
基于多流3D融合网络的人体行为识别
2020-03-18 09:42张天雨
智能计算机与应用 2020年10期
戎 炜, 张天雨
(合肥工业大学 计算机与信息学院, 合肥 230601)
0 引 言
行为识别是指从视频帧序列中提取出与目标行为相关的有用信息,并采用合适的方式进行数据表达,通过解释这些行为视觉信息,达到对人的行为模式分析和识别的目的。行为识别按识别对象区分为个体行为识别与群组行为识别。研究者针对个体行为识别任务,提出了一些方法。受到在静态图像上成功使用卷积神经网络的鼓舞,许多研究人员开发了用于视频理解和行为识别的方法[1]。最近的大多数作品都受到Simonyan等人提出的双流卷积神经网络的启发,其中合并了从RGB图像和光流图像中提取的空间与时间信息;另一方面,对于视频行为识别,3D卷积网络亦是该领域的重要研究热点,已被广泛应用于行为识别任务中。但是,3D卷积网络的预训练过程不仅需要大量的视频数据,而且还需要大量的硬件资源。
对于行为识别中双流网络与3D卷积网络各自的局限性,本文提出了一个新的网络模型。该网络模型将双流网络与3D卷积网络的特性结合,同时重新设计网络结构,以弥补两种网络的缺陷,使得该网络模型能出色地完成个体行为识别任务。
1 多流3D融合网络
本文提出的改良多流3D融合网络(Multi-stream 3D Fusion Network,M3DFN)模型将双流网络和3D卷积网络的特性结合,并加以改良,以提升在群体中个体行为识别的性能。多流3D融合网络的结构如图1所示。网络由输入采样模块,目标定位提取模块,多流3D卷积模块,分类LSTM模块等主要部分组成。在视频行为识别任务中,对于输入视频序列,采用时序分割方法,将视频序列分为若干帧一个片段,在每个片段中随机采样一帧图像,之后使用Faster R-CNN网络对图像中的人物进行目标定位。取人物帧图像前后若干帧组成图像序列,对其进行光流提取后得到光流信息特征图;将输入的图像分为多帧图像序列,采样得到的单帧图像以及多帧光流图序列,输入多流3D卷积模块中,输出的个体特征进行特征连接操作得到全局特征;将各个多流3D卷积模块输出的个体特征输入到分段LSTM模块中,输出的融合特征再次与全局特征融合;最后,经由全连接层与softmax分类操作得到最终个体行为识别结果。

图1 多流3D融合网络结构图
2 视频特征的多流提取与处理
2.1 膨胀3D卷积网络
多流3D卷积模块的结构如图2所示。双流网络部分沿用经典的时序分割网络,而膨胀3D卷积网络部分则是在已有的2D ResNet101上进行2D膨胀操作,将其扩充为3D卷积网络。膨胀3D卷积网络的输入是以随机采样得到的单帧RGB图像为中心的RGB图像序列,输出则是个体特征。为了与2D卷积输出的特征维度匹配,膨胀3D卷积网络的输出特征将会被压缩为2D尺寸。

图2 多流3D卷积模块结构图
残差神经网络(Residual neural Network, ResNet)最早是由He等人提出的,并在图像识别任务有出色表现[2]。代替直接拟合的基础映射H(x),残差网络将原始映射改良为F(x)+x以拟合残差映射。这类研究表明了这种连接之前输入的方式十分有效[3]。残差连接方式可以表示为式(1)和式(2):
yi=xi+F(xi,W),
(1)
xi+1=f(yi).
(2)
其中,xi与xi+1代表第i层的输入和输出;F(xi,W)代表残差映射;f()代表ReLU过滤函数。对于多于50层的网络,残差映射F(xi,W)则是由3层一组的形式组成。
由于3D卷积网络在空间卷积结构上与对应的2D卷积很相似。因此可以将ImageNet预先徐连的2D参数视为3D内核的一部分。可以沿时间维度将2D参数直接复制到3D内核中,这就是2D膨胀操作。但是由于参数不足以支撑起多出来的时间维度,仍然需要重新设计时间结构。受到I3D网络提出的扩展操作的启发,本文采用2D膨胀操作,用于引导ImageNet预训练参数。具体的思想是用3个2D卷积核来组成一个3D卷积核,这些2D卷积核是从对应的ImageNet预训练的2D卷积层的同一通道中复制的。于是参数的尺寸可以由正方形转换为立方体。这些操作可以描述为公式(3)和公式(4):
(3)
(4)
本文提出的多流3D卷积模块中的膨胀3D卷积网络是由2D的ResNet101经由2D膨胀操作变化得到的。具体操作如图3所示:将输入卷积的大小由7×7卷积变为3×7×7卷积。padding的尺寸由3×3变为1×3×3。3×3卷积包括最大池化卷积变为3×3×3卷积,1×1卷积变为1×1×1卷积。时间维度的步长均设为1,空间维度的步长保持不变,最大池化卷积在的时间与空间维度的步长也都保持不变。膨胀3D卷积网络的预训练参数由ImageNet预训练的对应2D卷积网络提供,因此不需要如Kinetics之类的数据集预训练,节省了大量的时间与计算开销。

图3 2D 膨胀操作示意图
2.2 双流卷积网络
双流卷积网络由两个独立的空间流卷积网络和时间流网络构成。空间流网络将RGB图像作为输入,而时间流网络则使用堆叠的光流图像作为输入。大量文献表明,较深的卷积网络可以提高双流网络的整体性能。特别是VGG-16,GoogleNet和BN-Inception在空间流和时间流上的性能都得到了验证。但ResNet101展示了其捕获静态图像特征的能力,因此选用ResNet101作为空间流和时间流的基准网络。空间流输入方面,采用单帧RGB图像已被证实十分有效。时间流输入方面,采用标准的10帧连续光流图像序列。Feichtenhofer等人的实验证明了融合特征的重要性,后期融合特征可以达到最佳融合,而早期的融合虽然需要的参数较后期少,但达到的性能不如后期融合。因此,本文采用最后一层融合特征的方式构造双流网络。在最后的融合中,本文采用了特征串联的方式,不仅串联时间流和空间流,也让膨胀3D卷积网络的输出特征参与串联过程。串联融合得到的特征成为分段LSTM的输入。双流ResNet101由ImageNet网络预训练,鉴于膨胀3D卷积网络的特性,可以从双流网络中共享参数。因此只需预训练双流网络,便可为膨胀3D卷积网络提供参数。
3 时间信息处理与特征融合
3.1 分段LSTM网络
视频内每个图像帧的变化都可能包含其他信息,这些信息可能对确定整个视频的人体行为有所贡献。最能直接提取并利用这些信息的模型之一是循环神经网络(RNN)。RNN可以通过隐藏状态单元设计学习时间动态信息。但是由于RNN存在的长时依赖问题,使用LSTM代替RNN是较好的选择。然而,更深的LSTM层不一定有助于获得更好的动作识别性能,因为之前的双流卷积网络与3D卷积网络已经提供了足够强大的学习性能。
本文采用LSTM单元与时间池化层的结合来提取时间动态信息,构造分段LSTM网络,如图4所示。输入特征为串联的3种特征序列。经过与采样阶段相同数量的分段后,经过BN(Batch Normalization)操作后,使用时间池化层从每个片段中提取区别特征,再输入LSTM中提取嵌入特征。时间池化层可以是平均池化层或者最大池化层,本文选用最大池化层。时间池化层从3D,空间和时间流串联的特征向量中提取区别特征。而LSTM将提取整个视频的嵌入特征。其本质上是学习非线性特征组合及其随时间变化的分段表示的机制。
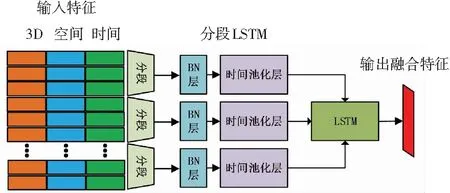
图4 分段LSTM结构图
3.2 分支特征融合
经过各个模块的提取输出的分支特征需要按照顺序进行汇总。本文评估了3种特征融合方法,如图5所示。
最简单直接的方法便是图5中左侧的直接连接。将每个分支特征向量按时间顺序连接到组合的特征向量中,之后直接输入全连层和分类层。聚合信息的第二种方法是图5中间的操作,添加了全连接层和Dropout操作,全连接层能进一步处理组合的特征向量,进一步提高识别的准确率。图5中右侧的是基于第二种方法的第3种方法残差连接,添加了残差全连接层,从而聚合从视频中提取的特征。本文采用第三种方法,公式(5)和公式(6)为
xc={x0,x1,...,xn-1},
(5)
xt=Hc(WcXc+xc).
(6)
其中,xc为各个分支特征xn合并而成,并进行残差连接操作,Wc代表残差连接层的权重,Hc代表ReLU函数与Dropout的结合操作。实验结果表明,组合特征向量的残差连接处理是有益的,连接输入特征向量丰富了特征中的信息,提升了识别性能。

图5 3种特征融合方法示意图
4 实验结果及分析
4.1 数据集介绍
为了证明本文提出的网络模型能有效完成个体行为识别任务,本文在volleyball数据集上对模型进行验证。该数据集是用于群体行为识别的数据集,但因为对场景中的每个个体的动作及位置都设置了标签,因此也适用于个体行为识别。Volleyball数据集的视频均为排球比赛,收集自YouTube视频网站。该数据集包含了55场排球比赛的实况录像,并且制作者为其中的4830帧制作了位置与行为标注。每个运动员个体都以一个边界框的坐标和9种个体动作之一进行标注,而这9种个体动作对应8种群体行为,表明在场景中的某个群组发生的群组行为类别。本文将volleyball数据集的2/3用于训练,1/3用于测试。
4.2 评价指标
文中选择准确率(Accuracy)指标来评价方法和模型的性能。准确率是群组行为识别任务广泛采用的指标,准确率计算方法如式(7):
(7)
其中,nij指真实标签是i,分类预测结果标签是j的样本数量。njj是nij的特殊情况,代表真实标签和分类结果标签均为j。N代表参与测试和评价的样本总数量,Acc代表准确率。准确率越高代表方法和模型的效果越好。
4.3 实验环境
本文在64位系统Ubuntu16.04上安装了pytorch深度学习框架,该计算机GPU由两块NVIDIA GeForce GTX 1080与一块NVIDIA GeForce TITAN xp组成,共有四块GPU。CPU采用Intel Core i7-8700k型号。内存大小为48G,编程环境选择python3.6环境。
4.4 实验方法
本文的实验方法选择标注帧的前五帧与后四帧,包括标注帧在内的10帧时序连续图像作为输入。在消融实验中,将调整包括标注帧在内的时序连续图像的数量,比如调整为25帧时序连续图像。本文中的卷积神经网络采用残差网络与密集网络的3D膨胀版本,该网络的特性是不需要预训练也能表现出较好的性能,省去了庞大的预训练开销。输入图像需统一调整分辨率为224×224,并经过数据扩充处理。本文的数据扩充方法为多尺度随即裁切,即裁切由最小长度与尺度乘积定义的区域,比例从1.0,0.875,0.75,0.66中随机选择。同时,对每3帧图像,执行水平翻转操作的概率为50%。之后分别提取裁剪视频帧的外观特征与运动特征以满足时序分割部分输入的需要。本文的LSTM部分采用单层LSTM网络,输入的特征向量为4096维,LSTM隐藏单元为512个。
本文实验采用Faster R-CNN网络作为目标检测方法,并对检测出的场景中的个体目标提取外观信息和运动信息,并送入空间流与时间流网络。在空间流与时间流网络中,经过膨胀3D卷积层提取融合操作,输出的特征经过连接操作,进入LSTM网络提取跨时间信息,并得到个体行为的特征表达,经过softmax层分类,作出最终的行为预测结果。同时本文也将使用真实位置标注的实验结果作为对比。
本文网络模型的优化算法选用Adam优化算法,Dropout参数的值设置为0.5,以防止过拟合现象。模型的初始学习率设置为0.001,衰减设置为每个周期的学习率衰减为上个周期的0.75。这是因为传统的梯度下降策略将导致损失的持续增长,并且过快的梯度更新更容易过拟合。批处理数据大小为128,即网络每个周期处理128段视频序列。训练周期为340个周期,即网络对整个数据集训练340次。
4.5 对比实验结果分析
为了研究本文提出的多流3D融合网络在个体行为识别任务中的提升效果,本文在volleyball数据集上进行了模块递进的消融实验,各方法消融实验结果见表1。

表1 Volleyball数据集上的消融实验结果
在表1中,将本文方法与各方法进行了对比,该对比实验未使用真实位置标签,而是利用Faster-RCNN网络对群组中个体进行空间定位,同时对输入视频段的采样设置为3帧一段。表1中Two-Stream表示传统时序分割双流网络方法;Inflated-3D表示经过膨胀操作后的3DresNet101网络方法;Two_Stream+LSTM与Inflated+LSTM代表为这两种网络添加LSTM层后形成的网络方法;Ours代表本文提出的方法。由表1可知,双流网络的识别准确率要高于膨胀3D卷积网络,而在加入LSTM层后,这两种方法的识别准确率也都有所上升,不过双流网络方法的识别准确率依然要高于膨胀3D卷积方法的识别准确率。而本文提出的方法由于融合了这几种网络的特点,其识别准确率均高于这几种网络的识别准确率。
表1中的方法的损失与准确率收敛曲线如图6所示。图6(a)中,双流网络的时间流需要对光流图提取时间信息,导致整体训练速度较慢,损失震荡较明显,需要较长时间收敛。而膨胀3D网络将时间信息作为一个维度的信息进行提取,训练速度较双流网络要快,损失对比双流网络收敛较快,但最终收敛损失比双流网络要高。添加分段LSTM模块的双流网络与膨胀3D网络损失收敛更快,这是LSTM网络更好地提取时间信息的缘故。本文提出的方法结合了多种网络的优点,损失下降最快,且震荡较小,最终收敛损失也最低。图6(b)中也能看出,本文提出的方法的准确率最高,对比双流LSTM网络与膨胀3D网络的准确率,分别提高了1.7%和4.6%。
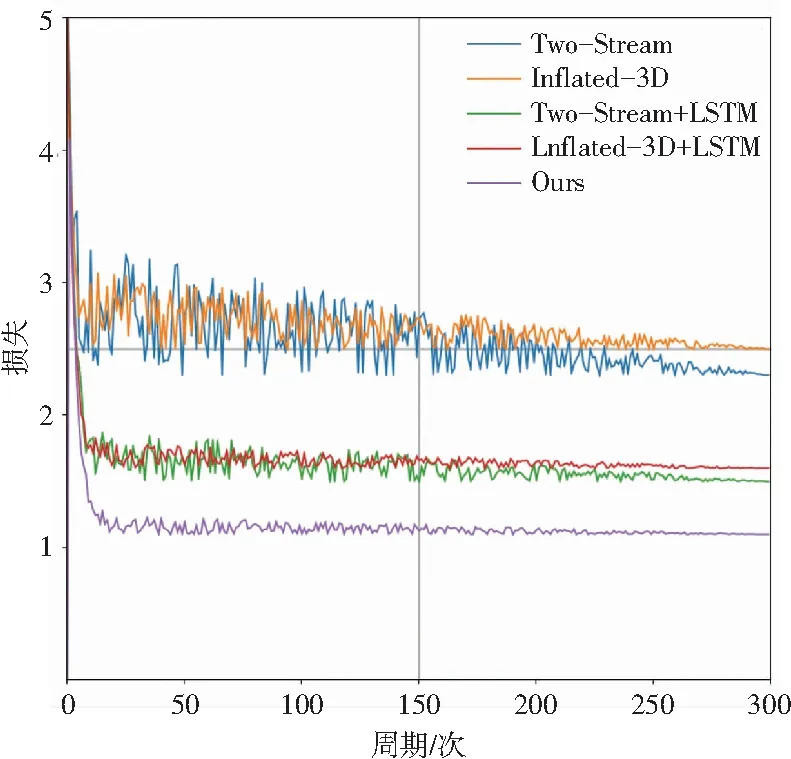
(a) 损失收敛曲线
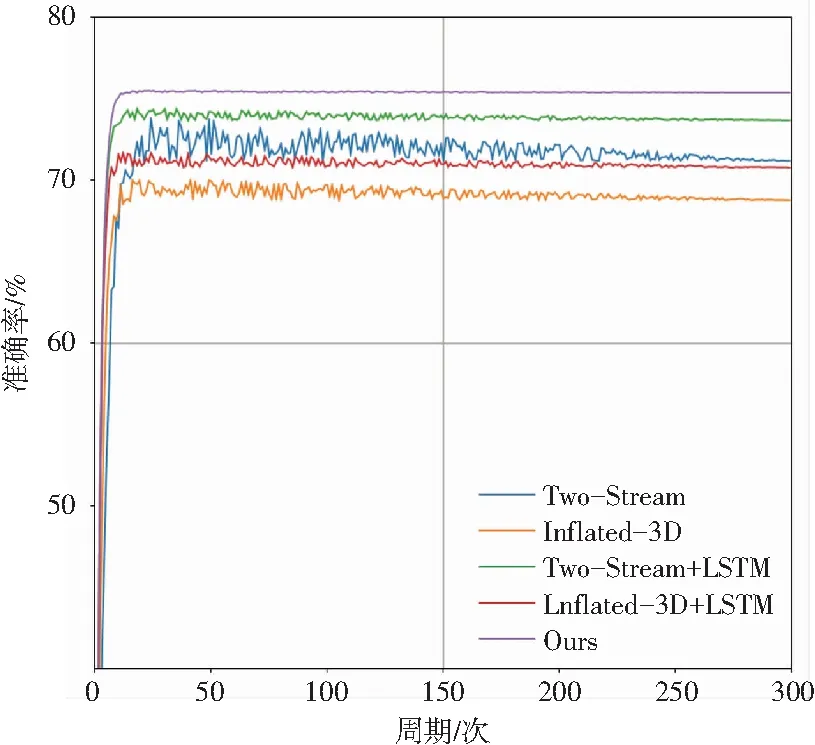
(b) 准确率收敛曲线
不同融合方法的对比实验结果见表2。3种融合方法在volleyball数据集上的实验准确率如图7所示,Direct-Connection代表直接连接融合,Fully-Connection代表全连接融合,Residual-Connection代表基于全连接融合的残差连接融合。其中残差连接融合准确率最高,对比直接连接融合与全连接融合分别提升了2.6%和1.9%。实验证明,使用残差连接融合处理组合特征向量丰富了特征中的信息,提升了识别性能。

表2 不同融合方法的对比实验结果
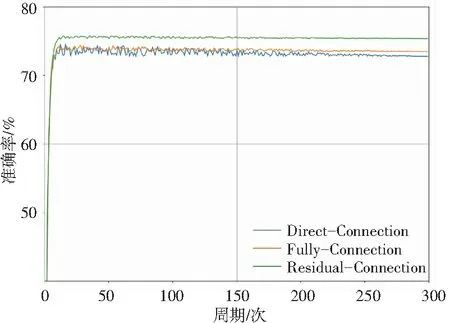
图7 3种融合方法的准确率收敛曲线
4.6 与其他方法对比分析
将本文提出的方法与Bagautdinov提出的方法进行了对比,实验结果见表3。
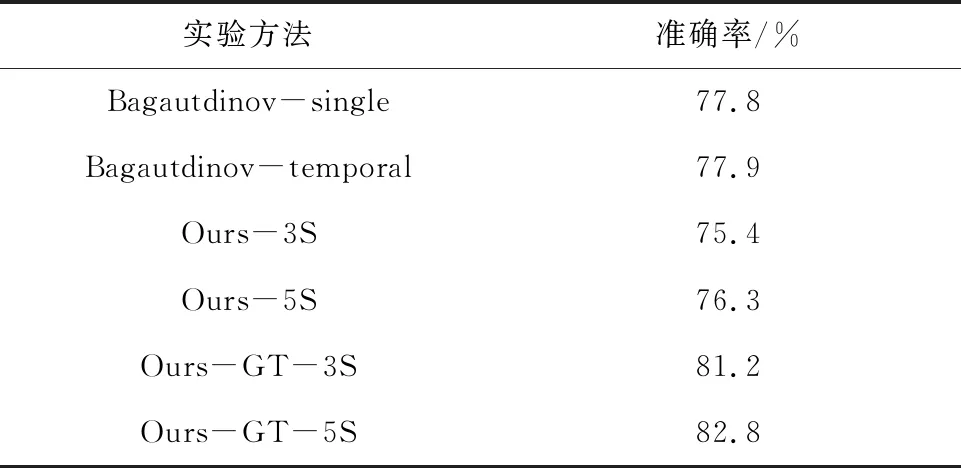
表3 Volleyball数据集上的对比实验结果
Bagautdinov-single代表输入图像帧数为1帧;Bagautdinov-temporal代表输入图像帧数为10帧序列;Ours代表本文提出的方法,3S代表输入视频分割方法为3帧一段,5S则代表以5帧一段进行分割,GT代表使用真实位置标签进行目标定位,否则代表使用Faster R-CNN网络进行目标定位。由表3可知,本文提出的方法在不使用真实位置标注的情况下,识别准确率要低于Bagautdinov提出的方法。而使用了真实位置标注后,本文的方法的识别准确率则高于Bagautdinov方法。另外,5帧分割方法的识别准确率要高于3帧分割方法,这是因为获得了更多的输入帧,从输入中提取的时间信息更加丰富。而对于可能出现的模糊、遮挡情况,Faster R-CNN网络检测极易出现偏差,且对于某些实际边界框个数少于真实边界框标签个数的场景,本文采用将其特征置0的处理方式,这同样也会影响个体行为识别结果,而真实位置标注也不会存在这样的问题。
4.7 混淆矩阵分析
使用Faster R-CNN定位与真实位置标注定位的实验混淆矩阵如图8与图9所示。可以看出,使用真实位置标注定位的准确率要高于使用Faster R-CNN定位的准确率。两者在setting,jumping,moving等动作的识别准确率上有较大差异。这是因为Faster R-CNN定位的目标位置与真实位置有偏差,以及忽略某些人物的位置预测所造成的。如图10所示,蓝框为Faster R-CNN检测到的人物位置框,黄圈中则为未检测的人物。由于场景与人物互相遮挡,以及实际边界框个数与标签不匹配等问题,会造成人物定位的偏差与遗漏,从而导致识别准确率下降。

图8 Faster R-CNN定位的混淆矩阵

图9 真实位置标注的混淆矩阵
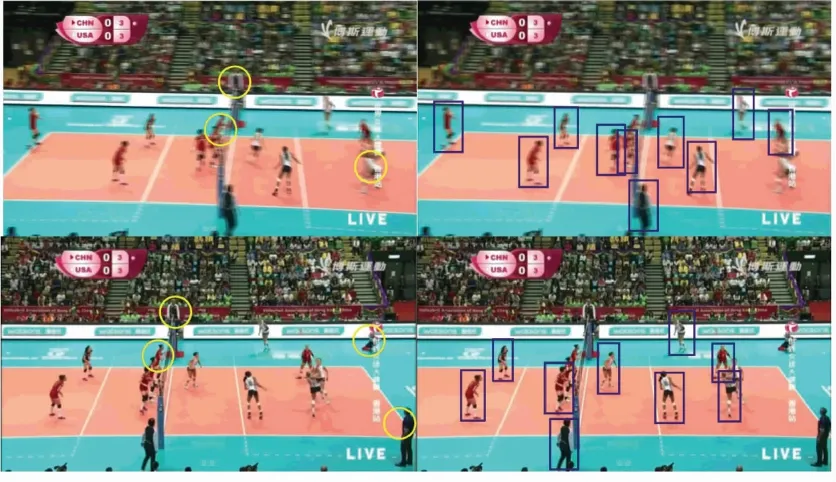
图10 Faster R-CNN检测失败对比图
5 结束语
本文主要介绍了结合了双流网络与3D卷积网络特性并改良的网络模型,该网络模型提取视频帧的外观特征与运动特征,并经过膨胀3D卷积模块,双流卷积网络与长短期记忆网络提取跨时间信息。最终学习视频时序变化的全局描述,达到进行精确的个体行为识别的目的。在volleyball数据集上的实验证明了本文提出的模型在群组中个体行为识别任务中的有效性。考虑到现实场景任务中的复杂性,如何在更加复杂的场景中更有效快速地完成人体行为识别任务,正是未来工作的重点之一。
猜你喜欢
现代经济信息(2022年22期)2022-11-13
中小学校长(2022年7期)2022-08-19
成都信息工程大学学报(2022年2期)2022-06-14
当代县域经济(2022年5期)2022-05-09
心理学报(2022年4期)2022-04-12
作文大王·低年级(2022年2期)2022-02-28
北京大学学报(自然科学版)(2022年1期)2022-02-21
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
