
面向海量数据的分布式用户态文件系统研究与设计*
2020-03-26 08:26李小勇
通信技术 2020年2期
龚 恒,李小勇
(上海交通大学 网络空间安全学院,上海 200240)
0 引 言
传统意义上,文件系统是操作系统内核的一部分。随着分布式存储系统[1]的出现和大数据分析技术[2]需求的增大,面对海量的数据文件,用户实现数据访问的步骤也越来越繁琐,开发面向用户场景的用户态文件系统[3]势在必行。
本文底层使用分布式对象存储系统,结合fuse[4-5]技术和分布式数据库MongoDB[6],设计基于分布式存储的用户态文件系统bfs-fuse,以文件目录形式对分布式对象存储系统中的对象进行管理和访问,从而为用户提供高效便捷的数据访问管理策略。
1 底层数据存储架构
底层数据使用分布式存储系统。分布式存储将数据对象分散到多个存储服务器上,并将这些分散的数据资源通过统筹管理合并为一个虚拟统一的存储系统。
典型的分布式存储架构,如图1所示。
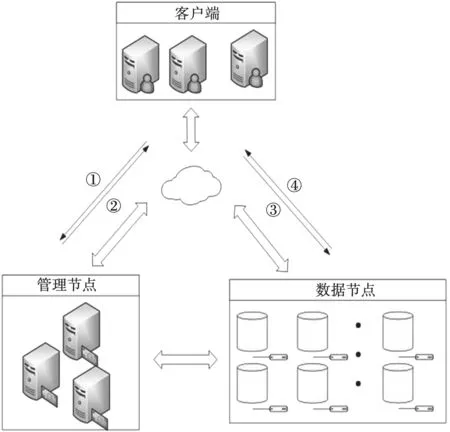
图1 分布式存储架构
它通常由3个部分组成——管理节点(Manager Node)、数据节点(Data Node)和应用客户端(Client)。其中,管理节点负责管理集群元数据、协调集群服务、响应客户端发来的数据请求等。在整个集群架构中,管理节点是最核心的部分,通常采用主从、多活等方式增加整个架构的稳定性和安全性。数据节点主要负责存储用户数据,保证用户数据的可用性和完整性;应用客户端负责发送数据的读写请求,缓存元数据和用户数据。
2 数据分布与存储策略
2.1 基于一致性哈希的数据分布
20世纪末,麻省理工学院Karger等人提出一致性哈希算法,解决了分布式结构中动态增加和删除带来的雪崩问题以及数据分布不均衡问题,在分布式系统中得到了广泛应用。
本文使用一致性哈希算法作为分布式存储数据节点的数据分布算法。集群中同一个存储池中的所有数据对象,经过一致性哈希运算后被分散存储到该存储池中的所有存储设备上。为增强数据分布的均衡性,在数据和存储节点之间再引入一层虚拟节点(Cube)层。虚拟节点可以理解为存储节点在哈希空间中的复制品,其总数远大于存储节点的数量,且按照不同存储节点在容量和性能上的差异以及负载均衡的要求进行分布。图2展示的是系统在查找对象号object_id为obj_1的对象的查找映射过程。
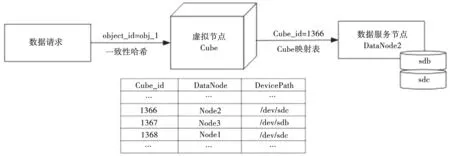
图2 数据分布查找映射
2.2 多副本管理机制
数据存储采用多副本方式来提高数据的高可用性,各副本将被尽量存储到不同的数据服务器。初始状态下,容器中所有对象默认以双副本存储,也可在创建每个容器时对容器的副本数进行单独配置。对于相对重要的文件,通常以三副本保存。系统中每个对象对应的文件扩展属性中保存了数据版本号和随机序列数,两者结合进行版本管理和一致性保证。
在读取数据流程中,客户端首先从三个副本所在的数据服务器拉取版本号,选择版本号最新的副本作为正确数据向上层应用返回,并将版本号错误的副本信息报告给对应的数据服务器,以便在之后进行数据修复。在写入数据流程中,客户端将优先写主副本,然后由主副本所在数据服务器采用扇出写的方式向另外两台数据服务器写从副本。为了平衡性能与一致性,底层向上层应用保证最终一致性,即只有主副本落盘且确认另外两个从副本均已成功推送至对应数据服务器后向客户端返回数据写入成功。
2.3 元数据管理机制
元数据的管理是分布式文件系统的核心,也是分布式存储系统架构和保障的重中之重。
为了提高文件元数据的一致性和可靠性,支持用户文件系统目录操作,本文使用MongoDB数据库对分布式存储系统存储的文件元数据进行集成管理。文件元数据最基本的作用在于数据对象的定位,客户端只有先访问存储元数据的管理节点,得到数据对象的inode号以及相关的访问权限,才能进行下一步的数据读写访问。元数据服务模块架构如图3所示。
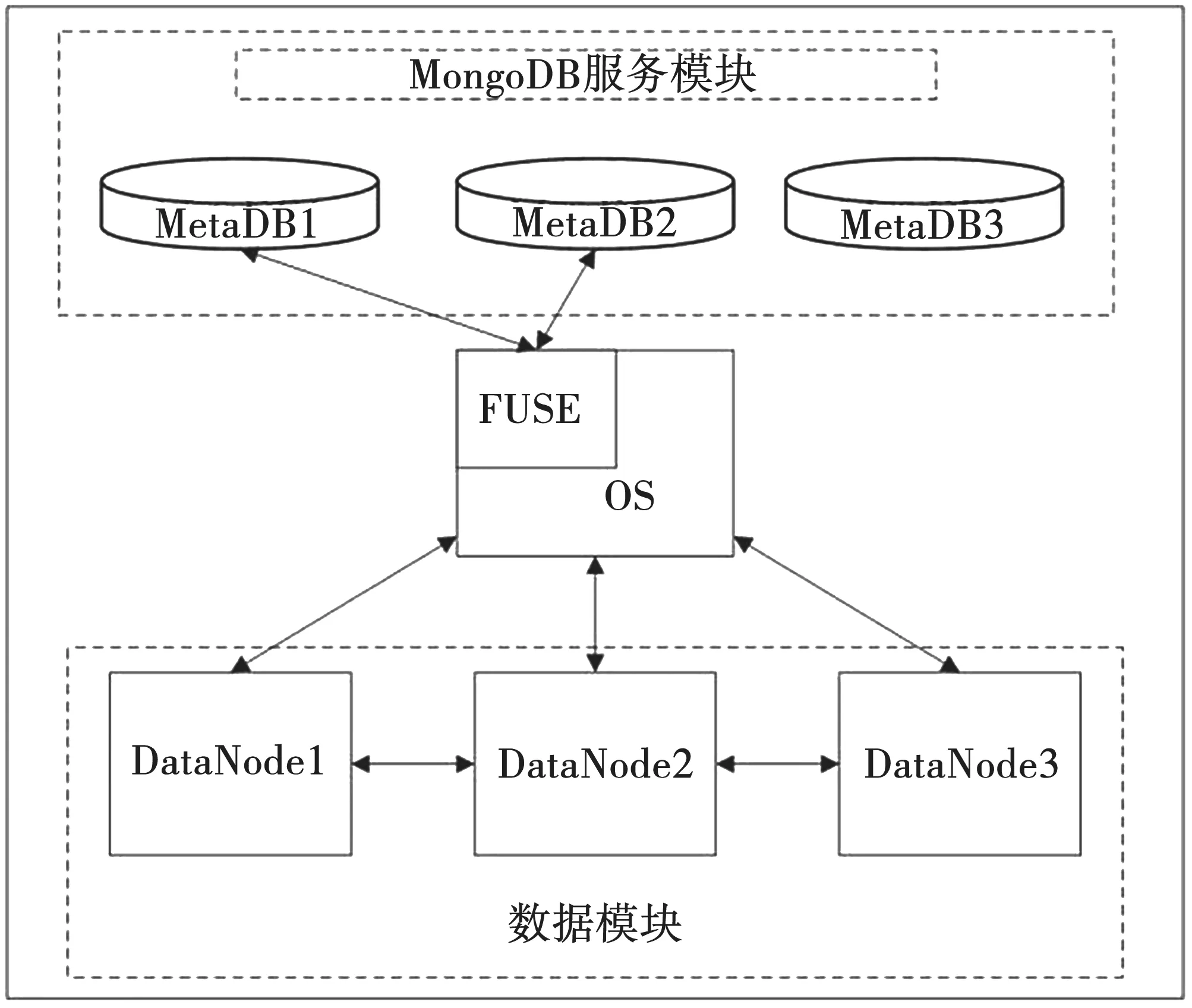
图3 元数据服务模块架构
为了提高系统的访问效率,将文件系统中所有目录和文件用一张统一的表(fs_object)来管理,即用户空间里的所有文件和目录都被映射为存储系统里面的一个个对象,通过关键字(is_dir)是否为0来区分文件和目录。每个对象的元数据信息包括对象ID、对象名、父节点ID、是否是目录、对象大小、创建时间、修改时间以及父inode号等。在访问请求中,客户端只需要访问一张表就可以获得文件对象的所有元数据信息,从而减少不必要的开销,提高元数据的管理效率。
3 数据访问设计
3.1 基于bfs-fuse的数据访问
分布式存储系统通常使用Linux系统作为硬件操作系统,但Linux中文件系统中文件系统都在内核态实现,文件系统功能的增加和修改在内核中需要做很大的工作量,且调试起来非常复杂,而fuse的出现改善了这一情况。
fuse(用户态文件系统)是一个在用户空间实现的文件系统框架,通过fuse内核模块给予支持。基于fuse提供的接口,本文设计实现了支持对象与文件映射和文件操作的文件访问系统bfs-fuse。
在bfs-fuse中,由内核模块创建块设备/dev/fuse,作用是沟通用户空间进程的fuse进程和系统内核。来自/dev/fuse的所有请求都是通过file requests请求队列发送到内核,bfs-fuse从/dev/fuse中读取请求并进行处理。
当用户态应用程序(如ls、cp、mv、rm等)发起具体请求时,应用程序将文件系统操作请求发送给内核,内核读取来自该设备的请求。内核中,每一个具体的请求都包含具体文件的inode,内核需要解析文件路径中每一层路径的inode号进行拼接,得到文件具体的inode号,再根据文件的inode号从MongoDB数据库中得到文件映射在存储系统中对象的object_id,进而通过一致性哈希运算得到对象在分布式储存中的location地址,最后从分布式系统中取出数据对象,返回给用户空间的应用程序。它的内核调用流程如图4所示。
3.2 fuse组件改进
在原有的分布式集群中增加fuse组件和元数据信息的管理,必然会降低文件系统增删查改对象的效率。为了减少系统性能的损失,在设计bfs-fuse时,本文针对分布式存储的特性,对fuse挂载组件的部分参数配置进行了如下改进。
(1)提高页面空间大小。在fuse中,默认请求被分配的page大小是4 kB,但实际中存储的文件大小通常远大于4 kB,使得文件写入时上下文切换频率增加,降低文件读写效率,故bfs-fuse中将页面空间大小修改为128 kB。
(2)缓存文件的元数据信息。对于只读和查询的文件,对文件的inode和dentry结构进行缓存。
(3)数据直接I/O读写。对于数据需要直接落盘的应用,允许应用程序跳过缓存,直接将数据写入存储设备中。
4 性能测试
本文的测试方案通过海量数量小文件读写测试和大文件读写测试两个角度模拟实际应用中的I/O需求。通过海量小文件的读写,测试系统的性能瓶颈;通过大文件的读写,测试系统的吞吐量性能。部署3节点分布式存储集群作为测试环境,所有硬件服务器均为DELL服务器,内存32 GB,16核CPU,千兆以太网。测试脚本通过调用linux读写接口,在磁盘中创建和读写文件,并返回读写时间和带宽。
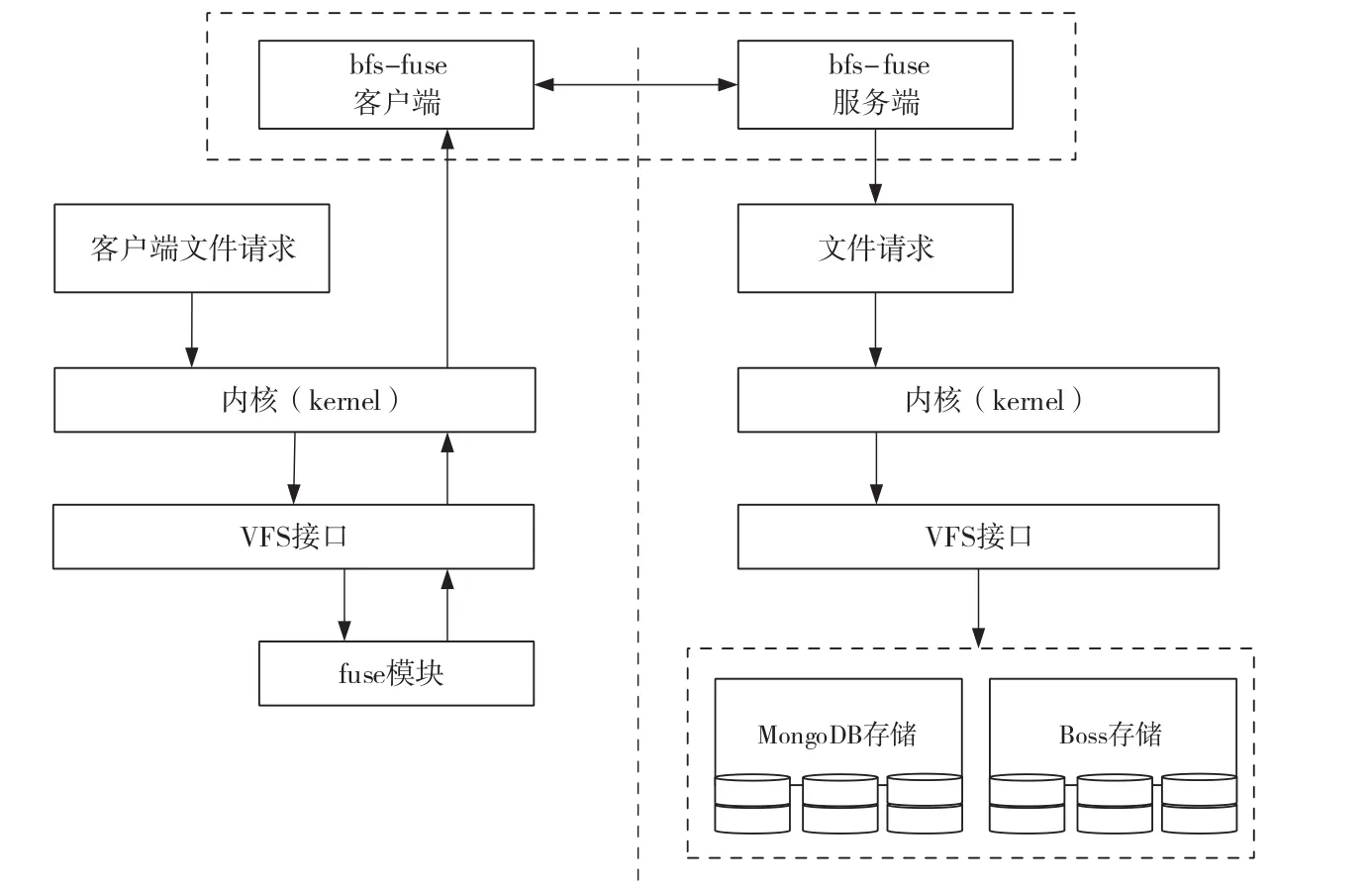
图4 bfs-fuse内核调用流程
在小文件测试中,分别使用1~1 024个线程。每个线程分别在挂载目录写入、读取100个16 kB大小的文件,用来模拟现实网络中常见的小文件读写,测试结果如图5所示。

图5 小文件读写测试
从图5可以看出,由于使用分布式存储,小文件读写的性能随着线程数的增加而增加;当线程并发数超过256时,读写性能趋于稳定,分别是35 MB/s和80 MB/s左右。它的带宽低于千兆以太网理论带宽的峰值,这是因为对于海量的小文件,读写过程中产生的额外开销不可忽视,如MongoDB元数据读写、文件查询和定位等。从读写整体性能对比来看,相同线程数写入的带宽速率要远高于读取速率,这是因为小文件批量写入时采取的是顺序写的方式,但读取时因为文件大小比较小、数量多,其读取方式相当于随机读取,所以读取带宽速率会小于写入的带宽速率。
在大文件测试中,分别使用1~1 024个线程。每个线程分别在挂载目录写入、读取4个1 GB大小的文件,用来模拟现实网络中常见的大文件读写,测试结果如图6所示。其中,随着线程并发数的增加,读写带宽随之增加,最终趋近于各自的峰值140 MB/s和120 MB/s。这与千兆以太网理论带宽相近。
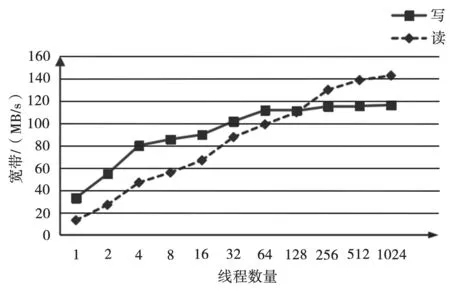
图6 大文件读写测试
从整体来看,系统在吞吐量性能方面有着不错的表现,但在小文件读取性能方面有一定的提升空间,因为文件系统通过MongDB访问元数据带来的性能开销在小文件读写中无法忽视,建议对MongoDB服务器配置SSD固态磁盘存储元数据,同时开启MongoDB缓存提高元数据访问速率,进而提高海量小文件读取时的性能。
5 结 语
本文的创新点是在分布式存储系统的基础上,结合MongoDB,使用fuse框架设计,实现了面向海量数据的用户态分布式文件系统,既具有很高的灵活性和可扩展性,又使得用户对分布式存储系统的访问更加便捷,管理更加方便。经过小文件读写和大文件吞吐量测试可以发现,本文设计的文件系统在吞吐量性能和小文件创建方面有着优良的性能表现,但在小文件读取性能方面有进一步的提高空间。
猜你喜欢
计算机系统应用(2022年5期)2022-06-27
今日农业(2021年9期)2021-07-28
现代装饰(2021年1期)2021-03-29
网络安全和信息化(2019年8期)2019-08-28
中国计算机报(2019年12期)2019-06-21
计算机系统应用(2019年2期)2019-04-10
发明与创新·大科技(2019年12期)2019-03-17
小型微型计算机系统(2018年3期)2018-03-27
电子制作(2017年19期)2017-02-02
弹箭与制导学报(2015年1期)2015-03-11
