
基于深度学习的驾驶员换道行为预测①
2020-03-18 07:54惠飞,魏诚
计算机系统应用 2020年3期
惠 飞,魏 诚
(长安大学 信息工程学院,西安 710064)
驾驶员的换道行为是行车安全中的关键因素,一个不正当的换道行为可能会造成车辆的碰撞,甚至安全事故[1,2].但是在行车过程中,影响驾驶员变换车道的因素很多[3-5],这就要求预测模型能融合多种特征数据后得出一个较为准确的结果.2014 年,Zheng J 等[6]提出了一个普通的前馈神经网络模型来预测驾驶员的换道行为,该模型融合了多个车辆在行驶过程中的数据特征,其准确率达到了94.58%(左换道)和73.33%(右换道).但是该模型没有考虑驾驶员自身的生理特征并且右换道和左换道的准确率不对称.2015 年,Peng JS 等[7]提出了一种多特征融合的神经网络的模型,该模型考虑了驾驶员例如头部转动等生理因素.并利用前馈神经网络来预测驾驶员的换道意图.但文章中提到该模型的时间窗口提取方法不准确,可能会影响模型性能.
通过文献[8-11],可知大多数较早期的预测模型都是以3 层的全连接神经网络来作为预测模型,但是这种网络在处理时间序列的能力不强,所以不论将数据怎样处理,神经网络的输入都是代表一个瞬时值,这可能会导致预测结果的偏差.2016 年,Dou YL 等[12]提出了一种以支持向量机和前馈神经网络为主要方法的预测模型.该模型只对支持向量机和前馈神经网络的预测结果做了分析和合并,并没有将支持向量机和神经网络的结构加以改变.同年,Wang XP 等[13]提出了一种以前馈神经网络和卷积神经网络为基础的混合神经网络模型,该模型以时间序列为输入,通过卷积网络来提取数据特征,再经过前馈网络进行数据融合后得出结果.但此模型的问题在于当用卷积网络提取数据时,可能会造成数据的损失,使得预测精度降低.
针对上述问题,本文提出了一种基于全连接神经网络和循环神经网络的混合神经网络模型,该模型充分利用了循环神经网络的变体Seq2Seq[14,15]框架来处理时间序列数据,并且利用全连接神经网络来提取数据特征.其次,本文将驾驶员的生理数据和汽车的运动学数据作为模型的输入特征,以提高预测的精准度和前瞻时间.
文章的结构分为4 个部分,第1 部分介绍数据采集过程以及预处理方法,第2 部分介绍模型的结构和训练方法,第3 部分对训练后的模型进行验证,最后对文章模型以及结果进行分析.
1 数据采集及预处理
由于实验数据来源于真实交通场景和不同的传感设备,所以数据预处理的第一个任务是将每个传感设备采集的数据进行滤波、分段处理,第二个任务是进行时间戳对齐,并按时间窗口提取具有同一标签的数据.
1.1 数据采集
本次数据采集过程中,汽车运动学数据中的速度、加速度来自安装在试验车上的Cohda_wireless 短程通信设备.转向角、转向角加速度来自安装在方向盘处的转角测试仪.驾驶员生理数据中的脑电数据(EEG)和头部运动数据来自脑波分析仪.心电数据(ECG)来自贴片式心率测试仪.头在水平方向转动的次数来自行车记录仪中的行车视频.数据采集设备如图1 所示.图2 是模型训练数据的采集路线,采集车辆从长安大学出发到西安城北客运站,全长23.8 公里.为了使模型训练和验证的时候更加鲁棒,我们邀请了不同的驾驶员在不同的天气、道路、行人、车辆情况下进行数据采集.

图1 数据采集设备

图2 训练集/测试集数据采集路线
1.2 时间窗口选取
时间窗口是所有数据处理的时间大小依据,所以该时间窗口的大小要能容纳驾驶员换道前的各个数据变化.即在该时间窗口内,车道变换前后的各个数据变化要能被观察到.如图3 所示,将从车辆转向角发生巨大变化至转向角趋于平稳的一个行为标记为一个变道行为,并将该段时间记作一个时间窗口.在讨论该模型的前瞻性时,采用依次缩短该时间窗口的方法.其具体做法是将时间窗口的结束点依次提前,在不考虑预测精确率的情况下,时间窗口结束点3 比结束点2 具有更好的前瞻性.因此,在模型训练和验证过程中,采用缩小时间窗口的同时比较准确率的方法来训练和验证模型.
在数据处理过程中,以当前的时间窗口大小为依据.文章所采用的循环神经网络要求每次输入的数据为定长,但由于时间窗口是不定长的,因此要求在每个时间窗口内设定一个通用的数据提取方法,使得在不同长度的时间窗口内提取数据特征个数相同,在保证输入数据的一致性的同时又可以将数据损失降到最小.驾驶员在时间窗口内头部在水平方向的转动次数不经过循环神经网络的处理,直接参与全连接网络的计算.
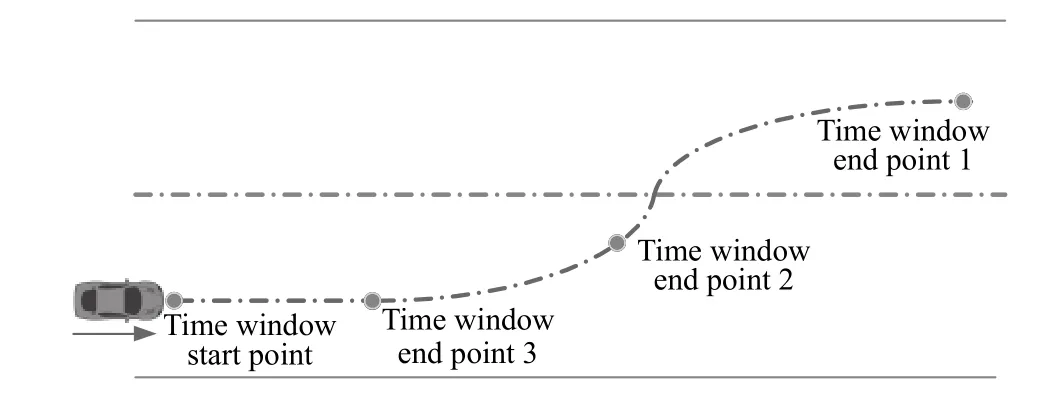
图3 时间窗口确定方法
1.3 数据预处理
1.3.1 汽车运动学数据
由于时间窗口是动态划分的,为了使每个时间窗口内提取的数据特征相同且长度相等,在处理汽车运动学数据时,取每条数据在时间窗口内的最大值、最小值、平均值等.表1 给出各个数据量在时间窗口内的处理方法.在逐渐缩小时间窗口时,Seq2Seq 的标签数据为原时间窗口的尾部数据,但取值方法相同.因此一共提取了15 个特征.
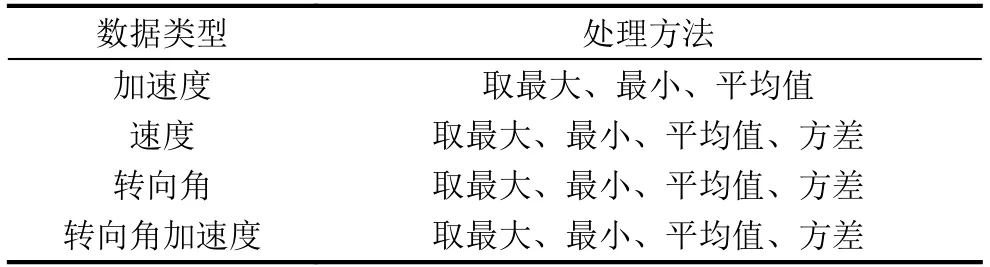
表1 汽车运动学处理方法
1.3.2 驾驶员生理学数据
脑电信号EEG 采用切比雪夫2 型滤波器进行带通滤波,设置截至频率下限为3 Hz,上限为30 Hz.在这里,将EEG 中1~3 Hz,幅度为20~200 μV 的δ 波剔除,因为δ 波出现在人类的婴儿阶段或者智力发育不成熟时期以及成年人在极度疲劳和昏睡或麻醉状态下.所以驾驶员在考虑换道时,该波形不会有明显的变化.
模型需要的输入波形为频率为4~7 Hz,幅度为5~20 μV 的θ波、频率为8~13 Hz,幅度为20~100 μV的α波、频率为14~30 Hz,幅度为100~150 μV 的β波.这3 种波形分别在人类处于抑郁、正常、兴奋状态时有明显的变化,所以可以作为模型的输入量.同样,在这个时间窗口内,取EEG 信号中的θ,α,β波的平均值、最大值、最小值、方差4 种值.然后取θ波段和α波段的绝对功率以及再从每个波段的提取6 个非线性EEG 特性别记为:θ/(θ+α),α/(θ+α),(θ+α)/β,α/β,(θ+α)/(θ+β),及θ/β.从EEG 信号中一共提取了18 个特征.
心率信号的处理方法与他数据类似,也是将其放在一个时间窗口内处理,因此处只有一个信号,不再进行滤波.取一个时间窗口内心率的最大值,最小值,平均值,方差作为输入的特征信号,最终从心率信号中提取了4 个特征.
驾驶员头部的运动数据为驾驶员头在三维空间上的最大转速和转动次数,分别取其时间窗口内的最大值即可.在车辆换道过程中,驾驶员头部在一个时间窗口内的的转动次数为该驾驶员对后视镜的观看次数,该次数表现了驾驶员换道的迫切性,头部最大转速亦是如此,转速越大,表现驾驶员越注意后方车辆,越迫切换道,所以这4 个特征不需要循环神经网络的处理,即不需要Seq2Seq 的预测,直接输入到全连接网络参与分类.
数据按以上方法处理后,可以保证在任何大小的时间窗口下输入的数据个数均相同,同时也保证了模型在训练和检测时数据的一致性.如图4、图5 所示是汽车运动学数据和驾驶员生理数据在一个完整时间窗口内的变化.

图4 汽车运动学数据在一个换道时间窗口的变化
2 模型建立及训练
本文模型是基于循环神经网络和全连接神经网络建立的,循环神经网络用来提取原始数据的特征,并对下一时间点的值进行预测.数据处理过程中提取了41 个特征数据,除了驾驶员头部转动数据外,其他都要经过循环网络的预测.所以循环神经网络需要37 个输入和37 个输出.混合网络一共有41 个输入,2 个输出.该模型的流程如图6.

图5 脑波数据在一个换道时间窗口的变化
2.1 Seq2Seq 层
循环神经网络(Recurrent Neuron Network,RNN)是一种对数据序列建模的神经网络,该网络的优点在于能够很好的处理时间序列数据.由于车辆的换道行为往往发
生在较长的时间段内,如果直接用全连接网络去处理时间序列,势必会造成数据的损失,从而导致模型预测精度下降.RNN 在处理时间序列数据时,会考虑到数据序列中每个数据之间的相关性,可最大程度的利用每个时间窗口的数据序列[9].本文模型需要以数据序列预测数据序列,所以选取RNN 的一个变体结构Seq2Seq,该变体是普通RNN 的增强版本,由一个编码器Encoder 和一个解码器Decoder 成,而Encoder 和Decoder 的计算内核由GRU 构成.

图6 模型流程
Seq2Seq 典型结构就是如图7 所示的Encoder-Decoder 框架,其工作机制是先使用Encoder 将输入编码映射到语义空间,得到一个固定的位数向量,该向量即Seq2Seq 的输入语义向量.然后使用Decoder 将这个语义向量解码,获得所需要的输出.

图7 Seq2Seq 框架
Seq2Seq 的Encoder-Decoder 框架有两个输入,x作为Encoder 的输入,y作为Decoder 的输入且x和y依次按照各自的顺序传入网络.假设Encoder 的输入序列是x={x1,x2,···,xt},传入D e c o d e r 的输入是y={y1,y2,···,yt},根据RNN 的特点,输入过程中t时刻的隐藏状态ht为:

其中,f是非线性激活函数,在本次模型构建中,选择ReLU 函数.依次类推,最后得到ht的就是固定长度的编码向量C,当依次输入得到编码向量C后,开始利用Decoder 解码,那么解码器中的t时刻状态ht为:
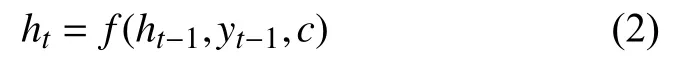
由此,可以推出y在t时刻的条件概率是:
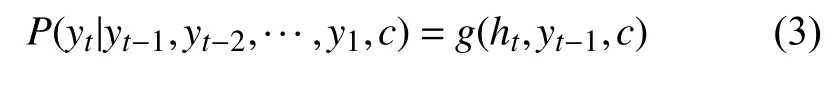
其中,f和g是给定的激活函数,但是后者必须产生有效概率.最后,整个Encoder-Decoder 结构的2 个组件被联合训练以最大化似然条件对数:
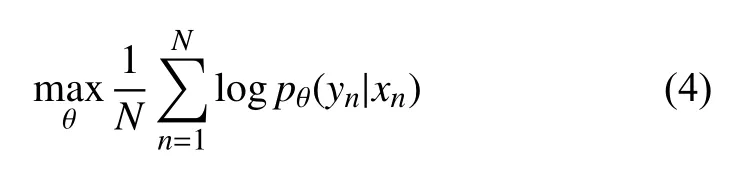
得出该概率之后,即可计算出每个节点的输出.
2.2 全连接层
全连接网络是神经网络里最基本、最简单的一种,但这种网络在多参数融合时的表现良好,所以一般用于处理复杂的非线性分类问题.Seq2Seq 的输出数据复杂且本文的变换车道是预测典型的二分类问题,以及全连接网络与其相匹配的多个激活函数都可以很好的处理该二分类问题.所以采用全连接网络作为Seq2Seq后的分类器.本文所使用的全连接网络的输入有37 个来自RNN 的输出,4 个来自数据预处理,因此共有41 个输入,而结果只需要换道或不换道2 种结果,所以只有2 个输出,全连接网络的数据流向如图8 所示.
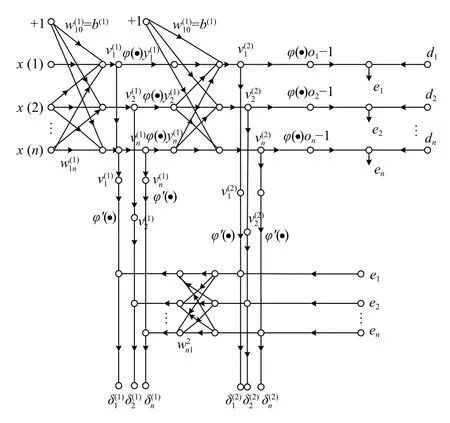
图8 全连接网络数据流图
首先给出全连接网络的向前传播公式.本文将这些输入量设为x(1),x(2),···,x(n-1),x(n),表示第l层神经元的第j个突触的权值,那么在l层的诱导局部域为:
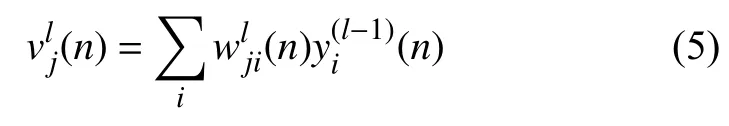

如果神经元在j第一个隐藏层,则有:

其中,xj(n)是输入向量x(n)的第j个元素.如果神经元j在输出层(即l=L,L称为网络的深度),则有:

所以,网络输出误差为:

其中,dj(n)是期望响应向量的第j个元素.
正向传播完成之后,进行反向传播,以完成权值优化.现在给出反向传播的公式:

其中,δj(n)是局部梯度,φj’()是对自变量的微分.得出局部梯度以后,进行权值更新,下面给出在迭代到第n次的权值更新公式:
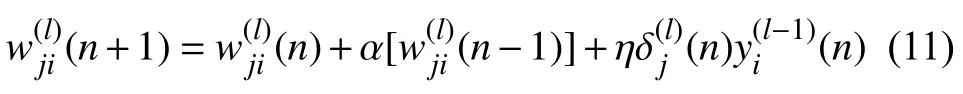
其中,a为动量常数,η为学习率参数.至此,模型构建完成.
2.3 模型训练
据调查统计显示,大部分驾驶员在驱车行驶的过程中更加愿意跟随,而不是急于换道.所以驾驶员换道的数据样本数据并不是很多.为了避免在试验过程中出现驾驶员刻意换道的情况,在数据采集之前并没有告诉驾驶员这次行车的真正目的.并且邀请了不同的驾驶员来完成本次数据采集,尽可能的避免人为干扰.从所采的数据集中一共提取了500 个变道行为和1500 个非变道的特征数据,由于数据量不是很多,因此采用10 折交叉验证的方法来训练和验证模型.
为了能更好展示模型训练过程及性能,如图9 所示,模型训练随时间窗口的缩小推进.第1 步采用原始时间窗口,由于没有缩小时间窗口,所以本次的Seq2Seq 没有标签数据.实验中在Seq2Seq 结构后直接加入全连接层,以变道信号为标签,讨论整个模型的预测精确率.第2 步将原始时间窗口缩小至原来的2/5,讨论模型的前瞻时间和精确率.根据深度学习数据处理方法和Seq2Seq 特点,被训练及预测的标签部分应尽量包含整个时间窗口的数据且至少是整个时间窗口数据的一半以上,这是因为被预测的标签数据需要输入到全连接网络预测,如果标签数据过短,会影响全连接网络的预测准确率.所以第1 步将输入数据设置为2/5,预测时间窗口后3/5 的数据.第3 步将时间窗口缩小至原始时间窗口的1/5,同样讨论前瞻时间和精确率.输入数据时间窗口缩小到原时间的1/5 是为了提高预测前瞻时间,并且1/5 已经是缩小极限,如果再次缩小,会造成严重的数据损失,造成Seq2Seq 的预测偏差过大.在缩小时间窗之后,加入Seq2Seq 网络预测性能展示.
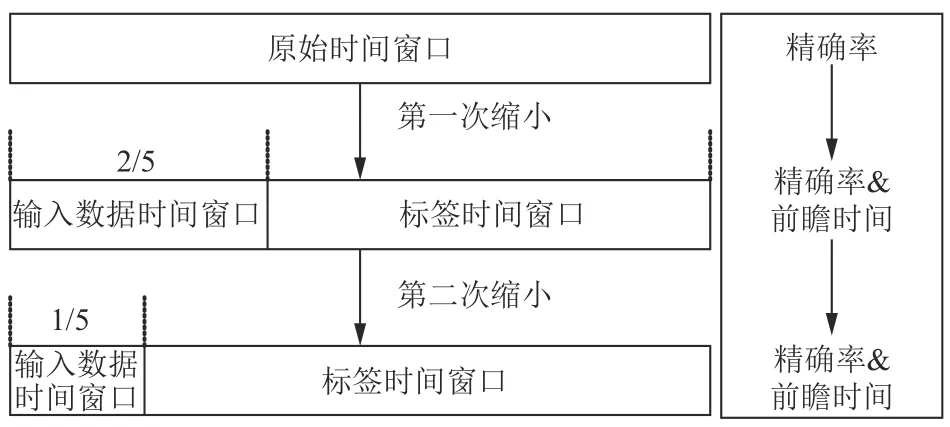
图9 模型训练过程和时间窗口大小关系
在两者级联训练模型收敛后,整个网络的权值会适配输入数据时间窗口为2/5 和1/5 的情况,并且达到最优值,其次就可以进行整个网络模型的测试和验证.
无中间标签时,只讨论整个模型的预测精度,如图10、图11 所示为迭代过程中的损失和精度变化.

图10 无中间标签时网络预测精度

图11 无中间标签时网络预测损失
模型迭代20 000 次后呈收敛状态,精确率达到95%,损失降低到0.1.表明该模型可以较为精确的预测驾驶员变道行为.
其次给出两次缩小时间窗口后Seq2Seq-全连接网络的训练过程,Seq2Seq 预测的是每个原始时间窗口1/5、2/5 后的数据,由于输入输出数据较多且Seq2Seq层预测的是下一时间点的驾驶员和车辆状态,所以用欧式距离来评估预测结果对真实结果的回归程度,计算公式为:

如图12、图13 所示,分别为模型在训练时分别2 次缩小时间窗口的平均偏离程度.迭代200 次后,平均偏离程度开始收敛,但偏离程度会在小范围内波动,这是由于Seq2Seq 模型的输入较多而引起的噪音,并不影响整个模型的预测结果.
将Seq2Seq 预测结果输入到全连接网络中进行10 折交叉验证,图14、图15 所示分别为第一次缩小时间窗口的预测精确率和损失,迭代到20 000 步时模型收敛,精确率达到93.4%,模型的交叉熵损失降低至0.12.此次模型的精确率降低是因为缩小时间窗口造成了数据损失,但这样做的好处是提高了前瞻时间.同理图16、图17 分别是第二次缩小时间窗口后训练集和测试集上的精确度和损失,其精确率达到了93.8%,损失降低至0.11.
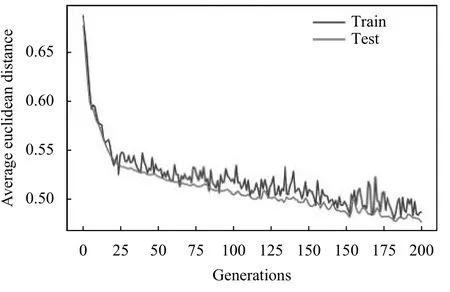
图12 第一次缩小时间窗口时Seq2Seq 误差
如图18、图19 所示,是对相同变道的两种不同的预测方式.t1,T1是车辆变道作用的时间,t2,T2是Seq2Seq训练和测试时的数据提取窗口,t4,T4是Seq2Seq 训练时训练时的标签提取窗口,则t3+t4,T3+T4是提前预测变道的时间长度,即前瞻时间.
从图18 和图19 可看出,T3>t3,在模型训练过程中,第1 种方法的预测精确率达到93.4%,第2 种达到93.8%.说明第2 种方法的预测能力优于第1 种.而第2 种预测方法预测变道所用时间是整个变道所用时间的1/5,即T2=T1/5.假设一个正常变道所用时间为2 s,那么该模型会在变道的前1.6 s 会预测出变道行为.
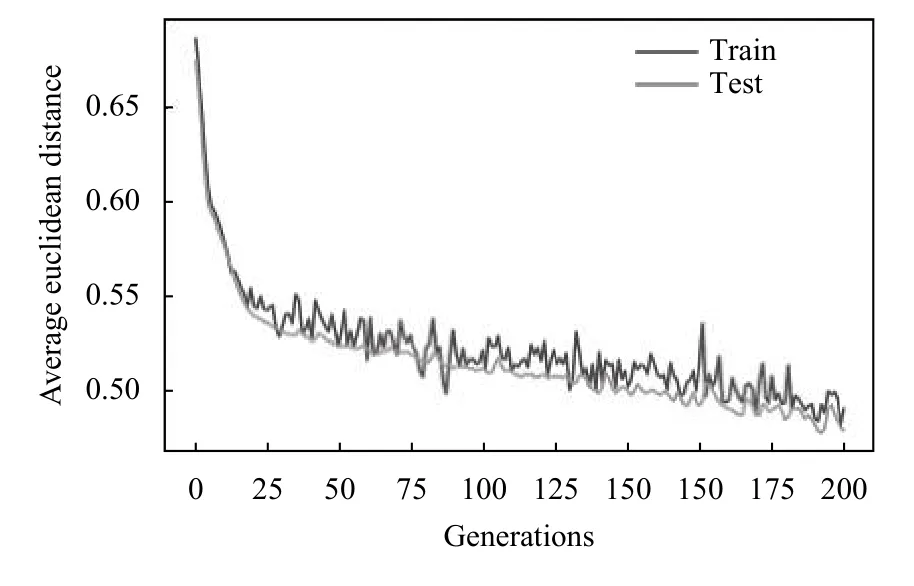
图13 第二次缩小时间窗口时Seq2Seq 误差

图14 第一次缩小时间窗口预测精确率

图15 第一次缩小时间窗口预测损失
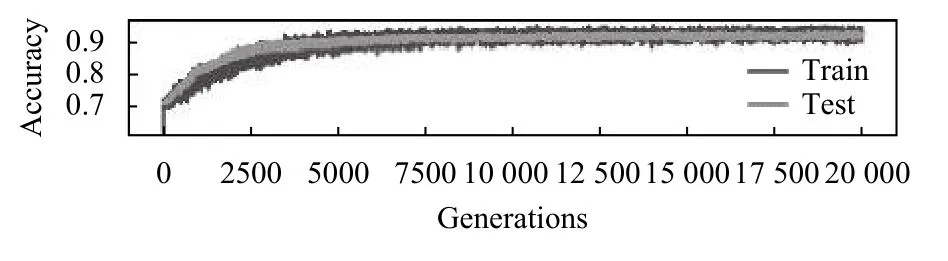
图16 第二次缩小时间窗口预测精确率

图17 第二次缩小时间窗口预测损失
表2 给出了500 个换道行为所用的时间及对应个数,其中用时2-3 s 的变道占了总数的47%,其前瞻时间为1.6-2.4 s,因此该模型能够很早的预测变道且具有较高的预测精确率.

图18 第一次缩小时间窗口前瞻时

图19 第二次缩小时间窗口前瞻时间

表2 变道个数及所用时间
图20 给出了在所有变道中抽样50 次后,变道所用时间和预测所用时间对比,预测时间远小于整个换道时间.
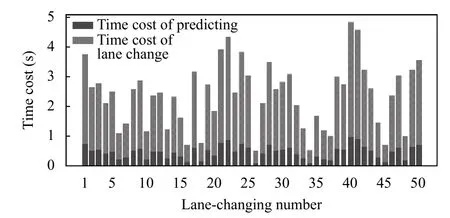
图20 换道/预测用时
当整个模型达到收敛状态,其内部权值达到最优时,开始用另一组未使用过数据对模型性能进行验证.
3 模型验证
模型训练结束后,其内部的权值参数已经达到最优,为了检验模型的泛化程度,将训练使用过的数据全部丢弃,并邀请了不同的驾驶员驾驶数据采集车辆在不同的路线进行数据采集,图21 是验证数据采集路线.
图21 测试数据采集路线
使用和模型训练时相同的数据处理方法,但验证模型只有一个输入数据,没有任何的标签,数据从网络输入,只看网络预测变道结果和真实结果的对比,不同算法精准率对比如图22 所示.我们采用200 个变道数据和800 个非变道数据进行十折交叉验证,图23 是每个测试批次的精确率变化.可见模型的在初始的几个测试批次出现了精确率降低的情况,但整体表现良好,其测试平均精确度达到了93.5%,其前瞻时间和训练模型时相同,前瞻时间是整个换道时间的4/5,如图24所示,同样随机抽取了50 个变道数据来展示模型前瞻性.

图22 不同算法精确率对比
我们使用同样的数据处理方法验证了几种深度学习和机器学习领域的经典算法.发现在相同的情况下,传统BP 网络的精确率达到了91.6%,MTSDeepNet 的精确率达到了92.0%,SVM 的精确率达到了90.1%,DBN、Decision tree 的精确率分别达到了75.0%和84.0%.相比较,本文提出模型的平均精确率达到了93.5%,在性能上优于以上算法.

图23 模型验证精确率

图24 验证集换道/预测用时对比
模型验证结果表明本文提出的Seq2Seq-全连接网络的混合网络模型能较准确的预测驾驶员变道行为,其平均精确率达到93.5%,平均预测时间达到2 s.
最后给出整个模型的在训练和验证完成后的性能分析.模型训练和测试所用的环境是Windows 10 下的Spyder 和Tensorflow.机器的处理器为至强E5-2623,内存为16 GB.在此环境下,整个模型训练的时间为28 小时左右.完成训练后,进行模型验证,1000 条数据在5-6 min 内可完成计算预测,此时模型权值已近计算完成,模型只进行顺序计算即可,每条数据的计算耗时0.3-0.4 s,能够满足实车测试的实时性.且在此基础上,提高了模型精确率和前瞻时间.相较传统网络模型,该网络模型加入了二级训练标签,更适合处理深层次、更复杂的时间序列.计算时间方面,模型的训练耗时更长,但验证时间和传统模型相比持平或更短.综上,该网络模型优于传统网络模型.表3 给出该混合网络模型和传统模型在输入数据相同时的参数规模.
本文提出的Seq2Seq-全连接网络模型的参数规模为104,和DBN 模型的规模相同,而全连接网络、SVM、Decision-Tree 的参数规模均为103.这说明本文提出的模型具有更多的权值点和深度.但相比较DBN,所以出的网络模型具有更快的计算时间和更强的时间序列处理能力.

表3 不同模型的参数规模
4 结论与展望
本文提出了一种基于RNN-Seq2Seq 和全连接网络的两级混合神经网络,可以更加准确、更加提前的预测驾驶员的换道行为,减少驾驶员在行车过程中的危险性.在该模型中,车辆运动学数据、驾驶员生理数据、驾驶员运动学数据被用作混合神经网络的输入.并且设计了一种以动态时间窗口来提取车道变换过程中的3 种数据特征的方法,使用缩小时间窗口的方法来训练提出的混合神经网络以提高预测的前瞻时间.结果表明,该混合网络模型的平均预测精确率达到93.5%,平均前瞻时间达到2 s,优于其他5 种常用模型.
在下一步的研究中,首先会增加训练和验证模型的数据量,使得模型更加泛化和鲁棒.其次,会增加各种不同路况和路型的数据来训练模型,使得模型能够适用于不同的行车环境[16,17].最后,会使用不同的车辆种类来采集数据来训练模型,以提高模型的使用范围.
猜你喜欢
黄河之声(2022年10期)2022-09-27
汽车实用技术(2022年14期)2022-07-30
舰船科学技术(2022年11期)2022-07-15
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
汽车实用技术(2022年7期)2022-04-20
煤气与热力(2022年2期)2022-03-09
汽车实用技术(2022年4期)2022-03-07
北京航空航天大学学报(2021年4期)2021-11-24
