
基于CTD-BLSTM的医疗领域中文命名实体识别模型①
2020-03-22 07:42:14祝锡永
计算机系统应用 2020年8期
祝锡永,吴 炀,刘 崇
(浙江理工大学 经济管理学院,杭州 310018)
随着医疗百科、医疗健康知识问答等平台的发展以及医疗信息管理系统、电子病历档案在医疗单位中的广泛应用,涌现出大量、多源、冗余并且内容分散的网络医疗数据.针对这些的海量医疗信息中的数据,如何高效识别、整合其中的知识实体对搭建医疗知识图谱、提供精准的医疗知识问答和进行医疗知识推理等具有重要的研究意义.由于大部分的医疗数据为非结构化数据,这类数据的组织结构虽然能比较方便地表达一些医疗事件和概念,但在医疗信息统计、知识整合与知识图谱的构建等方面带来很大不便,因此挖掘和抽取其中的医疗信息成为一项重要任务.命名实体识别(Name Entity Recognition,NER)是一项从给定的一段文本中抽取出诸如人名、物名、机构名等实体的基础技术,是挖掘和抽取非结构化数据中信息的首要步骤.
医疗领域的中文命名实体识别不同于开放领域的中文命名实体识别,文本中的实体单元不再是人名、地名等,而是诸如疾病名、临床症状、药名等实体.例如,“核磁共振结果显示患者脊柱内有胶质瘤”中“胶质瘤”就是疾病名称;“患者逐渐肌肉萎缩”中“肌肉萎缩”就是临床症状;“静脉注射硝苯吡啶控制”中“硝苯吡啶”就是药品名称.这些疾病名称、临床症状以及药品名称实体反映了患者的疾病情况以及治疗手段.医疗领域的中文命名实体识别最主要的任务就是识别文本中的专业术语,为医疗领域信息的抽取、检索以及构建问答系统等提供支持.但目前中文医疗标注语料数据缺乏,并且中文中词与词间没有明显的边界,相较于英文命名实体识别来说更加困难,为应对该情况,本文提出一种面向医疗领域的高效中文命名实体识别模型:基于协同训练半监督方法的双词向量双向长短期记忆神经网络算法(Co-Training Double word embedding conditioned Bi-LSTM,CTD-BLSTM).
1 相关研究
早期的命名实体识别主要是针对开放领域,但近年来,越来越多的学者关注到了特定领域,例如医疗领域.与开放领域的命名实体识别一样,早期医疗实体识别也是通过领域专家和语言学家手工制定规则的方法,比如国外著名的电子病历命名实体识别系统MedKAT(Medical Knowledge Analysis Tool)和cTAKES (Clinical Text Analysis and Knowledge Extraction System),但该类方法的构建需要掌握大量语言学知识,并且对于不规范语料处理效果也不理想,具有很大的局限性.随后,由于标注语料的增加,医疗实体识别也渐渐开始运用传统机器学习和词典规则相结合方法的方法.Murugeasan等[1]提出的BCC-NER 方法在BioCreative II GM 语料库中对基因的识别取得了较好的成果;张金龙等[2]则将筛选规则与外部上下文特征结合入CRF 中,使得模型对中文医疗机构实体体现了显著的识别效率.除此之外,Lei JB 等[3]将中文临床病历作为主要研究对象,分别采用了最大熵、CRF、SVM、结构化的SVM 等4 种方法对医疗实体进行识别,其中结构化的SVM 识别效果最佳,使病程记录和出院小结的F 值达到90%以上.
然而上述方法大多是以机器学习为基础结合词典或规则等构建模型,需要完成繁重的规则构建、设定特征与标注语料等预先工作.近年来,随着深度学习的发展与具有提取自我特征的特性,出现了大量基于神经网络的模型用于完成命名实体识别任务,神经网络方法在命名实体识别方面表现出更强的泛化性和更低的特征工程依耐性[4],减少特征提取所需代价,有效地提高了模型对实体识别的效率.Liu 等[5]通过设计多组对照组对I2B2 数据集中英文电子病历进行实验,得出LSTM 模型的识别效果优于CRF 模型;Almgren 等[6]提出一种基于字符的深度Bi-LSTM的医疗实体识别模型,其F 值比经典模型高出60%;Xu 等[7]将Bi-LSTM与条件随机场进行结合用于医学命名实体识别,实验结果该BLSTM-CRF 模型优于两者单一模型.目前大多数实体识别任务均以BLSTM-CRF 模型进行,但医疗领域的中文命名实体任务复杂,医疗领域标注语料不足和中文分词困难等都会影响模型准确率,如杨红梅等[8]利用BLSTM-CRF 模型对中文电子病历实体进行识别,其中出院小结的识别率偏低.
总结上述研究及难点,本文在双向长短期记忆网络的基础上,通过双词向量扩展BLSTM 神经网络结构,并结合协同训练协同学习方法,最终构建出一种基于协同训练半监督方法的双词向量双向长短期记忆神经网络算法(CTD-BLSTM),用以提高中文医疗命名实体的识别效率.
2 基于CTD-BLSTM的命名实体识别
2.1 Bi-LSTM 神经网络
自然语言处理(NLP)中的命名实体识别是典型的文本序列标准问题,而循环神经网络(RNN)能有效地解决序列标注任务,但处理长序列数据时可能会发生梯度消失或梯度爆炸等现象,为此在长短期记忆网络(LSTM)中通过引入“门”限制机制解决这一问题.此外,由于在实体识别中不仅需要当前词的上文信息,也需要下文信息,因此本文选择在能同时包含上下文的信息[9]的双向长短期记忆网络(Bi-LSTM)的基础上提出一种新的模型算法改进.Bi-LSTM 输入层中包含2 个方向相反且相互独立的LSTM,输出层结果包含了2 个LSTM的结果,这种方式保证了整个Bi-LSTM是非循环的,并且使得整个网络能兼顾上下文信息并自动提取句子特征,从而获取更好的特征信息.
2.2 双词向量扩展BLSTM (D-BLSTM)
词向量在Bi-LSTM 网络中训练的过程中进行不断微调可以包含更多有用的信息,但与此同时也会逐渐丢失原本的句法与语义等特征,针对这种情况,本文参照双词向量卷积2E-CNN 模型[10],利用预训练的词向量与微调后的词向量对神经单元结构进行扩展,提出一种双词向量BLSTM 神经网络算法(Double word vector conditioned BLSTM,D-BLSTM)[11],将两种词向量同时作为BLSTM 网络的输入进行训练,其网络模型结构如图1所示.
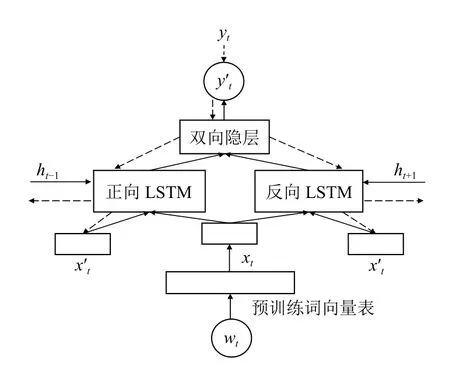
图1 双词向量扩展的BLSTM 网络模型图(D-BLSTM)
通过预训练的词向量表,对语料中的单词wt进行唯一向量化表示,将其作为输入词向量xt和x't的初始值进行训练,在整个模型的训练过程中保持预训练词向量xt不变,对x't不断进行微调,每个时刻都有xt、x't和ht–1等3 个变量输入LSTM 神经单元,其单元内输入门、遗忘门、输出门的计算公式见式(1)至式(3),存储块更新的计算公式见式(4).

2.3 融入半监督框架的协同训练
为解决医疗领域标注语料稀缺的问题,在D-BLSTM中引入半监督学习方法,协同训练(co-training)是一种非常广泛使用且有效的半监督学习框架[12],该方法将大量未标注语料加入到少量已标注语料库中,并反复训练从而得到识别能力良好的模型,但必须将语料集自然分割成两个在给定条件下相互独立的特征集,并且由特征集训练的两个模型都是有效的[13],训练步骤如下:
(1)提出两个相互独立特征集,并对两者的算法模型进行构建;
(2)分别使用两个特征集中少量已标注语料对模型进行训练;
(3)将未标注的语料分别输入两个模型中进行标注预测,并对预测结果进行置信度评价;
(4)挑选若干置信度(即对未标注语料赋予正确标记的置信度)高的样本加入到另一方模型的训练语料库中,用扩充后的语料库重新对模型进行训练;
(5)重复上述步骤(3)、(4),直至达到设定条件要求.
协同训练半监督学习方法可以在医疗领域已标注语料不充足的情况下大大提高模型实体识别的性能.
2.4 基于协同训练的D-BLSTM (CTD-BLSTM)
本文在D-BLSTM 算法中引入协同训练半监督学习方法,最终构建出一种结合协同训练的双词向量BLSTM 神经网络算法(CTD-BLSTM),其流程如图2所示.

图2 CTD-BLSTM 算法流程示意图
(1)根据实体识别任务具体场景,选择两个独立的特征并制定相应特征模板;
(2)将采集的文本语料进行少量标注,并依据两套不同的特征模板整理出训练集;
(3)用两套语料训练集训练得到两个不同的D-BLSTM模型,并分别用其对各自未标注语料进行标注;
(4)将标注的预测结果进行置信度评价,并与设定的阈值进行对比,若置信度高于阈值,则将语料加入到对方的训练语料中,同时迭代计数加1;
(5)循环执行步骤(3),直到两个模型对未标注语料标注结果基本一致,或用尽测试集中未标注语料,或达到预先设定的循环次数.
3 实验
3.1 实验数据
为验证CTD-BLSTM 算法对医疗领域实体的识别提取效果,本文通过爬取如寻世界医疗网、健康大全网、好大夫在线网等医疗网站中的药物信息、疾病信息以及医患问答信息,经整理后得到上述3 种信息的有效数据分别为2665 条、7359 条和157 090 条.
由于需要将数据以基于词典的形式进行分词标注,实验过程选取搜狗细胞词库中的“医学词汇大全”作为基础词典,并通过爬取百度百科中“药理学”、“疾病”、“解剖学”、“传统医学”、“卫生保健”等几个与医疗领域相关标签内的词条来进一步扩充词典,最终对两者进行对齐、消歧、合并等操作共得98 647 条词条.
3.2 特征选择
协同训练半监督学习方法需建立两个相互独立的特征集,Chen 等[14]提取分词、词性等特征完成临床命名实体识别任务,得到选取分词特征和词性特征作为训练特征识别效果最佳;Peters 等[15,16]将上下文窗口的特征融入基于预训练的BLSTM-CRF 语言模型中,提高已有模型的效果,因此本文选用上下文窗口特征与词性特征作为两个相互独立的特征构建特征集.
考虑到研究主体为医疗领域文本内的中文实体,本文参考中文电子病历词性标注规范[17]将爬取的数据定义为“症状”、“部位”、“药品”、“疾病”、“检查”、“科室”与“治疗”7 类实体,词性标注见表1.

表1 扩展词性标注表
在词性特征的构建上,首先需构造词性表D={d1,d2,d3,…,dn}(di表示一个词性,i∈[1,n]),并构建每个词的词性特征向量V={v1,v2,v3,…,vn}(vi代表该词词性是否对应词性表D中的di),假设某词的词性为nhd,则该vi的取值见式(5),计算后求得该词的特征向量.
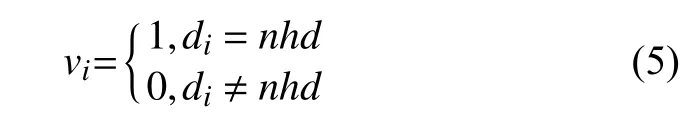
在设置上下文窗口特征时,为提取当前词的前后两个词,将窗口大小设为5,对每个词建立词性特征向量以及词特征向量,并将不存在的上文窗口词与下文窗口词设为空值.以“患者之前有低血糖病史,有高血压病史啊”为例,上下文窗口处理过程见表2.注:通过删除语句中如“吗”、“吧”、“啊”等语气词以及一些数词或状态词来提升运行效率.

表2 上下文窗口处理过程

表3 实体标注实例
3.3 实验测评
待选定特征向量后,采用CTD-BLSTM 算法完成命名实体识别.首先通过上文构造的词典对少量语料中实体进行O-S-B-I-E 标注,然后再经人工进行审查与修正,标注实例见表3.
待实验语料标注完毕后,将数据中70%作为训练集分别对基于词性特征的CTD-BLSTM 模型和基于上下文窗口特征的CTD-BLSTM 模型进行迭代训练,30%作为测试集对模型进行检验,并将模型训练迭代次数设为40 次.实验得到的模型性能变化如图3和图4所示,观察可得两个模型的F 值、准确率和召回率均随迭代次数的增加呈上升趋势,证实了CTD-BLSTM算法的有效性.

图3 基于词性特征的CTD-BLSTM 模型

图4 基于上下文窗口特征的CTD-BLSTM 模型
为进一步验证CTD-BLSTM 模型对实体的识别效果,随机抽取数据集中5000 条数据进行标注作为模型的训练集,并用20000 条数据对模型进行训练.除此之外,并用5000 条数据和25000 条数据分别对BLSTM、BLSTM-CRF与D-BLSTM 模型进行训练得到12 个对照模型组,实验结果见表4所示.
从表4中可以得出以下结论:
(1)上下文窗口特征比于词性特征包含更多信息,因此在实验阶段其模型识别率有显著的提高.
(2)对比特征与规模大小相同训练集下的模型,得出D-BLSTM 模型性能优于基础的BLSTM 模型,证明了利用双词向量进行扩展的有效性.例如,对比模型7和模型11,模型的F 值从原来的88.43%提升到了90.41%,并且由于精简了数据集,模型的性能比原来提高了25%左右,能做到快速且准确的实体识别.
(3)对比模型3、5、9、11、13,发现协同训练方法的引入使得改进模型CTD-BLSTM 在准确率、召回率及F 值上虽略低于用25000 条数据训练的D-BLSTM模型与BLSTM-CRF 模型,但其识别效果明显高于经5000 条数据训练的D-BLSTM 模型与BLSTM-CRF 模型,体现引入协同训练半监督学习方法是有效的,并在一定程度上大大减少了语料的标注工作.

表4 实体识别模型对比测评结果(单位:%)
4 结论与展望
本文针对医疗领域的中文命名实体识别任务进行了研究.为了提高实体识别效果,在双向长短期神经网络的基础上,用预训练词向量和微调词向量对神经网络结构单元进行扩展,并引入协同训练学习方法,最终提出了CTD-BLSTM 模型.经过实验证明,改进后的模型在准确率、F 值和召回率上均有明显提高,是一个适用于医疗领域的中文命名实体识别模型.
本文选择词性特征与上下文窗口特征构建相互独立的特征向量集对CTD-BLSTM 算法模型进行训练,而可选的特征不仅仅限于词性特征与上下文窗口特征,因此,在未来的研究中,需要进一步测试不同特征模板的选择对模型效果的影响.此外,我们将进一步检测此模型在其它特定领域的效果,来探索此模型算法对不同领域的适用性,以进一步提高识别准确率,获得更精准的实体识别结果.
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
中国外汇(2019年18期)2019-11-25 01:41:54
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
