
视角相关的车辆型号精细识别方法
2020-03-23 05:29:10朱文佳付源梓
合肥工业大学学报(自然科学版) 2020年2期
朱文佳, 付源梓, 金 强, 余 烨
(1.安徽百诚慧通科技有限公司,安徽 合肥 230088; 2.合肥工业大学 计算机与信息学院,安徽 合肥 230601)
由于车牌易被遮挡和篡改,而针对车标、车辆类型的识别系统不能实现车辆的精确认证,因此,车辆型号(下文简称“车型”)识别受到了研究者的青睐。车型识别属于目标精细识别问题,要求识别车辆具体的品牌和款式,可用于车辆身份认证、特定车辆定位和追踪等,为道路交通管理、城市安全等提供了重要的技术支撑。
针对精细分类问题,一些研究者尝试提取图像中具有区分度的特征来捕捉类别之间细微的外观差异。文献[1]针对一个精细分类的典型数据集,首先整体学习出一个字典,使用该字典对整体类别的公共部分进行编码,再针对每个类别单独学习一个字典,对每个类别中的细节部分进行编码,最终将两者结合进行分类;文献[2]结合Fisher向量编码方式来提高精细分类的准确率;文献[3]分别使用2个独立的卷积神经网络(convolutional neural network,CNN) 模型特征提取器,分别提取图像特征,通过双线性操作汇聚特征,实验表明该方法在鸟类数据集上取得了非常好的效果。
也有研究者从另外的角度进行精细分类。文献[4-5]认为精细分类问题中子类别大都从属于某个大类别,因此各个子类别之间必然存在着某些关联,基于此先验知识,考虑类别之间的结构相关性,构造从粗类别到细类别的由顶向下的多级标签结构,有效解决精细分类中类间差异小、类内差异大的问题;文献[6-7]基于递归CNN模型自适应地找到一系列具有高区分度的区域并提取特征;文献[8]基于强化学习,首先采用多任务驱动的方式来训练全卷积注意力模型,之后自适应地选择图像中有判别力的区域,大大地提高了计算效率与准确率;文献[9]提出一种基于注意力机制的深度残差网络模型,该模型分为2个分支,一个分支类似于传统的CNN用于提取图像特征,另一分支通过设计卷积和反卷积操作得到注意力权重,对2个分支特征进行点积操作来增强有效特征而抑制低效或无效特征。
上述基于目标精细识别的方法用于车型精细识别时并不能取得非常好的效果,其识别率还有待提升。目前,针对车型精细识别的相关文献并不是非常多。文献[10]提出使用上、下分层网络的方法对卡口图像中的车辆前脸照片分别进行特征提取,通过特征的融合进行车型识别;文献[11]提出几种“特征重用”的方法,以残差网络为主结构,提升了网络提取车辆精细特征的能力,提高了车型识别的识别率;文献[12]认为车辆正面外观中的结构部件具有不同的视觉特性,首先在车辆品牌级别利用车标子区域进行车型分类,以减少类间相似性,之后根据剩余子区域的判别能力,为每个子类训练出不同的分类器,实现车型精细分类;文献[13]提出一种新的基于SqueezeNet结构的品牌和车型识别(make and model recognition, MMR)的深度学习方法,首先提取车辆图像的正面视图,并将其输入深层网络进行训练和测试,SqueezeNet结构使得MMR系统在车型识别任务中更加高效。
针对车型精细识别问题,本文考虑车辆拍摄视角所带来的特征差异,以多视角的车辆图像为数据源,提出了一种视角相关的卷积神经网络(viewing angle relative convolutional neural network, VAR-NET)模型。VAR-NET模型具有以下特点:① 在经典目标检测模型[14]的基础上进行改进,设计视角预测子网络以提取图像中车辆视角信息;② 设计分类网络将分类特征与视角特征进行融合,增强车辆精细分类的有效特征;③ 整合视角预测网络与分类网络,实现端到端的多任务训练。在公开数据集CompCars和StanfordCars上进行实验,实验结果表明,VAR-NET模型用于车型精细识别,能够取得非常好的识别效果,其识别率高于一些其他经典的CNN模型。
1 算法描述
1.1 VAR-NET模型结构
VAR-NET模型框架如图1所示。
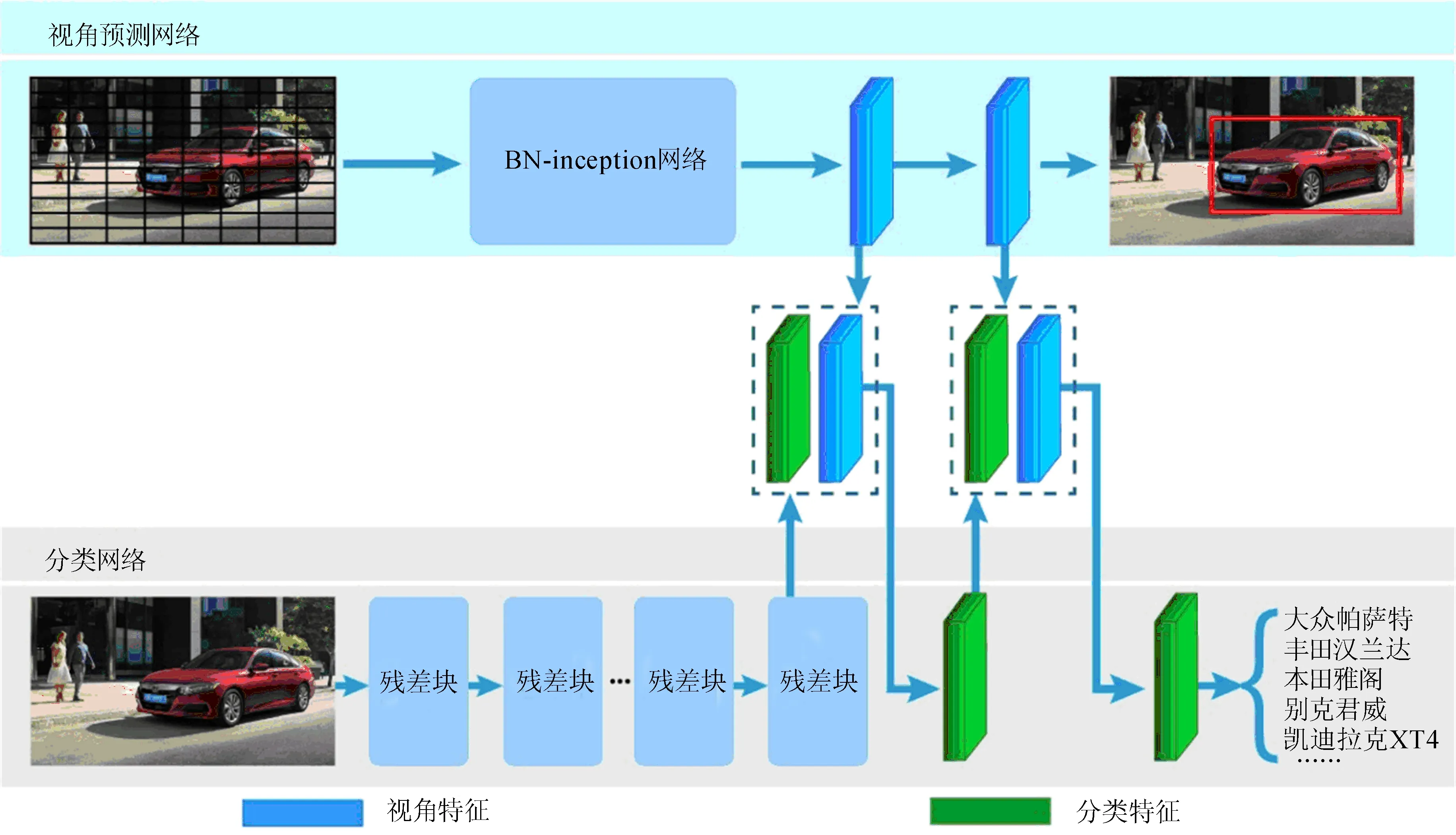
图1 VAR-NET模型框架
VAR-NET模型通过在CNN模型中嵌入车辆的视角相关信息,实现对多视角车辆图像的精细特征提取,完成车型的分类。该模型由进行视角初始估计的预测子网络和基于特征重标定与特征融合的分类子网络2个部分构成。
视角预测网络以YOLO算法为原型,针对车辆视角预测任务加以改进,将原图像分成N×N尺寸的网格,每个网格预测信息包含车辆的置信度、视角信息及坐标信息,使用非极大值抑制的方法定位车辆并预测车辆视角信息。本文称视角预测网络提取的特征为视角特征,在图1中用蓝色块表示。分类网络是一个常规的CNN模型,用以提取车辆特征并实现分类,本文选用残差网络(residual network, ResNet)[15]模型。车辆输入图像首先在2个子网络中并行传播,然后再将视角预测网络的视角特征与分类网络提取的分类特征进行融合,对融合后的特征进行分类,实现对多视角车辆图像的精细分类。
1.2 视角预测网络
YOLO模型是由文献[14]提出的一种基于CNN的端到端目标检测方法。YOLO算法相比于基于区域的卷积神经网络(region-based CNN, R-CNN)系列算法,在检测物体时可以考虑到全局特征信息,从而更有效地区分目标与背景。本文利用YOLO模型这一特点,利用图像的全局特征对车辆的位置与视角等视角相关信息进行预测,进而提取车辆的视角特征。
本文基于YOLO算法设计视角预测网络的特征提取结构,同时为了获取车辆的视角信息与视角特征,对模型的细节加以改进,主要调整包括改变骨架网络、修改模型输入及调整损失函数。
1.2.1 改变骨架网络
由于BN-inception网络[16]有着更好的分类性能与训练性能,本文使用BN-inception网络作为特征提取的主体结构,并且在BN-inception网络后面额外增加了2层卷积层,以进一步提取更加有效与鲁棒的车辆视角特征。
1.2.2 修改模型输入
YOLO模型与VAR-NET模型的输入如图2所示。原始YOLO模型的输入是输入图像和图像中目标的位置,其使用目标的中心坐标及宽、高来代表目标的位置,将目标中心所在的块作为负责检测目标的块,而将其他的块看作不是检测目标的块,如图2a所示。本文VAR-NET模型考虑到车辆的每个部分重要程度不同,获取图像中每块的重要度Aij,计算公式为:
(1)
其中,Sij为第i行第j列块的面积;SBB为目标包围盒的面积;∩表示求第i行第j列块区域与目标包围盒重叠区域的面积。Aij将作为YOLO算法中损失函数的权重,且所有Aij=1的块,即整个块都落在车辆上的块,都将看作负责检测目标的块,如图2b所示。
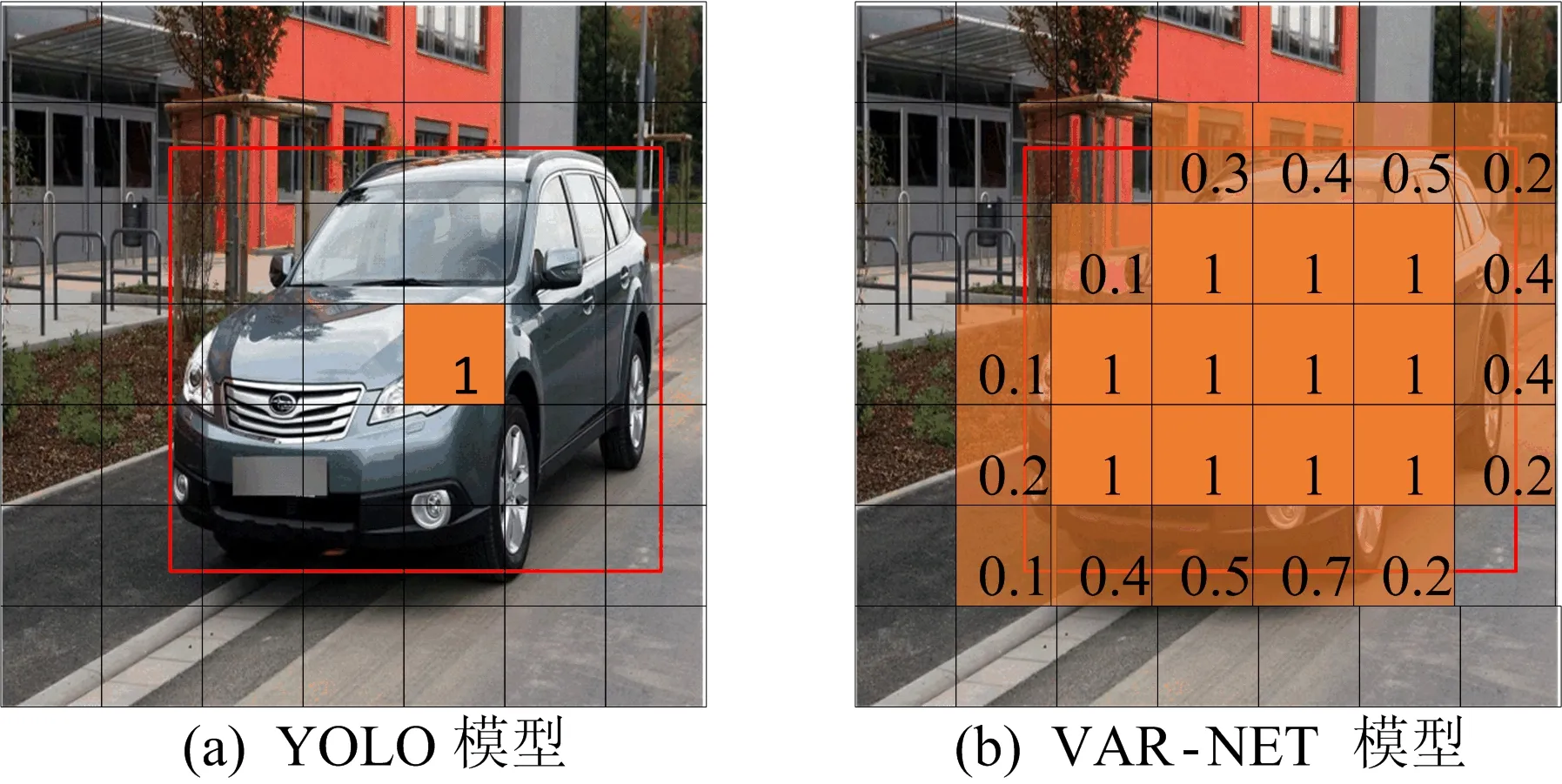
图2 YOLO模型与VAR-NET模型的输入
1.2.3 调整损失函数
不同于YOLO原始算法针对定位和分类任务的设计,本文仅用YOLO算法对车辆进行定位和视角预测,而不用于分类,因此在损失函数中删除了分类误差,同时增加了视角误差,调整后的损失函数L如下:
L=Ecoord+Edetect+Eview
(2)
其中,Ecoord为坐标误差;Edetect为检测误差;Eview为视角预测误差。
视角预测网络的定位任务属于简化的单类别定位任务,因此,设定每个预测块只预测1个包围盒。本文只使用完全落在目标上的块,即Aij=1的块,来预测目标的位置,Ecoord计算公式为:
(3)
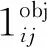
本文以每个块与目标包围盒的重叠面积作为“真实重要度”,Edetect为“预测重要度”与“真实重要度”之间的差值,其计算公式为:
(4)
视角预测任务属于多分类问题。视角预测只针对完全落在目标上的块来预测,Eview计算公式为:
(5)
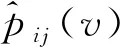
1.3 视角相关的分类网络
为了提高CNN的特征表达能力,有些网络如VGG[17]通过加深网络的深度来提高性能,但是由于训练过程中的梯度消散问题以及硬件条件限制,约束了网络深度的进一步增加;也有些网络从空间维度上提升网络的性能,如GoogLeNet[18]和ResNet等加宽网络“宽度”的方式,都取得了很好的效果。本文的分类网络从视角相关信息角度出发,将车辆的特征与视角信息相结合,选择更有利于车辆精细分类的特征,实现对车型的识别。
文献[19]提出了挤压和激励网络(Squeeze-and-Excitation Networks,SENet),针对不同通道进行建模,并在2017年ImageNet比赛的图像识别任务中获得冠军。在SENet中,不同通道的权重通过“压缩”和“激励”2步操作得到。其中“压缩”是指将前一层的特征图按每个通道求得平均值,得到通道数量为C的向量;“激励”是指以“压缩”后的向量作为输入,用一个2层的全连接神经网络得到不同通道的权重。
本文选用SE-ResNet-50结构作为分类网络的主体,同时为了将视角特征与分类特征进行融合,在SE-ResNet-50特征提取结构后面额外增加了2个卷积层。在特征传播过程中,将视角特征与分类特征融合,额外增加的2个卷积层将结合2类信息对车辆特征作进一步抽象,从而实现对车型的精细分类。
2 实验结果与分析
2.1 数据集与实验环境
为验证VAR-NET模型对多视角车辆图像识别的准确性,本文在CompCars数据集上对模型进行了分类测试。CompCars数据集共包含52 083张431种车型的多视角车辆图像,包含车辆的视角、类别及包围盒等标签信息。本文使用其中的70%作为训练集,另外30%作为测试集。
实验环境如下:CPU为Intel Core i7-7700K;内存为16 GiB;显卡为Nvidia GTX 1080;显存为8 GiB。CUDA版本为9.0。
2.2 训练过程
(1) 使用ImageNet的1 000类数据预训练BN-inception网络和SE-ResNet-50网络。网络的输入图像尺寸设定为256×256,使用裁剪、镜像操作后每张图像得到10张224×224尺寸的图像。
(2) 将CompCars数据集图像缩放至256×256,进行裁剪和镜像操作,使用类别标签微调步骤(1)得到的BN-inception网络和SE-ResNet-50网络的权重。
(3) 在前2步训练得到的BN-inception后添加2个卷积层,构成视角预测网络的主体结构。由于坐标标签限制,不再将训练数据进行扩增,而仅将CompCars数据集缩放至224×224尺寸,使用图像的视角和位置标签对视角预测网络进行训练。
(4) 在SE-ResNet-50的网络结构中加入视角特征与分类特征加性融合的结构,完成分类网络。使用224×224尺寸的数据集对整个网络进行微调训练,训练时批次大小设置为32,初始的学习率为0.001,使用逐步降低的策略调整学习率,每20×104次迭代降低1次学习率,共计迭代60×104次。
2.3 实验结果分析
不同模型在CompCars数据集上的识别准确率对比见表1所列。表1中,top1表示排名为第1类的类别;top5表示排名在前5类的类别。
表1不同模型在CompCars数据集上的识别准确率%

对比模型 top1top5AlexNet模型[20]81.990.4OverFeat模型[21]87.996.9GoogLeNet模型[18]91.297.1ResNet-50模型[15]91.398.1SE-ResNet-50模型[19] 91.498.5BoxCars模型[22]84.895.4Location-Aware模型[23]94.398.9FR-ResNet模型[11]95.399.1VAR-NET模型95.499.1
由表1可知,AlexNet模型的准确率相比之下明显较低,top1的准确率为81.9%,top5的准确率为90.4%;OverFeat模型作为AlexNet模型改进后的模型,准确率相比于AlexNet模型有很大的提高,top1、top5的准确率达到了87.9%、96.9%,但是相比于其他方法仍存在着差距,可见网络深度对模型分类性能有较大的影响;GoogLeNet模型为加宽和加深网络而引入了inception结构,提升了模型的分类性能,top1、top5准确率分别达到了91.2%、97.1%;ResNet-50模型中创新性地引入了残差结构,很好地解决了深度网络的退化问题,top1准确率与GoogLeNet模型相当,top5准确率达到了98.1%;SE-ResNet-50模型在ResNet-50模型的基础上加入了“压缩”和“激励”2种结构,其top1、top5准确率与ResNet-50模型的准确率持平;BoxCars模型未将车辆视角信息纳入考虑范围,top1、top5准确率分别为84.8%、 95.4%;位置感知多任务深度学习框架(location-aware multi-task deep learning framework,Location-Aware)模型采用先定位后分类的策略,在车型识别任务上达到了较高的识别率,其top1、top5准确率分别达到了94.3%、98.9%,由此可见车辆的位置信息对于精细分类任务有着很好的辅助作用;基于残差网络特征重用(feature reuse residual network,FR-ResNet)的深度卷积神经网络模型采用了多尺度输入、特征重用及特征图权重学习3种策略,减轻了冗余信息的干扰,将车型识别top1、top5准确率提高至95.3%、99.1%,该方法专注于网络特征的有效利用,而忽略了车辆图像中存在的位置与视角信息;本文VAR-NET模型既用到了位置信息,又用到了视角信息,top1准确率达到了最高,为95.4%,top5准确率与上述方法最优准确率相当,可能达到了CompCars数据集的瓶颈。随着分类网络的进一步发展,可以将VAR-NET模型中的分类子网络灵活地替换为更加先进的网络,进一步提升VAR-NET模型的识别准确率。
VAR-NET模型在CompCars数据集上识别的混淆矩阵如图3所示。由图3可知,所得混淆矩阵基本呈一条对角线,说明大部分的分类结果是正确的,但是其中仍然存在一些噪点,即错误分类的情况。
VAR-NET模型、ResNet-50模型、SE-ResNet-50 3个模型在CompCars数据集上的受试者工作特征(receiver operating characteristic,ROC)曲线如图4所示。
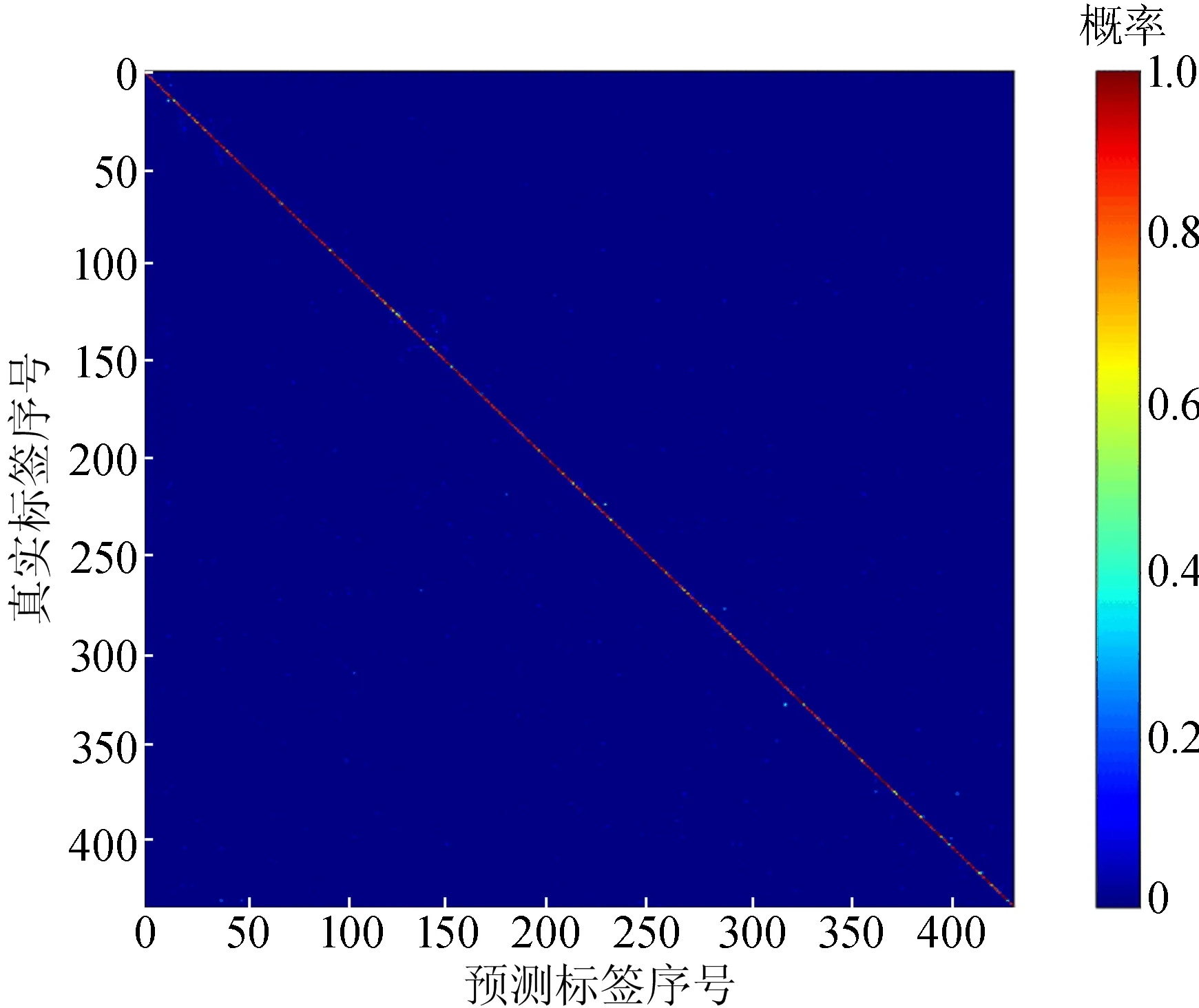
图3 VAR-NET模型在CompCars数据集上识别的混淆矩阵

图4 3个模型在CompCars数据集上识别的ROC曲线
从图4可以看出,VAR-NET模型的分类效果更加靠近左上角,表明VAR-NET模型相比于其他2个模型能够更加有效地实现车辆精细分类。车型的精细识别在现实场景中的应用十分广泛,不同场景下对车型识别的性能要求侧重不同,比如在对违法车辆的侦察任务中要求模型具有较高召回率,避免遗漏犯罪车辆,而针对交通流量的统计和管理任务,要求其具有较高的精确率。3个模型在CompCars数据集上识别的精确率和召回率见表2所列。由表2可知, VAR-NET模型的精确率和召回率都是最好的。

表2 3个模型在CompCars数据集上的精确率和召回率%
为进一步验证本文VAR-NET模型的可迁移性,在Stanford Cars数据集上进行了对比实验。Stanford Cars数据集中包含16 185张196种车型的车辆多视角图像,采用其中的8 144张图像作为训练集,其余的图像作为测试集。由于Stanford Cars数据集中只包含车辆的类别标签和包围盒标签,不包含车辆的视角标签,因此在使用CompCars数据集训练VAR-NET模型的基础上,固定视角预测网络的特征权重,仅使用Stanford Cars数据集的类别标签针对分类网络进行微调,实验结果表明,top1、top5识别准确率分别为86.45%、 97.07%。4种模型在Stanford Cars数据集上的识别准确率对比见表3所列。从表3可以看出,虽然没有使用视角信息和包围盒信息针对视角预测网络进行微调,本文VAR-NET模型依然取得了最好的分类精度。

表3 4种模型在Stanford Cars上的准确率 %
3 结 论
本文研究了复杂背景下多视角车辆的精细分类问题,提出了视角相关的卷积神经网络模型(VAR-NET模型)。VAR-NET模型强调了视角相关信息对车辆精细识别的重要性,利用YOLO网络获取车辆图像的视角特征,通过将视角特征与分类特征进行加性融合,来增强有利于精细分类的特征。实验结果表明,VAR-NET模型在多视角车辆型号的精细识别任务上性能优异。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中国交通信息化(2018年5期)2018-08-21 03:37:40
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
数学物理学报(2017年5期)2017-11-23 07:51:31
