
基于卷积神经网络的垃圾图像分类算法①
2020-03-22 07:42董子源韩卫光
计算机系统应用 2020年8期
董子源,韩卫光
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
1 引言
垃圾回收利用作为发展循环经济的必经之路,是根治污染、提高环境治理效果的关键所在.随着我国生产力水平的发展,生活垃圾、工业垃圾数量不断增加,困扰着很多城市.据统计,仅2018年,中国垃圾的清运量已经达到了2.28 亿吨[1].在人们将垃圾投放进垃圾箱之后,垃圾被运送到垃圾处理厂统一处理.当前国内的垃圾处理厂,更多依靠人工在流水线上作业去分拣垃圾,对作业者健康不利且分拣效率较低,已不能满足大量垃圾处理需求.此外,人工分拣的垃圾种类极为有限,大部分垃圾无法重新回收利用,造成很大浪费.随着深度学习技术的发展,卷积神经网络使图像分类算法在精度和速度上得到了巨大的提升,让我们看到了借助视觉技术自动分拣垃圾的可能性.通过摄像头拍摄垃圾图片,利用卷积神经网络检测出垃圾的类别,之后就可以借助机械手或推板自动完成分拣任务,可以降低人工成本,提高分拣效率.因此,开展垃圾图像分类算法的研究,具有重要的应用价值.
2 相关工作
早期,学者们只能借助经典的图像分类算法[2–5]完成垃圾图像分类任务,这要通过手动提取的图像特征并结合相应的分类器完成.吴健等[6]利用颜色和纹理特征,初步完成了废物垃圾识别.由于不同数据集的图像背景、尺寸、质量不尽相同,传统算法需要根据相应数据人工提取不同的特征,算法的鲁棒性较差,并且处理方式复杂,所需时间较长,无法达到实时的效果.随着卷积神经网络(Convolution Neural Network,CNN)的飞速发展,深度学习广泛应用于图像识别领域.作为数据驱动的算法,CNN 具有强大的特征拟合能力,可以有效、自动地提取图像特征,并具有较快的运行速度.2012年,AlexNet[7]取得了ImageNet 图像分类竞赛的冠军,标志着深度学习的崛起.随后几年,GoogleNet[8]、VGGNet[9]、ResNet[10]等算法提升了图像分类的精度,并成功应用于人脸识别、车辆检测等多个领域.垃圾图像分类,在深度学习算法的帮助下同样取得了较大的突破.斯坦福大学的Yang 等建立了TrashNet Dataset 公开数据集,包含6 个类别,共计2527 张图片.Ozkaya 等[11]通过对比不同CNN 网络的分类能力,搭建神经网络(本文称之为TrashNet)并进行参数微调,在数据集TrashNet Dataset 上取得了97.86%的准确率,是目前这一数据集上最佳分类网络.在非公开数据集方面,Mittal 等[12]自制了2561 张的垃圾图片数据集GINI,使用GarbNet 模型,得到了87.69%的准确率.国内方面,郑海龙等[13]用SVM 方法进行了建筑垃圾分类方面的研究.向伟等[14]使用分类网络CaffeNet,调整卷积核尺寸和网络深度,使其适用于水面垃圾分类,在其自制的1500 张图片数据集上取得了95.75%的识别率.2019年,华为举办垃圾图像分类竞赛,构建了样本容量为一万余张的数据集,进一步促进了该领域的发展.
我国各地区生活垃圾分类标准有所不同,大致可分为可回收垃圾、有害垃圾、厨余垃圾和其他垃圾这4 大类,且每个类别下又包含若干子类别,种类繁多且十分复杂.按照这样的分类标准做的垃圾图像识别研究,国内目前还处于起步阶段.现有的图形分类算法在垃圾处理领域的应用较少,且存在准确率不足、泛化性能差、处理效率低的缺点.针对现有方法的不足,本文提出一种基于卷积神经网络的垃圾图像分类算法(Garbage Classification Net,GCNet),在网络结构中融合了注意力机制模块与特征融合模块,提高了模型在垃圾分类任务上的准确性与鲁棒性.
3 算法设计
3.1 模型结构
本文构建的GCNet 模型包括特征提取器、分类器两部分,整体结构如图1所示.图中特征提取器由Resnet101 作为主干部分,共包括5 个bottleneck,并在不同的bottleneck 后加入注意力机制模块,同时对不同模块提取到的特征进行特征融合(如图1中虚线所示)以从输入x中提取图像的特征信息F1:

其中,Me表示特征提取器.
分类器由两层全连接层和一个Softmax 分类器组成,对提取到的特征信息F1进行分类,以得到图像在每个类别下的最终得分yi:
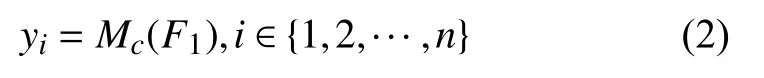
其中,Mc表示分类器.
3.2 注意力机制
注意力机制源于对人类视觉的研究,人类会根据实际需要选择视网膜内特定区域进行集中关注,可以将有限的处理资源分配至重要的部分.由于相同类别垃圾的特征表征差异性可能较大,不利于图片的正确分类,这就要求准确地关注图像中的显著区域.受这一思想的启发,通过构建注意力机制模块,使网络模型重点关注有利于分类的特征区域,以实现更好的特征提取功能,其具体结构如图2所示.
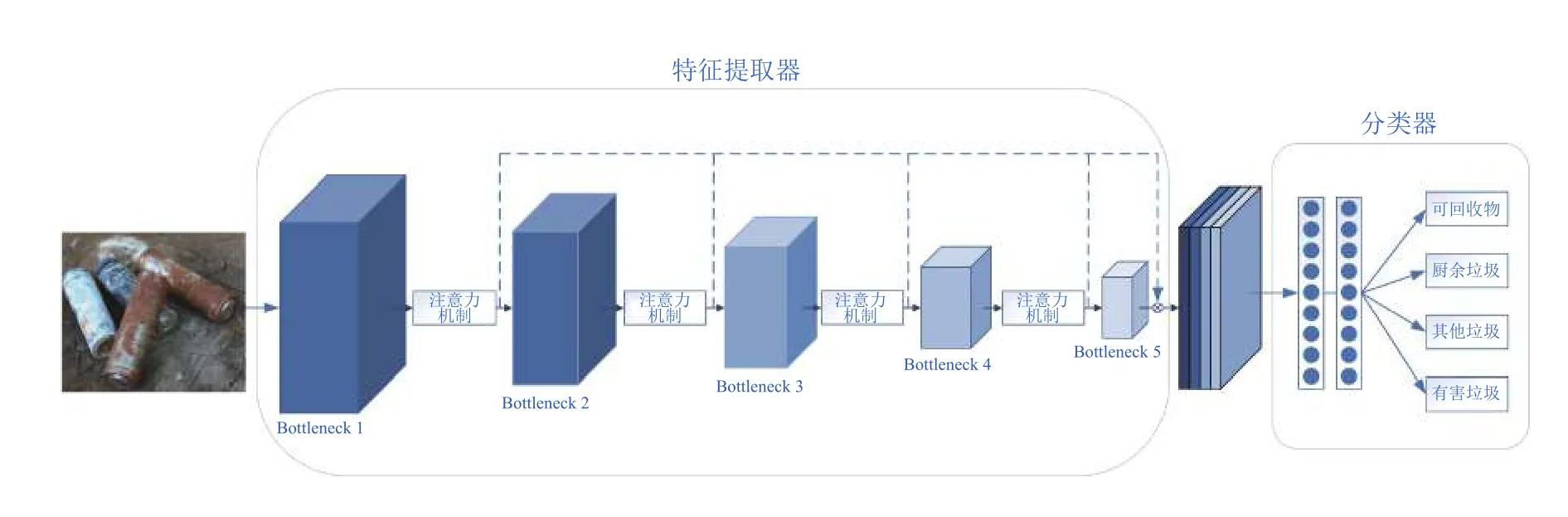
图1 GCNet 网络结构图
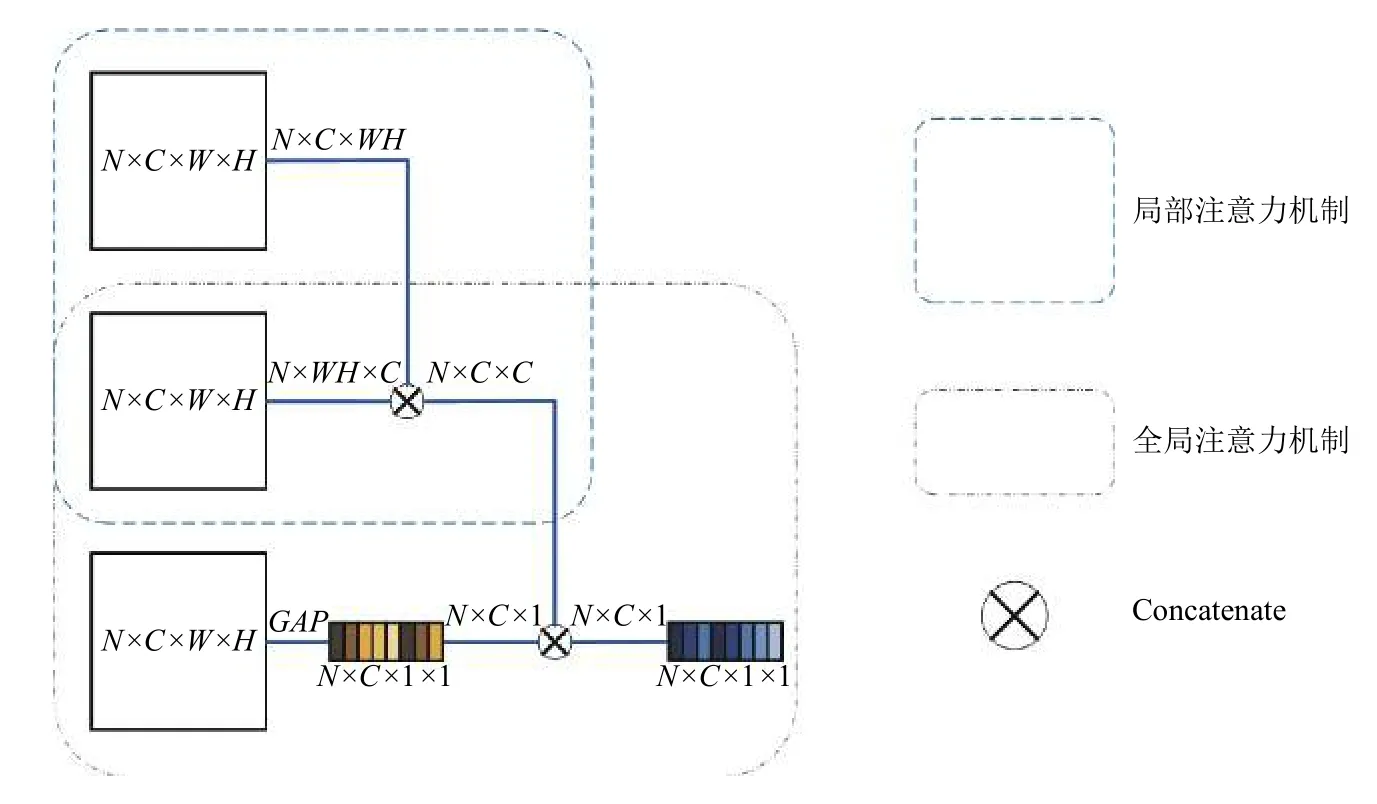
图2 注意力机制示意图
将每个bottleneck 提取到的特征以Fi表示,其大小为N×C×W×H.利用格拉姆矩阵[15]构建局部注意力机制模块,将Fi与其转置相乘,获得大小为N×C×C的局部特征:

该操作可以获得特征图中每个元素自身间的关联,使原本数值较大的元素越大、数据较小的元素越小,即凸显每个局部的重要程度,使有助于判断类别的特征更加明显,同时抑制影响判断的特征.
随后,对Fi进行全局平均池化操作(Global Average Pooling,GAP)[16],可以保留特征Fi提取到的空间信息和语义信息,并获得大小为N×C×1×1的全局特征:

代 表了特征Fi中最显著的特征,这也符合所定义的全局注意力机制.
最后,将局部特征与全局特征相乘,从而获得包含局部和全局信息的总体特征:

3.3 特征融合机制
垃圾分类任务中,从属于同一类别的垃圾往往差异性较大,如可回收物中包括的纸板箱和玻璃杯,二者存在较大的外观差异但却属于同一类别,这会给分类器的判别增加一定的难度.此外,随着网络层数的加深,单一的图像特征会丢失某些区域的信息,从而导致模型的分类性能变差.针对这一问题,常用的方法是通过不同卷积核的池化操作构建多尺度的特征融合模块,但这种操作会增大模型的运算量,同时也会使模型训练更加困难.
由于构建的特征提取器中包含了不同的池化操作,因此只需要提取不同bottleneck 下的特征便能获得不同尺寸的特征.在此基础上,本文提出了改进的特征融合机制,如图1中的虚线所示,将每个bottleneck 经过注意力机制后所提取到的总体特征进行融合:

其中,wc为1×1的卷积核,bc为偏置,Concat表示融合操作.该操作旨在利用不同尺度的特征信息,避免信息的丢失,进一步提升模型的鲁棒性.
4 实验及结果分析
4.1 实验平台
本文实验在Ubuntu16.04 系统下,利用Python 语言,Pytorch 深度学习框架完成.硬件环境为CPU Intel I7-9700K,内存32 GB,显卡Nvidia GeForce RTX 2080Ti.
4.2 实验数据
本文采用华为垃圾分类挑战杯数据集,该数据集已全部标注类别,包括厨余垃圾、可回收物、其他垃圾和有害垃圾4 个大类,每个大类下又包含若干子类别,合计40 个小类别,共计14 683 张图片.
在实验中,采用4:1的比例划分数据集,80%作为训练数据,20%作为测试数据.此外,为了增强模型的泛化能力和鲁棒性,还对训练样本进行了数据增强操作,包括随机旋转、随机翻折、随机裁剪等.
4.3 结果分析
实验选用ADAM[17]优化算法训练模型,动量系数为0.9,共设置50 个迭代周期,初始学习率设置为0.01,每隔10 个迭代周期学习率衰减0.1 倍,一阶矩估计的指数衰减率为0.99,二阶矩估计的指数衰减率为0.999.此外,使用交叉熵损失函数来训练优化模型.
在训练过程中,对GCNet 模型通过消融实验以分别验证注意力机制和特征融合机制的功能.实验1(Experiment_1)为含有注意力机制和特征融合机制的模型,实验2(Experiment_2)为只含有注意力机制的模型,实验3(Experiment_3)为只含有特征融合机制的模型,实验4(Experiment_4)为不含有注意力机制和特征融合机制的模型.各个实验的训练过程迭代曲线如图3所示.

图3 GCNet 训练过程曲线
从图3中可以看到,实验1的准确率提升与损失值下降都快于其他3 个实验,说明训练过程收敛更快.实验2和实验3的速度几乎相近,而实验4的速度最慢.为了进一步验证上述训练的准确性,在对应的测试集上进行测试,实验结果如表1所示.包含注意机制模块和特征融合模块的实验1 取得了96.73%的最优准确率,同时在各个子类别上均取得了最高的准确率,说明本文构建的模型泛化能力较好.在类内差异性较大的“其他垃圾”这一类别中,注意力机制和特征融合机制均能够显著提高模型的准确率.
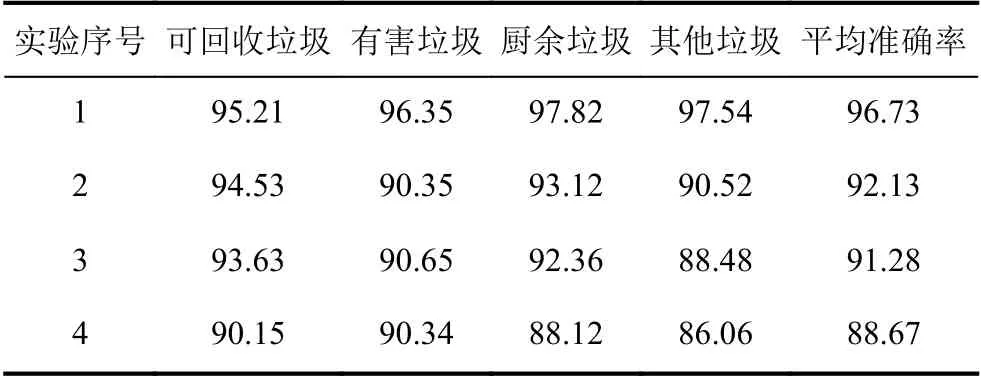
表1 GCNet 模型消融实验准确率对比(单位:%)
本文模型与其他模型的准确率对比结果如表2所示.可以看出,本文构建的GCNet 平均准确率最高,在各个类别中也取得了最高的准确率,说明本文构建的注意力机制和特征融合机制充分提取了有利于图像分类的特征,使得分类结果更加准确.TrashNet的平均准确率略差于GCNet,而CaffeNet 结果最差.
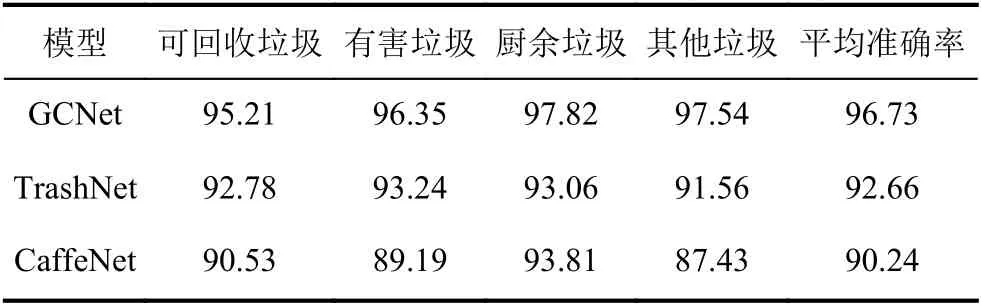
表2 不同模型实验准确率对比(单位:%)
图4为3 种算法GCNet,TrashNet和CaffeNet 对同样4 张图片的测试结果,显示了预测类别以及属于这一类别的概率.GCNet 在各个类别的样例中,也取得了最好的结果.特别是在第4 幅(其他垃圾)的测试中,由于该类别的图像类内差异过大,CaffeNet 将其识别为其他垃圾的概率仅为62.75%,将其错误地识别成有害垃圾的概率却高达35.61%,在某些干扰情况下,这可能会导致判定错误,对分类结果造成较大影响.本文算法成功的改进了这一问题,确保了在较难分辨的类别上的准确率.

图4 各模型测试结果对比图
5 结论
本文针对垃圾图像分类问题,构建了一种基于卷积神经网络的算法GCNet,该网络通过构建注意力机制和特征融合机制,能够有效地提取图像特征、降低类别差异性带来的影响,并在相关数据集上取得了96.73%的平均准确率,相较于现有的分类算法提升了约4%的准确率,满足了实际的应用需求,具有良好的应用前景.
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
少儿科学周刊·少年版(2015年3期)2015-07-07
