
基于模型的Web应用二阶SQL注入测试用例集生成①
2020-03-22 07:42:06王维扬
计算机系统应用 2020年8期
尤 枫,王维扬,尚 颖
(北京化工大学 信息科学与技术学院,北京 100029)
1 引言
在21 世纪,互联网上各种Web 应用随处可见,它们在为我们提供便利服务的同时也带来了不同程度的安全隐患.相较于传统应用,Web 应用因其开发快捷,部署方便,易于使用等优点被众多企业所青睐,但也因此具有更多的安全问题.2013年的一篇报导指出在2012年约有22%的网站遭受了安全攻击[1].SQL 注入漏洞是一种常见Web 安全漏洞,在最近几年更是成了影响Web 应用安全的主要漏洞之一[2,3].虽然一些脚本语言(如PHP,Java)通过提供参数化的方法来避免这种漏洞,但是由于一些历史以及教育上的因素[4],这些漏洞还在持续的增加.
SQL 注入漏洞可分为两类,一阶SQL 注入漏洞和以二阶SQL 注入漏洞为代表的多阶SQL 注入漏洞[5].二阶SQL 注入漏洞相比于一阶SQL 注入漏洞,其注入路径更加曲折,隐蔽性远高于一阶SQL 注入漏洞,这使得其更加难以检测,且由于恶意数据会被持久性存储,所以其造成的影响更加恶劣[6].
2004 年二阶代码注入攻击概念被首次提出[7].在之后的几年里,尽管对一阶代码注入漏洞的相关研究得到了许多成果,但是对二阶代码注入漏洞的研究却进展缓慢.2010年,Bau 等对当时主流的黑盒测试工具进行评估,发现它们并不能检测出程序中的二阶代码注入漏洞[8].目前针对二阶SQL 注入漏洞的检测主要是采用白盒与灰盒的测试方法,即基于程序的源码信息来检测漏洞,如文献[9–11]中提出的方法.文献[9]使用对程序源码进行静态分析,获取污点传播路径,将这样一条数据注入点到触发点的路径认定为程序的漏洞.文献[10]在文献[9]的基础上将程序源码的语义分析与数据的存储状态分析相结合,以此来找到二阶代码注入漏洞的污点传播路径,并将这种路径认定为二阶代码注入漏洞.在文献[11]中,闫璐等针对二阶SQL 注入漏洞提出了一种静态分析与动态测试相结合的检测方法,该方法通过静态分析找到源码中可能存在二阶SQL 注入漏洞的SQL 语句和列名,然后通过提交HTTP 请求的方法验证漏洞.该方法有效地利用了程序内部信息来提高动态测试的准确性,同时也利用了动态测试的特性降低了静态分析的误报率.这种基于静态分析的漏洞检测方法,往往依赖于静态分析工具设计人员的先验知识,这就导致在面对具有简单内部逻辑的应用时,静态分析往往能表现出很好的效果,但是在复杂的Web 应用上的表现却不尽如人意.如今的Web 应用大多使用面向对象的设计思想,大量使用第三方框架以及参数化的数据库操作,使得现有的白盒与灰盒测试方法很难对这些特性进行分析.
黑盒测试是一种在任何Web 应用上都适用的测试方法,其针对大规模代码单元的测试效率要远高于白盒测试,且在某些场景下测试人员只能采用黑盒的测试方法.但由于对其研究的复杂性,目前对该领域的研究成果较少,还没有一种能够可靠且高效检测二阶SQL注入漏洞的方法.虽然文献[12]提出了一种基于页面爬虫的二阶代码注入漏洞检测方法,该方法对被测网站进行两次爬取,第一次用于获取页面URL 并设置不同类型锚点,第二次则只针对具有存储锚点的页面进行爬取,来达到触发漏洞的目的.但该方法并未有效地利用二阶SQL 注入漏洞的特点,作者虽然表明该方法能够检测出二阶SQL 注入漏洞,但是在漏洞检测效果方面却并未给出更多的实验结果.随着模型语言(如UML)、模型驱动技术(MDA)和形式化验证技术的逐步成熟,以及以测试为中心的软件开发技术与方法的兴起和应用,基于模型的软件测试在学术界和工业界得到越来越多的重视,已成为自动化测试的一个重要研究方向.其中基于模型的Web 应用软件的测试方法,目前在国内外已有一些研究与进展[13],通过Web 应用模型来生成测试用例是十分高效的且有较好的预期.
本文利用Web 应用的前端模型,通过对二阶SQL注入漏洞与前端模型之间关系的深入分析,提出了一种基于客户端行为模型的测试用例集生成方法(CBMTG),该方法能够高效地生成检测二阶SQL 注入漏洞的测试用例集.
2 相关技术
2.1 基于CBM的测试用例
在Web 2.0 时代,Ajax 技术被大量应用到Web 应用中,而针对Web 应用漏洞的攻击是可能发生在这种Ajax 请求之中的.传统的Web 应用模型无法准确的对这种Web 应用中的动态行为进行建模,在本课题组之前的相关研究中,以Web 应用的DOM 结构为基准提出了一种Web 应用的客户端行为模型(CBM),该模型能够准确的描述Web 应用的客户端行为[14].
客户端的行为模型表示为一个4 元组
对Web 应用CBM 模型的建立在文献[14]中有详细描述,如图1所示展示了一个简单的CBM 模型,其中每一个节点表示一个S中的状态,有向边ti表示T中的一个迁移,为了表述方便图中隐去了ti的细节.

图1 CBM 模型
在针对Web 应用的自动化测试领域,测试用例通常是指一系列的用户操作的集合,而CBM 中的每一个迁移,都对应于一次用户操作,故如果一个Web 应用的CBM 模型为M=
在本文的研究中,为了降低生成测试用例复杂程度,规定CBM 一定包含两个状态节点start和exit,分别表示Web 应用的起始状态和终止状态.Start 状态一般是指Web 应用的主页或者登录页面等;exit 状态可以表示用户登出之后的页面,也可能表示一个虚拟状态,指用户已经停止操作.故在本文中,测试用例是指一个在CBM 中使得状态从start 转移到exit的一个迁移集合,并将其称为从start 到exit的一条路径.例如,在图1中,t3,t5,t4,t8这4 条迁移构成的从start 到exit的路径表示一个测试用例.
2.2 Web 应用二阶SQL 注入攻击
在一阶SQL 注入的情景下,用户输入的恶意变量被直接拼接到SQL 查询语句中并更改正常的SQL 语句逻辑.而在二阶SQL 注入情形下,注入过程被分为两个阶段,首先用户输入的恶意变量会先被存入数据库中,然后在用户进行第二次请求时,之前存入数据库或文件系统的恶意变量被取出,并被用于构造另一条SQL 语句,此时该SQL 语句的正常逻辑被更改.如代码1和代码2 展示了一个Web 应用中添加与更新用户信息的代码段中所包含的二阶SQL 注入漏洞.

代码1.addUser.php 1.$link=new mysqli("localhost","root","root");2.$query="INSERT INTO Users VALUES(‘?’,‘?’,‘?’)";3.cmd=cmd=1ink->prepare($qurey);4.cmd−>bindparam("sss",cmd−>bindparam("sss",usemame,$password,$email);5.$cmd->execute();代码2.updateUser.php 6.$query="SELECT * FROM Users WHERE username=‘?’ AND password=‘?’ ";7.result=mysqlquery(result=mysqlquery(query);8.row=mysqlfetcharray(row=mysqlfetcharray(result);9.usemame=usemame=row["username"];10.email=email=row["email"];11.password=password=_POST["newpwd"];12.$query="UPDATE Users SET username=‘$username’,password=‘$password’,email=‘$emal’ WHERE usemame=‘$username’";13.rs=mysqlquery(rs=mysqlquery(query);
在addUser.php 文件中采用的是预编译语句来将用户信息插入数据库中,而非动态构造SQL 语句.由于DBMS 会通过占位符来编译SQL 语句,在接受用户输入时编译已经完成,恶意数据无法改变SQL 语句的执行逻辑,所以这种参数化方法能够有效的防御一阶SQL 注入攻击.如果将email 输入为“123’ WHERE 1=(updatexml (1,concat (0x5e24,(select password from admin limit 1),0x5e24),1));-- ”,该恶意数据则会被存入数据库的“users”表中.在updateUser.php 文件中,6-8行执行数据库查询语句从users 表中取出用户信息并保存到内存中,在第12 行利用内存中的用户信息动态构建更新用户信息的SQL 语句,由于之前在数据库中email存入的是恶意数据,此时构建的SQL 语句为“UPDATE Users SET username=‘XXX’,password=‘XXX’,email=‘123’ WHERE l=(updatexml(1,concat (0x5e24,(select password from admin limit 1),0x5e24),1));--‘WHERE username=‘XXX’”,该条语句会通过错误信息暴露admin的密码,而非更新用户信息.
3 方法框架
二阶SQL 注入漏洞的触发至少需要3 条SQL 语句的执行,分别对应“存储”、“取出”、“使用”这3 个过程,在2.2 节的示例中,2,6和12 行分别对应了这3 条SQL 语句.事实上这个过程也是用户输入的数据到达程序注入点过程,从“存储”到“取出”,数据在数据库中;而从“取出”到“使用”,数据则是在程序的运行内存中.在黑盒条件下,内存中的数据流向是未知的,故本文只要求最终的SQL 语句执行满足“存储”然后“取出”的顺序,该执行顺序也是触发二阶SQL 注入漏洞的必要条件.为生成具有特定迁移执行顺序的测试用例集,使得SQL 语句的执行顺序满足触发漏洞的必要条件,本文提出基于客户端行为模型的Web 应用二阶SQL 注入测试用例集生成方法(CBMTG),该方法的框架如图2所示.CBMTG 主要由3 部分组成,分别为初始测试用例集生成,拓扑关系图(Topo 图)构建和最终的测试用例集生成.

图2 CBMTG 框架
CBMTG 首先通过对一个初始测试用例集的执行来建立迁移与SQL 语句之间的映射关系,然后对迁移对应的SQL 语句进行字段分析以确定迁移之间的依赖关系,并以此为依据建立迁移之间的Topo 图,最终以Topo 图为指导生成最终的测试用例集.
4 二阶SQL 注入测试用例集生成
4.1 初始测试用例集
在Web 应用中,用户进行的每一次操作都能对应到一个后台DBMS 所执行的一个SQL 语句集合.对CBM 中的每一个迁移同样与SQL 语句之间存在对应关系.本文对这种关系给出如下定义.
定义1.对CBM 中T的每一个迁移t,存在一个单射函数f,使得f(t)=SQLs.其中SQLs表示执行迁移t时DBMS 所有可能执行的不同结构的SQL 语句集合.
CBMTG 通过动态执行迁移t来确定其对应的SQLs.为了保证CBM 上的每一个迁移都能建立映射关系f,CBMTG 以CBM的迁移全覆盖为目标来生成初始的测试用例集.并且,为了获取到具有正常逻辑的SQL 语句以及保证程序的正常运行,初始测试用例中的输入采用随机输入.
单个测试用例的生成过程是一个迁移选择的过程,即从CBM的start 节点开始选择迁移直到达到exit 节点.迁移选择采用贪心算法,即对一个节点的射出迁移集合,从中优先选择之前被选择次数最少的迁移,如果生成的测试用例中所有迁移都在之前生成的测试用例中出现过,则舍弃该测试用例重新生成,直到CBM 中所有迁移都被选择.
贪心算法是一种求可行解的搜索算法,只要求达到近似最优解,相较于其他求全局最优解的启发式搜索算法,如遗传算法、粒子群算法等,其更加简单高效.生成初始测试用例集用以覆盖到CBM 中所有迁移的问题有多个可行解,本文仅需找到其中之一即可,所以该问题可以通过贪心算法求解.在求解过程中,将问题分解为针对当前节点的射出迁移选择问题,使得每一次局部迁移选择都能够更加接近迁移的全覆盖.
算法1是初始测试用例集的生成算法,该算法输入为CBM 模型,并根据迁移条件以及迁移的覆盖情况选择迁移,输出为初始测试用例集.

算法1.初始测试用例生成输入:CBM
4.2 迁移依赖关系
在获取到迁移对应的SQL 语句集合后,由于同一个迁移可能被多次执行,所以该集合中可能存在大量冗余的SQL 语句,而通过SQL 语句的解析树可以判断这些冗余的SQL 语句.SQL 作为一种结构化的语言,对其解析树进行分析是一种常见的研究手段,如文献[15]利用解析树来检测SQL 注入攻击.本文采用文献[15]对SQL 解析树的表示方式,将具有相同解析树结构的SQL 语句判定为相同的SQL 语句,并以此来去除冗余,即对所有具有相同解析树结构的SQL 语句只保留其中之一,最终得到迁移对应的SQLs.所以SQLs中每一个SQL 语句都不相同.图3展示了一个SQL 解析树的例子.在不考虑literal 节点的子节点情况下,只要其他节点相同,则两个SQL 解析树结构相同.

图3 SQL 解析树
在本文中,SQL 语句为触发二阶SQL 注入漏洞而需满足的执行顺序表示为SQL 语句之间的依赖关系,该依赖关系可通过对其进行字段分析得到.SQL 语句之间的依赖关系定义如下.
定义2.设sql1为操作字段包含a的select 类型SQL语句,如果a为长字符串类型,且存在另一个insert 或update 类型SQL 语句sql2以a作为操作字段,则称sql1依赖于sql2.
在测试用例集中,迁移是对Web 应用进行操作的最小单位,因为迁移与SQLs之间存在单射关系,即一个迁移对应多个SQL 语句,本文在此基础上建立迁移之间的依赖关系,使得当所有迁移之间的依赖关系被满足时,所有SQL 语句之间的依赖关系被满足,本文定义迁移之间的依赖关系如下.
定义3.设迁移f(t1)中存在SQL 语句sql1,f(t2)中存在SQL 语句sql2,使得sql1依赖于sql2,则称t1依赖于t2.
例如,迁移t1对应SQLs为{select name from user where id=‘userInput’,update schoolinfo set info=‘userInput’},迁移t2对应SQLs为{insert into user(name)values(‘userInput’),select info from schoolinfo},在该例中迁移t1依赖于t2,同时t2依赖于t1.
在定义2 中,由于数据库中非字符串类型以及短字符串字段无法存储恶意数据,所以无需考虑这些类型的数据库字段,字段信息通过查询information_schema.columns 来获取.
4.3 Topo 图生成
CBM 中迁移之间的依赖关系以Topo 图的形式来表示,Topo 图定义如下.
定义4.Topo 图表示为一个二元组
其中的二元组
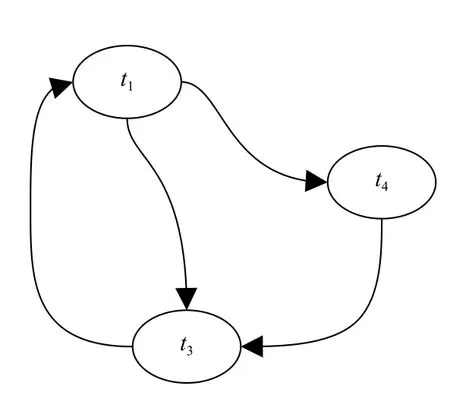
图4 Topo 图
算法2是Topo 图生成算法的伪代码.在第5 行,使用开源工具SQL-parser[16]来进行SQL 语句的解析,获取其属性字段以及操作类型等(该工具同样被用于4.2节的SQL 语句去冗余操作中).因为一个迁移可能对应多个不同类型的SQL 语句,故本文通过storageAttr 来记录insert和update 操作的字段,usageAttr 来记录select 操作的字段,然后通过求两者的交集来求得迁移之间的依赖关系,其对应算法中的16 行.在12 行中先将所有的迁移都放入Topo 图中,在14–20 行判断它们的依赖关系,最终在21 行从Topo 图中删除不存在任何依赖关系的迁移.

?
4.4 测试用例集生成
为满足触发二阶SQL 注入漏洞的必要条件,即使得迁移满足Topo 图中的依赖关系,最终的测试用例集需满足:对Topo 图中的任意一对依赖关系
为了触发漏洞,将测试用例上的所有输入都替换为攻击向量.一般情况下,Web 应用通常会对用户输入进行过滤、进化等操作,这使得输入的恶意数据被应用识别出来而根本不会被执行,或者被破坏以致于达不到攻击的目的,所以需要使用更加隐蔽的攻击向量.目前对SQL 注入攻击的攻击向量进行伪装的方法一般分为如下几种:大小写混合、关键词替换、更改编码形式、使用注释、等价函数与命令、特殊符号、HTTP参数控制,以及这几种方式的组合[17,18].在本文的研究中,为了便于攻击向量的自动生成,攻击向量的生成规则以巴科斯范式(BNF)的形式进行表示.

图5 迁移选择流程图
5 实验评估
为了全方位评估CBMTG 在检测二阶SQL 注入漏洞的能力,本文提出如下两个研究问题:
(1)CBMTG是否能够有效地检测出Web 应用中的二阶SQL 注入漏洞,其与当前现有的方法相比效果如何?
(2)CBMTG 使用的Topo 图是否能有效地指导针对二阶SQL 注入漏洞的测试用例集生成?
5.1 实验对象与环境配置
本文对如表1所示的4 个开源Web 应用进行了实验,这些Web 应用均使用PHP 作为后端脚本,并且以MySQL 作为数据库.这些应用都可以从Sourceforge上获取得到.

表1 被测程序
实验环境如下:CPU:Intel(R)Core(TM)i5-3470@3.20Ghz;内存:8 GB DDR3;操作系统:Windows10;浏览器:Chromever.78;测试用例执行工具:Python3.6.4+selenium3.0.1.
5.2 实验结果
5.2.1 漏洞检测能力
为了评估文中方法的漏洞检测能力,本文将CBMTG与文献[11]中的灰盒方法以及RIPS 工具进行了对比,这两种方法是目前检测二阶SQL 注入漏洞的主流方法.RIPS是目前仅有的能检测二阶SQL 注入漏洞的代码审计工具,它来自于文献[9,10]中的白盒方法.实验结果如表2所示.
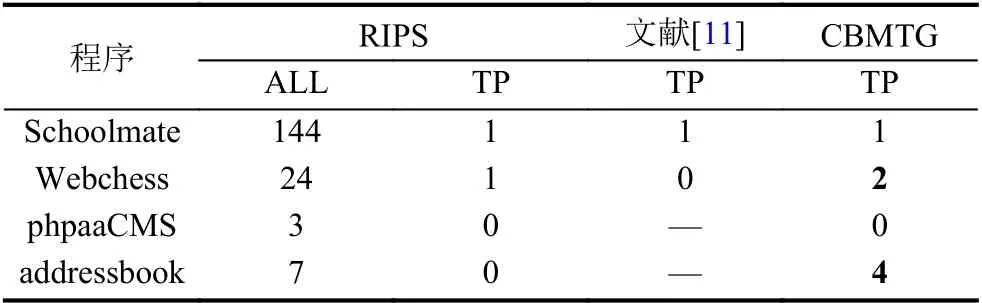
表2 漏洞检测结果
从表2中可以看出,CBMTG 能比RIPS 以及文献[11]的方法检测出更多的二阶SQL 注入漏洞.RIPS 使用静态分析的方法来检测漏洞,可以看出其报告的漏洞要远远多于真实存在的漏洞.经过对程序源码的分析发现,RIPS 将大量的主键数据的存取视为二阶注入漏洞.同样从结果中可以看出RIPS 在phpaaCMS和addressbook上检测效果并不理想,这是因为相比于另外两个应用,phpaaCMS和addressbook的源码具有更加复杂结构,严重干扰了RIPS的静态分析能力.而文献[11]的方法同样涉及源码的静态分析过程,由于文献中并未说明针对复杂源码结构(比如“类”、“命名空间”)的分析方法,所以本文没有得到对phpaaCMS 以及addressbook的检测结果.本文的CBMTG是一种黑盒的检测方法,所以复杂的程序结构并不会影响方法的检测结果.我们发现CBMTG 并未从phpaaCMS 检测出二阶SQL 注入漏洞,这是由于从数据库中查询出的恶意数据并未被用于构建另一个SQL 语句,虽然存在数据的“存储”到“取出”的过程,但是事实上该应用中并不存在二阶注入漏洞.
5.2.2 CBMTG 有效性
为了评估迁移Topo 图对测试用例生成的指导作用,本文在Schoolmate、Webchess、addressbook 等3 个应用上将CBMTG 生成的测试用例集与随机生成的测试用例集进行对比试验.其中随机生成的测试用例集保持与CBMTG 生成测试用例集同样的大小,且每组随机试验都进行了20 次,取平均值作为最终检测出漏洞个数.
实验结果如图6所示.横轴上括号中的数字表示单个测试用例集中的测试用例数量.从图6中可以看出CBMTG 优于随机的测试用例生成方法,说明CBMTG中使用的Topo 图确实能够有效地指导测试用例的生成.同时结合测试用例数量后发现,由于针对Schoolmate的测试用例集更加庞大,导致随机测试用例集在该应用上的表现与CBMTG的测试用例集更加接近,因为庞大的测试用例集能够使得迁移之间进行更多的组合,这就导致了二阶SQL 注入漏洞检测概率的提高.
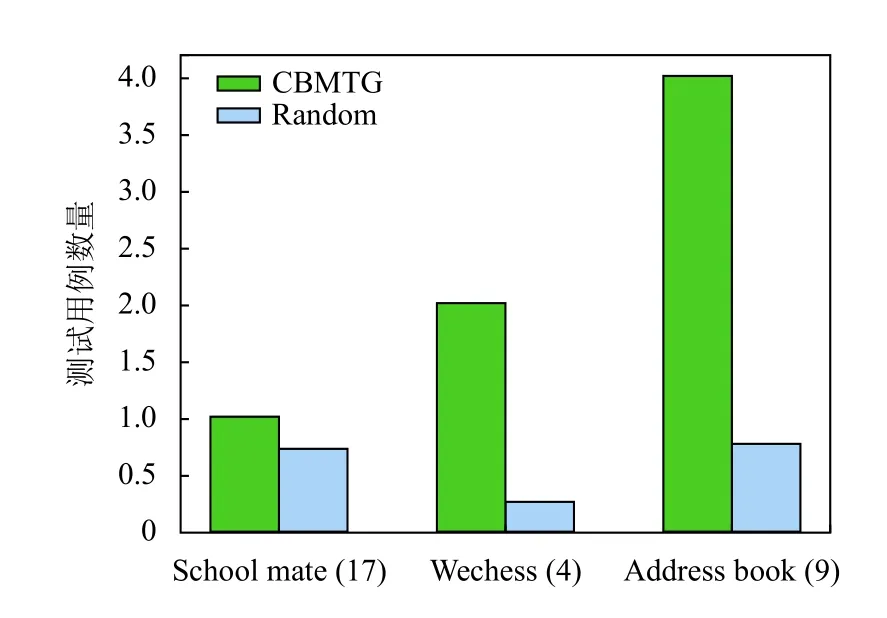
图6 CBMTG与随机测试用例集对比
6 结论与展望
在Web 应用中,二阶SQL 注入漏洞比一阶SQL注入漏洞更加难以检测,在黑盒情况下,目前还没有一种有效的方法来针对该漏洞生成测试用例.本文利用基于模型的测试用例生成思想,提出一种基于客户端行为模型(CBM)的测试用例集生成方法,利用客户端行为模型(CBM)先建立迁移与SQL 语句之间的映射关系,然后获取迁移之间的拓扑关系,以此来指导测试用例集生成.实验结果表明,本文提出方法所生成的测试用例集能够有效地检测出Web 应用中的二阶SQL 注入漏洞.在后续进一步的研究中,作者将考虑在现有测试用例集的基础上去除不相关迁移以达到提高漏洞检测效率的目的,同时探索将本文方法拓展到其他类型的二阶注入漏洞检测领域.
猜你喜欢
今日农业(2022年13期)2022-09-15 01:21:08
铁道通信信号(2020年6期)2020-09-21 09:23:22
应用数学(2020年2期)2020-06-24 06:02:46
数学物理学报(2018年6期)2019-01-28 08:58:02
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34
传感器与微系统(2018年7期)2018-08-29 00:44:18
Acta Mathematica Scientia(English Series)(2018年6期)2018-03-01 03:13:44
中国卫生(2016年5期)2016-11-12 13:25:28
儿童时代(2016年6期)2016-09-14 04:54:43
中国卫生(2015年12期)2015-11-10 05:13:38
