
基于深度学习的任意形状场景文字识别
2020-04-01 03:08:18徐富勇盛钟松
四川大学学报(自然科学版) 2020年2期
徐富勇, 余 谅, 盛钟松
(四川大学计算机学院, 成都 610065)
1 引 言
近年来,由于自然场景文字识别在广泛应用中的重要性,其引起了学术界和工业界的广泛关注.很多应用都受益于场景文字的丰富语义信息,比如:交通标志的识别[1-2]、产品识别[3-4]、图片搜索和无人驾驶[5]等.随着场景文字检测方法的发展,场景文字识别也成为当前研究的前沿课题,也是一个开放性和极具挑战性的研究课题.
目前,规则的文字识别[6]取得了显著的成功.基于卷积神经网络的方法[6]得到了广泛的应用.有很多研究方法将递归神经网络[7-8]和注意机制[9-12]结合到识别模型中,并且还取得了很好的效果.然而,目前大多数的识别模型仍然不稳定,无法处理来自环境的多种干扰.不规则文字的各种形状和扭曲模式对识别造成了更大的困难.如图1所示,透视和曲线形状等不规则的场景文字仍然很难识别.

图1 规则和不规则场景文字例子(a) 规则文字;(b)、(c) 不规则文字.Fig.1 Examples of regular and irregular scene text(a) Regular text;(b)~(c) irregular text.
因此,我们提出了一种带有灵活矫正功能的注意力增强网络FRAEN (Flexible Rectification Attention Enhanced Network),它可以识别自然场景中缩放和拉伸的文字.此网络由灵活矫正网络FRN (Flexible Rectification Network)和基于注意力增强的网络AEN (Attention Enhanced Network)的识别网络组成.我们把困难的识别任务分成两部分.首先,FRN作为一种图像空间转换器,对包含任意形状文字的图像进行矫正.如图2所示,经过FRN的矫正,倾斜的文字变得更加水平,更容易识别.紧接着,AEN将矫正后的图像作为输入,直接输出预测的单词.
当前的文字识别网络,那些具有注意力机制的解码器更可能利用经过矫正的图像预测正确的单词.但是Cheng等人[9]发现现有的基于注意力的方法会出现注意力偏移的情况.因此,根据他们所提出方法的启发,我们针对自己的模型,提出了注意力增强的方法来改进和训练AEN.提出了基于相邻注意力权重的双向GRU(Gated Recurrent Unit)解码器.由于注意力增强的作用,AEN对于上下文的变化更加鲁棒.简而言之,本文的主要贡献如下:(1) 本文提出的FRAEN能够很好地处理和识别不规则的场景文字;(2) 本文提出了一种基于注意力增强的解码器方法,本方法可以解决注意力偏移的问题;(3) 本文提出的方法可以以弱监督的方式进行训练,只需要提供文字标签,这样省去了大量的标注工作.
2 相关工作
近年来,由于神经网络的快速发展[13-15],对规则场景文字的识别能力已经大大提高.文献[11]概述了场景文字检测和识别领域的主要进展.由神经网络提取的模式特征相比于手工制作的特征变得占主导地位,例如Semi-Markov条件随机场和生成形状模型.Jaderberg等人[16]和Yin等人[17]使用卷积神经网络CNNs(Convolutional Neural Networks),提出了无约束识别的各种方法.
随着递归神经网络RNN(Recurrent NeuralNetwork)的广泛应用,基于CNN(Convolutional Neural Network)与RNN结合的方法可以更好地学习上下文信息.Shi等人[18]提出了一个具有CNN和RNN的端到端可训练网络,称为CRNN(Convolutional Recurrent Neural Network).此外,注意力机制侧重于信息区域以实现更好的性能.文献[11]提出了一种基于注意力机制的递归网络,用于场景文字识别.Cheng等人[9]使用聚焦注意网络来纠正注意力机制的变化,实现更准确的注意力位置预测.
与规则场景文字识别工作相比,不规则文字识别更加困难.一种不规则的文字识别方法是自底向上的方法[12],它搜索每个字符的位置然后连接它们.另一种是自顶向下的方法[8]直接从整个输入图像识别文本,而不是检测和识别单个字符.我们提出的FRAEN方法采用的是自顶向下的方法.注意力增强方法被用于提高FRAEN注意力的准确度.我们使用端到端的方式训练FRAEN,可以使得文字矫正网络和文字识别网络很好的结合.
3 方 法
FRAEN包含两部分,FRAEN的整体架构图如图2所示.第一部分是FRN,在本部分,由于目前提出的矫正网络都仅仅矫正水平方向,在本文中,我们加入一个由基本CNN构成的方向标准化网络,将垂直方向的文字转为水平方向文字,统一进行图像矫正,FRN网络的作用是学习图像每个部分的偏移量,根据学习的偏移量,我们通过双线性插值采样获得矫正后的文字图像;另一部分是AEN,由带有注意力增强解码器的CNN-BLSTM(Bi-directional Long Short-Term Memory)-GRU架构构成.直接处理和识别矫正后的图像,输出预测结果.
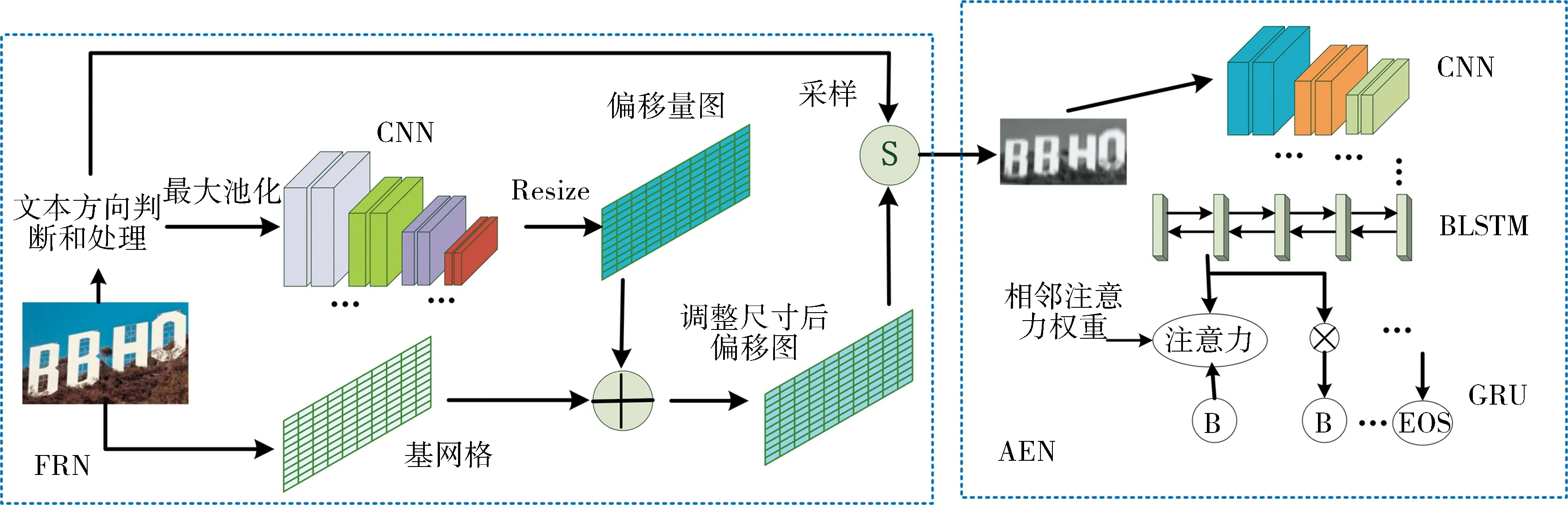
图2 FRAEN整体架构 Fig.2 Overall structure of FRAEN
3.1 FRN
常用的模式矫正方法,如仿射变换网络,其受到一定的几何约束,仅限于旋转,缩放和平移.然而,一个图像可能有多种变形,尤其自然场景文字的变形更是复杂多变的.由于识别模型对各种形状的多扰动处理能力不强.所以,我们考虑对图像进行矫正以降低识别的难度.如图2所示,FRN架构首先对传入网络的图像进行一个二分类判断,只判断图像中文字是否为垂直方向,并进行旋转处理,将处理后的图像传入由CNN构成的矫正网络,进行文字矫正处理.我们将一个最大池化层放在矫正网络之前,这样可以避免噪声和减少计算量.

表1 FRN架构
FRN架构如表1所示.在我们实现此网络时,除最后一个卷积层外,每个卷积层后面都有一个批处理归一化层和一个ReLU(Rectified Linear Unit)层.由表1可以看出,首先,FRN将图像分割为3×11=33个部分,预测每个部分的偏移量,输入大小为32×100,得到的偏移量图包含两个部分,分别代表原图像素在x坐标和y坐标方向的偏移量;然后,我们使用双线性插值平滑地调整偏移量图,使其与输入图像大小相同都为32×100.
偏移量图中的每个值表示原图原始位置的偏移量,因此我们先为输入图像生成一个基网格来表示像素的原始位置,该基网格使用x和y坐标表示输入图像像素的位置.将每个像素的坐标归一化至[-1,1].左上角像素的坐标为(-1,-1),右下角的坐标为(1,1).最后,将基网格和得到的偏移量图以如下方式进行求和.
offset′(c,i,j)=offset(c,i,j)+
basic(c,i,j),c=1,2
(1)
公式(1)中,(i,j)代表网格第i行和第j列的位置.c=1,2分别代表x坐标和y坐标.对于偏移量图而言,对应的是需要对原图x和y坐标位置的像素进行调整的偏移量.而对于基网格则是输入图像像素位置的x和y坐标.
采样前,偏移量图上的x坐标和y坐标分别归一化到[0,W]和[0,H].这里,H×W是输入图像的大小.矫正后的图像I’的第i行和第j列的像素值由以下公式得到:
I′(i,j)=I(i′,j′)
(2)

(3)
其中,I是输入图像;i′和j′分别对应于式(1)中c=1和2的取值.这里得到的i’和j’都是实数,而不是整数,因此,经过矫正的图像I’,是我们采用双线性插值方法从图像I中采样得到.由于式(2)是可微的,FRN可以进行梯度反向传播训练.
如图3所示,左边显示未进行矫正处理的不规则文本图像,右边显示的是经过FRN矫正处理后的文本图像.从图3可以看出,经过校正的图像中的文本更规则和更具可读性,倾斜和透视的文本经过矫正后变得紧密结合,弯曲文本也变得更规则.

图3 FRN矫正不规则文字的结果Fig.3 Results of the FRN on irregular text.
3.2 AEN
如图2所示,AEN的主要结构是CNN-BLSTM-GRU框架.编码器部分我们采用的是CNN-BLSTM架构.目前方法的解码器是基于GRU直接生成目标序列(y1,y2,…,yT).解码器生成的最大步数为T.解码器在预测到序列结束标记EOS时停止处理.在时间步t,输出yt如下.
yt=Softmax(Woutst+bout)
(4)
式(4)中,st是时间第t步隐藏层状态,我们使用GRU来更新st,由如下公式计算更新.
st=GRU(yprev,gt,st-1)
(5)
式(5)中,yprev代表的是前一个时间段的输出yt-1的嵌入向量;gt代表注意力权重向量.
yprev=Embedding(yt-1)
(6)
(7)
式(7)中,hi代表的是序列特征向量;L是特征图的长度.而第一项αt,i是注意力权重向量,计算如下.
(8)
et,i=Tanh(Wsst-1+Whhi+b)
(9)
在式(4)~式(9)中,Wout,bout,Ws,Wh和b都是可训练的参数.注意:在训练阶段yprev是来自最后一步的真实标记.然而,在测试阶段使用最后一步的预测输出作为yt-1.本文解码器是基于注意力增强的解码器,借鉴文献[5]的思想,本文提出了相邻注意力权重和双向GRU解码器方法,在3.3节和3.4节详细说明.AEN的架构详细信息见表2.编码器部分采用了45层的残差网络结构作为卷积神经网络,每个残差单元都由一个1×1的卷积层伴随一个3×3的卷积层组成.在第1个和第2个残差块中,图像被2×2步长的卷积层所降采样.而在最后的三个残差块中,降采样步长变为2×1,这样能够更好地区分宽度较窄的字母.卷积神经网络之后是两层的双向LSTM网络,其中的每一层都由一对LSTM网络组成,LSTM的隐藏层单元数量均为256.解码器是带有注意力机制的GRU网络,注意力机制的单元数和隐藏层单元数均为256.

表2 AEN架构

图4 是否带相邻注意力权重方法训练的比较Fig.4 Difference of training with and without adjacent attention weight methods
3.3 相邻注意力权重方法
解码器通过正确注意力的反馈,可以增强选择正确注意力区域的能力.但是,自然场景图像中存在着各种类型的噪声.在实际应用中,解码器可能会被欺骗以关注模糊背景区域.如果解码器生成不正确的注意力区域,选择非对应的特征,这将会导致预测失败.如图4所示,图像包含具有阴影以及复杂背景的文字.左边的解码器产生了错误的注意力区域,得到了错误的预测结果,遗漏了字母i.
我们使用了一种称为相邻注意力权重的训练方法,它在训练阶段每一个时间步都获取一对相邻的特征.通过此方法训练的注意力解码器可以感知相邻的字符.我们在解码器的每个时间步选择和修改一对注意力.在时间步t,αt,k和αt,k+1以如下方式更新.
(10)
其中,β是(0,1)间随机生成的小数;k是[1,T-1]间随机生成的整数;T代表解码器的最大步长.
基于相邻注意力权重方法的解码器,在αt,k和αt,k+1中都加入了随机性.这意味着:即使对于相同的图像,在训练阶段的每个时间步长,αt的分布都会发生变化.如式(7)所述,注意力向量gt根据αt的各种分布来获取序列特征向量hi,其等同于特征区域在变化.β和k的随机性不仅可以避免过拟合,并且可以增强解码器的鲁棒性.注意:αt,k和αt,k+1是相邻的.在不使用相邻注意力权重方法时,序列特征向量hk的误差项是
δhk=δgtαt,k
(11)
上式中,δgt是注意力向量gt的误差项;δhk仅与αt,k有关.但是,使用相邻注意力权重方法,误差项变为
δhk=δgt(βαt,k+(1-β)αt,k+1)
(12)
其中,αt,k+1与hk相关,如式(8)和式(9)所示,这意味着δhk受相邻特征决定.因此,反向传播的梯度能够在更宽范围的相邻区域上动态地优化解码器.
使用上述方法训练的FRAEN在每个时间步骤产生更平滑的αt.所以,我们不仅可以提取目标字符的特征,而且还提取了前景和背景上下文的特征.如图4所示,使用此方法能够正确地预测目标字符.
3.4 双向解码器
在我们上述的方法中,使用的序列到序列注意力模型只能捕捉一个方向上的标签相关性.在实际中,从左到右和从右到左两个方向上的相关性对识别都有利.例如,一个从左到右工作的解码器可能会因为缺乏上文而难以识别一些单词的首字母,尤其是当该字母为大写‘I’或小写‘l’这样容易混淆的字母时.相比之下,一个从右到左的解码器则可能更容易识别这些字母,因为它可以根据语言先验知识,由其余字母去推测首字母.
上述的例子表明,工作在相反方向上的两个解码器可能存在互补性.为了同时利用两个方向上的相关性,我们提出一种双向解码器.如图5所示,双向解码器由两个预测方向相反的解码器构成.一个从左到右地识别字母序列,另一个从右到左.从右到左解码器的输出和另一个解码器的输出进行得分比较.得分较高的标签序列被输出,较低的被丢弃.这里的得分为解码器每一步的判断得分的累加值.实际中,我们使用基于贪心算法的解码器,在每一步解码中都选取得分最高的标签作为输出,当输出为EOS时停止.

图5 双向解码器Fig.5 Bidirectional decoder
3.5 模型训练
FRAEN的训练是端到端且是多任务的.因此,训练的损失函数为
logprtl(yt|I))
(13)
其中,y1,…,yt,…,yT表示标注的字母标签序列.损失函数为两个解码器(其预测概率分别由pltr和prtl表示)各自损失函数的平均.等式的右侧只需由图像和标签序列标注计算得到,因此网络的训练只需要图像和对应的标注文字.
模型的所有网络层参数都是随机初始化的.通过随机梯度下降法进行训练,梯度通过反向传播算法进行计算,我们采用的卷积神经网络和循环神经网络都可以进行反向传播,因此FRAEN可以将其接收的误差梯度传递到每一个网络层上,将所有网络进行端到端训练.
网络训练的优化算法使用Adadelta,通过Adadelta分别计算每个参数上的学习率.在实际使用中,Adadelta的收敛速度快.
4 实 验
在本节中,我们在各种基准数据集上进行广泛实验,包括规则和不规则文字数据集.所有方法的性能都是通过单词级的精度来衡量的.我们在表3中列出了逐步组合本文各方法得到的结果.可以看出在将所有方法都统一为一个网络结构时,取得了最好的效果.

表3 FRAEN的准确率
4.1 数据集
IIIT5K-Words (IIIT5K)[20]包含用于测试的3 000张裁剪单词图像.每张图像都有一个50词的词汇表和一个1 000词的词汇表.词汇表由一个正确的单词和其他随机选择的单词组成.
SVT (Street View Text)[19]采集自Google Street View,其测试集包含647张裁剪后的图片.许多图片都受到噪声的严重影响,或者分辨率很低.每个图像都与一个50词的词汇表相关联.
ICDAR 2003(IC03)是ICDAR 2003竞赛所使用的数据集.本文只使用其识别数据集.包含非字母数字和长度小于3的文字图片被从数据集中剔除.过滤后的识别数据集包含860张裁剪图片.
ICDAR 2013 (IC13)[21]的大部分样本都继承自IC03.它包含1015个裁剪文字图像.没有与此数据集关联的词汇表.
SVT-P (SVT-Perspective)[22]被用于文字识别,并且是一个不规则文字数据集.主要由侧视文字组成,其图片来自于非正面拍摄的街景,因此很多图片都伴随强烈的视角扭曲.SVT-P包含639张裁剪图片.该测试集每张图片关联了一个50词的词汇表.
CUTE80[23]专门用于评估弯曲文字识别的性能.其包含288个裁剪的自然图像的测试集.没有词汇表与此数据集相关联.
ICDAR 2015(IC15)[24]包含2077个裁剪图像,包括200多张不规则文字图片.没有词汇表与此数据集相关联.
4.2 实现细节
(1) 网络结构:有关FRN和AEN的详细信息分别在表1和表2中给出.解码器中GRU的隐藏单元数为256.AEN输出37个类别,包括26个字母,10数字和1个代表EOS的符号.
(2) 模型训练:FRAEN以端到端的方式进行训练.训练数据由Jaderberg等人[25]发布的800万张合成图像和Gupta等人[26]发布的600万合成图像构成.我们的实验中不使用任何像素级标签.使用Adadelta自适应学习率调整的优化方法,我们在开始时将学习率设置为1.0,每三个epoch之后降低10倍,批量大小设置为256,训练完全耗费了46 h左右的时间.
(3) 实现:我们基于PyTorch0.4框架实现了我们的方法.我们的实验中使用NVIDIA RTX-2070 GPU,CUDA 10.0和CuDNN v7后端,我们的模型使用GPU加速,所有图像尺寸都调整为32×100.
4.3 FRAEN在规则文字数据集上的性能
我们在常用规则文字数据集上进行评估,这些数据集中大多数测试样本是规则文字,其中有一小部分是不规则文字.我们将本文方法与之前9种方法进行比较,结果如表4所示.FRAEN在没有词汇表的模式下优于所有当前最好的方法.
4.4 在不规则文字上的识别结果
我们还在不规则文字数据集上进行了评估,在存在大量不规则文字的SVT-P,CUTE80和IC15三个测试集上进行测试.结果如表5所示,FRAEN表现优异.
对于SVT-P数据集,许多样本都是低分辨率和透视的.具有50字词汇表的FRAEN的结果与Liu等人[27]的方法的结果相同.但是,FRAEN在没有任何词汇表的情况下优于所有方法.

表4 FRAEN在规则文字测试集上的准确率

表5 FRAEN在不规则文字测试集上的准确率
4.5 FRAEN的局限
为了公平比较和良好的可重复性,我们选择了广泛使用的训练数据集进行测试.如图6所示,可以看出最后两张图像本文方法预测错误,因此,在场景文字背景复杂和文字弯曲角度太大时,本文方法可能会失效,因为其可能会错误地将复杂背景视为前景,从而影响预测结果.上述实验均基于裁剪文字识别,没有文字检测器的FRAEN还不是端到端场景文字检测识别系统.在更多应用场景中,不规则和多方向的文字对于检测和识别都具有很大的挑战性.

图6 SVT-Perspective和CUTE80数据集上的结果Fig.6 Results on SVT-Perspective and CUTE80
在本文中,我们提出了一个用于任意形状场景文字识别的带有灵活矫正功能的注意力增强网络.本文方法分成两个阶段来解决不规则文字识别问题:文字矫正和文字识别.首先,由矫正网络处理复杂的变形文字,将其矫正为更易识别的文字.然后,使用基于相邻注意力权重的双向解码器的序列识别网络来识别矫正后的图像并预测输出.我们在规则和不规则文字数据集上进行了大量实验,都表现出了优异的识别性能,尤其在不规则文字数据集上.将来,我们有必要扩展这种方法来处理任意方向和任意弧度的文字识别问题,由于文字和背景的多样性,这个问题更具挑战性.由于端到端文字识别性能的改进不仅取决于识别模型,还取决检测模型.所以,找到一种将FRAEN与场景文字检测器结合起来的正确有效方法也是值得研究的方向.
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
中国自行车(2018年2期)2018-05-09 07:03:05
福建人(2016年6期)2016-10-25 05:44:15
Coco薇(2015年7期)2015-08-13 22:47:12
中国医疗美容(2015年2期)2015-07-19 10:11:59
电脑迷(2014年16期)2014-04-29 03:32:41
双语时代(2009年3期)2009-09-24 08:45:32
