
基于融合机制的多模型神经网络人物群体分类模型①
2020-03-22 07:42段新新
计算机系统应用 2020年8期
郎 波,张 娜,段新新
1(北京师范大学珠海分校 工程技术学院,珠海 519087)
2(北京师范大学研究生院珠海分院,珠海 519087)
如何有效的识别图像或视频中人物的状态(例如:年龄、性别等),归根结底是如何获取到图像中的“有效特征”.深度学习的出现解决了如何让机器自动学习“有效特征”的问题[1,2],它利用人脑处理信息的学习机制,利用分级处理的过程,逐层进行特征的变换,将样本在原空间的特征表示上升到一个新的特征空间表示,从而大大提高了分类的效能,可以更加丰富的表示出图像的内在信息,即“有效特征”的表示问题[3].深度学习解决了如何自动学习“有效特征”的问题,它通过逐层的特征变换,将学习样本在原空间上的特征表示变换到一个新的特征空间,从而使得分类识别任务变得更加有效.目前主要的研究工作是通过人脸图像信息来发现其性别属性.例如Tian 等[4]使用深度LDAPruned Net,Edinger 等[5]受到训练深度神经网络Dropout 技术的启发,训练了一个随机丢失某些特征的支持向量机(Support Vector Machine,SVM),通过它对人脸特征进行区分来完成性别分类,Brunelli 等[6]使用两个径向基函数来分别提取男人和女人的脸部特征来进行性别分类,此外还有利用反向传播网络(Back Propagation network,BP)和极限学习机(Extreme Learning Machine,ELM)进行分类的模型[7,8],张婷等[9]提出的基于跨连卷积神经网络的性别分类模型.尽管这些研究实验在图像光照、遮挡等外部因素影响下保持较高的识别率,但其所采用的测试样本数据库普遍具有前景对象突出、背景简单的特点,而且必须是标准的人脸照片,并不具备自然图像的特点.后来Levi等[10]利用Adience 数据集使用卷积神经网络对年龄和性别进行分类,采用的图片为自然条件下光照多变、姿态各异、图片质量欠佳等现实场景,但在训练网络做预处理工作时仍然必须采用基于人脸特征来进行性别以及年龄的区分.
为了克服特征缺失的问题,还有研究者尝试使用局部特征来对人物个体进行分类[11],局部特征的优势是能够详细描述图像的局部信息和细节,但是同时也存在缺点,例如,局部特征会忽略图像的色彩信息,而色彩信息对于识别人物的性别和年龄是至关重要的,另外过分强调局部特征也难以从整体构成和关系上来准确表达图像.
1 解决问题
本文尝试利用深度学习中卷积网络的学习方法来对场景中人物的年龄和性别进行区别,进而实现不同群体人物的分类.在设计学习模型时,主要考虑到以下3 个方面的问题:
(1)选择卷积神经网络能否对人物特征(年龄、性别)的分类有促进作用?
卷积神经网络可以从原始图像中学习出包含丰富语义信息的特征矩阵,从目前的研究结果来看,利用卷积网络学习到的特征,要比手工特征或局部特征的分类准确率高[12],所以,选取卷积神经网络来对人物特征进行分类是一个发展方向.
(2)如何得到较为全面的人物特征来促进年龄和性别的分类问题?
对于图像中人物特征的识别会受到很多因素的制约,例如颜色、构图、亮度、纹理等.如何从不同角度更加全面的挖掘图像信息、提取有效的图像特征,并且使得分类效果具有更广泛的适用性.卷积神经网络的学习效果依赖于输入源的质量.数字图像有不同的编码方式,将同一图像的不同表示矩阵作为输入源,可以获取更全面的图像特征.
实际生活中的自然图像背景复杂,人物着装发型各异,人物姿态多样,人物图像人物与背景关系复杂,因此如果要在这种自然图像集区分性别并判断年龄就比较困难.研究表明,综合有效利用高层次特征和低层次特征,对改善视觉系统的识别能力是很有作用的[8].以此为出发点,为了能够使卷积神经网络(Convolutional Neural Networks,CNN)模型更为快捷的实现多特征信息的互补,本文以CNN 模型为基础模型,提出一个多模型融合卷积神经网络的办法,利用ImageNet[13]训练得到的模型(例如:Inception v3,Xception,Inception-Resnet v2,DenseNet,NASNetLarge),参与本文神经网络模型的权值初始化,在有效节省时间和计算资源成本的前提下获取更多有效的特征.将多模型融合卷积神经网络用于性别和年龄识别的优点在:对现有模型进行混淆矩阵的分析,利用迁移学习在现有模型得到的图像特征的基础上,采用无监督方式进行性别和年龄的分类,以构造性能更好的分类器.
2 算法模型
深度神经网络的结构主要由卷积层、采样层、全连接层组成.其中卷积层的作用是利用卷积核进行特征抽取,并对抽取到的特征进行过滤和强化,卷积的目的是将前一层输出的特征图与卷积核进行卷积操作,并通过激活函数输出特征图(feature map),如式(1)所示:
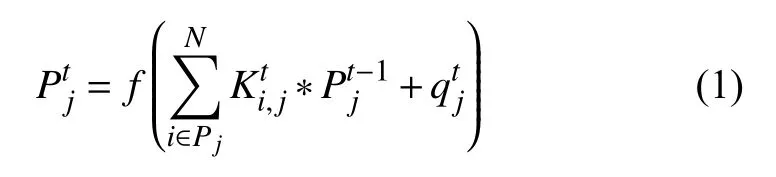
其中,f是激活函数Sigmod,t表示网络的层数,表示卷积核,*表示卷积操作,表示偏移量,Pj表示输入的特征图集合
采样层主要是用来降低特征维数,通过池化操作来获取抽样特征,抑制过拟合,提升特征的识别能力,如式(2)所示:

其中,ω是权值函数,simple()是采样函数.
传统卷积神经网络是一种特殊的深层前向神经网络模型,其结构一般由输入层、卷积层和池化层、全连接层及输出层构成,它的一个缺点是难以有效的融合各种特征去构造性能更好的分类器[3],由于CNN 模型主要利用灰度图像作为输入,缺失了对颜色和亮度的理解,为了更完善的表达图像,因此采用多特征融合的方法来对图像进行处理,针对该问题,本文引入了多模型融合的思想,提出了一个多模型卷积神经网络融合(Multi-model-Integrated Convolution Neural Network,MICNN))算法模型,用于对自然场景下的人类性别和年龄进行分类.该模型整体结构如图1所示.
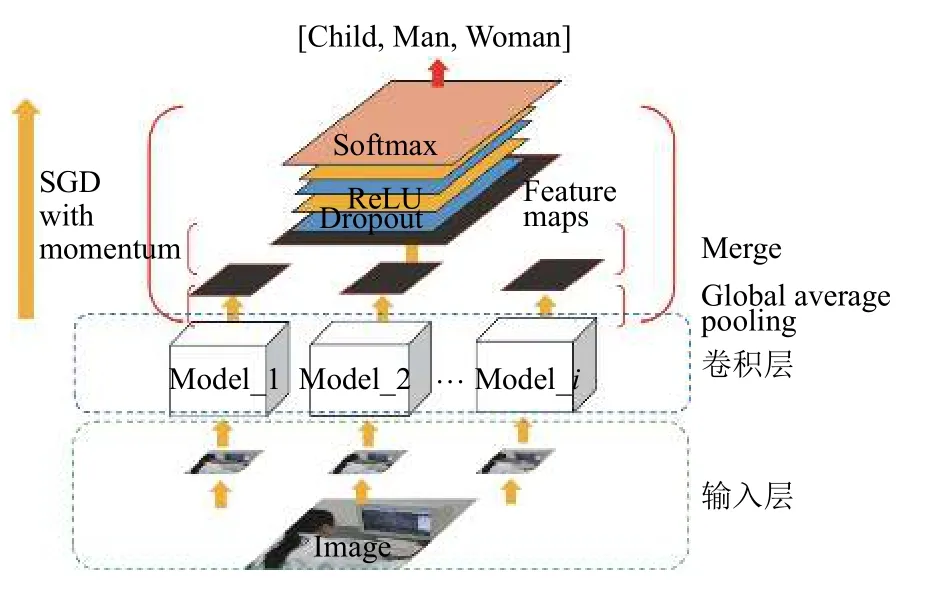
图1 多模型融合卷积神经网络模型
2.1 特征抽取层
本层选取若干网络模型分别对训练数据集、验证数据集和测试数据集做特征提取的训练,获得图像的特征表示,目前选取的网络模型为Inception v3[9],Xception[10],Inception-Resnet v2[11],DenseNet[12],NASNetLarge[13].之所以选择这几个网络模型,主要考虑到:Resnet 网络结构通过增加恒等映射,用来解决深度网络中学习退化的问题,从而优化训练结果;Inception 模块通过使用不同的滤波器对输入进行卷积并进行最大池化工作,增加了网络宽度,从而得到更为全面的特征表象;Inception-Resnet v2 可以有效防止模型梯度消失的问题;Xception 在减少模型参数的前提下增加了模型的表现能力;DenseNet 可以做到大量的特征被复用,即使用少量的卷积核就可以生成大量的特征;NASNet架构主要用于大规模的分类和识别,并可以做到对模型规模的自动调整.
2.2 全局平均池化层
使用平均池化,将从特征抽取层中得到的特征图进行全局平均化,即把一个的张量平均化为一个1×1×D的张量.使用全局平均池化层的目的是为了将N个特征图降维成1×N大小的特征图,然后在全连接层用分类数class(本文设置为3,即男、女、年龄)个1×1的卷积核将1×N的特征图通过卷积得到1×class的向量.以Xception 网络为例,(nb_samples,10,10,2048)在使用在使用全连接层Softmax 之后的计算量为nb_samples×10×10×2048,而使用全局平均池化后计算量为nb_samples×1×1×2048)
全局平均池化通过加强特征图与类别的一致性,让卷积结构更简单.因为本文提出的融合训练的模型中每一个都是大型的网络结构,同时本研究项目的数据集并不丰富,所以训练过拟合是本项目重点考量的问题,全局平均池化并且不需要进行参数优化,所以在模型中设置这一层的目的就是为了更加有效地避免过拟合,而且,全局平均池化层对空间信息进行了求和,因而对输入空间的变换更具有稳定性,可以使计算网络对图像进行特征提取的同时也保留了图像的空间信息的特点.
2.3 Dropout+ReLU 层
全局平均池化层虽然在一定程度上避免了过拟合问题,但是在研究过程中发现,由于对人物个体的分类比较细化(除了对性别进行分类,还有对成人儿童进行分类),所用到的训练数据集较小,同时为了提高泛化性能,数据集中的图片均是自然场景图片,背景纹理复杂,对提取有效特征有一定的难度.此融合结构比较复杂.所以在仍需要对解决过拟合问题采取一定措施.
神经网络的训练流程是将输入内容通过网络正向传播,然后将训练误差反向传播进行权值更新,dropout的作用就是在上述过程中临时随机删除部分神经元.即在网络训练前向传播的时候,让某个神经元的激活值以一定的概率P停止响应,这样可以使训练模型不至于过分依赖某些局部特征,从而提高模型的泛化能力.如图2所示.
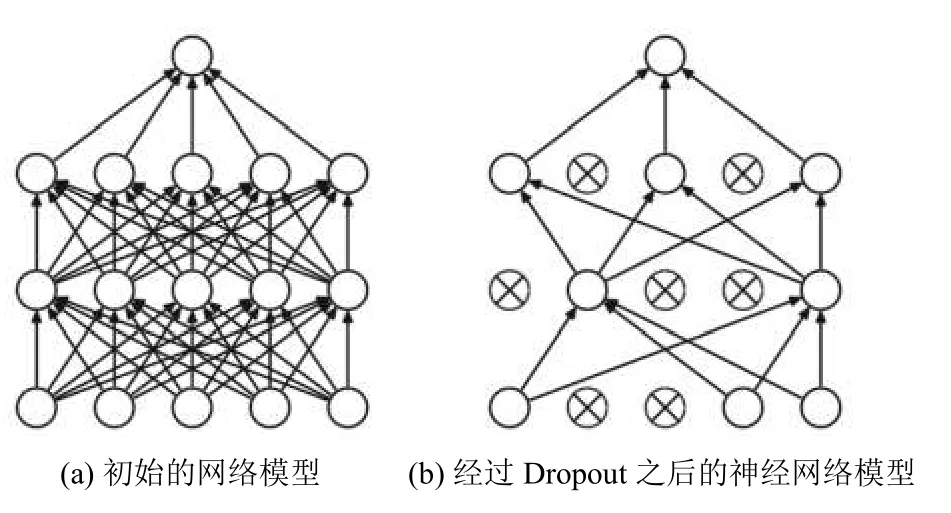
图2 神经网络训练流程
Hinton 等的研究表明过拟合现象可以通过阻止某些特征的协同作用来进行缓解[14].通过dropout 过程的参与,可以有效减少神经元之间的共适应性,降低神经元的互相依赖性,从而增强计算模型的鲁棒性.经过实验验证,为了减少特征之间的相关性,本文中的dropout比率设置为0.5,假设网络中的神经元个数为N,其激活函数输出值个数也为N,则该层神经元经过dropout后,大约0.5×N的值被置为0.其各部分的数学定义为:
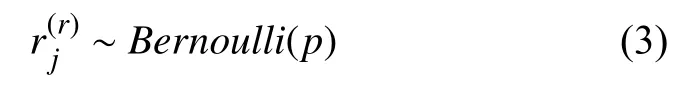

式中,yl为原本第一层的输出,y∗(l)为第一层经过dropout之后的输出.
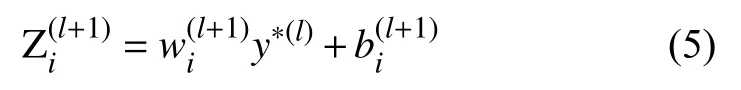

其中,是第l+1层的输出,是激活函数.
2.4 全连接层
模型的最后一层是输出结果,输出的结果用一个概率向量来表示[Pchild,Pman,Pwoman],本文输出层激活函数使用Softmax 对网络输出各权重值进行计算从而得到多分类下的先验概率.若在Softmax 层之前的隐藏层为L输出值为M维向量,向量中的每个元素为待分类对象在各类别中的先验概率值Pj=P(y=j|x),j=1,···,M,(即向量x属于j分类的概率),公式表示为:
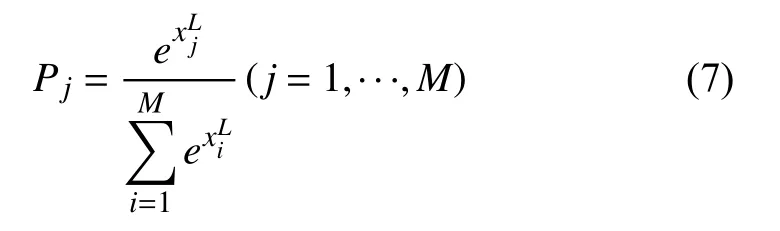
本文选择交叉熵损失函数衡量真实值与网络的估计值的误差,该方法可以克服某些损失函数在模型训练学习过程中权重和偏置的更新速度缓慢的问题,如式(8)所示:
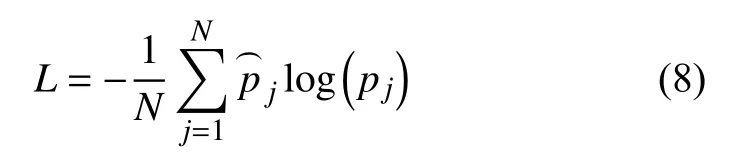
其中,N为测试集中样本的数量,为第j个类别的真实值,pj是Softmax 函数的第j个输出值.
2.5 误差修正
在神经网络训练过程中,通常无法直接计算loss 损失函数的全局最优解,但可以通过损失函数求出网络中各参数的梯度目前使用梯度下降迭代的数值优化方法来降低损失函数,即通过 θ ←θ−来迭代更新参数.本模型中使用SGDM(伴随动量随机梯度下降)来计算模型参数 θ ←θ+Vt(Vt表示每一次迭代后θ的更新量),从而使模型更加逼近或者达到最优值并使loss 损失函数最小,具体表示如式(9)所示:
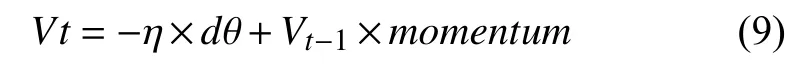
其中,η表示学习率,即当前梯度对最终更新方向的影响程度,dθ是网络中更新参数相对于目标函数的梯度,Vt−1表示上一次的更新量,momentum的值是介于[0,1]之间的一个随机量,用来表示保留原来更新方向的程度.该模型在训练过程中更新参数时会在一定程度上保留之前的更新方向,同时还会利用当前批次的训练结果微调下一轮迭代的更新方向,可使得模型在训练过程中更加稳定,并且有助于加快模型的收敛速度.
本模型在训练过程中,初始训练梯度相对较大,所以momentum初始值为0.5,训练一段时间后,梯度变化相对减小时更改为0.9,考虑到学习率大小对梯度下降迭代更新参数的影响,太小收敛速度慢,太大学习率会阻碍收敛,并会造成损失函数在最小值处的震荡,甚至导致发散,将 η的初始值设为0.0001,在模型训练过程中监测在验证集的损失或者准确率,当学习停滞时,则减少学习率,反之则进行调整.
3 实验方法
3.1 测试库的选择
本文在Open Images Dataset V4 数据集提供的图像库的基础上,经过人工筛选制作了实验所需的数据集.该数据集中的图像源于普通真实的生活场景,图像背景复杂,人物姿态各异,具有很强的实用性,我们分别用man、woman、child 表示不同类别的图像的标签,得到的数据样本集为[man,woman,child]=[1504,1504,1504],验证集为1354 幅.其数据集部分图像如图3所示.
3.2 数据预处理
数据集在输入模型训练之前对图像样本执行逐样本均值消减的归一化的预处理,即分别对各个通道进行去中心化处理.归一化的目的是为了移除图像的平均亮度值,很多情况下我们对图像的亮度并不感兴趣,而更多地关注其内容,这时对每个数据点移除像素的均值是有意义的.

图3 本文采用的数据集部分样例
为了提高训练效率,本文采用已经在ImageNet 数据集上预训练好的CNN 模型作为特征提取器,通过这些预训练好的模型导出的特征向量可以快速概括图像上的大约内容,分别对训练集、验证集、测试集分别做特征提取的预训练.我们对目前比较流行的几种CNN 模型进行了分析,如表1所示.
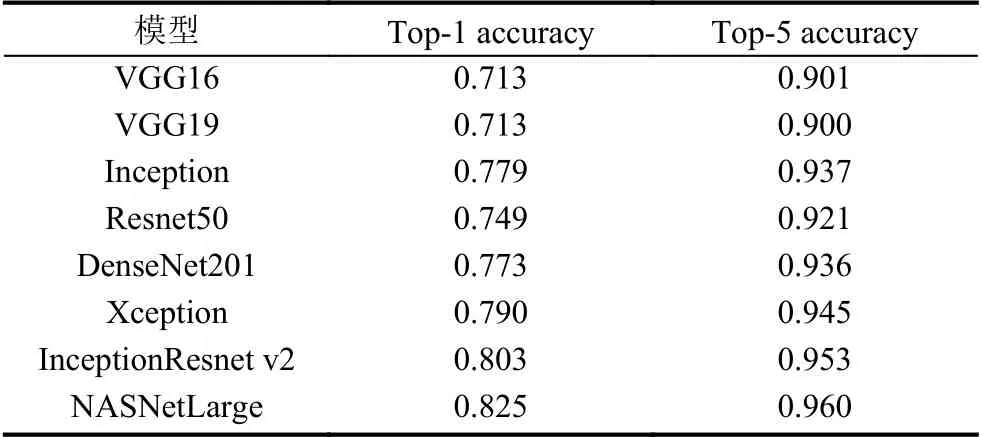
表1 ImageNet 预训练模型分类性能比较
表1中,top-1和top-5是指模型在ImageNet 验证数据集上的性能.top-1 accuracy为预测类别中概率向量中排名第一的类别与实际相符的准确率,top-5 accuracy即为排名前5的类别包含实际结果的准确率.利用全局平均池化将卷积层输出的每个激活图直接求平均值,减少输出数据文件大小,在一定程度上减少过拟合问题.最后针对每一个预训练模型导出5 个文件:
(1)train (train_nb_samples,model_ouput).
(2)val (val_nb_samples,model_ouput).
(3)test(test_nb_samples,model_ouput).
(4)train_label (train_nb_samples).
(5)val_label(val_nb_samples).
其中,train_nb_samples,val_nb_samples,test_ nb_samples,model_ouput 分别为训练集样本数、验证集样本数、测试集样本数、预训练模型的输出图像的特征表示长度.其中VGG16,VGG19,Resnet50,InceptionV3,Xception,InceptionResnet v2,DenseNet201,NASNet-Large的model_ouput 分别为512,512,2048,2048,2048,1536,1920,4032.将多个不同的网络输出的特征向量进行保存,再利用这些特征向量训练、调参、优化模型,会大大减少训练时间和计算代价.
3.3 融合训练
融合的目的是为了尽可能的发挥各个单一模型的优势,从而提高整个模型的性能.通过多个模型融合训练,最终的特征表示是由多个不同的局部区域特征组合而成,这种“组合特征”的优越性能够在实际任务中显著的区分出个体的主要差别,其算法流程如算法1.
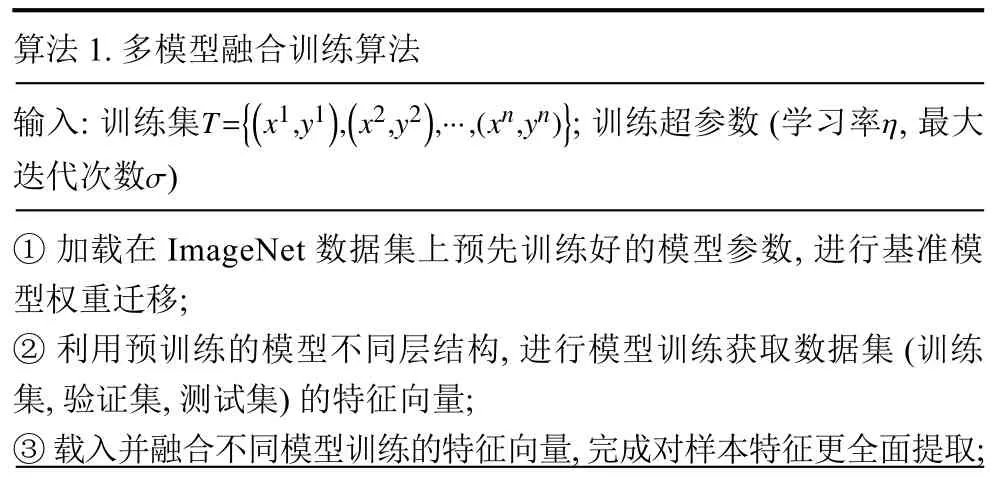
算法1.多模型融合训练算法T={(x1,y1),(x2,y2),···,(xn,yn)} η输入:训练集 ;训练超参数(学习率,最大迭代次数)σ①加载在ImageNet 数据集上预先训练好的模型参数,进行基准模型权重迁移;②利用预训练的模型不同层结构,进行模型训练获取数据集(训练集,验证集,测试集)的特征向量;③载入并融合不同模型训练的特征向量,完成对样本特征更全面提取;

④使用两层ReLU+dropout 层和一层Softmax 形成新的网络进行训练,计算每个样本图像的实际输出类别;⑤根据损失函数loss function(衡量在单个训练样本上的表现)及成本函数cost function(衡量在全体样本训练样本上的表现),计算出网络训练反馈误差;⑥计算网络模型中的权重和偏置得到梯度值;⑦使用SGD with momentum 动量随机梯度下降法,更新模型参数(权值和偏置)以及模型参数的更新变量 ;⑧输出并保存网络模型的权重与偏置.vt
需要定义以下参数对模型的训练质量进行评估:
(1)定义模型评估指标值:
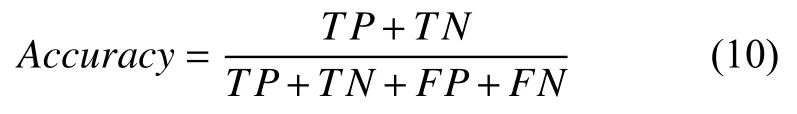
其中,TP是被标记为正例的正例数据点,称为真正例.FP是被标记为正例的反例数据点,称为假正例.TN是被标记为反例的反例数据点,称为真反例.FN是被标记为反例的正例数据点,称为假反例.
(2)定义F−S core是precision(精确率)与recall(召回率)的加权调和平均值:
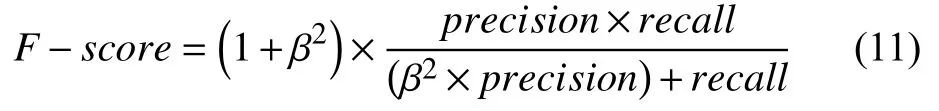
其中,precision=标识分类模型返回相关实例的能力,recall=表示分类模型识别所有相关实例的能力.
当β=1时,将F−S core设为:

理想中的期望是精度和召回率越高越好,然而在工程实践中,这两个指标是不能兼得的,在较高时,我们认为此时的特征检测结果最为理想.
计算各单一模型在个体识别分类混淆矩阵,因为根据混淆矩阵可以分析单一预训练模型对男性、女性、儿童不同个体识别分类的精确率结果,从而判断模型表现的优劣情况,为选择合适的模型进行融合训练提供真实的数据依据.表2表示从混淆矩阵中得到不同模型在个体识别任务中针对不同类别的表现能力.
根据表2提供的数据,选择在child 个体识别精确率最高的Inception_ResNet_V2 模型,man和woman个体识别精确率最高的NASNetLarge 模型,但Inception_ResNet_V2 在woman 模型上的精确率相对并不是很高,所以选择在child 精确率在80% 以上,woman 精确率相对提高的模型Xception,InceptionV3,DenseNet201.最终融合模型训练选择:Inception_ResNet_V2,Xception,InceptionV3,DenseNet201,NASNetLarge.在本研究中命名次新模型为:Merge_Model_V1.
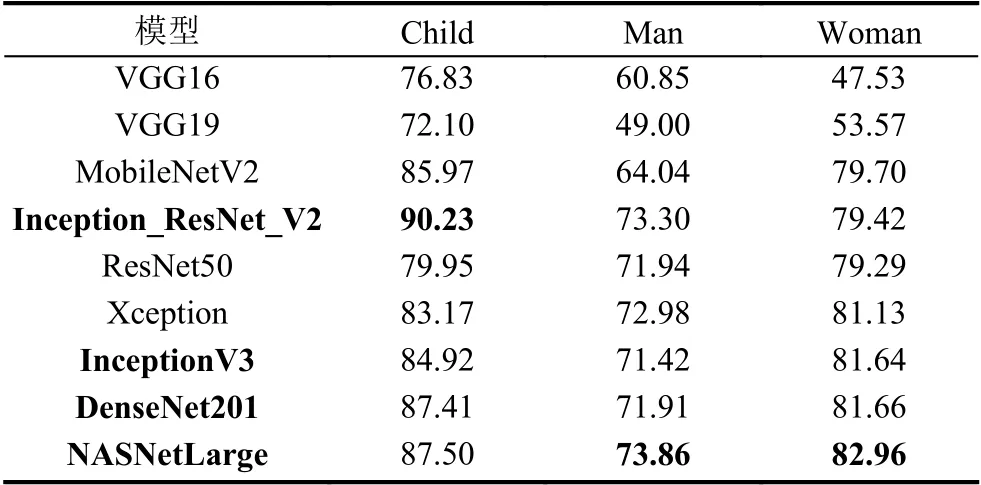
表2 各单一模型在识别不同个体类别的精准率(%)
4 实验结果与性能评估
在样本集上利用Merge_Model_V1 进行训练学习并输出结果,如图4、图5所示的部分结果,注意本模型对于输入的图片并未做任何人为标注,仅使用样本集中本身具有的文件夹作为分类标签信息,也未对图片中的目标主题做中心化处理,从结果来看,本模型网络对于个体性别的分类特征还是很准确的,并能够在复杂场景下聚焦分辨人物性别.另外分别计算出通过Merge_Model_V1 训练网络得出在训练集与验证集上的交叉熵曲线、准确率曲线和F1 曲线,如图6.从曲线的拟合度上可以看出,Merge_Model_V1 模型并没有发生“过拟合”的现象,模型表现出了非常好的健壮性.
5 结论与展望
本文基于融合多模型预训练实现对自然场景中男性、女性、儿童实现群体识别分类.本模型综合考虑识别全局图像信息和局部特征信息,使用多模型预训练的方式,(利用全局平均最大池化的方式将卷积层输出的每个激活图直接求平均值,减少输出的数据量,在一定程度上减少过拟合问题.)完成对数据集的特征向量提取,融合模型阶段使用预训练阶段数据集的不同的特征图,在网络训练阶段训练时间大大减少,更加方便模型参数调优.现阶段根据模型的实验结果表明,本模型对于自然场景中的个体分类中成年男性、成年女性、儿童识别准确率相对平均可以保持在85%左右,在考虑提高模型整体准确率的情况下,我们下一步工作研究的重点将是使用本文提出的模型作为分类器,应用与目标检测框架,完成场景理解任务.在场景安全隐患预估问题上,可以做到针对特定不同个体的安全系数评估,从而为更全面研究场景安全问题奠定一定基础.

图4 融合模型对自然场景下的人物性别热力分析

图5 融合模型对特殊条件下的人物性别热力分析
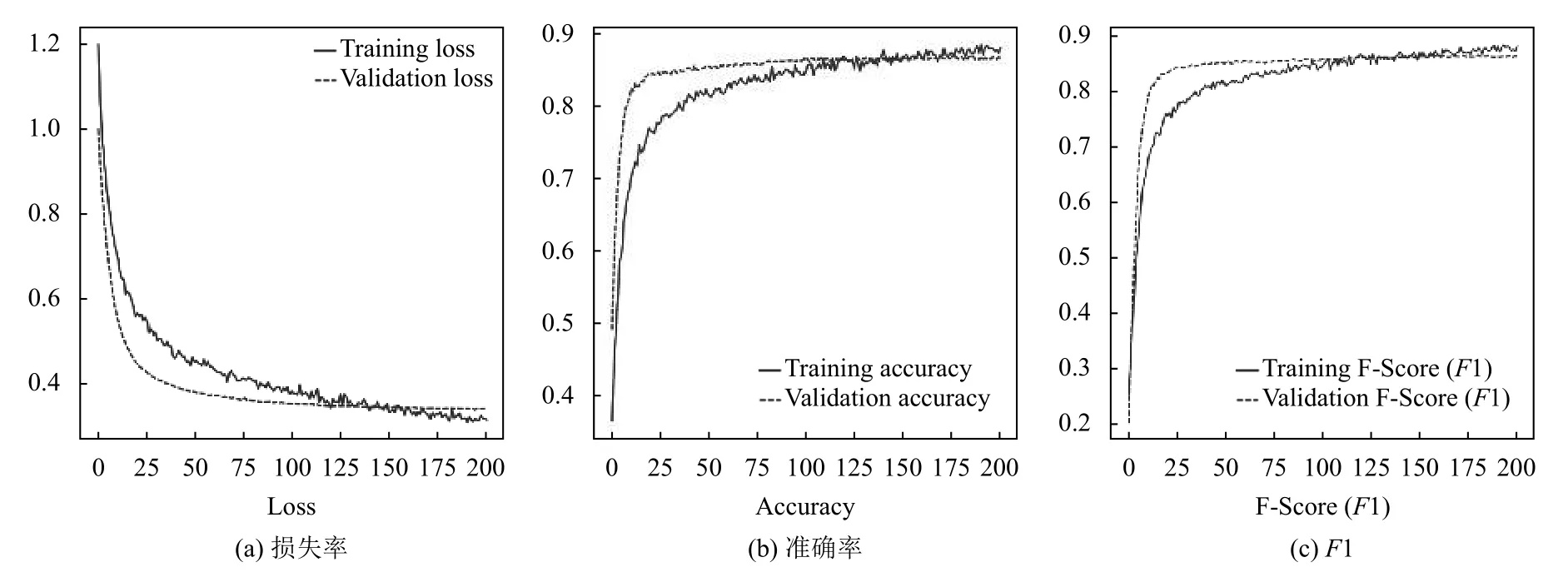
图6 损失率、准确率和F1 曲线图
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
电子制作(2019年24期)2019-02-23
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
