
基于机器学习算法的脑出血相关肺炎预测模型研究
2020-03-26 12:41:20王孟覃露王春娟李姣王伊龙赵性泉王拥军李子孝
中国卒中杂志 2020年3期
王孟,覃露,王春娟,李姣,王伊龙,赵性泉,王拥军,李子孝
卒中是全球死亡率最高的疾病之一[1]。根据全球疾病负担研究最新估计,2017年我国卒中死亡率为106/10万,居我国疾病死因首位[2]。脑出血是致残率、死亡率最高的一类卒中亚型,分别占卒中发病、死亡的30.1%和50.0%[1,3]。卒中相关肺炎(stroke-associated pneumonia,SAP)是脑出血常见并发症之一,是导致卒中患者死亡的独立危险因素[4-6],增加患者住院时间和医疗费用[7-8]。因此,探索SAP的危险因素,建立风险预测模型,是发现高危人群、预防SAP、降低卒中死亡率的有效手段。
研究证明,年龄、性别、吸烟、糖尿病、高血压、心房颤动、心力衰竭、慢性阻塞性肺疾病、吞咽困难、高血糖等可能是导致SAP的危险因素[9-12]。目前,应用于脑出血相关肺炎的预测模型较少。冀瑞俊等[13]在中国国家卒中登记人群中,首次建立了脑出血相关肺炎预测模型。
机器学习能够对大数据深度挖掘与分析,目前已在疾病发病、预后预测等方面有广泛应用[14-15]。然而,目前尚未有基于机器学习的疾病风险预测模型,应用于脑出血相关肺炎的早期诊断。本研究采用基于机器学习的Logistic回归、CatBoost、XGBoost、LightGBM四种算法,建立、评价脑出血相关肺炎预测模型。
1 研究对象与方法
1.1 研究对象 本研究基于中国国家卒中登记Ⅱ(China National Stoke Registry Ⅱ,CNSRⅡ)数据库,以2012年5月-2013年1月连续登记的发病7 d内的急性脑出血住院患者为研究对象,研究覆盖我国219家医院。
纳入标准:①年龄>18岁;②根据世界卫生组织诊断标准诊断为脑出血[16];③脑出血诊断经CT或MRI确诊;④经门诊或急诊住院;⑤入院后经吞咽功能评价;⑥患者或法定代表人签署知情同意。排除临床信息不完整的患者。
1.2 研究方法
1.2.1 患者基本信息 采用病例报告表收集患者的人口统计学信息(年龄、性别、吸烟、饮酒)、既往病史(高血压、糖尿病、血脂异常、心房颤动、周围血管疾病、心肌梗死、心力衰竭、慢性阻塞性肺疾病、脑血管病)、入院后临床检查结果(吞咽功能障碍、NIHSS评分、白细胞计数)。病例报告表中数据的完整性、准确性由独立的数据专家进行核查。
1.2.2 卒中相关肺炎的诊断标准 患者出现呼吸道感染的临床表现和实验室指标异常(如发热、咳嗽、听诊呼吸音粗或啰音、新的脓性痰或痰培养阳性),同时有典型的胸部X线或CT检查结果支持,临床诊断为SAP[17]。
1.2.3 机器学习算法 CatBoost在2017年被Yandex[15]首次提出,它采用对称树的方式,并且用特殊的方式来处理分类特征,从而有效地避免了过拟合的问题,提高了泛化能力,提高了模型的鲁棒性,特别适合样本量小、数据不平衡的情况。
XGBoost是华盛顿大学陈天奇[18]于2016年开发的Boosting库,兼具线性规模求解器和树学习算法。传统的梯度提升迭代决策树(gradient boosting decision tree,GBDT)方法只利用了一阶的导数信息,XGBoost则是对损失函数做了二阶的泰勒展开,并在目标函数之外加入了正则项,整体求最优解,用于权衡目标函数的下降和模型的复杂程度,避免过拟合,提高模型的求解效率。
LightGBM是微软2015年提出的新的Boosting框架模型,该算法在传统的GBDT基础上引入了两个新技术:梯度单边采样技术(gradient-based one-side sampling,GOSS)和独立特征合并技术(exclusive feature bundling,EFB)。GOSS可以剔除很大一部分梯度很小的数据,只使用剩余的数据来估计信息增益,从而避免低梯度长尾部分的影响。EFB实现互斥特征的捆绑,以减少特征的数量[18]。
1.3 统计学方法 数据分析应用SAS软件(版本9.4,SAS Institute Inc,Cary,NC)完成。计量资料采用中位数(四分位数间距)表示,组间比较采用Wilcoxon检验;计数资料用频数和百分比表示,组间比较采用卡方检验。将SAP组和非SAP组随机分为训练集(80%)和测试集(20%)。在训练集中,采用非条件Logistic回归,建立预测模型,选择纳入模型的预测指标。首先采用单因素Logistic回归,以P<0.1为纳入多因素分析的标准;将单因素分析选择出的危险因素纳入多因素分析,采用逐步回归法,以P<0.05为最终纳入多因素模型的标准,建立脑出血相关肺炎风险预测模型;用测试集人群对训练集建立的模型进行内部验证。最后,使用多因素Logistic回归模型纳入的指标,采用Logistic回归、CatBoost、XGBoost和LightGBM四种机器学习方法,在训练集、测试集分别建立、验证预测模型,用ROC曲线下面积(area under the curve,AUC)、灵敏度、特异度和正确率比较4种方法预测价值。以上统计均采用双侧检验,以P<0.05为差异具有统计学意义。
2 结果
2.1 患者一般特征 本研究共纳入符合研究条件的脑出血住院患者2303例,平均年龄62.1±12.7岁,男性占62.1%。住院期间肺炎发生率为15.7%(3 61/2 3 03)。非SAP组年龄[61(53~71)岁 vs 67(58~76)岁,P<0.001]、NIHSS评分[6(3~10)vs 10(5~16),P <0.0 0 1]和周围血管疾病史(2.6% vs 5.8%,P=0.001)、慢性阻塞性肺疾病史(1.1% vs 3.9%,P<0.001)、脑血管病史(22.9% vs 31.6%,P<0.001)、吞咽功能障碍发生率(10.6% vs 50.1%,P<0.001)均显著低于SAP组;而白细胞计数[7.6(6.0~9.7)×109/L vs 9.3(7.2~12.4)×109/L,P<0.001]显著高于SAP组;其余人口学信息、既往病史等,两组无统计学差异(表1)。
2.2 Logistic回归单因素和多因素分析结果在训练集中(SAP患者288例,非SAP患者1553例),单因素Logistic回归结果显示年龄、周围性血管疾病、慢性阻塞性肺疾病、脑血管疾病史、吞咽功能障碍、NIHSS评分、白细胞计数可纳入多因素分析。多因素Logistic回归结果显示年龄、吞咽功能障碍、NIHSS评分、白细胞计数可作为候选预测因子来构建预测模型(表2)。
2.3 Logistic回归、CatBoost、XGBoost、LightGBM四种模型结果比较 选择Logistic回归选出的4个危险因素,在测试集(SAP患者73例,非SAP患者389例)验证模型效果,并建立CatBoost、XGBoost、LightGBM预测模型。结果显示ROC曲线下面积Logistic回归、XGBoost、LightGBM模型较高,分别为0.776、0.736、0.767;XGBoost和LightGBM模型灵敏度较高,分别为80.82%和80.82%;Logistic回归和CatBoost模型特异度较高,分别为69.15%和86.12%;其余结果见表3和图1。
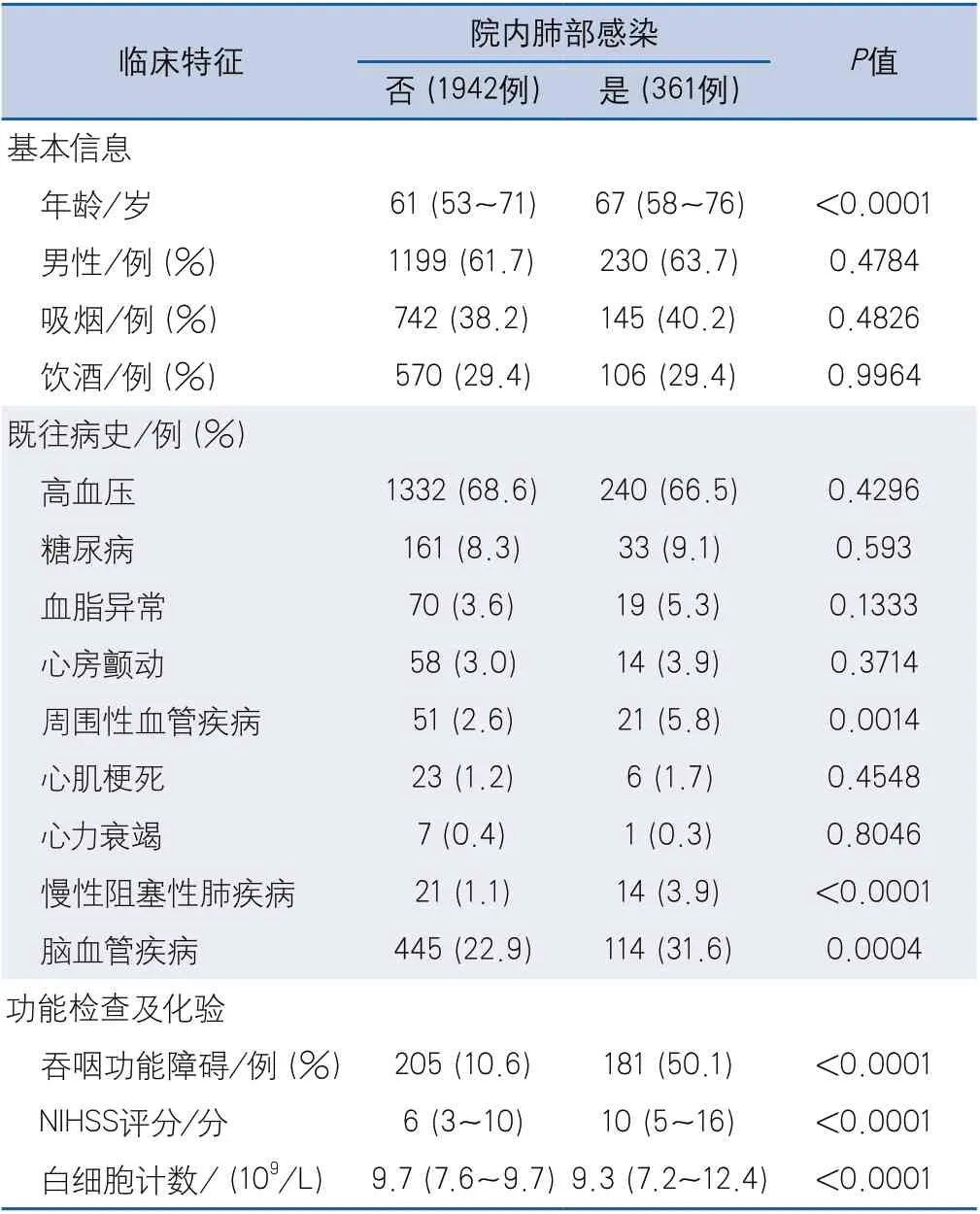
表1 根据住院期间是否发生肺炎分组的患者基线特征
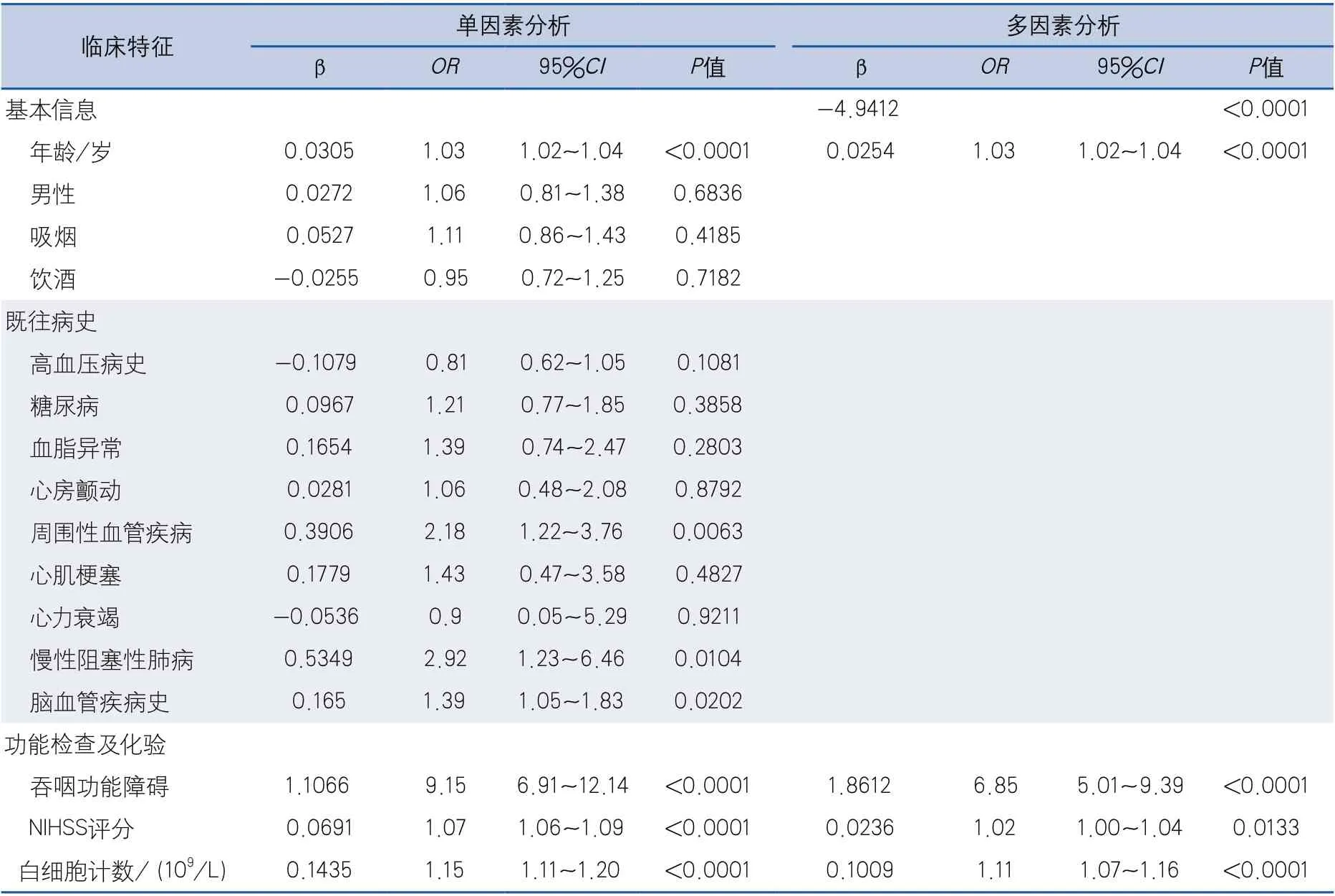
表2 单因素与多因素Logistic回归分析结果
3 讨论
本研究建立并验证脑出血相关肺炎预测模型,可用于脑出血患者肺炎发生风险预测。结合患者基本信息、疾病史、临床检查、血液检查等指标,使用Logistic回归、CatBoost、XGBoost、LightGBM四种算法构建预测模型,以期能够辅助临床医生诊断、预测肺炎发生。
机器学习是人工智能领域中一种新方法,可以对大量输入数据的特征标识进行有效学习,为精准预测提供了新的研究思路和方法。机器学习算法有传统的逻辑回归、决策树,以及在此基础上延伸出的随机森林、LightGBM、XGBoost等。已有学者利用这些模型开展疾病预测研究,且取得较好效果。曹文哲等[19]采用BP神经网络(back-propagation neural network)、Logistic回归和随机森林3种机器学习算法,纳入年龄、游离前列腺癌特异抗原等4种危险因素,建立诊断预测模型,并比较3种模型对前列腺癌的诊断价值,结果证明机器学习建立的多因素预测模型预测效果,优于任意一种单因素建立的预测模型,所建立模型可纳入前列腺癌诊断决策,协助临床医生对患者的诊断和治疗,减少不必要的活检。Heo等[20]在回顾性队列中,采用深度神经网络、随机森林、Logistic回归3种算法,建立急性卒中良好结局预测模型,与洛桑急性卒中登记分析(acute stroke registry and analysis of Lausanne,ASTRAL)模型[21]进行比较,结果表明,深度神经网络效果较好(AUC=0.888),能够显著提高模型预测效果;作者同时证明,当选择和ASTRAL评分相同变量时,机器学习并未显著提高模型预测效果。与此结果类似,本研究中,当选择相同变量时,尽管在训练集中XGBoost(AUC=0.844)、LightGBM(AUC=0.822)模型效果显著高于Logistic回归(AUC=0.778)模型,但测试集中,Logistic回归(AUC=0.776)模型效果略优于XGBoost(AUC=0.736)、LightGBM(AUC=0.767)。
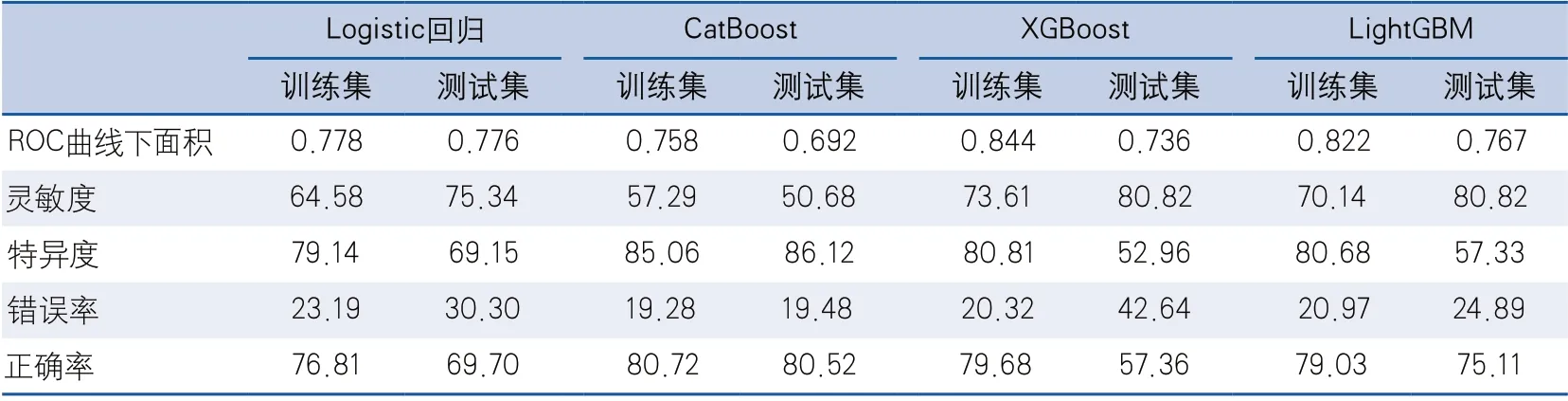
表3 Logistic回归、CatBoost、XGBoost、LightGBM四种模型结果比较
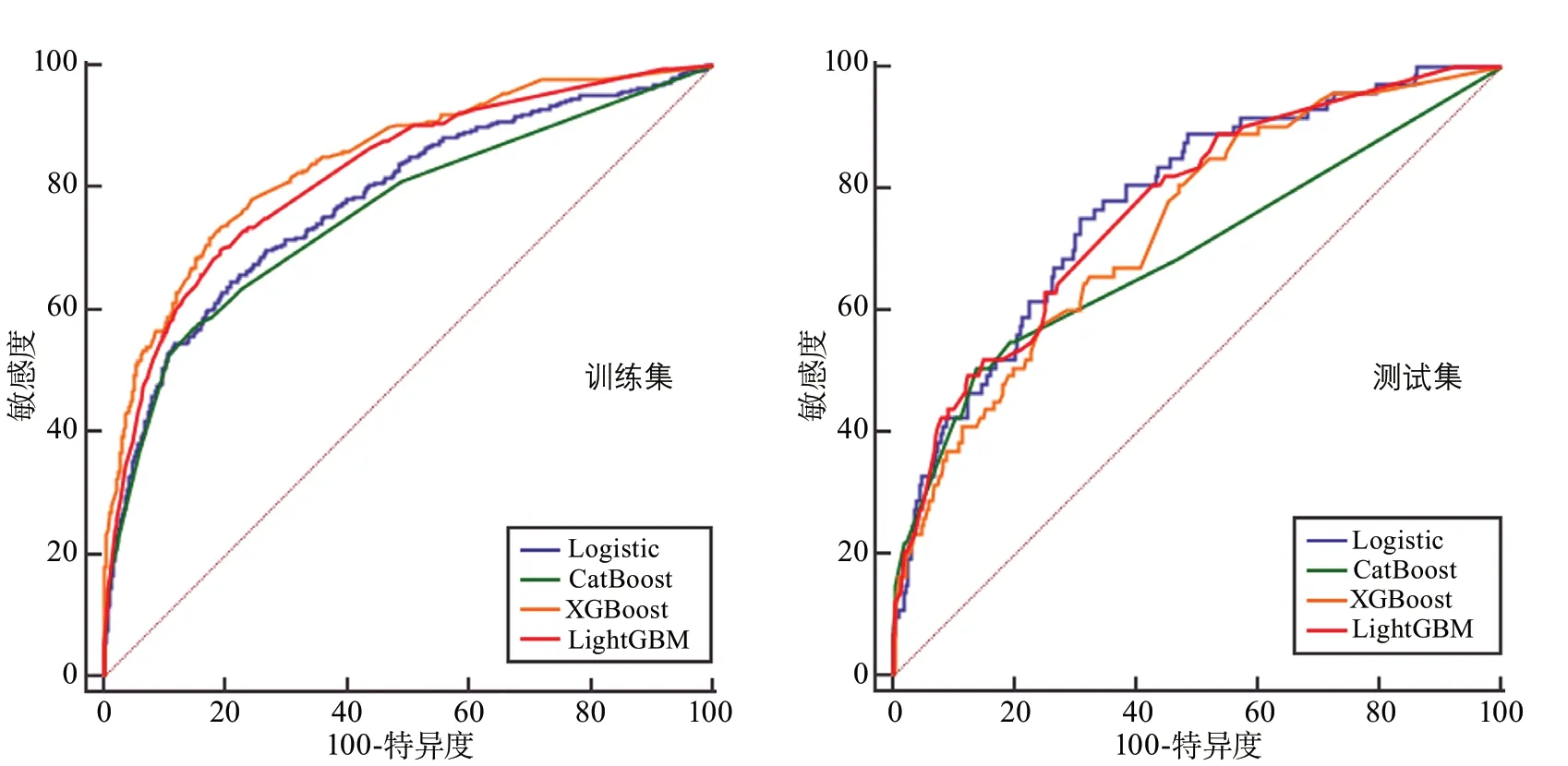
图1 Logistic回归、CatBoost、XGBoost、LightGBM四种模型ROC曲线结果比较
为了尽早识别发生肺炎的高风险患者,优化预警和干预措施,可改善患者预后,近年来国内外已经建立多个SAP预测量表[12,22-25],但多为脑梗死相关肺炎预测。冀瑞俊等[13]建立首个脑出血相关肺炎预测模型,研究采用Logistic回归,纳入年龄、吸烟、饮酒、慢性阻塞性肺疾病、mRS评分、NIHSS评分、GCS评分、吞咽困难等11个指标,结果表明,该模型AUC为0.76,预测效果较好。然而,该模型未纳入实验室检查的指标,已有研究证明超敏反应蛋白、白细胞计数等指标与SAP严重程度正相关[26-27];同时,该模型纳入指标过多,在临床使用时,增加临床医生工作负担。本研究纳入实验室检查指标,使用白细胞计数作为预测因子,结果显示,白细胞计数对于SAP发生的影响(OR 1.11,95%CI 1.07~1.16)高于年龄(OR 1.03,95%CI 1.02~1.04)和NIHSS评分(OR 1.02,95%CI 1.00~1.04);同时本研究只纳入4个预测因子,Logistic回归(AUC=0.776)和LightGBM(AUC=0.767)两个模型的预测效果均高于上述研究的预测效果,预测结果更准确。
本研究的优势有以下三点:首先,脑出血相关肺炎预测模型较少,本研究尝试在脑出血患者中,使用机器学习的方法预测SAP发生风险,研究方法可供后续研究使用;其次,白细胞计数在临床上容易获得,并且与SAP发生关联较高,因此模型只纳入4个预测因子,取得较好的预测效果,方便临床医生的实际应用;最后本研究将人群随机分为两部分,对建立的模型进行了内部验证,保证了模型结果的可靠性。同时,本研究也有不足之处,模型未进行外部验证,仍需在大样本、多中心的外部人群中进行验证,以保证模型的准确性与可靠性。
综上,基于机器学习方法建立的脑出血相关肺炎风险预测模型有较高的诊断价值,年龄、NIHSS评分、白细胞计数和吞咽功能障碍为候选预测因子,可将模型纳入脑出血相关肺炎诊断决策。本研究结果的临床应用价值有待于更大样本的外部队列进行验证。
【点睛】基于机器学习的方法,结合实验室检查指标,可优化脑出血相关肺炎预测模型。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
中国典型病例大全(2022年11期)2022-05-13 21:44:11
环球时报(2022-03-14)2022-03-14 18:19:44
数学小灵通(1-2年级)(2021年11期)2021-12-02 01:30:20
中等数学(2020年8期)2020-11-26 08:05:58
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
电影(2018年8期)2018-09-21 08:00:06
数学小灵通·3-4年级(2017年11期)2017-11-29 01:35:42
老年医学与保健(2017年6期)2017-02-06 05:30:02
中国卫生标准管理(2015年5期)2016-01-14 05:17:05
