含识别
2020-04-01 03:08:20杨煦晨琚生根刘宁宁谢正文王婧妍
四川大学学报(自然科学版) 2020年2期
张 芮, 杨煦晨, 琚生根, 刘宁宁, 谢正文, 王婧妍
(四川大学计算机学院, 成都 610065)
1 引 言
自然语言推理(Nature Language Inference,NLI)任务是自然语言处理的一个重要子任务,能否推理出两段文本之间的关系是机器进一步理解自然语言的基础.自然语言推理又被称为文本蕴含识别(Recognizing Textual Entailment,RTE),是指给定两段文本P和H,其中P为前提(Premise);H为假设(Hypothesis),若能从前提P的内容中推断出假设H的内容,则称P和H为蕴含关系,否则为非蕴含关系,非蕴含关系可进一步划分为中立关系(P和H的事实无关)和矛盾关系(P和H内容矛盾).文本蕴含技术是关系抽取、机器阅读理解[1]、对话问答和文本摘要等任务的技术基础,运用文本蕴含技术可进一步提高这些任务的精度.
早期文本蕴含研究通过手工构建大量文本特征[2-3]来判断文本蕴含关系.而随着深度学习理论的完善和连续语义空间向量[4]表达能力的提升,基于神经网络的方法及序列优化模型[5]被广泛用于各个领域[6-7].目前基于神经网络的文本蕴含研究方法主要有两大类:(1)基于文本编码模型[8-9];(2)基于交互聚合网络[10].基于文本编码模型旨在得到一个更优的句子表示,基于交互聚合模型则是构建文本对交互特征用于文本关系分类.现有的交互聚合模型通常基于一次词级注意力得到文本交互特征并用于关系判断,但通过一次词级交互往往不能很好地捕捉到文本对的关系.原因包括:(1)仅通过一次词级注意力捕捉到的文本对信息有限;(2)词级交互重点捕捉局部词关系,当文本对包含多个相同词时,局部相似词对于文本关系的判断影响较大.
基于上述分析,本文作了如下工作:(1) 提出句子门控推理结构(Sentence Gated Match LSTM,sgMatch-LSTM),该结构结合了次级别局部交互和句子级别门控机制来动态推理前提和假设文本关系;(2) 基于sgMatch-LSTM结构提出多层次动态门控推理网络(Multi-level Dynamic Gated Inference Network,MDGIN),该网络基于sgMatch-LSTM结构并采用不同注意力交互方式构建文本不同层面的特征,提升了模型对两段文本语义信息的理解.
2 相关工作
早期的文本蕴含研究大多采用特征工程方法,通过相似度特征[11]、逻辑演算[12]、基于转换[13]等方式,构建各种特征来判断文本的蕴含关系.随着斯坦福在2015年发布大规模文本蕴含语料(Stanford Nature Language Inference,SNLI)[14],拉开了基于神经网络的文本蕴含技术新篇章.
基于文本编码的模型是通过训练一个句子级别编码网络,来分别编码前提和假设文本,并将表示向量连接后用于两段文本的关系分类.文本编码模型的编码器则可通过LSTM、CNN、注意力机制[15-16]等构造.这种方式可有效提升句子语义表示,但缺少了文本之间的交互,而对于文本蕴含任务来说,交互特征对蕴含关系的识别十分重要.
基于交互聚合网络则是采用注意力机制对前提和假设文本进行交互.Parikh等人[17]提出Decomp-Attention模型和Chen等人[10]提出ESIM模型均通过计算一次静态词级注意力矩阵来提取前提和假设的交互特征,并将交互特征聚合用于分类.这样存在的问题是如果前一层的文本表示稍有偏颇,则会影响局部注意力矩阵的结果,进而得到不准确的交互信息;Rocktäschel等人[18],Cheng等人[19],Wang等人[20],采用动态匹配的思想对前提和假设文本进行迭代推理,每一步的词级交互基于上一步的结果在动态变化,一定程度上缓解了静态词级矩阵的缺陷.上述模型都是基于词级语义进行匹配推理,虽然词级信息可以很好地关注到文本的细节,但是针对某些文本,比如4.4.2节中表4中的样例3,前提和假设文本中均包含多个相同词“Angiosperms”,“phylum”,“plants”,导致模型在基于词进行推理时很容易将其判断为蕴含关系,但是实际文本关系为非蕴含.因此,本文在词级别动态推理基础上引入了句子级别语义门控机制用于“修正”词级别推理的局部误差.另外,Wang等人[20]模型均只考虑词级信息的一个层面,本文模型通过不同注意力计算方式来提取文本不同层面的特征.
3 模 型
本文的模型主要由3个部分组成: 文本编码层、多层次动态匹配层和输出层.其中动态匹配层分别基于sgMatch-LSTM结构(简称sgM)计算三个不同层面的文本交互特征,对应图1中sgM1,sgM2,sgM3,并将特征聚合用于分类.图1显示了MDGIN模型整体架构.
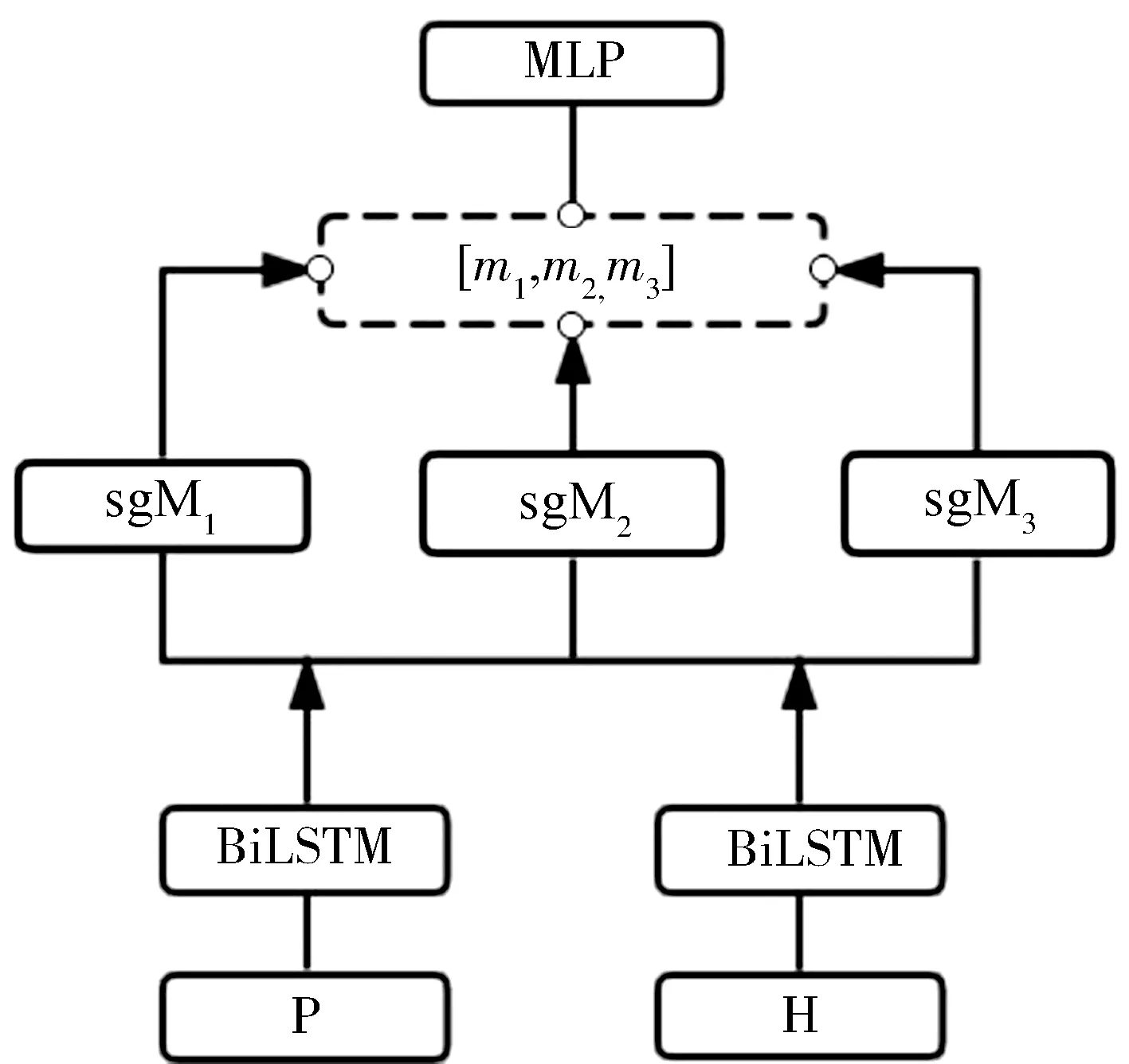
图1 MDGIN模型架构图Fig.1 Model structure of MDGIN
模型输入形式为(P,H,Y),其中P=[p1,p2,…,plp],H=[h1,h2,…,hlh]分别为前提文本序列和假设文本序列,lp为前提文本长度;lh为假设文本长度.Y为真实的类标签.表示p和h之间的蕴含关系,Y∈{Entailment,Neural,Contradiction}.
3.1 文本编码层
本文使用双向LSTM(BiLSTM)网络编码前提和假设的文本向量.
(1)
(2)

3.2 动态匹配层
3.2.1 Match-LSTM模型 Wang等人[20]提出词级别动态推理模型Match-LSTM,本文模型很大程度上受此模型启发.

(3)

(4)
(5)
其中,∂ij为注意力权重,表示前提文本第i个词和假设文本第j个词的对齐权重;Wp,Wh,Wm∈2d×d;wk∈d均为训练参数.
(6)
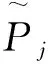
(7)
3.2.2 多层次词级匹配 本文在Match-LSTM基础上分别增加两个不同层面的词级注意力T2和T3,用于提取文本不同层面的特征.
(8)
(9)
其中,Wp,Wh,Wm∈2d×d;wk∈d均和式(4)相同,为模型训练参数.
T2为元素点乘匹配函数,点乘注意力用于重点提取两段文本的相似信息,使模型重点关注文本对相似层面的语义特征.T3为元素相减匹配函数,元素相减操作可以指明推断方向,同时重点捕捉前提和假设文本之间差异信息.相比于原Match-LSTM模型仅对词进行一次交互,本文通过多种注意力方式可提取文本不同层面的特征,提高模型对文本的语义理解.
3.2.3 全局语义门控机制sgMatch-LSTM 虽然通过多层次词级别推理可充分捕捉文本局部特征,但由4.4.2节表4样例3可知,仅从词层面推断,很容易受到文本中局部语义相似但全局语义相反的情况的影响,产生错误的判断.因此本文模型进一步引入句子级别语义作为门控来对词级推理结果进行“修正”.sgMatch-LSTM结构如图2所示.T为词级匹配函数;S为全局语义门控机制,虚线表示hvec作用于每步时序.

图2 sgMatch-LSTM结构Fig.2 The structure of sgMatch-LSTM
函数S用于计算文本对在句子级别的注意力,并通过sigmoid函数映射到(0,1)区间作为门控,用于更新和重新选择词级推理的结果.如果局部词相似,但全局语义相反,通过句子语义门控选择在一定程度上可降低局部相似词的影响,达到“修正”词级别推理的结果.反之亦然.

(10)

(11)
其中,hvec为假设文本句向量,通过自注意力[21]方式得到;sg为句子级别注意力结果;⊙为元素相乘;rj为门控选择后的前提向量表示.S为句子级别匹配函数,对于不同层面的句子语义信息采用不同的计算方式,包括S1,S2,S3三种计算方式.
(12)
其中,Wpv,Whv∈2d×2d;bv∈2d;σ表示sigmoid激活函数.
对于句子级别相似和差异层面特征,分别采用点乘和元素相差两种计算方式.
(13)
(14)
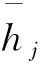
(15)
(16)
3.3 输出层
将3个sgMath-LSTM最后一步时序的推理向量m1,m2,m3拼接得到m向量,m=[m1,m2,m3],m∈6d,采用一层激活函数为tanh的全连接层进行降维,全连接层隐层维度为2d,最后用Softmax函数分类.模型采用交叉熵损失函数.
4 实 验
4.1 数据集和评价指标
本文在SNLI[14]和SCITAIL数据集[22]进行验证.SNLI是由斯坦福在2015年发布的大型文本蕴含数据集,包含3类标签,句式简单而相对固定.而SCITAIL数据集是科学类文本蕴含数据集,根据科学类多选问答任务构造的前提和假设文本,包含2类标签,不受手工规则的限定且句式多样复杂,推理相对困难.两个数据集分布如表1所示.本任务采用的评价指标:准确率(Accuracy).

表1 两个数据集的分布
4.2 实验环境及参数设置
本文模型基于Tensorflow框架搭建,采用ADAM优化器[23]作为整个模型的优化函数,第一个动量系数设为0.9;第二个动量系数设为0.999.学习率为0.0004,batch size为32,dropout[24]比率为0.2,l2正则化在[0,0.0001,0.00001]之间选择最优.模型采用预训练的300维词嵌入,对于词表外的单词,采用高斯分布随机初始化一个300维的向量,所有词向量在整个训练过程中不更新.本文三个sgMatch-LSTM结构共享参数.
4.3 实验结果
本文模型在SCITAIL数据集上运行结果如表2所示.由表2可知,本文模型在SCITAL数据集取得了80.7%的准确率,分别超过Decomp-Attention[17]和ESIM[10]模型8.4%和10.1%.Decomp-Attention和ESIM模型均采用静态词级别注意力矩阵进行文本匹配.但其在较为复杂的SCITAIL数据集上表现效果一般,说明仅用一次静态注意力矩阵的方式并不能很好推理复杂的文本关系.而本文模型采用多层次动态推理方式取得了较好的效果.本模型分别也超过了2018年发布的分解图蕴含模型[22](DEGM)3.4%以及采用对抗训练的AdvEntuRE模型[25]1.7%,验证了本文模型MDGIN的有效性.
本文模型在SNLI数据集上的验证结果如表3所示.DISAN[15]完全基于注意力方式对文本进行编码和交互,LSTMN[19]引入了记忆网络的思想对LSTM进行改进,Word-by-Word Attention[18]和Match-LSTM[20]均是动态词级别推理模型,但仅采用一次词级推理交互,TreeLSTM[9]是基于树结构额外捕捉文本的词法句法信息,DSA[26]是2018年新发布的基于动态词级注意力的编码模型.从实验结果来看,本文模型均优于上述模型.
表2SCITAL数据集验证结果(准确率)
Tab.2Performance(accuracy)onSCITAILdataset

模型验证集/%测试集/%Majority class63.360.3Decomp-Attention75.472.3ESIM70.570.6Ngram65.070.6DEGM79.677.3AdvEntuRE-79.0MDGIN81.780.7
表3SNLI数据集验证结果(准确率)
Tab.3Performance(accuracy)onSNLIdataset

模型训练集/%测试集/%word-by-word attention 85.383.5DISAN91.185.6LSTMN87.485.7TreeLSTM93.186.0Match-LSTM92.086.1Decomp-Attention89.586.3DSA87.386.8MDGIN95.387.2
4.4 结果分析
4.4.1 模型结构分析 本节对模型结构进行详细分析,图3中的结构(a)为仅用LSTM编码的模型,结构(b)为词级动态匹配推理模型,即Match-LSTM,结构(c)为增加句子级别门控推理的模型,结构(d)为多层门控推理网络MDGIN.
由图3可知,基于词级交互模型(b)相较于仅用LSTM编码分别在SCITAIL和SNLI 数据集上准确率提升了3.9%和8.5%,表明了细粒度文本交互对于文本蕴含任务的重要性.结构(c)在词级交互基础上增加了句子级别门控机制,效果进一步提升了1.1%和0.3%,说明句子级别门控“修正”了词级别匹配结果,而采用多层次门控推理网络(d),综合对文本不同层面的推理结果,准确率进一步提升了3.6%和0.8%,说明了对文本不同层面采用不同注意力计算方式可有效加强模型对文本特征的提取,验证了本文模型各部分结构有效性.另外,由图3可以观察到本文模型对于大型SNLI数据集提升较少,而具有小数据量SCITAIL数据集有较大提升,原因是大数据集本身包含信息足够丰富,小数据集在信息缺乏情况下基于本文模型可有效捕捉更准确的语义信息和更全面的文本特征,因此文本关系的判断准确率提升较大.

图3 模型消融折线图Fig.3 Ablation performance of MDGIN

表4 样例结果和分析
4.4.2样例分析 表4给出了一些文本对样例,由样例1和样例2可看到,基于词级别的动态推理倾向于对齐前提和假设中相似的词,当相似词越多,越可能被判定为蕴含关系,反之判定为中立关系.而样例3中两段文本有较多相似词,仅通过词级别语义推理会将其预测为蕴含关系,但本文模型MDGIN引入句子级别语义信息“修正”了局部推理结果.样例4由于句子较长且句式相对复杂,Match-LSTM也错将其预测为中立关系,MDGIN通过多个层面特征判断可正确预测为蕴含关系.
本文提出sgMatch-LSTM结构,通过结合词级别细粒度推理和句子级别门控机制用于动态推理文本蕴含关系,并基于此结构提出多层次动态门控推理网络(MDGIN),分别从三个层面来推理文本的语义关系.本文模型在SNLI数据集和较复杂的SCITAIL数据集上均有不同程度的提升.由于机器阅读理解、问答等任务也需要蕴含推理技术,未来可尝试将多层次动态推理模型应用于机器阅读理解或对话问答等其他相关领域.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
基层中医药(2021年8期)2021-11-02 06:25:02
开放教育研究(2020年2期)2020-03-31 01:54:14
家庭影院技术(2018年5期)2018-06-29 07:42:10
家庭影院技术(2018年3期)2018-05-09 07:06:12
中学生(2017年13期)2017-06-15 12:57:48
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
